
spark 실습
-
데이터 다운로드
cd ~wget https://mydatahive.s3.ap-northeast-2.amazonaws.com/mnm_dataset.csv
-
hdfs dfs 별명 붙이기
vim ~/.bashrcalias hd="hdfs dfs"추가

source ~/.bashrc
-
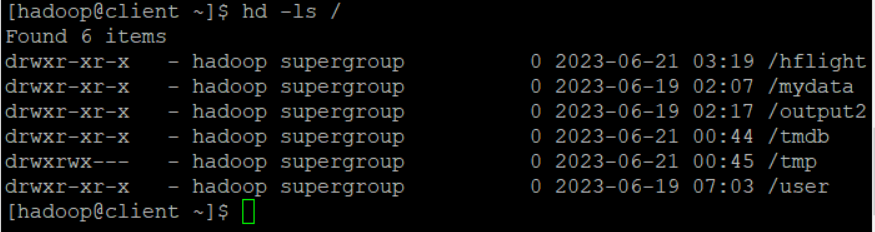
하둡에 생성된 폴더 확인
hd -ls /
-
하둡에 데이터 넣기
hd -put mnm_dataset.csv /mydata/
-
jupyter notebook 키기
pyspark- 주소창에
client:8888입력
-
jupyter notebook에 입력
from pyspark.sql import SparkSessionmnm_df = spark \ .read \ .format("csv") \ .option("header", "true") \ .option("inferSchema", 'true') \ .load("/mydata/mnm_dataset.csv")mnm_df.show(n=5)

count_mnm_df = mnm_df.select("State", "Color", "Count").groupBy("State", "Color").sum("Count").orderBy("sum(Count)")count_mnm_df = mnm_df.select("State", "Color", "Count")\ .groupBy("State", "Color")\ .sum("Count")\ .orderBy("sum(Count)")count_mnm_df.show()
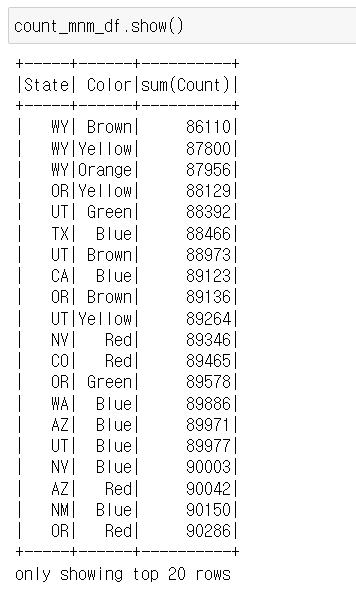
ca_count_mnm_df = mnm_df.select("*")\ .where(mnm_df.State == 'CA')\ .groupBy("State", "Color")\ .sum("Count")\ .orderBy("sum(Count)")ca_count_mnm_df.show()


공부합시당