LSTM & GRU 셀
버퍼 오버플로우: 컴퓨터가 처리 가능한 용량을 넘어서 컴퓨터가 바보가 됨
순환신경망은 그레디언트 소실문제 발생 -> LSTM 구조를 사용하자 !
: 결과값에서 그레디언트 값이 점점 줄어드는 문제를 방지하고자 함
단기기억을 오래 기억하기 위해 고안 (Long Short-Term Memory) = LSTM
입력 -> 시그모이드 함수를 거친 값이 은닉층으로 + tanh 거친 값이 다시 은닉층으로(시그모이드 활성화 함수 사용)
은닉상태 말고 셀상태(cell state)가 존재
은닉상태와 달리 셀상태는 다음층으로 전달 X 안에서만 계속 순환
배치 사이즈(=숟가락 크기라고 생각하면 됨) 클수록 메모리를 많이 먹음, 배치사이즈에 따라 모델의 성능이 바뀜. 하이퍼파라미터(⬅학습 중 수정 필요)
배치사이즈가 클수록 빠름
배치사이즈가 작을수록 느림
데이터가 적은 추론같은 경우는 CPU로 돌리기 GPU로 할 필요 없음 !
GPU메모리는 하나의 프로세스가 사용중이면 다른데서 쓸 수 없음 !
collback 함수 - 체크포인트
GRU 셀 -> 2개의 시그모이드 함수 , LSTM을 간소화한 버전
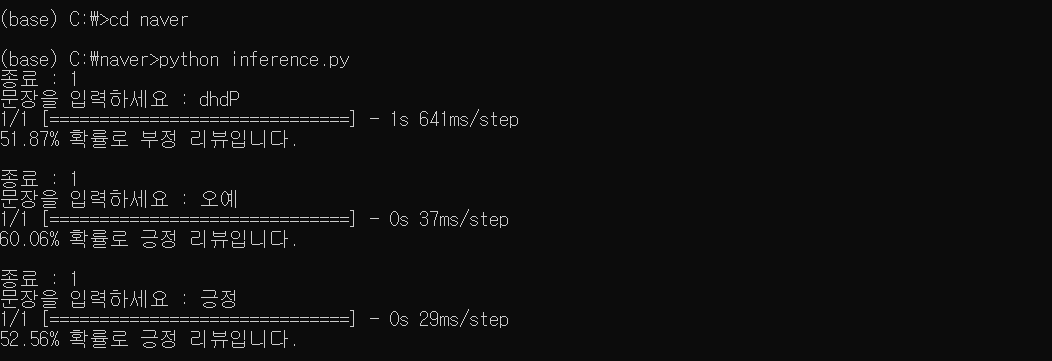
한글 형태소 분석을 통한 감성분석(LSTM 활용)
강사님께서 올려주신 LSTM_네이버 영화리뷰_감성분석 파일 참고하기 !
강사님이 공유폴더에 올려주신 머신러닝-딥러닝-네이버파일(저장해서 c드라이브에 naver라는 이름으로 옮기기)
이후 프롬포트에서 실행 !
sql 문제 풀이
하이디sql을 키고 수업내용에 강사님이 올려주신 instacart 테이블에 접속해서 다섯문제 풀기 !
- 6번(첫 구매 후 다음 구매까지 걸린 평균 일수)
SELECT c.product_name, b.product_id, a.order_id, AVG(a.days_since_prior_order) FROM orders a LEFT JOIN order_products__prior b USING (order_id) LEFT JOIN products c USING (product_id) WHERE order_number =2 GROUP BY a.order_id;
- 7번(주문 건당 평균 구매 상품 수)
SELECT (COUNT(product_id)/COUNT(distinct(order_id))) AS UPT FROM order_products__prior;
- 8번(인당 평균 주문 건수)
SELECT (COUNT(distinct(order_id))/COUNT(distinct(user_id))) AS 인당주문건수 FROM orders;
- 9번(재구매율이 가장 높은 상품 10개)
SELECT b.product_name, a.product_id, (SUM(a.reordered)/COUNT(a.reordered)) AS 재구매율 FROM order_products__prior a LEFT JOIN products b USING (product_id) GROUP BY a.product_id ORDER BY 3 desc LIMIT 10;
- 9번(강사님 답변)
SELECT * FROM (SELECT *, ROW_NUMBER() over(ORDER BY ret_ratio DESC) rnk FROM (SELECT product_id, SUM(reordered) / COUNT(*) ret_ratio FROM order_products__prior GROUP BY product_id) A ) B WHERE rnk <= 10;
- 10번(Department별 재구매율이 가장 높은 상품 10개)
SELECT * FROM (SELECT *, ROW_NUMBER() OVER(PARTITION BY department ORDER BY 재구매율 DESC) rnk FROM (SELECT c.department, b.department_id, b.product_name, a.product_id, (SUM(a.reordered)/COUNT(a.reordered)) AS 재구매율 FROM order_products__prior a LEFT JOIN products b USING (product_id) LEFT JOIN departments c USING (department_id) GROUP BY c.department, a.product_id) A) B WHERE rnk BETWEEN 1 AND 10 AND department IS NOT NULL ORDER BY department_id;
airflow 맛보기
1) 강사님이 공유폴더에 업로드 해주신 download_rocket_launchers.py 다운받기

2) 어제 wsl에 가상환경을 실행해서 airflow를 install 하면서 생긴 home/playdata에 있는 airflow파일 안에 dags파일을 생성하고 그 안에 다운받은 download_rocket_launchers.py 파일을 복붙하기 !
