(오전 수업은 혼자공부하는머신러닝 책의 RNN내용이었음. 나중에 혼공머신러닝 따로 정리해서 공부하기 !)
한글 형태소 분석
pip install konlpy
- 형태소 분석을 위한 파이썬 기본 내장 패키지 다운로드
from konlpy.tag import Mecab, Komoran
-
패키지로부터 형태소 분석이 가능한 프로그램 import
-
Mecab은 한국어 형태소 분석에 많이 활용되는 프로그램
-
KoNLPy는 여러 한국어 형태소 분석가들을 모아놓은 랩핑 라이브러리 제공
tokenizer = Komoran()
-
tokenizer라는 변수에 해당 모듈 지정
-
이 코드를 실행 시 뜨는 에러 -> 자바 설치가 안되어서 난 에러
-
jdk(자바개발도구)다운로드 -> 윈도우 64비트 MSI installer 다운받기
https://www.oracle.com/kr/java/technologies/downloads/#jdk20-windows
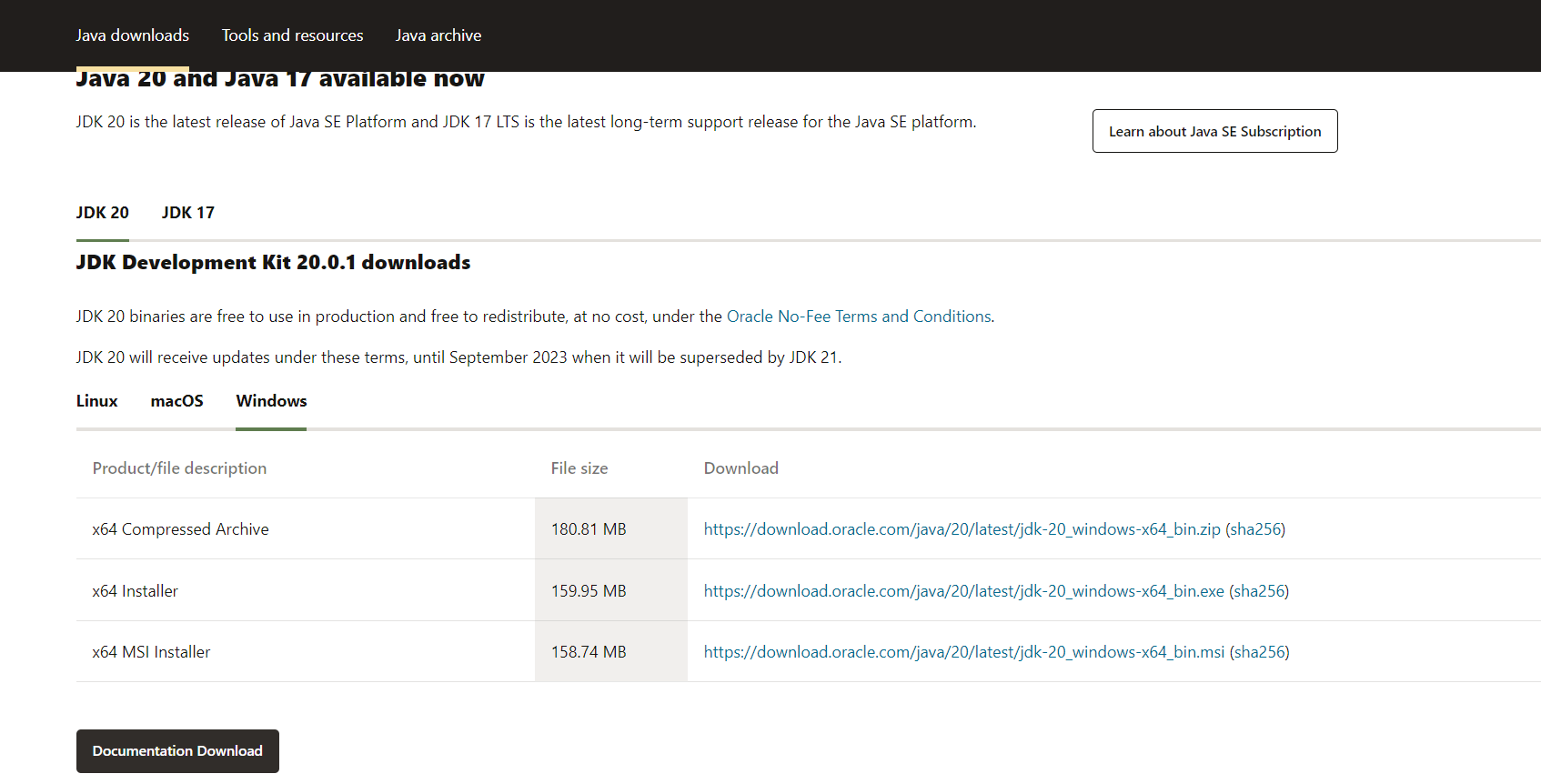
이 홈페이지에서 맨 아래에 있는 MSI Installer 다운로드
시스템 환경변수 설정하기(윈도우 - 설정 - 시스템 - 정보 - 고급 시스템 설정 - 환경변수)
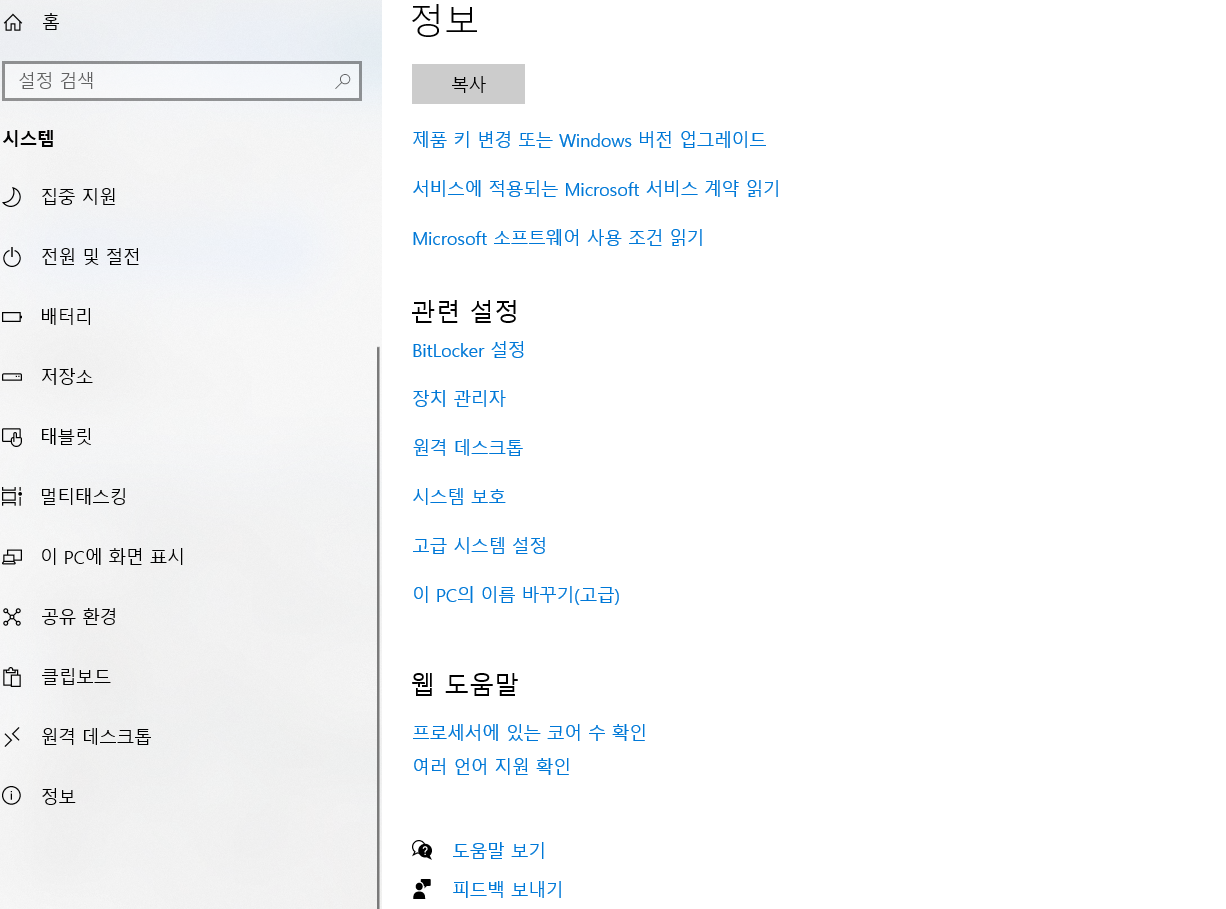

