
Hive 활용
자바 코딩으로 집계하는게 아니라 sql쿼리를 만들면 집계를 해주는 hive를 사용
Hive를 통해 따로 데이터베이스를 만들지도 않았는데 데이터를 집계가능하게 해줌
-
su hadoop -
강사님이 올려주신 S3 data를 다운로드
wget https://mydatahive.s3.ap-northeast-2.amazonaws.com/tmdb.zip
-
unzip 설치
sudo yum install unzip
-
디렉토리 생성하고 파일 압축 풀기
mkdir tmdb && unzip ./tmdb.zip -d ./tmdb

-
하둡 사용
hdfs dfs -mkdir /tmdbcd tmdbhdfs dfs -put ./*.csv /tmdb
-
Hive 실행
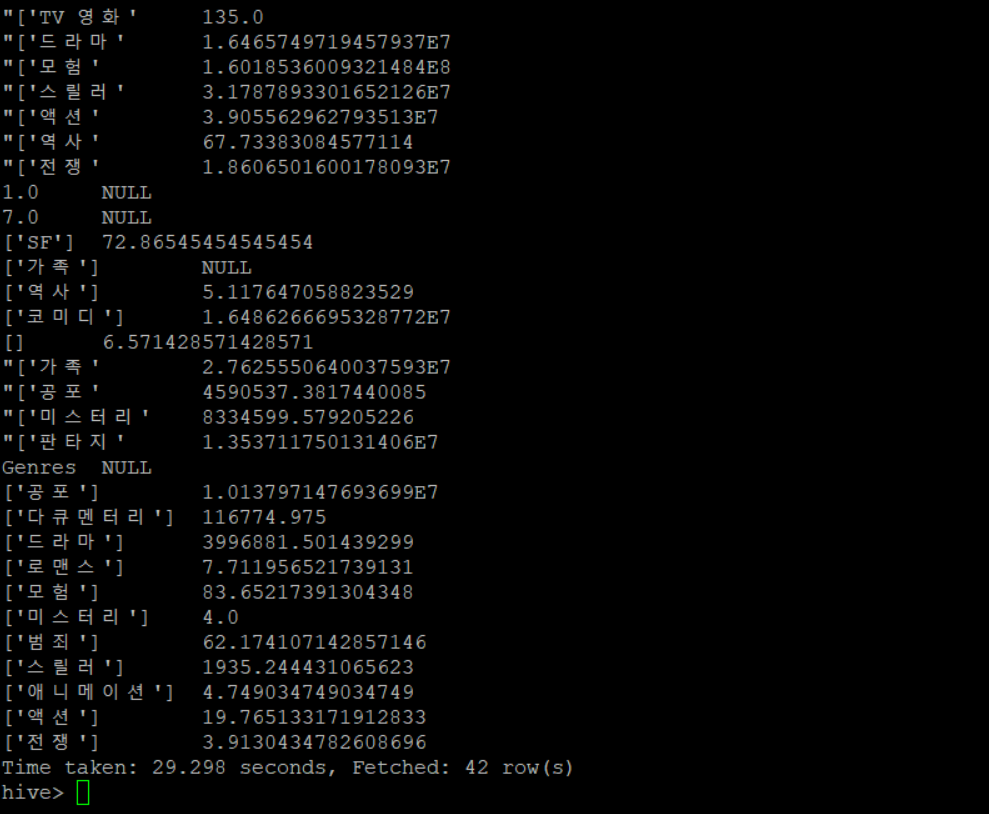
hiveCREATE EXTERNAL TABLE IF NOT EXISTS movie( Movie_ID STRING, Adult STRING, Backdrop_Path STRING, Genres STRING, Homepage STRING, Original_Language STRING, Original_Title STRING, Overview STRING, Popularity STRING, Poster_Path