추천 시스템
6월 7일 수업 이어서 진행
추천 시스템(Recommendations)의 개요와 배경
-
추천 시스템이란 사용자의 과거 행동 데이터나 다른 데이터를 바탕으로 사용자에게 필요한 정보나 제품을 골라서 제시해 주는 시스템
-
집단의 크기를 극단적으로 줄이면 각 집단이 한 사람이 되고, 이렇게 각 사용자별로 맞춤형 추천과 서비스를 제공하는 것을 개인화(personalization)이라고 한다.
-
추천 시스템을 통해 사용자의 취향을 이해하고 맞춤 상품과 콘텐츠를 제공해 조금이라도 오래 자기 사이트에 고객을 머무르게 하기 위해 전력을 기울이고 있음
추천 시스템 유형
-
아이템 기반
-
유저 기반
-
잠재요인 기반(딥러닝 적용): 넷플릭스가 아마도 이 시스템을 사용중 !
-> 잠재요인은 다음주 수업 때 할 예정 ~
콘텐츠 기반 필터링
- 사용자가 특정 장르나 배우에 점수를 많이 주면 이것들을 활용해서 사용자에게 유사한 영화를 추천해줌(유튜브)
- 장르, 출연배우, 감독, 영화 키워드 등의 콘텐츠와 유사한 다른 영화를 추천해주는 방식
협업 필터링(Collaborative Filtering:CF)
- 소비자의 평가를 받아서 패턴이 비슷한 소비자를 한 집단으로 보고 그 집단에 속한 소비자들의 취향을 활용하는 기술
- 장점
- 이 기술은 사람들의 취향이 뚜렷이 구분되는 제품을 추천할 때 더욱 정확하다고 알려져 있음
- 한계점
- 소비자들의 평가 정보를 구하기 어려울 수도 있음
- 이러한 한계를 극복하기 위해서 간접적인 정보(검색량, 장바구니)를 사용하는 경우가 많음
- 이러한 정보가 온라인에서는 클릭스트림 형태로 수집되기 때문에 클릭스트림의 분석을 통해서 소비자의 취향이나 니즈를 알아낼 수 있음
-> 스트리밍 데이터를 활용하기 위해 카프카 활용 - 협업 필터링의 가장 대표적인 예가 아마존의 제품 추천, 넷플릭스의 영화 추천
최근접 이웃(Nearest Neightbor)
- 사용자가 아이템에 매긴 평점 정보, 상품 구매 이력 등 사용자 행동 양식만들 기반으로 추천하는 것이 협업 필터링
- 협업 필터링은 사용자-아이템 평점 매트릭스와 같은 축적된 사용자 행동 데이터를 기반으로 사용자가 아직 평가하지 않은 아이템을 예측 평가
내용 기반 필터링(Content-Based filtering:CB)
-
내용 기반 필터링이란 제품의 내용을 분석해서 추천하는 기술
-
특히 소비자가 소비하는 제품 중 텍스트 정보가 많은 제품(예를 들어 뉴스나 책 등)을 분석하여 추천할 때 많이 이용되는 기술
- 텍스트 중에서 핵심 키워드가 어떤 것인지를 분석하는 기술이 기본적인 기술
- 예를 들어서 어떤 소비자가 현재 관심이 있는 것으로 보이는 책이나 뉴스가 있다면 그 책과 뉴스의 키워드를 추려내고 다른 책이나 뉴스 중에서 비슷한 키워드를 가진 것들을 찾아내서 화면의 상단에 보여주면 소비자가 이들을 클릭해서 볼 가능성이 높을 것
