ec2 서버 -> 로컬 파일 다운
scp -i [pem파일] -r ec2-user@[서버 Public IP]:~/rawdata .
ec2 서버안에 위치한 rawdata 파일을 로컬 컴퓨터에 저장하고자 하는 명령어, 위 명령어는 로컬 프롬포트에서 입력하면 됨
-
pem 파일의 위치는 프롬포트에서 dir을 입력해서 찾기
-
서버 IP:[서버에서 가져오고자 하는 data 위치][로컬에 저장하고자 하는 위치]
Hadoop
Hadoop 서버 설정
-
이전에 만들어놓은 ec2 서버의 hadoop 계정에 sudo 권한 부여하기
-
ec2-user에서
sudo visudo입력 -
:set nu입력해서 줄번호 확인하기 -
:100입력해서 100번째 줄로 이동 -
yy로 100번째 줄 복사
-
p로 100번째 줄 붙여넣기
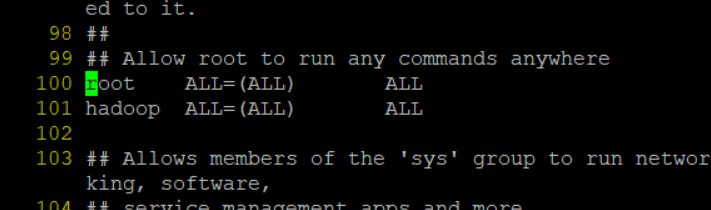
- 위와 같은 방식으로 hadoop 유저에도 root 계정과 같은 권한 부여
-
-
java bashrc에 환경변수 등록하기-
java 입력: java가 잘 설치되었는지 확인용
-
아무위치에서나
cd /usr/lib/jvm입력 -
ls입력 시 아래와 같이 목록이 뜨면 됨
hadoop@client jvm]$ ls java jre java-1.8.0 jre-1.8.0 java-1.8.0-openjdk jre-1.8.0-openjdk java-1.8.0-openjdk-1.8.0.372.b07-4.el8.x86_64 jre-1.8.0-openjdk-1.8.0.372.b07-4.el8.x86_64 java-openjdk jre-openjdk-
vim ~/.bashrc -
bashrc 파일에
export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.372.b07-4.el8.x86_64"추가 -
source ~/.bashrc -
echo $JAVA_HOME를 입력해 환경변수가 잘 지정됐는지 확인
-
-
python 3.9 설치
sudo yum install python39
-
환경변수 수정
-
vim ~/.bashrc -
별명 붙이기
- bashrc 파일 맨 아래에
alias python="python3",alias pip="pip3"입력하고:wq
- bashrc 파일 맨 아래에
-
-
hadoop 사용자 계정에 hadoop 설치(
su hadoop한 뒤 아래 명령어 실행)-