STRING, Production_Companies STRING, Production_Countries STRING, Release_Date STRING, Revenue STRING, Runtime STRING, Spoken_Languages STRING, Status STRING, Tagline STRING, Title STRING, Vote_Average FLOAT, Vote_Count INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION '/tmdb' ;SELECT * FROM movie limit 5;SELECT Genres , AVG(Vote_Count) FROM movie GROUP BY Genres
spark 시작
-
spark 설치하기
wget https://dlcdn.apache.org/spark/spark-3.2.4/spark-3.2.4-bin-hadoop3.2.tgz
tar xzf spark-3.2.4-bin-hadoop3.2.tgzmv ./spark-3.2.4-bin-hadoop3.2 ./spark
-
Parquet 파일 = 엄청 대용량 파일
-
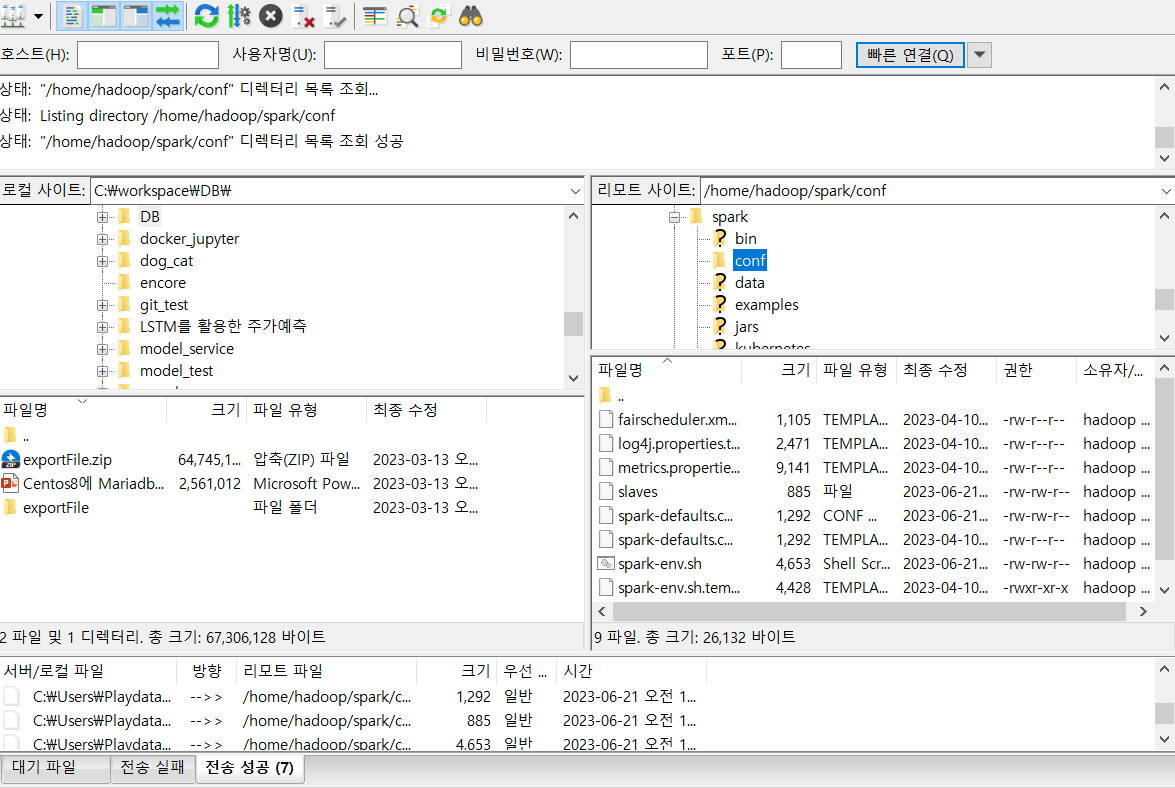
/home/hadoop/spark/conf이 위치에 강사님이 올려주신 파일 3개 업로드 -
