
하둡
하둡이란?
-
하둡은 범용 하드웨어ㄹ 구축된 컴퓨터 클러스터의 아주 방대한 데이터 세트를 분산해 저장하고 처리하는 오픈 소스 소프트웨어 플랫폼
-
핵심 기능은 장애 허용(fault tolenrance)
-
확장성을 높이기 위해 장애를 당연히 발생 가능한 일로 간주
-
기반 소프트웨어 시스템이 실패한 작업을 책임지고 재시도하게 설계
-
이로 인해 다소 불안정하지만 저렴한 하드웨어로도 매우 안정적인 시스템을 구성할 수 있음
-
-
하둡은 모든 작업을 병렬로 처리하도록 설계
- 그 당시에는 빨랐지만, 현재는 다소 느려서 스파크를 사용함
-
대규모 검색 색인 구축을 위해 자바(JAVA)로 개발된 오픈 소스 컴퓨팅 플랫폼
하둡의 핵심 기술
- 분산 파일 시스템
- 리소스 관리자와 스케줄러
- 분산 데이터 처리 프레임워크
하둡 에코시스템
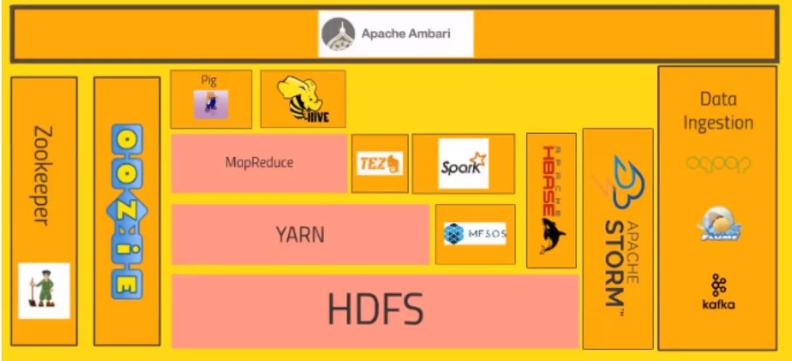
-
HDFS
- 대규모 데이터를 분산, 저장, 관리하기 위한 분산 파일 시스템
-
맵리듀스
- 대용량 데이터를 분산 처리하기 위한 목적으로 개발된 프로그래밍 모델이자 소프트웨어 - 프레임워크(Map과 Reduce로 구성),
- Map: 클러스터에 분산된 데이터를 효율적으로 동시에 변형,
- Reduce: 그 데이터를 집계
- 대용량 데이터를 분산 처리하기 위한 목적으로 개발된 프로그래밍 모델이자 소프트웨어 - 프레임워크(Map과 Reduce로 구성),
-
YARN
- 스케줄러, 데이터 처리부분을 담당
-
Pig
-
하둡 에코시스템 중에서 데이터를 모델링하고 프로세싱하는 경우 가장 많이 사용하는 데이터 웨어하우징용 솔루션
-
ETL 작업 지원 언어, 야후에서 개발
-
-
Hive
-
하둡 환경에서 데이터를 다루기 위해 맵퍼와 리듀서를 연결하는 작업을 진행해 처리해야하지만 이런 작업을 SQL처럼 쉽게 사용가능하게 페이스북에서 만든 오픈소스 프로그램
-
HiveQL이라고 불리는 SQL 같은 언어를 활용해 맵리듀스의 모든 기능 지원
-
쿼리를 작성하면 자동으로 맵리듀스 작업으로 변경돼 클러스터에서 실행
-
-
scoop
-
데이터 마이그레이션
-
하둡과 정형 데이터베이스 간의 효율적인 대용량 벌크 데이터 전송을 지원하는 도구
-
외부 시스템의 데이터를 HPFS로 가져와 HBase 테이블에 삽입 가능
-
새로운 유형의 외부 데이터 소스 연동 가능(Mysql, Postgresql, Oracle ...)