지식 기반 필터링(Knowledge-Based filtering: KB)
-
협업 필터링과 내용 기반 필터링의 공통적인 단점은 전체적인 그림이 없다는 것
-
어떤 소비자가 어떤 제품을 좋아할지에 대한 분석은 가능하지만 "왜 그 제품을 좋아할 것인가?"에 대해서는 답을 해줄 수 없음
-
지식 기반 필터링은 특정 분야 전문가의 도움을 받아서 그 분야에 대한 전체적인 지식구조를 만들어서 이를 활용하는 방법
-
전체적인 지식구조는 다양한 형태로 표현될 수 있다. 그 분야의 중요한 개념을 가지고 체계도(ontology)를 만드는 것이 가장 일반적인 방법
-
예를 들어 컴퓨터라는 제품 분야에서는 가장 중요한 상위 분류가 PC, 노트북, 태블릿 이 될 것이며 전문가는 이들 각각에 대해서 그 밑에 어떤 것들이 있고, 다시 그 밑에는 어떤 것들이 있는지를 제시할 수 있을 것임
-
이렇게 작성된 체계도를 바탕으로 소비자가 구매한, 혹은 관심이 있는 제품과 관련이 있는 제품을 이 체계도에서 찾아서 제시할 수 있음
-
장점
- 전제적인 구조를 알 수 있다는 점
- 교육, 와인, 커피처럼 지식이 중요한 분야에서 효과가 좋다는 점
-
한계점
- 각 분야에 대해서 전문가가 필요
- 전문가의 능력에는 한계가 있기 때문에 모든 세세한 분야에 다 적용할 수 없다는 점
잠재 요인(Latent Factor) 협업 필터링
-> 다음주에 수업 !
Matrix Factorization(MF) 기반 추천
-
추천을 위한 다양한 알고리즘 분류를 하면 메모리 기반과 모델 기반으로 나눠짐
-
메모리 기반 알고리즘이란 추천을 위한 데이터를 모두 메모리에 가지고 있으면서 추천이 필요할 때마다 이 데이터를 사용해서 계산을 해 추천하는 방식
- CF는 대표적인 메모리 기반 알고리즘
-
모델 기반 추천은 데이터로부터 추천을 위한 모델을 구성한 후에 이 모델만 저장하고, 실제 추천을 할땐 이 모델을 사용해서 추천을 하는 방식
-
행렬 요인화(MF)방식이 대표적인 모델 기반 추천 알고리즘
-
Deep-learning 방식의 추천도 데이터는 신경망 학습에 사용되고 예측은 학습된 신경망을 가지고 한다는 점에서 모델 기반 추천 알고리즘이라 할 수 있음
-
MF 방식의 원리
-
행렬 요인화(MF)는 평가 데이터, 즉 사용자X아이템으로 구성된 하나의 행렬을 2개의 행렬로 분해하는 방법
-
앞서 CF에서 활용한 사용자X아이템 matrix 형태의 2차원 행렬
-
아래 그림과 같이 사용자 잠재요인 행렬과 아이템 잠재요인 행렬로 나눌 수 있음
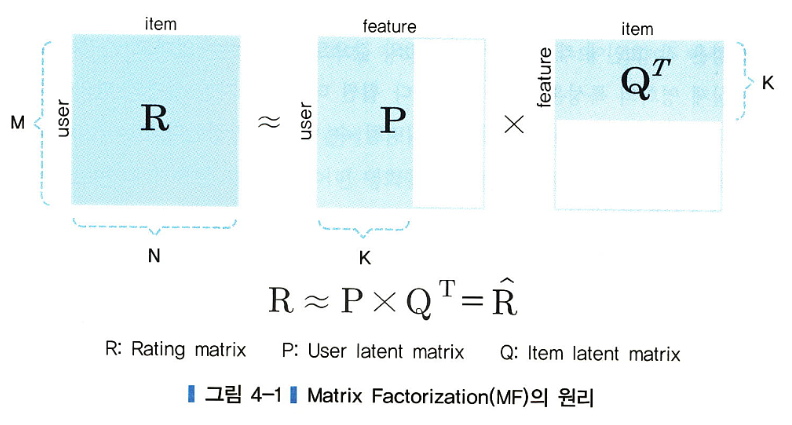
- 여기서 R은 사용자X아이템 평가 데이터, 이 R행렬을 사용자 행렬(R)과 아이템 행렬(Q)로 쪼개어 분석하는 것이 MF 방식, R^은 R의 예측치이고 R^이 R에 가까운 값을 가지도록 하는 P와 Q를 구하면 그것이 바로 추천을 위한 모델인 것 !