cd ~+wget https://archive.apache.org/dist/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz -
tar xvzf hadoop-3.2.1.tar.gz -
mv ./hadoop-3.2.1 ./hadoop
-
-
hadoop 보안키 설정(
su hadoop해서 hadoop 사용자로 들어간다음 실행)-
cd ~+ssh-keygen -t rsa -
cd ~/.ssh-> ssh 디렉터리 안에 key 파일이 생성된 걸 확인 -
cat id_rsa.pub >> authorized_keys파일 복붙 -
나는 write, read 가능하고 그룹은 read 가능하고 제 3자는 권한 없게 설정
chmod 640 ./authorized_keys -
cd ~/.ssh+cat id_rsa -
개인키를 복사한 것을 메모장에 붙여넣기 -> pem 파일명으로 저장 -> puttygen에서 pem을 ppk로 변환(conversions -> import key)
-
이후 이 ppk 파일을 fileziila에 등록해서 hadoop 계정의 저장소를 열어볼 수 있게 하기가 가능(이때 ip는 client 서버의 public ip)
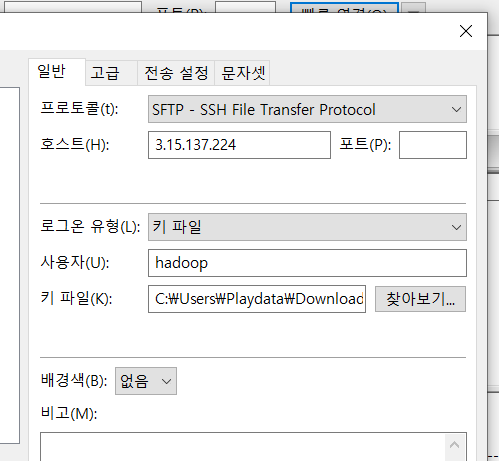
-
-
fileziila를 통해서 강사님이 업로드 해주신 파일들(인프라-하둡)을
hadoop 사용자의 hadoop/etc/hadoop으로 옮김- 파일들 목록

- 옮긴 이후 filezilla
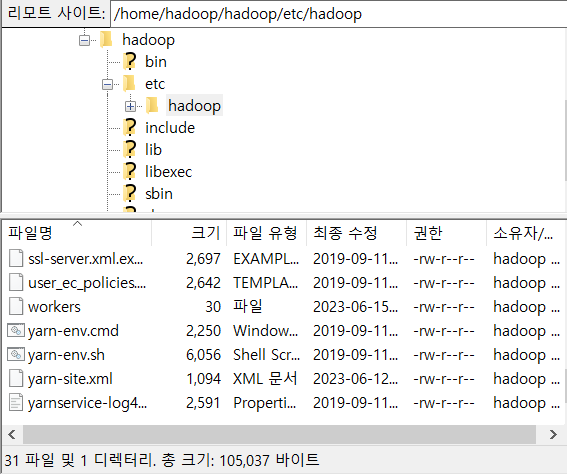
- 파일들 목록
- bashrc 파일 환경변수 추가
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HIVE_HOME/bin- 서버 중지
sudo shutdown -h now
hadoop 서버 이미지 생성
-
ec2 인스턴스 선택 -> 작업 -> 이미지 및 템플릿 -> 이미지 생성
이미지를 만들면 지금까지의 작업이 완료된 인스턴스를 언제나 복제할 수 있게끔 할 수 있음 -
하둡은 병렬처리이므로 다른 세대의 컴퓨터에도 위와 같은 전처리 작업을 해야함
-
이미지를 생성함으로써(복제본을 뜸) 병렬처리가 가능하게 하고자 함
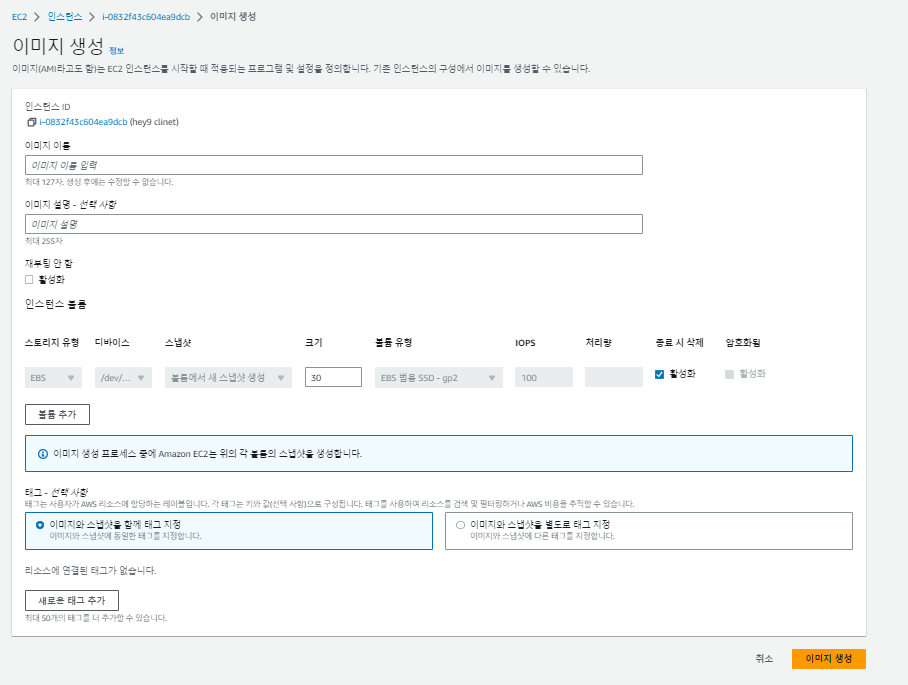
이미지 이름만 입력하고 이미지 생성 !
