추천시스템 Basic (1)
00. 학습 내용
- 추천 시스템 개요에 대하여 학습
- 추천 시스템의 평가 지표에 대하여 학습
- 인기도 기반 추천에 대하여 학습
01. 추천 시스템 개요
(1) 개요
- 과거에 우리가 접할 수 있는 상품과 컨텐츠는 한정적
- 그러나 기술의 발전으로 웹/모바일 환경이 보편화되면서 다양한 상품과 컨텐츠가 등장함
- 따라서 우리는 이제 정보의 풍요를 넘어선 정보의 홍수 속에서 살게됨
- 정보의 홍수 속에서 우리는 원하는 걸 어떤 키워드로 찾아야 하는 지 모를 수 있고, 많은 정보 중에서 나에게 맞는 정보를 찾는데 많은 시간이 걸림
- 이러한 정보의 홍수 속에서 나에게 가장 필요한 정보를 빠르게 찾거나 제공받는 기술이 바로 추천 시스템이라고 할 수 있음
(2) 사용하는 Data의 종류
- 추천 시스템에서 사용하는 Data는 크게 3가지 종류로 나뉨
- 유저 관련 Data
- 유저 ID, 디바이스 ID 등의 식별자 정보
- 성별, 연령, 지역 등의 데모그래픽 정보
- 페이지 방문 기록, 아이템 평가 등의 유저 행동 정보
- 유저의 정보를 수집하는 행위를 유저 프로파일링이라 하며, 유저 프로파일링을 통해서 얻은 정보를 바탕으로 추천이 이루어짐
- 아이템 관련 Data
- 아이템의 식별자 정보
- 다양한 아이템의 특성 정보(장르, 브랜드, 출시일, 이미지 등)
- 아이템의 정보를 수집하는 행위를 아이템 프로파일링이라 하며, 아이템 프로파일링을 통해서 얻은 정보를 바탕으로 추천이 이루어짐
- 유저-아이템 상호작용 Data
- 유저가 오프라인 혹은 온라인에서 아이템과 상호각용을 할때는 로그가 기록되고, 이 로그가 곧 Feedback 데이터가 됨
- 로그에 아이템에 대한 유저의 직접적인 선호 정보가 담겨져 있다면 Explicit Feedback Data(평점, 좋아요 등)
- 로그에 아이템에 대한 유저의 직접적인 선호 정보가 담겨져 있지 않다면 Implicit Feedback Data(클락, 아이템 구매 등)
(3) 문제 정의
- 추천 시스템의 목적은 특정 유저에게 적합한 아이템을 추천해주거나, 특정 아이템에 적합한 유저를 추천해주는 것이라 할 수 있음
- 이 목적을 이루기 위해서는 유저-아이템 상호작용을 평가할 Score 값이 필요함
- 추천에서 Score 값은 크게 두 가지 Task를 기준으로 나뉘어짐
- 유저에게 적합한 아이템 Top K개를 추천하는 랭킹 문제
- NDCG@K, MAP@K 등
- 유저가 아이템을 가질 선호도를 예측하는 문제(평점, 클릭, 구매 확률 등)
- MAE, RMSE, AUC 등
- 유저에게 적합한 아이템 Top K개를 추천하는 랭킹 문제
02. 추천 시스템의 평가 지표
- 개발한 추천 시스템을 실제 서비스에 적용하기 위해서는 Offline Test와 Online A/B Test를 거쳐야 한다.
(1) Offline Test
- 새로운 추천 모델을 검증하기 위해 가장 우선적으로 수행되는 단계
- 유저로 부터 수집한 데이터를 Train / Val / Test 로 나누어 모델의 성능을 객관적인 지표로 평가
- Offline Test에서 중요하게 생각해야 할 부분은 Offline Test의 좋은 성능이 Online 에서의 좋은 성능을 보장하지 않는다는 것이다.
- Offline Test에서 사용된 데이터는 축척되지 않는 과거의 데이터지만, 실제 Online 환경에서는 실시간으로 축척되는 데이터이고 유저의 관심은 실시간으로 바뀔 수 있기 때문에, 모델의 결과가 실제 서비스와 다른 양상을 보여주는 Serving bias가 나타날 수 있다.