3) vscode 터미널에서 airflow webserver & + airflow scheduler & 구동
4) 주소창에 127.0.0.1:8080 입력: airflow의 기본 포트는 8080
4-1) login하라는 창이 뜨면 user-admin, password-admin 입력
(이건 어제 airflow 설치할때 만들어둠, 5월 22일 수업 내용 참고)
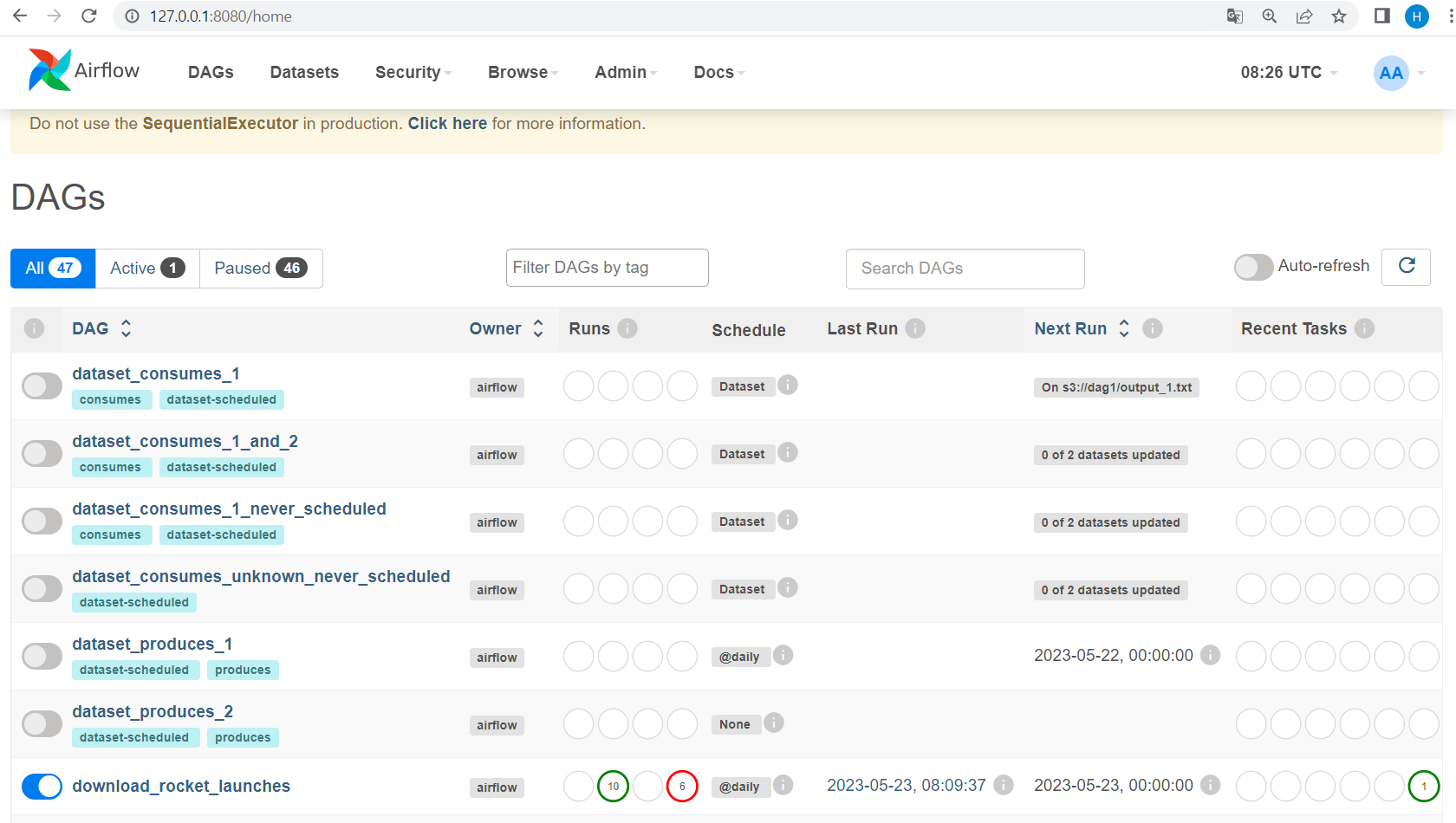
5) airflow web 페이지의 DAGs를 누르면 위 사진과 같은 dags 목록이 뜸, 여기서 우리가 실행하려는 download_rocket_launchers 클릭
6) trigger dag -> 해당 dag 실행
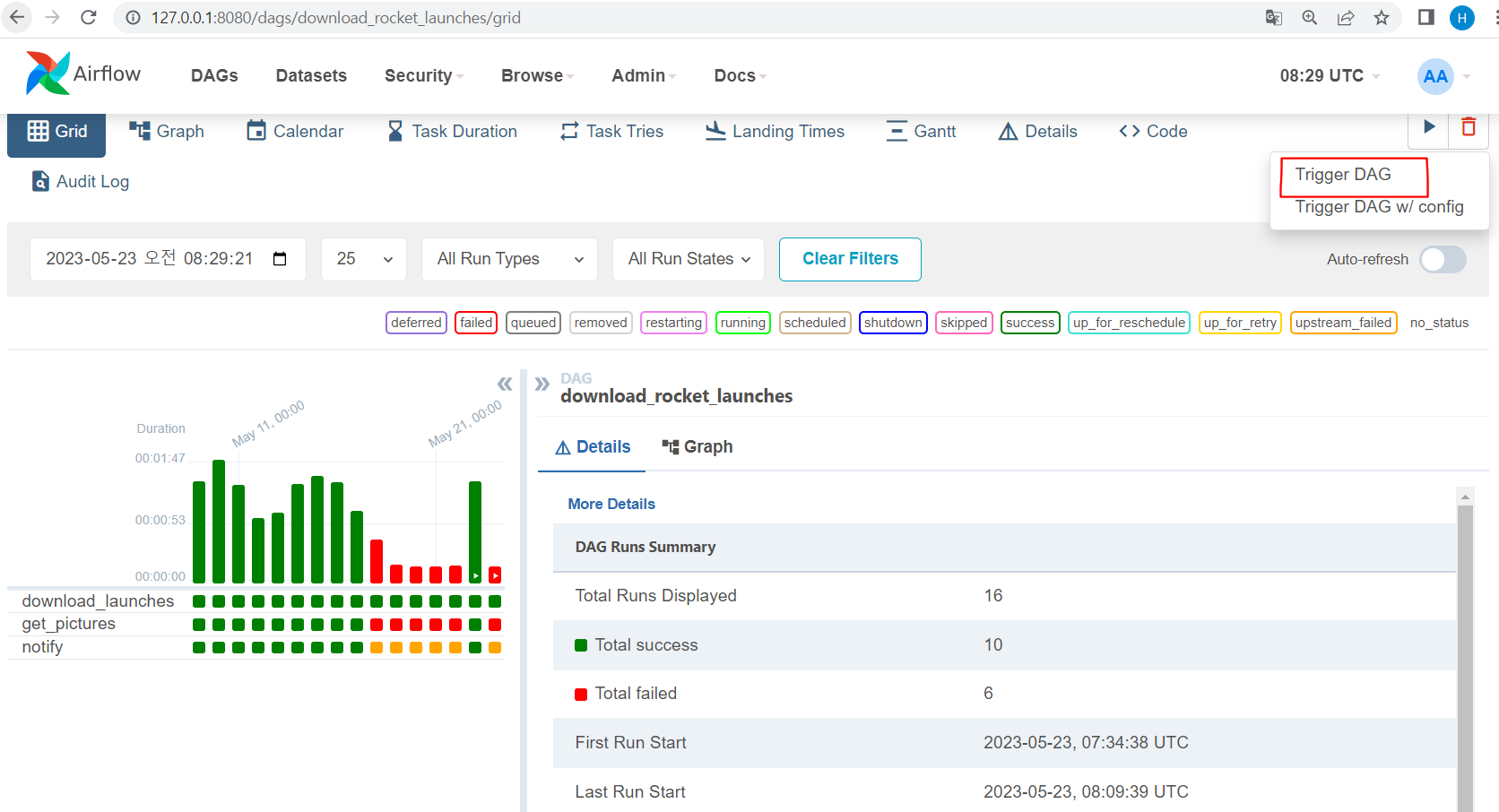
7) graph에 들어가면 해당 dag의 형태+실행 과정 확인가능
8) download_rocket_launchers.py의 내용은 다음과 같음
import json
import pathlib
import airflow.utils.dates
import requests
import requests.exceptions as requests_exceptions
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
dag = DAG(
dag_id="download_rocket_launches",