MF 예시
-
위 예시에서는 k = 2(잠재요인이 2개) = 영화의 특성을 두 개 요인으로 나타낼 수 있음
-
두 요인의 차원이 (액션-드라마), (판타지-사실주의)이고 모든 사용자와 영화의 특성은 각 요인에 대해 -1.0~1.0 값으로 표현할 수 있다고 가정한다면 P와 Q 행렬의 예시


- 위의 두 행렬을 다시 2가지 요인의 값에 따라 2차원 공간에 그림으로 배치할 경우 다음과 같음

- MF의 원리인 R^ = P X Q^T이므로 R^을 계산하면 아래와 같음
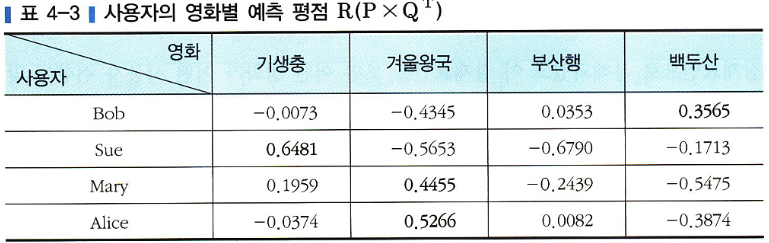
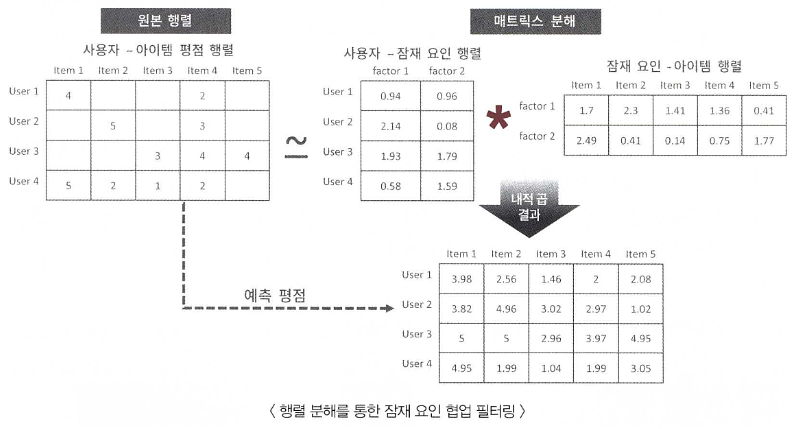
MF에서 행렬 분해의 경우
-
행렬 분해는 다차원의 매트릭스를 저차원 매트릭스로 분해하는 기법으로 대표적으로 SVD(Singular Vector Decomposition), NMF(Non-Negative Matrix Factorization) 등이 있음
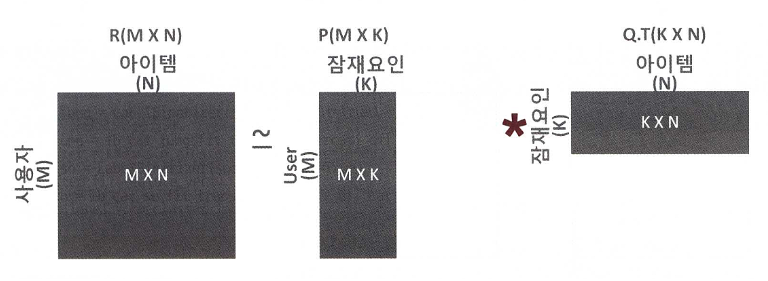
-
행렬 분해에는 주로 SVD 방식을 이용하지만 Null 값이 많을 경우 확률적 경사 하강법이나 ALS 방식을 이용해 수행