-
이미지 생성 후 -> 이미지:AMI 선택 -> 생성된 이미지 볼 수 있음
-
또는 이미지 생성 후 -> 해당 인스턴스 선택 -> 세부정보에서도 생성된 이미지 볼 수 있음
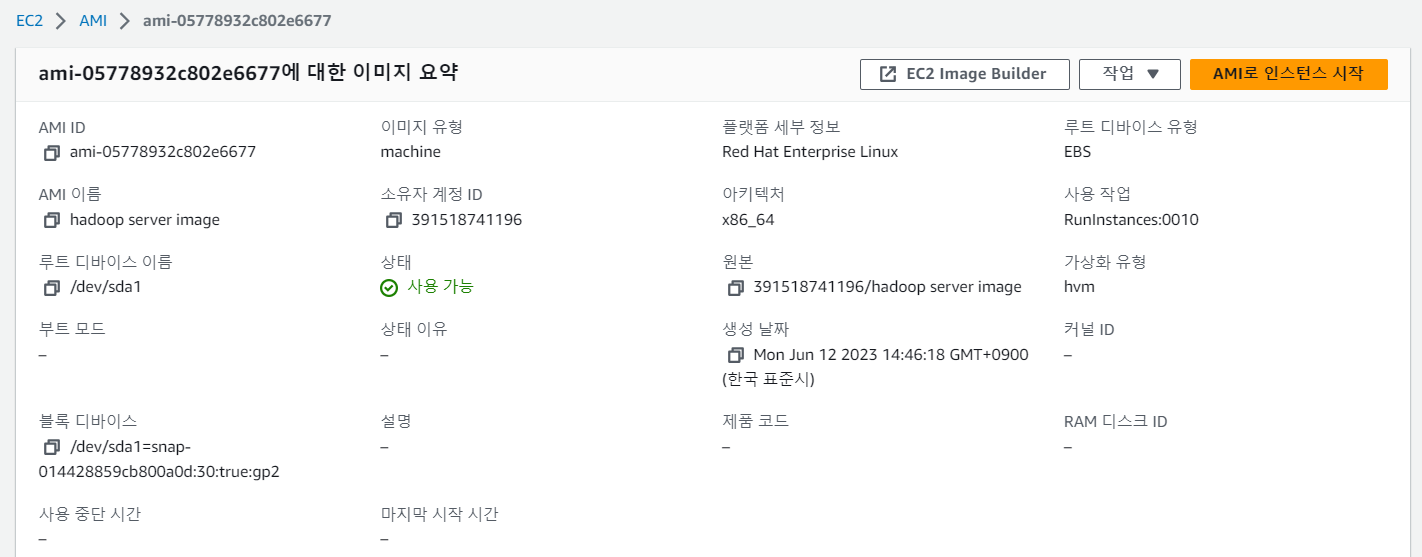
이미지를 기반으로 인스턴스 생성
-
이미지:ami -> ami로 인스턴스 생성 -> 3개의 인스턴스를 동일한 조건으로 생성
