
데이터 전처리
기계학습 모델들은 학습하는 데이터에 의존성이 굉장히 크다. 똑같은 모델이어도 좋은 데이터로 학습하면 이후 성능도 좋게 나오지만 안 좋은 데이터로 학습하면 성능도 안 좋아진다. Garbage In, Garbage Out이다. 그래서 사람의 손으로 모델이 학습을 잘 할 수 있도록 전처리를 통해 데이터를 가공해서 모델에 보내준다.
기계학습 모델에는 데이터의 크기에 따라 영향을 받는 것도 있고, 데이터가 가지고 있는 단위에 영향을 받는 것도 있다고 한다. 그래서 보통 다음과 같이 데이터를 전처리한다.
- Null/NaN 처리
- 데이터 인코딩
- 데이터 스케일링
- 이상치 제거
여기서는 데이터 인코딩과 데이터 스케일링에 대해 알아보자.
인코딩(Encoding)
머신러닝 모델에 들어가는 데이터는 모두 숫자여야 한다. 그런데 사람의 눈에 편하게 보이고 편하게 입력하는 데이터 형태는 문자열이다. 예를 들어, 살고 있는 지역을 물어볼 때 0, 1이 아니라 '서울', '제주' 등으로 대답하는 것과 같이 말이다.
그런데 이렇게 문자열로 받은 데이터는 머신러닝 학습에 피처로 쓸 수 없기에 각 정보에 번호를 부여해 구별할 수 있도록 하는 과정이 필요하며, 이를 보고 데이터를 인코딩한다고 한다. 인코딩의 종류에는 대표적으로 다음과 같이 두 가지가 있다.
- 레이블 인코딩(Label Encoding)
- 원-핫 인코딩(One-hot Encoding)
1. 레이블 인코딩
레이블 인코딩은 ['서울', '제주', ...] 데이터를 [0,1,...] 로 변환하는 것을 의미한다. 가장 직관적이고 직접적인 방식이다.
# Label Encoding
from sklearn.preprocessing import LabelEncoder
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
# LabelEncoder를 객체로 생성한 후, fit()과 transform()으로 레이블 인코딩 수행.
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값:', labels)
# 각 값이 원래 뭘 뜻하는지 알고 싶다면?
print('인코딩 클래스:', encoder.classes_)
변환하면 원래 문자열 값이 들어있던 리스트가 숫자형 값으로 바뀐다. 그리고 각 값이 원래 무엇을 뜻하는지 알고 싶다면 encoder.classes_ 속성에서 확인할 수 있다.

그러나, 이렇게 되면 위 예시에서 '컴퓨터가 TV보다 더 큰 값을 가지고 있다' 와 같이 변환된 리스트가 의도하지 않은 의미를 내포한다. 만약 피처의 크기에 영향을 받는 모델인 경우, 인간이 의도하지 않은 결과를 뱉어낼지도 모른다. 그래서 웬만하면 이렇게 구분만 한 데이터는 영향을 안 주도록 하는 것이 필요하다. 원-핫 인코딩 방법을 사용하면 이런 문제점을 해결할 수 있다.
2. 원-핫 인코딩
원-핫 인코딩은 분류별 항목에 해당하는 새로운 컬럼을 추가해서 각 컬럼마다 해당 분류에 맞는 행의 값만 1로 하고, 나머지는 0으로 놓는 식으로 변환하는 방식이다. 이렇게 하면 값이 0과 1뿐이므로 크기에 민감한 모델들도 사용할 수 있다.

이 때, 원-핫 인코딩을 사용하기 위해선 인자로 2차원 ndarray가 들어가야 하므로 기존 데이터를 2차원 ndarray 형으로 바꿔주는 선작업이 필요하다.