jAVA_HOME이라는 환경변수를 새로 만들기를 통해 생성(위의 사용자변수가 아닌 시스템 변수에 만들어 주어야 적용됨)
- 나의 경우 jdk-20의 경로인
C:\Program Files\Java\jdk-20path 추가mac의 경우
vim ~/.zshrc,export JAVA_HOME= 경로
jupyter lab 재부팅 후
from konlpy.tag import Mecab, Komoran
tokenizer = Komoran()
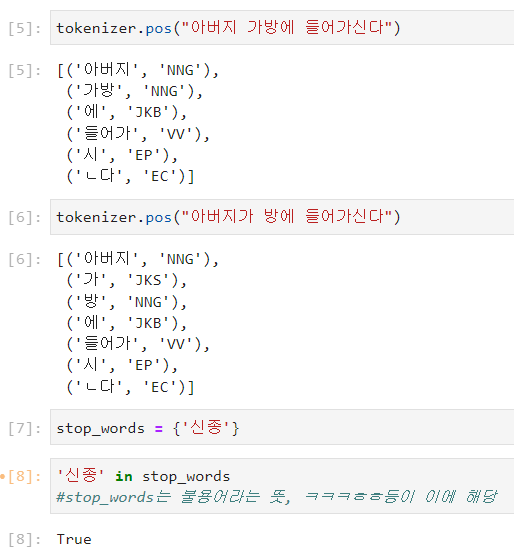
tokenizer.pos("아버지 가방에 들어가신다")
tokenizer.pos("아버지가 방에 들어가신다")
순서대로 실행 시 오류 없이 제대로 잘 실행되는 것을 볼 수 있다 !
한글 형태소 품사 태그는 아래 주소에서 확인 가능 !
- http://kkma.snu.ac.kr/documents/?doc=postag
- 이를 통해 감정분석에 활용할 수 있다.

stop_words = {'신종'}
import os
total = []
for roots, dirs, files in os.walk("./news"):
for idx,file in enumerate(files):
if idx % 100 ==0 : print(idx)
with open (roots + "/" + file, "r", encoding='utf-8') as f:
for text in f:
tmp = []
for word, morpheme in tokenizer.pos(text.strip()):
if morpheme in ['NNG', 'NNP', 'NNB', "NNM"] and len(word) > 1 :
#print(word, end=", ")
if word not in stop_words: tmp.append(word)
total.append(tmp)위는 강사님이 주신 코드, 아래는 그 코드에 대한 설명
이 코드는 주어진 디렉토리 "./news" 내의 텍스트 파일을 읽어와 특정 형태소 태그에 해당하는 단어들을 추출하여 리스트에 저장하는 기능을 수행합니다. 코드를 분석해보면 다음과 같은 동작을 수행합니다:
- import os: os 모듈을 가져옵니다. 이 모듈은 운영 체제와 상호 작용할 수 있는 함수를 제공합니다.
- total = []: 빈 리스트 total을 생성합니다. 추출된 단어들을 저장하기 위한 변수입니다.
- for roots, dirs, files in os.walk("./news"):: os.walk() 함수를 사용하여 "./news" 디렉토리와 그 하위 디렉토리를 반복적으로 순회합니다. roots는 현재 순회 중인 디렉토리를 나타내며, dirs는 현재 디렉토리의 하위 디렉토리들의 리스트입니다. files는 현재 디렉토리 내의 파일들의 리스트입니다.