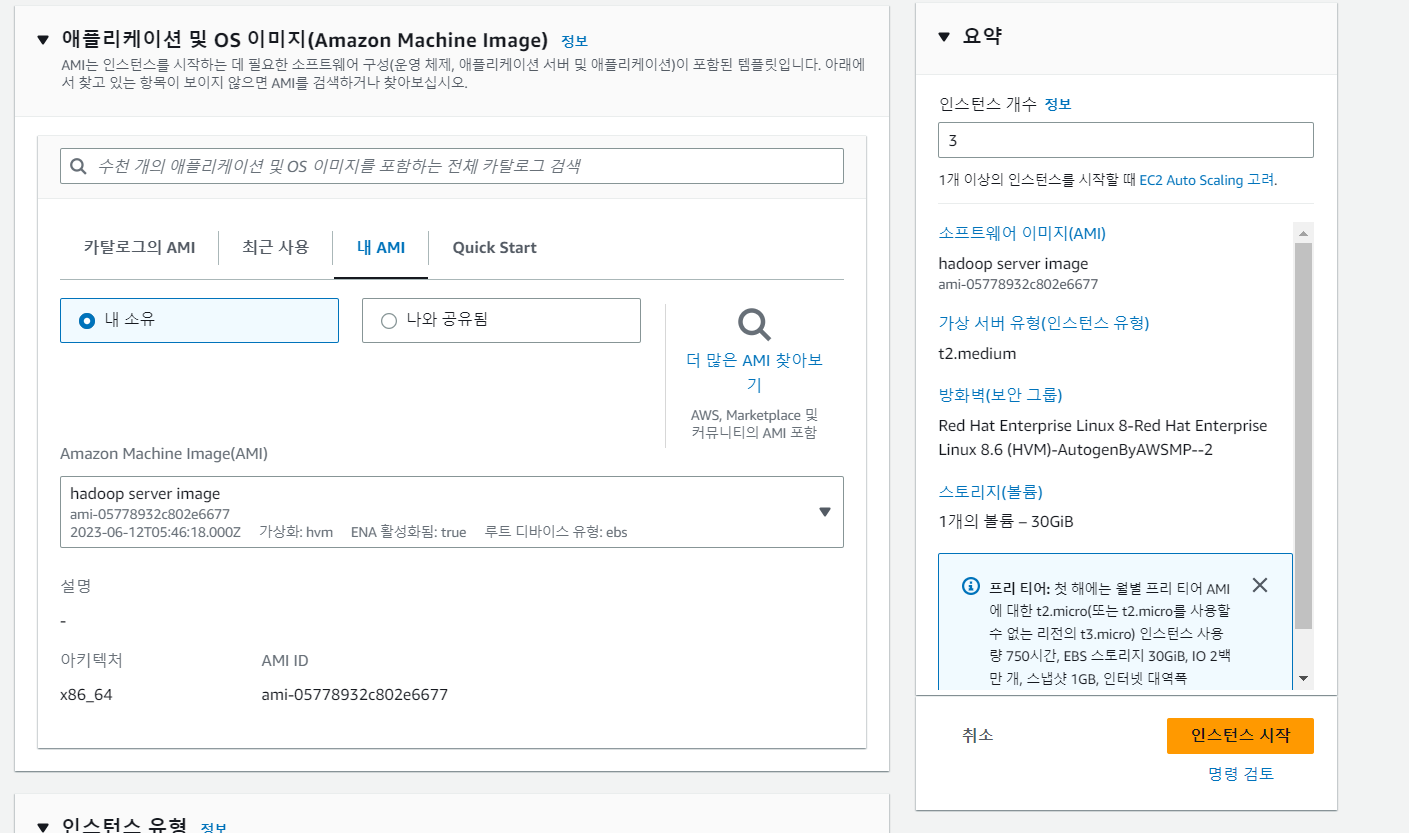
-
기존 인스턴스 포함 인스턴스가 4개 생성된 걸 볼 수 있음 !
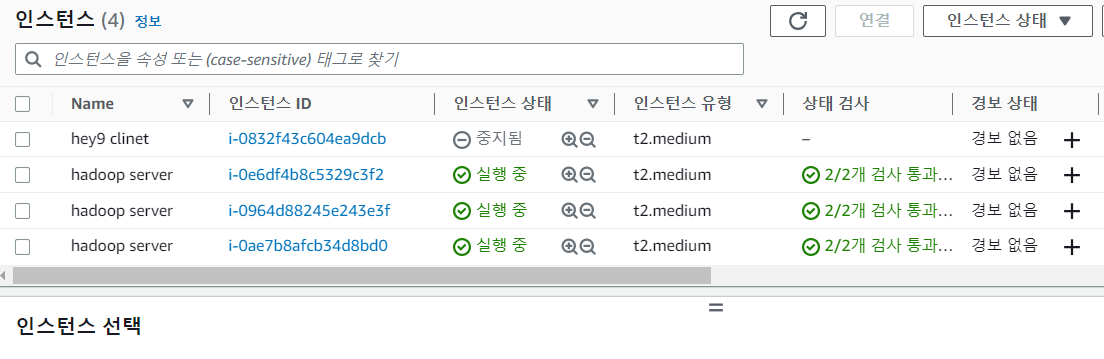
탄력적 IP 연결
-
인스턴스를 중지하고 재실행할때마다 퍼플릭 IP 주소가 변경됨. 따라서 탄력적 IP를 발급받아 해당 인스턴스에 지정해주면 서버를 중지 및 재실행 해도 IP주소가 변경되지 않아 putty에서 접속할때마다 편함 !
