추천시스템 Basic (2)
00. 학습 내용
- 연관 규칙 분석에 대하여 학습
- TF-IDF를 활용한 컨텐츠 기반 추천에 대하여 학습
01. Association Rule Analysis
1) 개념
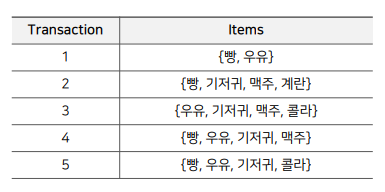
- 연관 규칙 분석은 위 그림과 같이 주어진 transaction(거래 내역, 장바구니 등) 데이터에 대해서, 하나의 itemset이 등장했을 때 다른 itemset이 같이 등장하는 규칙을 찾는 것이다.
- 흔히 장바구니 분석 혹은 서열 분석이라고도 불리며, 상품의 구매, 조회 등 하나의 연속된 거래들 사이의 규칙을 발견하기 위해 사용된다.(우리가 잘 아는 월마트의 맥주와 기저귀 진열이 대표적인 사례)
2) 기본 용어
- 연관 규칙
- IF (autecedent) THEN (consequent)
- 특정 사건 autecedent이 발생했을 때 함께 빈번하게 발생하는 또 다른 사건 consequent 사이에 규칙을 의미함
- 여기서 autecedent -> consequent는 인과관계를 의미하지 않음(즉, 반대의 경우도 성립한다는 것)
- itemset
- autecedent와 consequent 각각을 구성하는 상품들의 집합
- autecedent와 consequent는 서로소 관계
- support count
- 전체 transaction data에서 itemset이 등장하는 횟수
- support
- itemset / len(transaction data)
- 즉, support count를 비율로 나타낸 값이라 할 수 있음
- frequent itemset
- 유저가 지정한 minmum score(suport, confidence, lift) 값 이상의 itemset
- 즉, 우리가 연관 규칙 분석에 활용할 itemset 이라고 할 수 있음
3) 연관 규칙의 척도
우리가 연관 규칙을 분석하기 위해서는 frequent itemset을 설정해야 하는데, 이 frequent itemset 구하는 데 사용하는 척도가 우리가 앞으로 배울 support, confidence, lift 이다.
(1) support
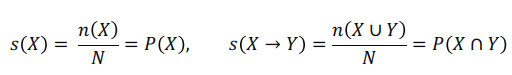
- X, Y는 itemset을, N는 전체 transaction의 수를 의미
- 두 itemset X, Y를 모두 포함하는 transaction의 비율을 의미
- 즉, 전체 transaction에 대한 itemset의 확률 값(빈도가 높거나, 구성 비율이 높은)
(2) confidence
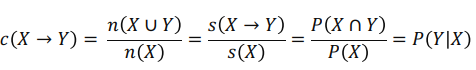
- X가 포함된 transaction 가운데 Y도 포함하는 transaction 비율 (Y의 X에 대한 조건부 확률이라고 볼 수 있음)
(3) lift
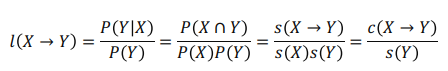
- X가 포함된 transaction 값 * Y가 포함된 transaction 값에 대한 X와 Y가 모두 포함된 transaction 값
- 따라서 lift 값이 1이라면 X와 Y는 서로 독립이고, 1 이상이라면 X와 Y는 양의 상관관계를 가지고, 1 이하라면 X와 Y는 음의 상관관계를 가진다.
4) 탐색 방법
연관 규칙 분석은 우선 위해서 정의한 척도의 최솟값을 만족하는 모든 itemset을 생성하는 작업(Frequent Itemset Generation)을 거친 뒤에, 해당 itemset을 바탕으로 association rule을 생성하여 연관 규칙을 분석한다.
(1) Brute-force Approach
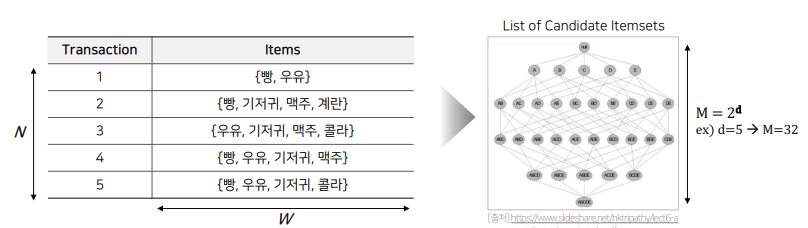
- Brute-force Approach은 말 그대로 개별 트랜잭션의 아이템들을 풀스캔하여 가능한 모든 itemset의 support를 계산하는 방법이다.
- 따라서 Brute-force Approach의 시간 복잡도는 O(NWM)이라고 할 수 있어, 매우 시간이 오래 걸리는 접근법이라고 할 수 있다.
- N은 모든 transaction의 개수, W는 transaction의 너비, M은 List of Candidate Itemsets 이다. (M은 이기 때문에 M을 줄이는 것이 제일 핵심이라고 할 수 있다.)
- 이제 앞으로 다룰 알고리즘들은 이제 이 N과 M을 어떠한 방식으로 줄이느냐에 따라 나뉘어지는 알고리즘들이다.