- for idx, file in enumerate(files):: files 리스트에 대해 반복문을 수행하면서 파일 이름과 인덱스 값을 순차적으로 가져옵니다.
- if idx % 100 == 0: print(idx): 인덱스 값을 100으로 나눈 나머지가 0일 경우에만 인덱스 값을 출력합니다. 이는 작업이 진행 중인지를 표시하기 위한 것으로 보입니다.
- with open(roots + "/" + file, "r", encoding='utf-8') as f:: 현재 파일을 읽기 모드로 엽니다. roots와 file을 합쳐서 파일의 경로를 생성합니다. encoding='utf-8'은 파일을 UTF-8 인코딩으로 열도록 지정합니다.
- for text in f:: 파일을 한 줄씩 읽어옵니다.
- tmp = []: 빈 리스트 tmp를 생성합니다. 추출된 단어들을 임시로 저장하기 위한 변수입니다.
- for word, morpheme in tokenizer.pos(text.strip()):: tokenizer 객체를 사용하여 현재 읽은 줄(text)을 형태소 단위로 분석합니다. pos() 함수는 단어와 형태소를 반환합니다.
- if morpheme in ['NNG', 'NNP', 'NNB', "NNM"] and len(word) > 1: tmp.append(word): 형태소가 ['NNG', 'NNP', 'NNB', "NNM"] 중 하나에 속하고, 단어의 길이가 1보다 큰 경우에만 추출하여 tmp 리스트에 추가합니다.
- total.append(tmp): tmp 리스트를 total 리스트에 추가합니다.
-
따라서, 이 코드는 "./news" 디렉토리 내부의 텍스트 파일들을 읽어와서 형태소 분석을 수행한 뒤, 특정 형태소 태그에 해당하는 단어들을 추출하여 total 리스트에 저장하는 작업을 수행합니다. 각 파일은 한 줄씩 읽혀서 형태소 분석이 이루어집니다.
-
분석할 형태소 태그는 ['NNG', 'NNP', 'NNB', "NNM"]으로 지정되어 있으며, 단어의 길이가 1보다 큰 경우에만 추출합니다. 추출된 단어들은 tmp 리스트에 임시로 저장되며, 각 파일 별로 tmp 리스트에 저장된 단어들이 모두 total 리스트에 추가됩니다.
-
이 코드의 목적은 "./news" 디렉토리 내의 텍스트 파일에서 명사 형태소를 추출하여 통계 분석이나 자연어 처리 작업에 활용할 수 있는 형태로 데이터를 구성하는 것 !
aws 서버 관리
재부팅 될때마다 서버의 ip가 변경됨 -> 서버 사용하기 힘듦
-> 서버의 퍼블릭 ip를 고정으로 하고 싶다. 그럼 탄력적 ip라고 신청을 해야함
-> 탄력적 ip의 경우 ip하나당 한달에 5000원 정도 돈을 받음
모든 인스턴스 말고 주로 사용할 서버 ip만 탄력적 ip로 신청하기
탄력적 ip가 아닌 서버의 경우 서버를 재부팅 할때마다 ip가 변화함
이와 달리 프라이빗 ip는 ip 주소가 거의 바뀌지 않음
보통 해커가 여러개의 서버 중 하나만 뚫어도 프라이빗 ip(사설 ip)가 비슷하기 때문에 다른 서버도 다 뚫림
sql 문제 풀이
하이디sql을 키고 수업내용에 강사님이 올려주신 instacart 테이블ㅇㅔ 접속해서 다섯문제 풀기 !