-
-
spark
-
분산 시스템을 사용한 프로그래밍 환경으로 대량의 메모리를 활용하여 고속화를 실현하는 것
-
Scala라는 언어를 사용해 스크립트 작성
-
속도가 빠르고 머신러닝 라이브러리도 지원
-
실시간 스트리밍 데이터 처리 가능
-
클러스터의 데이터를 신속하고 효율적, 안정적으로 처리 가능한 도구
-
-
HBASE
- 하둡의 Nosql 데이터베이스
-
Splunk
-
실시간 데이터 처리 기술
-
대용량 로그 수집/분석 시스템
-
-
아파치 이그나이트(Apache Ignite)
-
분산 데이터 관리 시스템
-
in-memory db(메모리에 올려서 쓰는거라 속도가 빠름)
-
미국에서 하둡 대신 마니 쓴다고 함
-
EC2에서 하둡 활용
EC2 인스턴스 생성 시 운영체제를 red hat 8으로 선택
키페어는 한번 잃어버리면 다시 다운받을 수 없음. 깃허브에 올리면 뚫리므로 같이 올리지 않도록 주의 !
인스턴스 유형은 크기를 너무 작게 만들면 데이터를 다운받을 때 문제가 발생. 어느정도 필요한 크기로 만들기(또 너무 크면 비쌈, 나의 경우 t2 medium으로 생성)
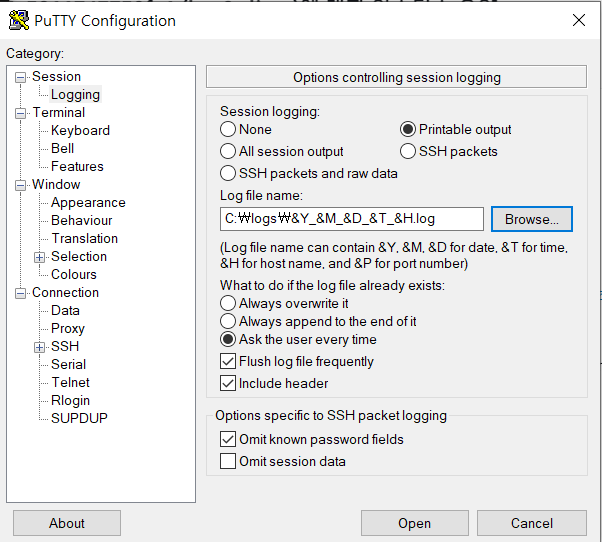
putty에서 session 설정 다음과 같이 바꿈
log file name은 다음과 같이 설정하면, 앞으로 서버에서 로그가 발생할 경우 다음과 같은 이름으로 logs 디렉터리에 파일이 저장됨
super putty.msi 다운로드
browser 선택 창이 뜨면 맨 위 - putty가 위치한 경로로 들어가서 putty 파일 선택
맨 위 바로 아래 선택 창 - 동일하게 뜨는 ppsd ?이 파일 선택
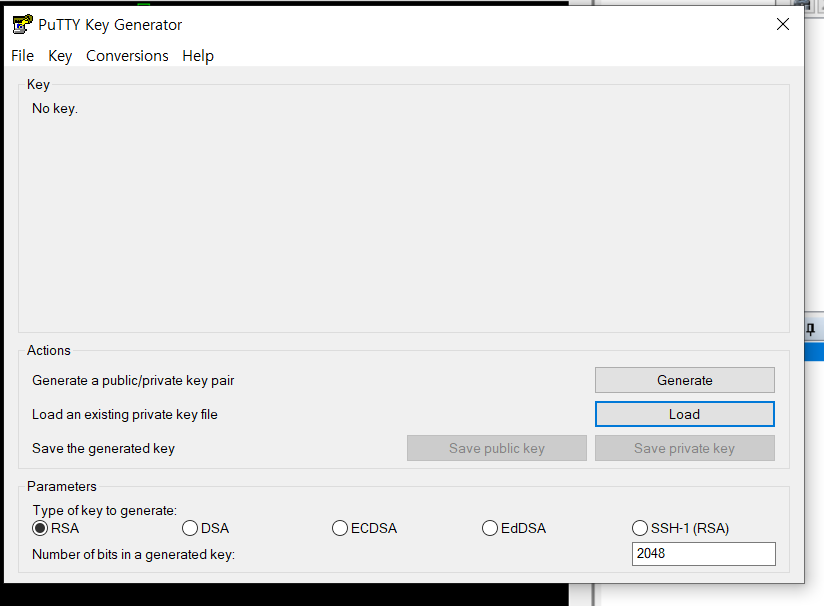
puttygen 들어가서 load -> pem 파일이 위치한 디렉터리 들어가서 변환할 pem 파일선택
- puttygen은 key가 pem 파일일 경우 ppk 파일로 바꿔서 접속가능하게 하는 것 !(mac은 pem 파일을 사용함)
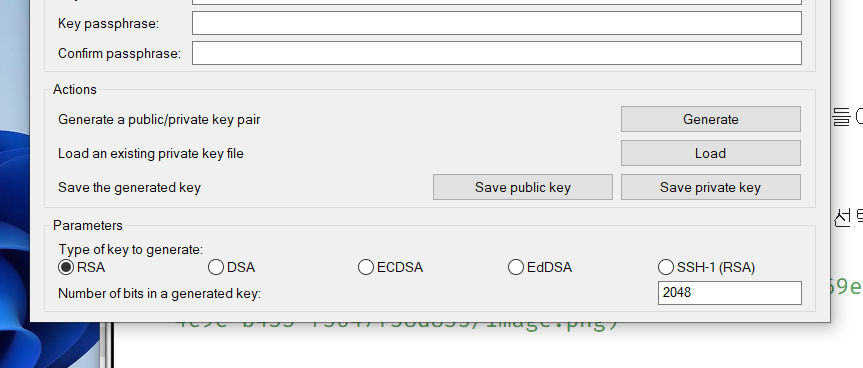
여기서 save private key 선택 !