-
환경변수 수정
vim ~/.bashrcexport SPARK_HOME="/home/hadoop/spark"export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin

source ~/.bashrc
-
spark 실행
pyspark- 만약 python3로 인해 permission dinied가 뜬다면
sudo yum install python39를 통해 파이썬을 다운로드
-
jupyter notebook 설치
pip install jupyterjupyter notebook --generate-config
-
jupyter notebook 접속
ipython
-
접속할때 사용할 비밀번호 설정
from notebook.auth import passwdpasswd()설정하고 out되는 값 복사해서 메모장에 적어놓기
-
jupyter/jupyter_notebook_config 파일 수정
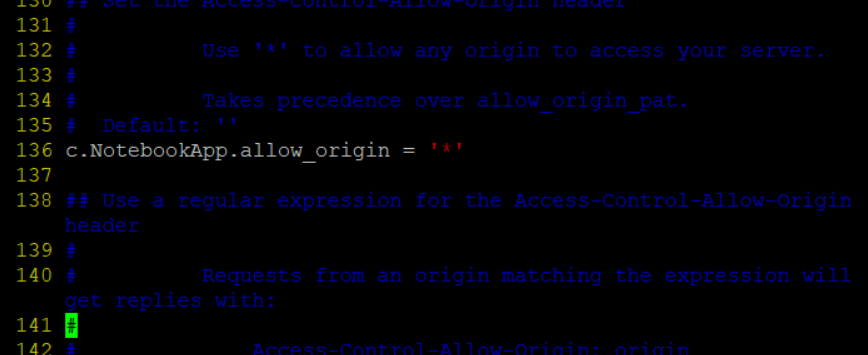
vim /home/hadoop/.jupyter/jupyter_notebook_config.py