- 1번(전체 주문 건수)
SELECT COUNT(order_id) FROM orders;
- 2번(구매자 수)
SELECT COUNT(distinct(user_id)) FROM orders;
- 3번(상품별 주문 건수)
SELECT a.product_id, b.product_name, COUNT(a.order_id) FROM order_products__prior a LEFT JOIN products b USING (product_id) GROUP BY a.product_id;
- 4번-내 풀이(카트에 가장 먼저 넣는 상품 10개)
SELECT product_id, COUNT(add_to_cart_order) FROM order_products__prior WHERE add_to_cart_order = 1 GROUP BY product_id ORDER BY COUNT(add_to_cart_order) DESC LIMIT 10;
- 4번-강사님 풀이(카트에 가장 먼저 넣는 상품 10개)
SELECT * FROM (SELECT *, rank() OVER(ORDER BY F_1st DESC) rnk FROM (SELECT product_id, SUM(case when add_to_cart_order = 1 then 1 ELSE 0 END) F_1st FROM order_products__prior GROUP BY product_id) A LIMIT 10) B LEFT JOIN products C ON B.product_id = C.product_id ORDER BY rnk ;
- 5번(시간별 주문 건수)
SELECT order_hour_of_day, COUNT(order_id) FROM orders GROUP BY order_hour_of_day;
airflow 설치 및 스케줄링 만들기

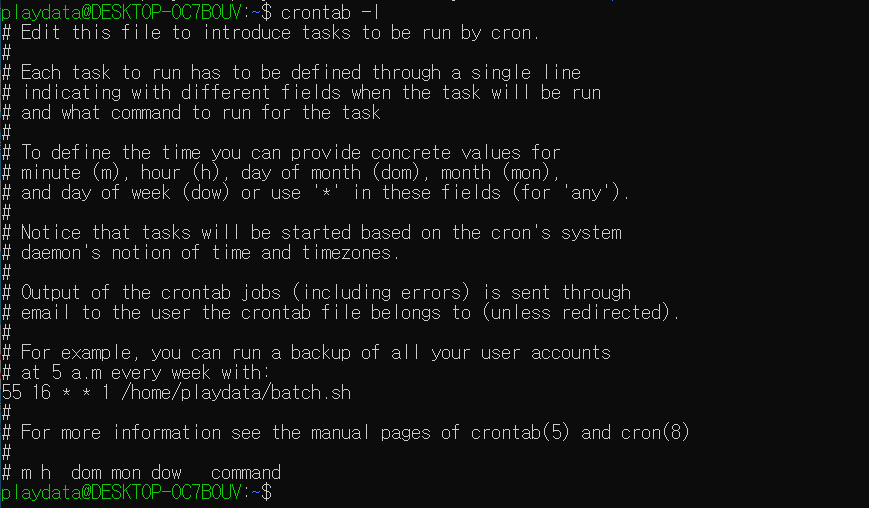
기존 wsl의 crontab -e 를 입력하면 위와 같은 창이 뜬다.
여기에서 0 5 * * 1 tar -zcf /var/backups/home.tgz /home/
첫번째 : 분
두번째: 시간
세번째 : 일
네번째 : 월
다섯 : 요일
0 16 * * 1 -> 월요일 오후 4시
0 16 * * 2 -> 화요일 오후 4시
0 16 * * 3 -> 수요일 오후 4시
0 16 * * 4 -> 목요일 오후 4시
0 16 * * 5 -> 금요일 오후 4시
eval이란 함수는 자동으로 text를 배열 형식으로 바꿔주는 아주 좋은 친구 ! 나중에 더 공부할것 ..!