overwrite 하면 큰일남 .... key 파일 복사본이 없을 경우 .... 서버를 삭제해야하는 불상사가 발생함 ....
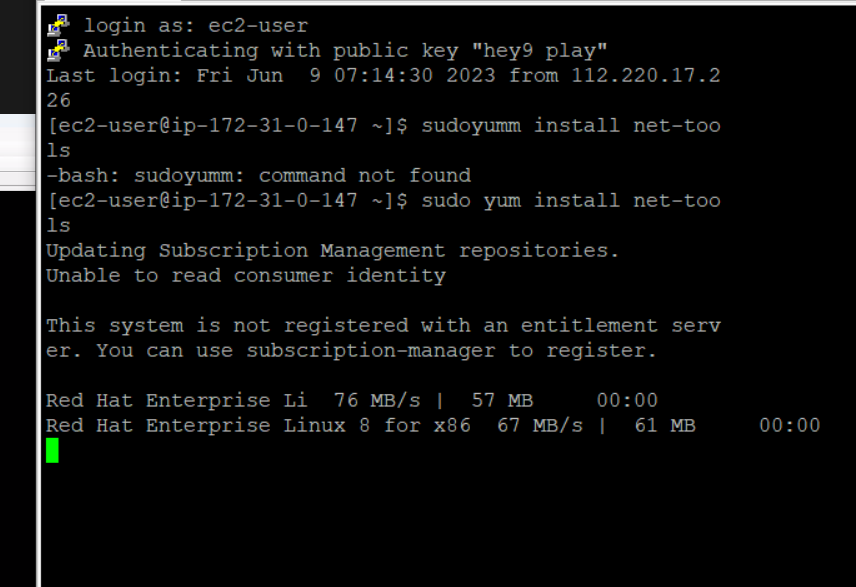
새로 생성한 ec2에서 입력할 명령어(하둡 사용을 위해)
sudo yum install net-tools
sudo yum install vim wget -y
sudo dnf install java-1.8.0-openjdk ant -y
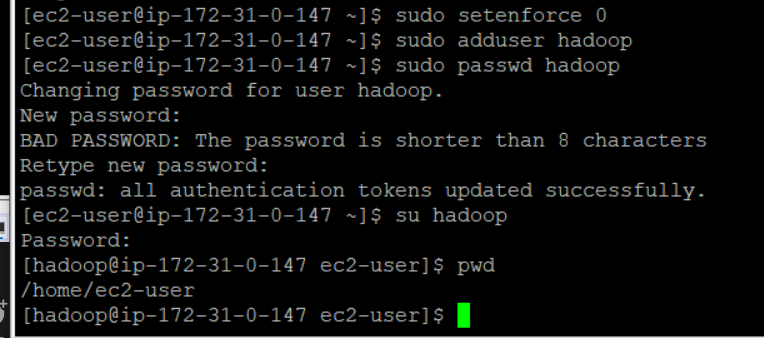
sudo setenforce 0
-> 이걸 안하면 하둡이 동작을 막게 함
sudo adduser hadoop
-> hadoop 이라는 유저 생성
sudo passwd hadoop
-> hadoop의 비밀번호 생성
su hadoop
-> hadoop 계정으로 들어감
pwd
-> 현재 위치(home/ec2-user) ec2-user 폴더에 hadoop을 생성함
다음주에 할 것 ~
cat /etc/hosts
인스턴스의 통신이 가능하게끔 ..어쩌구