136. c.NotebookApp.allow_origin = '*' 458. c.NotebookApp.open_browser = False 469. c.NotebookApp.password = '아까 메모장에 복사한 내용' 450.c.NotebookApp.notebook_dir = '/home/hadoop/workspace'- 수정할때는
set nu하고 해당 번호 찾아서 수정(아래 사진처럼)
-
환경변수 수정
vim ~/.bashrcexport PYSPARK_DRIVER_PYTHON=jupyterexport PYSPARK_DRIVER_PYTHON_OPTS='notebook --ip=0.0.0.0'
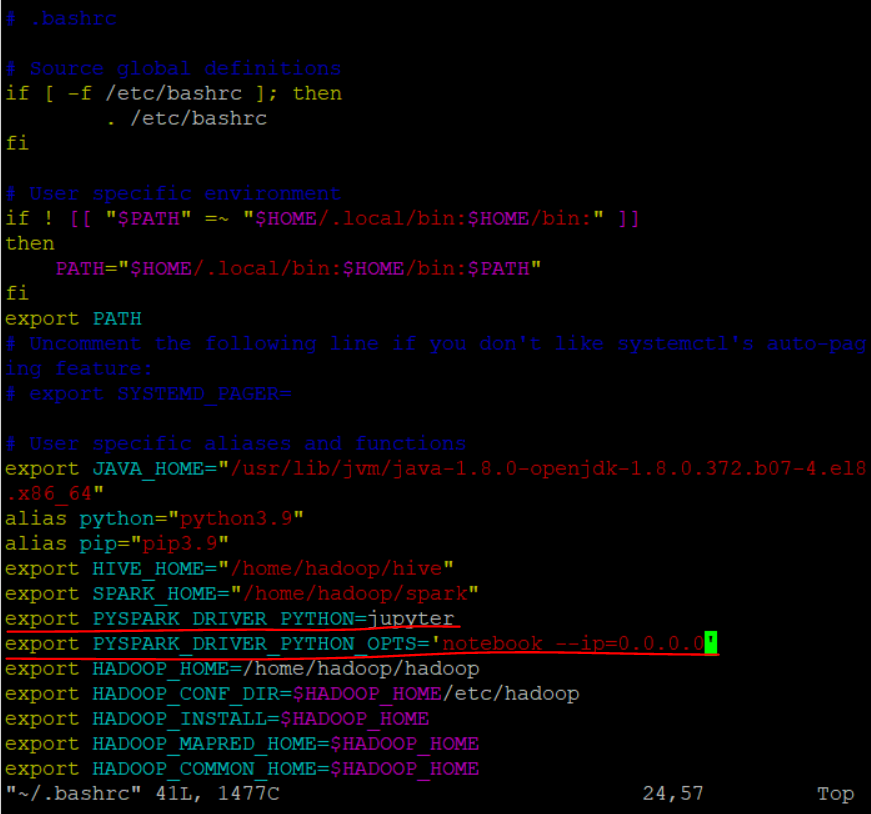
source ~/.bashrc
-
spark 작업할 폴더 만들기
mkdir ~/workspace
-
apache spark 서버 실행
pyspark --master yarn --num-executors 3- 주소창에
client:8888입력
- 앞서 내가 지정한 password 입력
-
앞서 만든
home/hadoop/workspace에 강사님이 올려주신 파일 업로드(filezilla)
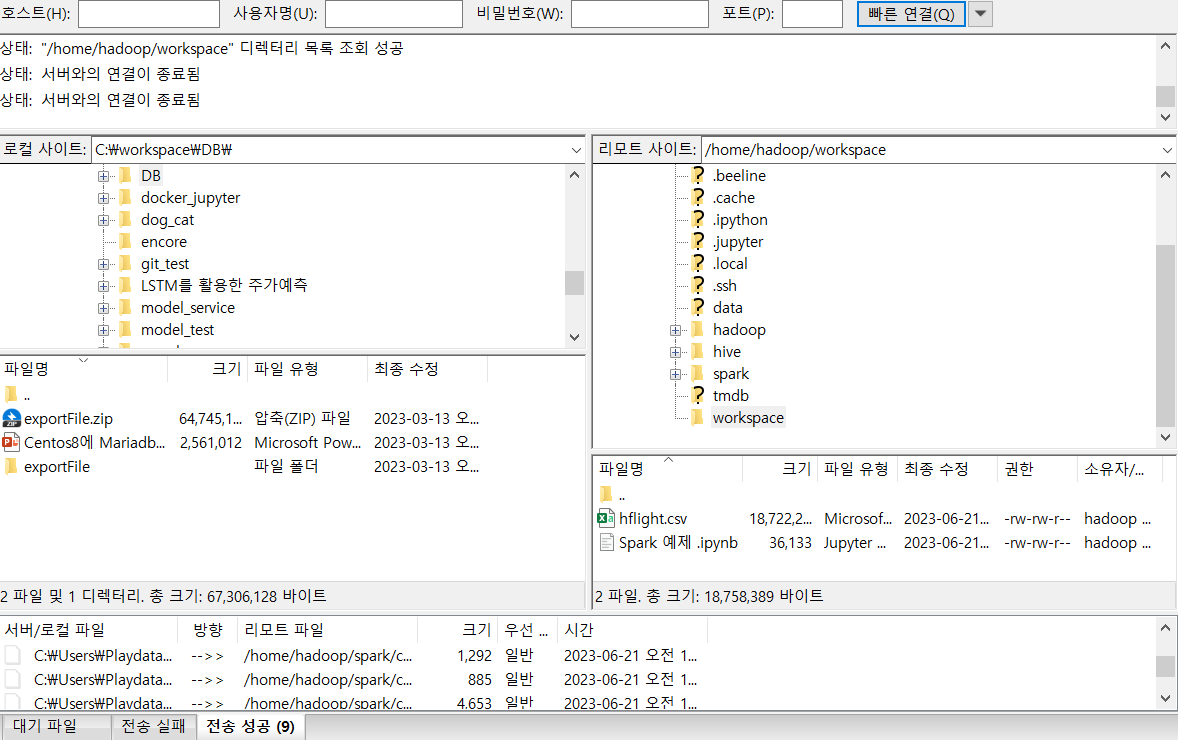
- 그럼 이제 jupyter notebook 서버를 다시 확인해보면 파일이 제대로 들어가 있는 걸 확인할 수 있음 !