(2) Apriori 알고리즘
- 본 알고리즘은 itemset A가 frequent itemset이라면, A의 모든 부분집합은 frequent itemset이라는 원리를 사용하는 방법으로, 특정 척도 값을 만족하는 집합까지만을 찾고 그 부분 집합을 추가 또는 제거하는 방식으로 활용된다.
- 따라서 Apriori 알고리즘은 가능한 후보 itemset의 개수(M)를 줄이는 방법이라고 할 수 있다.
(3) DHP(Direct Hashing & Pruning) 알고리즘
- itemset의 크기가 커짐에 따라 전체 N개 transaction보다 적은 개수를 탐색하는 알고리즘이다.
- 따라서 DHP 알고리즘은 탐색하는 transaction의 숫자(N)를 줄이는 방법이라고 할 수 있다.
(4) FP(Frequent pattern)-Growth 알고리즘
- 효율적인 자료구조(FP-tree)를 사용하여 후보 itemset과 transaction을 저장하여, 모든 itemset과 transaction의 조합에 대해서 탐색할 필요가 없는 알고리즘이다.
- 따라서 FP-Growth 알고리즘은 탐색횟수(NM)를 줄이는 방법이라고 할 수 있다.
2. TF-IDF를 활용한 컨텐츠 기반 추천
1) TF-IDF 개요
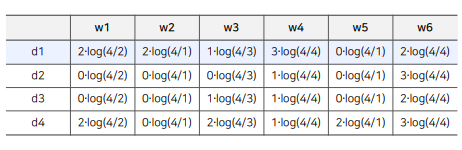
- TF-IDF는 간단하게 말하면 단어에 대한 중요도를 나타내는 Score인 TF * IDF 로 이루어진 행렬을 만드는 것이라고 할 수 있다.
- TF는 단어 w가 문서 d에 등장하는 횟수
- IDF는 전체 문서 가운데 단어 w가 등장한 비율의 역수
- 따라서 문서 d에 등장하는 단어 w에 대해서, 단어 w가 문서 d에 많이 등장하면서, 단어 w가 전체 문서(D)에서는 적게 등장하는 단어라면, 단어 w는 문서 d를 설명하는 중요한 feature로, TF-IDF 값이 높게 측정된다.



2) 컨텐츠 기반 추천 개요
- 컨텐츠 기반 추천은 유저가 선호하는 아이템을 기반으로 해당 아이템과 유사한 아이템을 추천해주는 방식
- 장점
- 유저에게 추천을 할 때 다른 유저의 데이터가 필요하지 않음(아이템의 특징을 바탕으로 추천을 하기 때문에)
- 새로운 아이템 혹은 인기도가 낮은 아이템을 추천할 수 있음(새로운 아이템에 대한 특징 벡터만 얻을 수 있다면 현재 존재하는 아이템들 간의 유사도를 구할 수 있기 때문에)
- 추천 아이템에 대한 설명(explanation)이 가능함(너가 빨간색 공 아이템을 선택했는데, 이 아이템과 유사한 아이템은 빨간색 아이템, 공 아이템 이야)
- 단점
- 아이템의 적합한 피쳐를 찾는 것이 어려움(도메인 지식이 많이 필요한 작업이 될 수 있음)
- 한 분야/장르의 추천 결과만 계속 나올 수 있음(비슷한 분야와 장르의 아이템은 특징 또한 서로 비슷하기 때문에)
- 다른 유저의 데이터를 활용할 수 없음(아이템에 특징을 바탕으로 추천을 사용하기 때문에 이 부분이 장점이자 곧 단점이 될 수 있음, 개인화된 추천이 어려울 수 있다는 것)
3) TF-IDF를 활용한 컨텐츠 기반 추천
- 우선 문서를 Item으로, 단어를 아이템에 대한 특징(장르, 유저의 Item에 대한 피드백 정보 등)으로 하여 각 아이템에 대한 TF-IDF 값을 구하여 Item Profile을 구축한다.
- 그 후 과거에 유저가 선호했던 Item List에 존재하는 개별 Item의 TF-IDF 값의 평균 값을 사용하거나 유저가 아이템에 내린 선호도로 정규화(normalize)한 평균값을 사용하여 User Profile을 구축한다.
- 이제 구축된 Item Profile과 User Profile 두 벡터 간의 Cosine Similarity(다른 유사도를 사용할 수 있음)를 구하고, 구해진 유사도 Score을 기준으로 User에게 아이템을 추천해줄 수 있다.
- 그리고 구한 유사도 Score는 유저 u 가 아이템 i 에 대해 가질 선호도(평점)를 에측하는 Task에 가중치로도 사용이 가능하다. 개인적으로 유저가 선호했던 아이템과 예측할 아이템에 대한 유사도 Score를 사용함으로써 유저가 선호한 아이템에 대한 평점 비중을 더 많이 반영할 수 있기 때문에 굉장히 좋은 방법이라고 생각한다.
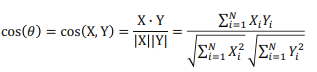
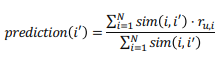

Machine Learning Engineer at Konan Technology