-
네트워크 및 보안: 탄력적 IP -> 탄력적 IP 주소 할당 -> 작업 -> 탄력적 IP 주소 연결 -> 해당 인스턴스 선택
-
이 경우 탄력적 IP는 1:1 매핑 ! 그래서 다른 인스턴스들도 탄력적 IP를 연결하고 싶다면 총 4개의 탄력적 IP를 발급받아야 함
-
하지만 client 서버를 제외한 나머지 3개의 서버는 public IP가 필요하지 않음. client 서버에서 나머지 3개의 서버에 접속해서 운영할 것이기 때문. 나머지 3개의 서버는 private IP만 있으면 됨.
-
client 서버에 private IP 연결
-
타 서버에 접속하는 명령어는
ssh privateIP -
client 서버에서 다른 서버에 접속하면
.ssh폴더 안에 known_hosts라는 파일이 생성됨
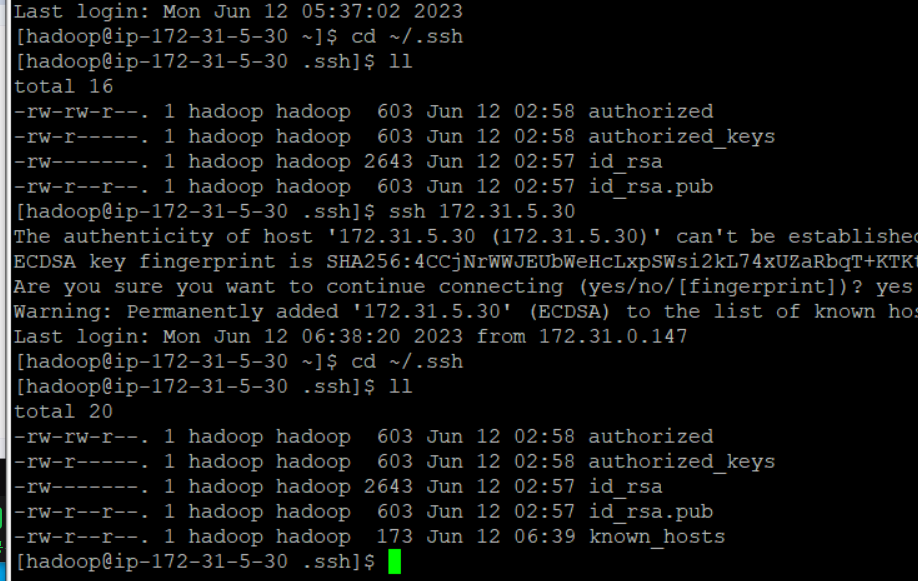
-
다른 서버에 접속할때마다 IP가 아닌 별칭으로 접속가능하게 설정
-
sudo vi /etc/hosts명령어 입력, 내부 파일을 아래와 같이 수정 후:wq -
이때 타 서버의 IP는 private IP
-
네 개의 모든 서버에
etc/hosts를 수정해주어야 함
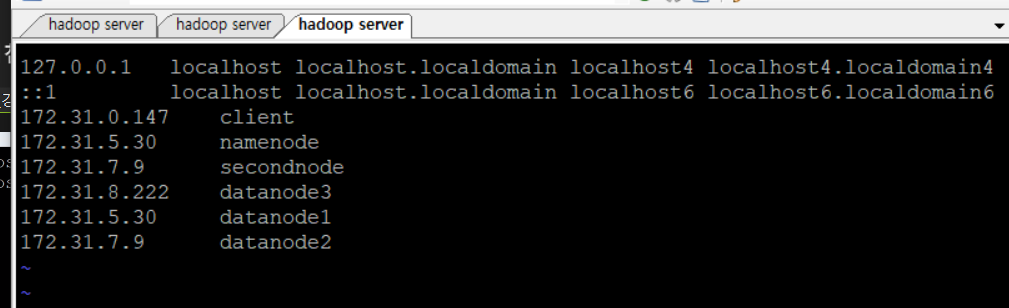
-
한번 해당 서버에 접속하고 나서 yes 를 입력하면 앞으로 별칭이나 IP를 입력해서 접속할때에는 yes/no를 물어보지 않는다.