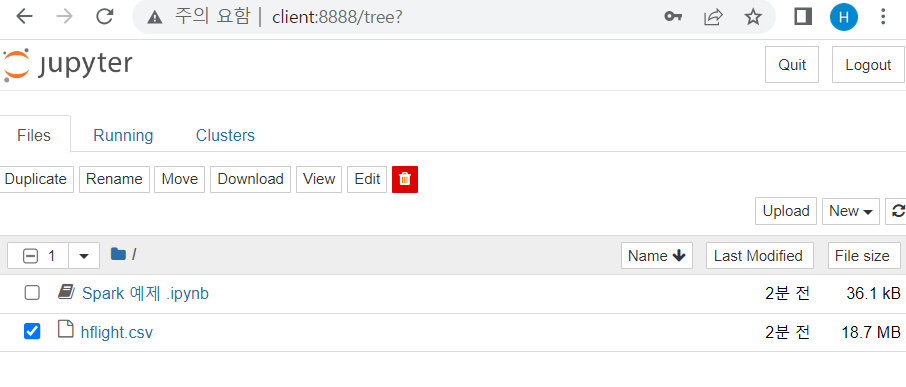
-
하둡에서 저장할 폴더 만들기
hdfs dfs -mkdir /hflight
-
하둡으로 데이터 파일 업로드
- 데이터가 존재한 worksapce 로 이동
cd ~/workspace hdfs dfs -put hflight.csv /hflight
- 데이터가 존재한 worksapce 로 이동
-
데이터가 잘 업로드 됐는지 확인
namenode IP:50070에서browse directory확인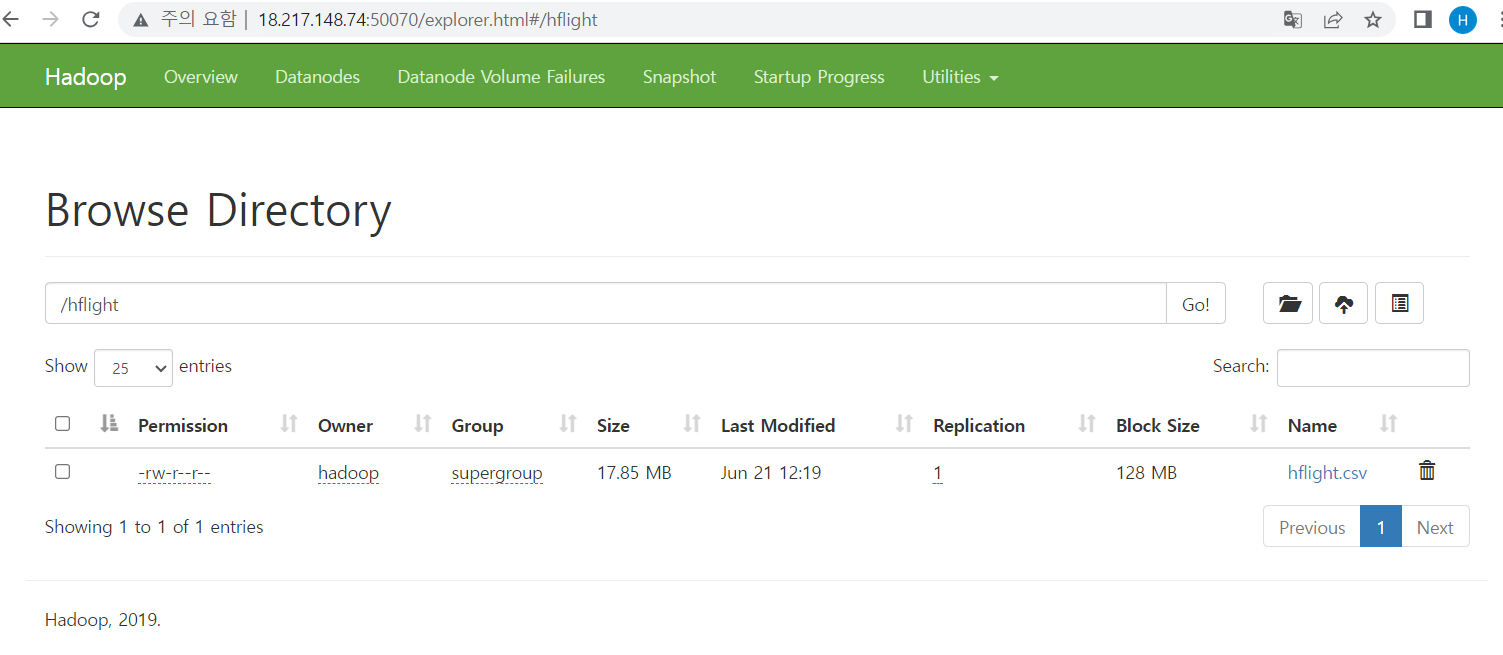

spark 분석 실행
-
notebook에서 spark 분석을 실행할때는 항상 시작할때
from pyspark.sql import SparkSession명령어를 실행 -
하둡에 올린 데이터를 불러올때는
df = spark.read.option("inferSchema", "true").option("header", "true").csv("/hflight/hflight.csv")이런식으로 경로는 위에서hdfs dsf -mkdir을 사용해 만든 파일로 설정해야 함 -
함수를 불러올때는
from pyspark.sql.functions import sum, count, avg, expr, col, when와 같이 from pyspark.sql.funcions 라이브러리를 가져와서 import함