- Offline Test에서 시용되는 모델 성능 평가 지표
- Precision@K
- Recall@K
- AP@K
- 한명의 유저에 대한 Precision@1 부터 Precision@K 까지의 평균 값
- 유저가 관심있는 아이템이 더 높은 순위에 존재할수록 점수가 상승
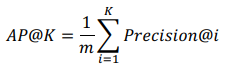
- MAP@K
- 모든 유저에 대한 AP@K 값의 평균 값
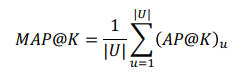
- NDCG@K
- MAP@K와 같이 추천 아이템의 순서에 가중치를 더 많이 주는 지표지만, Relevance라는 수치값을 사용하여 MAP@K 보다 추천 리스트 내부에 순위까지도 고려힐 수 있는 지표, 즉 Relevance 값을 이용하여 우리가 원하는 추천 아이템이 얼마나 상위에 존재하는지를 알 수 있음(ex, 1 2 3 4 5 라는 추천 리스트가 존재했을 때, Relevance 값이 1이라면 MAP@K와 NDCG@K 모두 값이 1이지만, 아이템마다 Relevance 값이 다르게 존재한다면(Relevance 값을 기준으로 5 4 3 2 1이 최적의 추천) MAP@K 값은 1이지만 NDCG@K 값은 1이 될 수 없음)
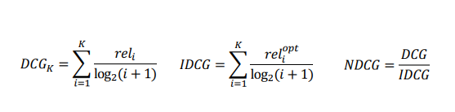
- IDCG는 가장 이상적인 추천 리스트이고 DCG는 모델이 추천한 리스트로 두 추천 리스트가 비슷할수록 1에 가까운 값을 얻음
- Precision@K
(2) Online A/B Test
- Offline Test에서 검증된 가설이나 모델을 실제 서비스에서 실험해보는 단계
- 대조군(A, 새로운 추천시스템 미적용), 실험군(B, 새로운 추천시스템 적용) 간의 성능을 평가함(A와 B 환경은 최대한 동일해야 함)
- 최종 의사결정에 반영되는 마지막 Test이기 때문에 매출, CTR, PV(Page View) 등의 비즈니스/서비스 지표를 사용해 모델의 성능을 평가
03. 인기도 기반 추천
- 인기도 기반 추천을 말 그대로 가장 인기있는 아이템을 추천하는 것
- 인기있다는 것을 조회수, 평균 평점, 리뷰 개수, 좋아요의 수 등으로 정의할 수 있음(이 정의는 Task에 따라서 다양하게 표현될 수 있음)
(1) 조회수가 가장 많은 아이템에 대한 Score 공식
- Hacker News Formula
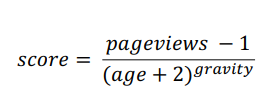
- 뉴스에서 가장 중요한 속성은 최신성이기 때문에 시간에 따른 Score 값의 조정을 위하여 age(뉴스 게시 후 경과된 시간)라는 변수를 사용하여 뉴스가 게시된 시간이 과거일수록 Score 값이 작아짐
- Reddit Formula
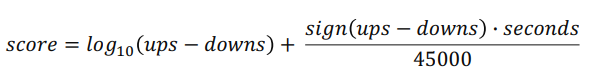
- 첫번째 텀에 log의 특성을 활용해 초반에 좋아요가 많은 아이템에 대해서 높은 가중치를 줌
- 두번째 텀에 포스팅이 게시된 날짜가 최신일 수록 더 높은 점수를 줌(45000을 통해서 12시간 30분 마다 1점을 주고, secondes의 경우 서비스 오픈 날짜 부터 현재 포스팅이 게시된 날짜 까지의 초를 의미함)
(2) 평균 평점이 가장 높은 아이템에 대한 Score 공식
- Steam Rating Formula
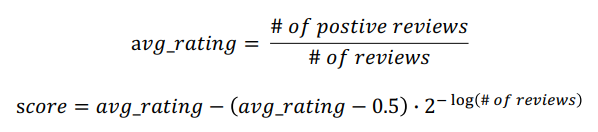
- 전체 리뷰의 개수에 따라서 rating 보정함 (1 ~ 5점의 평점일 경우 0.5 값을 3.0 or 모든 평점 데이터의 평균 값으로 바꿔서 사용할 수 있음)
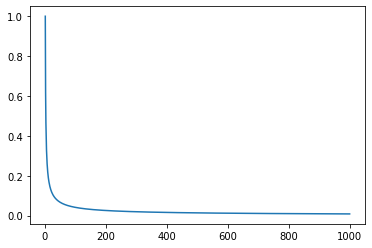
- 아래 그림과 같은 -log의 특성을 사용해 리뷰의 개수가 많아질수록 평균 rating에 가까운 Score 값을 얻도록 구성함

Machine Learning Engineer at Konan Technology