-
wsl에서
pip install apache-airflow-> 안될 경우 wsl의 가상환경을 하나 만들고 activate한 상태에서 pip 다시 해볼 것 -
설치가 완료되면
airflow db init+airflow users create --username admin --password admin --firstname Anonymous --lastname Admin --role Admin --email test@test.com

- 그럼 위 같은 창이 뜨고, 다시 한번
airflow webserver &+
airflow scheduler &를 wsl 창에 치면 아래와 같은 창이 뜨면서 airflow가 제대로 실행되는 것을 볼 수 있음
from datetime import date, datetime
import requests
import pandas as pd
krx_url = "http://data.krx.co.kr/comm/bldAttendant/getJsonData.cmd"
krx_payload = {"bld": "dbms/MDC/STAT/standard/MDCSTAT01901",
"locale": "ko_KR",
"mktId": "ALL",
"share": "1",
"csvxls_isNo": "false",}
today = str(date.today()).replace("-","")
r= requests.post(krx_url, data=krx_payload)
total = []
for x in r.json()['OutBlock_1'][:10]:
symbol = x['ISU_SRT_CD']
url = f"https://api.finance.naver.com/siseJson.naver?symbol={symbol}&requestType=1&startTime={today}&endTime={today}&timeframe=day"
df =pd.DataFrame(data=eval(requests.post(url).text.strip())[1:], columns=eval(requests.post(url).text.strip())[0])
df['symbol'] = symbol
total.append(df)
pd.concat(total, ignore_index=True).to_csv(f"./{today}.csv", index=False)-> 이거를 stock.py로 저장
- wsl에서 cron 서비스 실행
sudo service cron start
sudo service cron status
->* cron is running
- python3 실행 경로 확인
which python3
-
batch.sh 파일 생성
vim batch.sh- batch.sh안에 내용은 아래처럼 입력
#!/bin/bash /usr/bin/python3 ~/stock.py
-
셸(Shell) 스크립트 파일 batch.sh를 실행하는 명령어
sh ~/batch.sh -
실행 권한 부여하기
chmod +x ~/batch.sh
~/batch.sh -
date 명령어로 현재 시간 확인
-
저 위에 있는 부분을
55 16 * * 1 /home/username/batch.sh로 수정
#없애고 뒤에 경로(home/username/batch.sh)는 알아서 맞게 수정 !
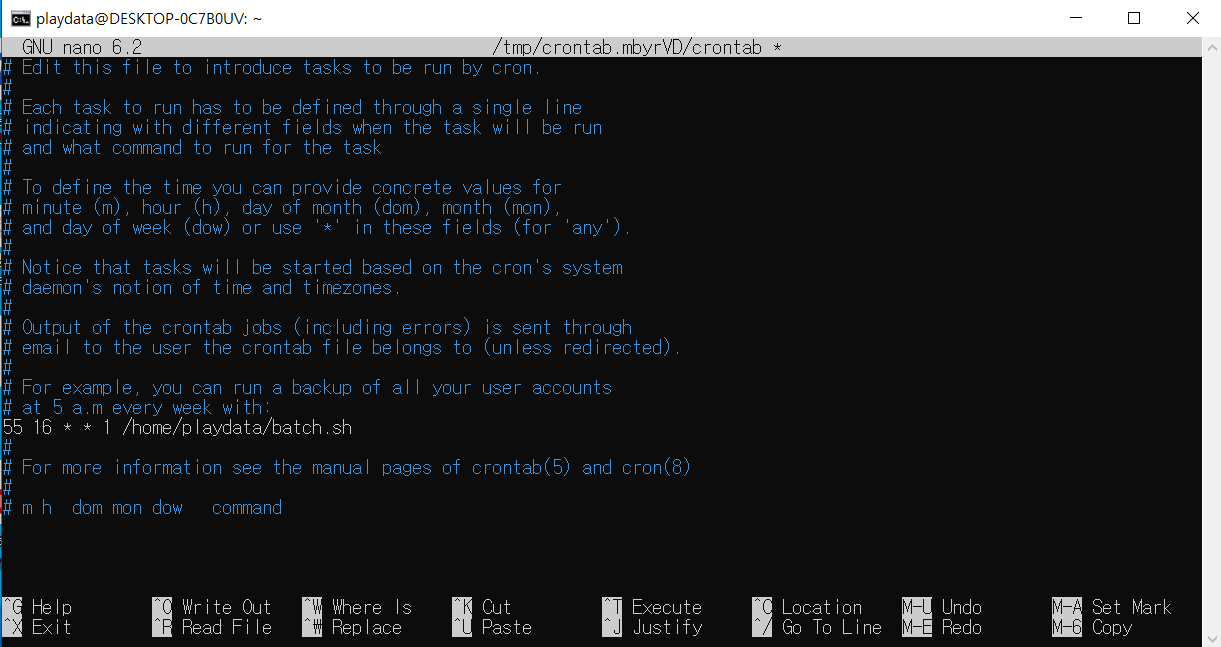
위의 예시처럼 수정 !
crontab -l-> crontab 리스트 확인