description="Download rocket pictures of recently launched rockets.",
start_date=airflow.utils.dates.days_ago(14),
schedule_interval="@daily",
)
download_launches = BashOperator(
task_id="download_launches",
bash_command="curl -o /tmp/launches.json -L 'https://ll.thespacedevs.com/2.0.0/launch/upcoming'", # noqa: E501
dag=dag,
)
def _get_pictures():
# Ensure directory exists
pathlib.Path("/tmp/images").mkdir(parents=True, exist_ok=True)
# Download all pictures in launches.json
with open("/tmp/launches.json") as f:
launches = json.load(f)
image_urls = [launch["image"] for launch in launches["results"]]
for image_url in image_urls:
try:
response = requests.get(image_url)
image_filename = image_url.split("/")[-1]
target_file = f"/tmp/images/{image_filename}"
with open(target_file, "wb") as f:
f.write(response.content)
print(f"Downloaded {image_url} to {target_file}")
except requests_exceptions.MissingSchema:
print(f"{image_url} appears to be an invalid URL.")
except requests_exceptions.ConnectionError:
print(f"Could not connect to {image_url}.")
get_pictures = PythonOperator(
task_id="get_pictures", python_callable=_get_pictures, dag=dag
)
notify = BashOperator(
task_id="notify",
bash_command='echo "There are now $(ls /tmp/images/ | wc -l) images."',
dag=dag,
)
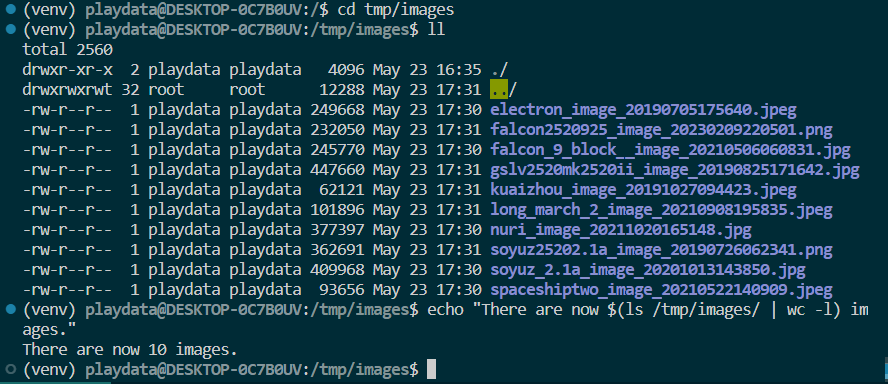
download_launches >> get_pictures >> notify마지막 문단을 보면 위 dag에서 저장한 image 파일들을 /tmp/images/파일에 저장하는 걸 볼 수 있음! 따라서 /tmp/images/ 안에 파일이 존재하는지 확인하기 !
위처럼 10개의 사진이 존재하는 걸 볼 수 있음 !