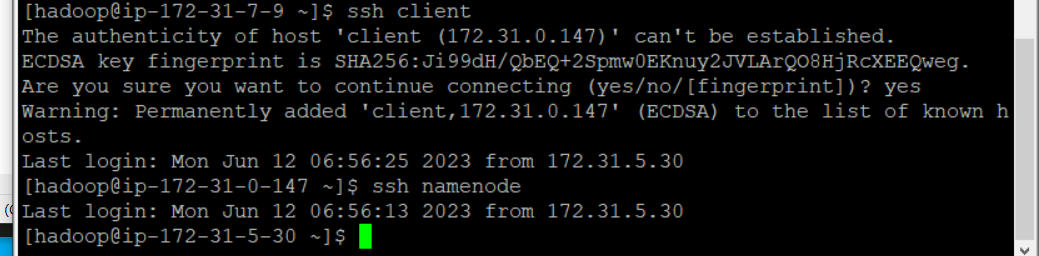
-
-
w는 세션 정보 확인 -
해당 서버에 접속하면 바로 알아챌 수 있도록 서버의 이름을 hadoop@ip-privateIP가 아닌 별칭과 동일하게 변경
-
sudo hostnamectl set-hostname namenode -
그럼 다음과 같이 exit 했다가 다시 접속하면 이름이 namenode로 변경됨
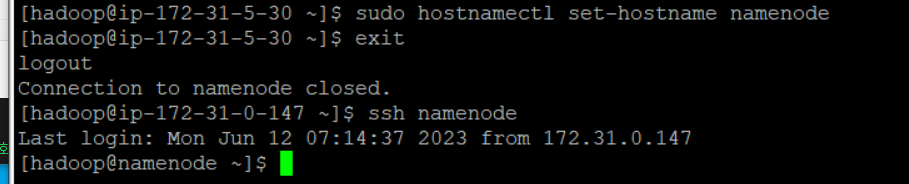
-
4개의 서버 모두 hostname을 변경 완료한 걸 볼 수 있다 !

-
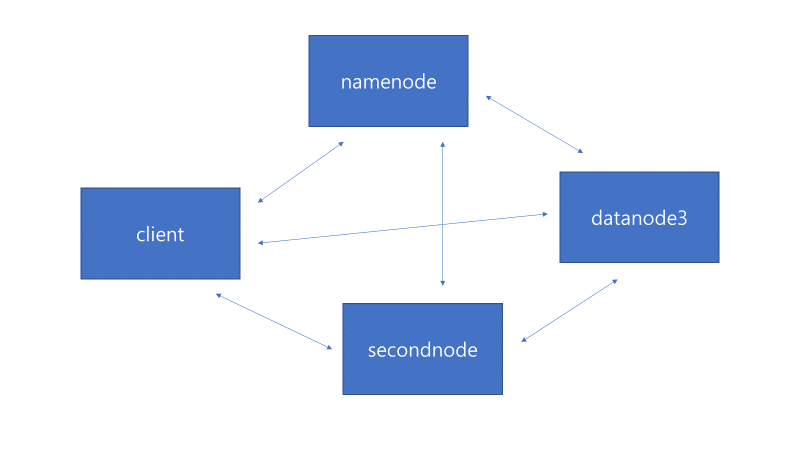
하둡 병렬처리를 위한 서버 연결 상태 도식화