원핫 인코딩 코드
# One Hot Encoding
# 원핫 인코딩은 피처 값의 유형에 따라 새로운 피처를 추가해 고유 값에 해당하는 데이터에만 1을 표시하고 나머지는 0을 표시하는 방식.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# items 선언
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
# 2차원 데이터로 변환
items = np.array(items)
items = items.reshape(-1, 1)
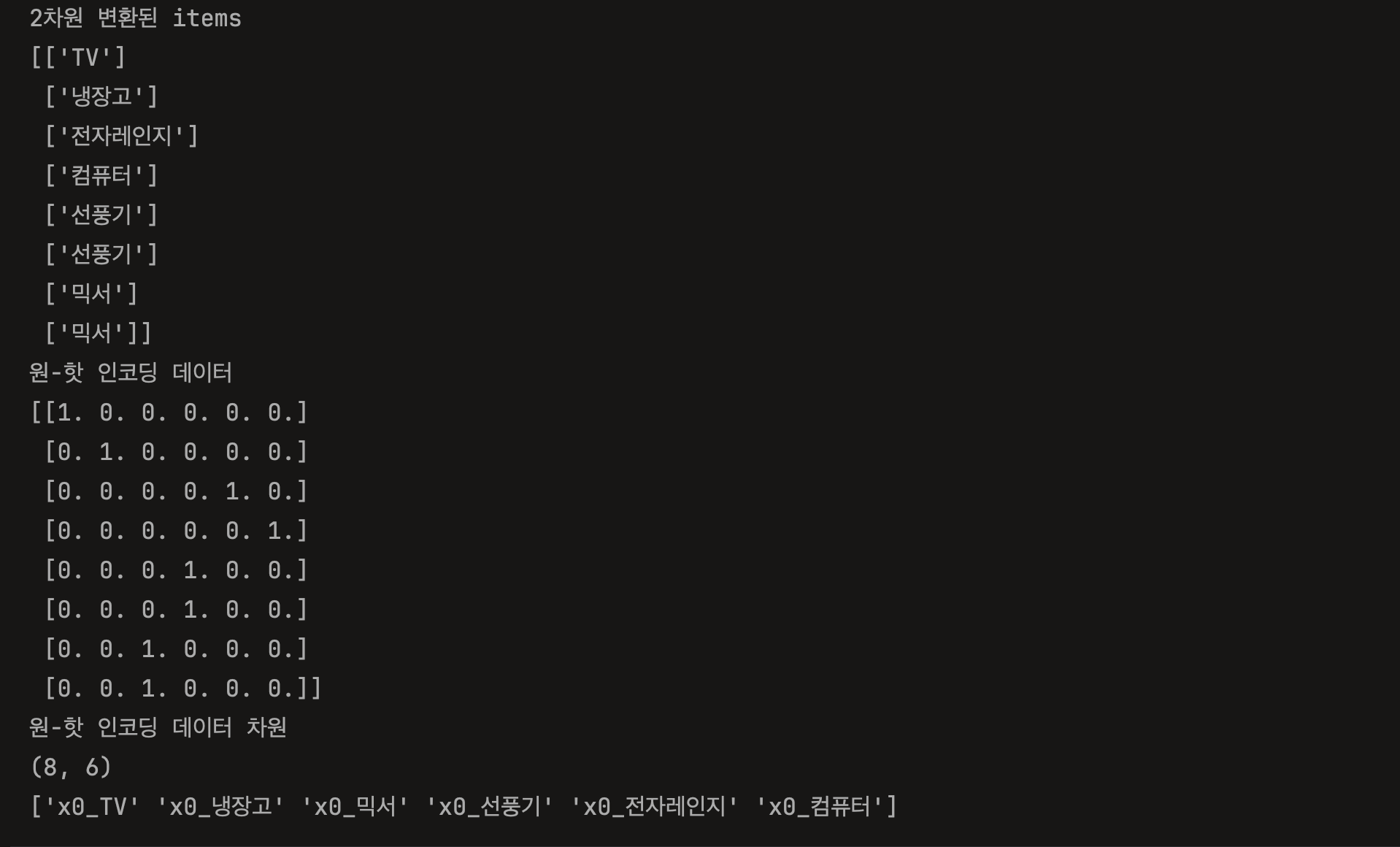
print('2차원 변환된 items')
print(items)
# OneHotEncoder 객체 생성 후, fit()과 transform()으로 원-핫 인코딩 수행.
encoder = OneHotEncoder()
encoder.fit(items)
one_hot = encoder.transform(items)
print('원-핫 인코딩 데이터')
print(one_hot.toarray())
print('원-핫 인코딩 데이터 차원')
print(one_hot.shape)
# 각 행이 무슨 뜻인지 알고 싶다면
print(encoder.get_feature_names_out())원-핫 인코딩의 결과는 항목 리스트의 각 값에 대해서 1,0으로 이루어진 벡터가 반환된다. 예를 들어, TV는 [1, 0, 0, 0, 0, 0, 0], 냉장고는 [0, 1, 0, 0, 0, 0, 0] 등으로 나온다. 여기서 1,0 각각의 위치가 어느 항목을 뜻하는 것인지는 enncoder.get_feature_names_out() 메소드를 활용하면 알 수 있다.
pandas에서도 원-핫 인코딩 기능을 지원하고 있는데, get_dummies() 메소드를 이용하면 된다. get_dummies()는 DataFrame의 한 열을 입력으로 받아 원-핫 인코딩을 진행한 후의 결과를 DataFrame 형으로 반환해준다.
import pandas as pd
# get_dummies() 함수를 사용하여 원-핫 인코딩 수행
one_hot_encoded = pd.get_dummies(df['column_name'])