airflow 설치 이후 anaconda prompt에서 jupyter lab을 실행했을 때 뜨는 오류
Traceback (most recent call last): File "<stdin>", line 1, in <module> File "C:\Users\me\source\repos\FlaskWebProject1\env\lib\site-packages\flask\__init__.py", line 14, in <module> from jinja2 import escape File "C:\Users\me\source\repos\FlaskWebProject1\env\lib\site-packages\jinja2\__init__.py", line 12, in <module> from .environment import Environment File "C:\Users\me\source\repos\FlaskWebProject1\env\lib\site-packages\jinja2\environment.py", line 25, in <module> from .defaults import BLOCK_END_STRING File "C:\Users\me\source\repos\FlaskWebProject1\env\lib\site-packages\jinja2\defaults.py", line 3, in <module> from .filters import FILTERS as DEFAULT_FILTERS # noqa: F401 File "C:\Users\me\source\repos\FlaskWebProject1\env\lib\site-packages\jinja2\filters.py", line 13, in <module> from markupsafe import soft_unicode ImportError: cannot import name 'soft_unicode' from 'markupsafe' (C:\Users\me\source\repos\FlaskWebProject1\env\lib\site-packages\markupsafe\__init__.py)-> 해결 방법은 프롬포트에
pip install -U jinja2 markupsafe입력
-> 이는 jinja2라는 패키지를 업데이트 하는 것
bashshell: 파이썬으로 bash 명령어를 실행가능함
curl: 웹에 접속하는 명령어 curl https://www.naver.com -> www.naver.com 웹의 정보를 가져옴
wc는 개수를 알려줌 -> 현재 위치에 이미지가 몇개인지 알려주는 코드에 활용
- dag의 순서: download 런처 -> 사진 가져오기 -> notify
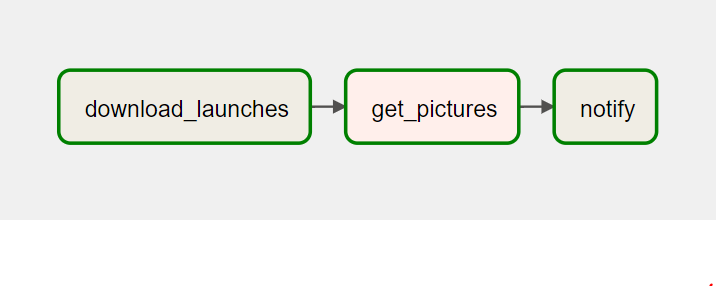
-> 내일은 네이버 주식사이트에서 파일을 가져와서 주식 정보를 얻기 !
(airflow를 통해 정기적으로 데이터 가져오기가 가능, 스케쥴은 내가 지정 ! 횟수도 지정 !)
airflow의 목적: 데이터 수집을 편하게 할 수 있음 ~ 실시간으로 실행 과정이 어떻게 되가고 있는지도 보여줌
텐서플로 ㄴㄴ 파이토치가 뜨는 중 파이토치를 써보자 !
hugging face라는 사이트: 논문이나 유명한 모델 구현되어있음, 일반적으로 연구 및 공부하는 사람들이 무료로 이용 가능! 모델 다운로드 받을때 텐서플로, 파이토치 중 어떤 걸로 다운 받을지도 선택이 가능 ~
깃허브는 사용자가 코드를 올림.. 위 hugging face도 깃허브처럼 사용자가 업로드. 요근래는 파이토치로 주로 업로드 되어있음 !
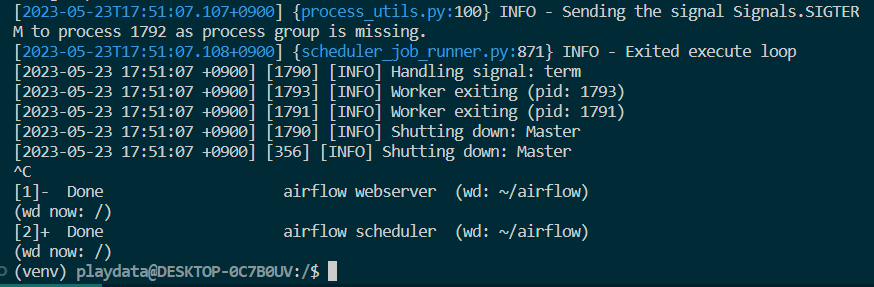
프로세스 끄는 방법 ^.^ -> kill
-
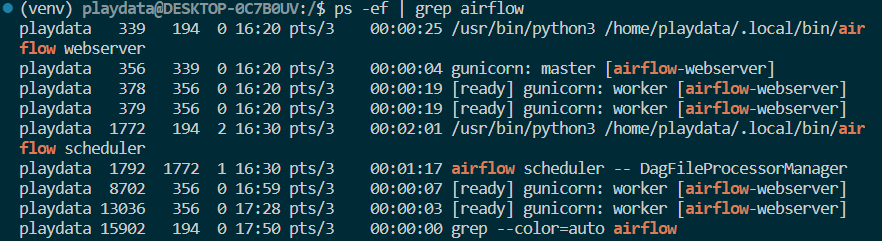
ps -ef | grep airflow-> 프로세스 목록 확인
-
kill -9 pid-> 프로세스 죽이기
pkill -f airflow-> airflow가 들어간 프로세스는 다 죽임
