Collaborative Filtering (1)
00. 학습 내용
- Collaborative Filtering의 기본 개념에 대하여 학습
- Similarity Measure Method에 대하여 학습
- Neighborhood-based Collaborative Filtering에 대하여 학습
- K-Nearest Neighbors Collaborative Filtering에 대하여 학습
- Rating Prediction에 대하여 학습
01. Collaborative Filtering
1) 개요
- Collaborative Filtering은 많은 유저들로부터 얻은 기호 정보를 이용해 유저의 관심사를 예측하는 방법이다.
- 더 많은 유저/아이템 데이터가 축척될수록 협업의 효과는 커지고 추천을 정확해질 것이라는 가정에서 출발하였다.
- Collaborative Filtering은 Content-based와 달리 아이템에 대한 특징을 따로 추출하지 않아도 되기 때문에 도메인 지식으로 부터 자유롭다는 장점을 가지지만, 유저에 대한 피트백 정보가 적다면 사용하기 매우 까다롭다는 단점도 가진다.(그래서 두 가지 방법을 모두 활용하는 Hybrid 방법도 존재하고, 다양한 모델을 앙상블하기도 한다.)
2) 방법
- 주어진 데이터(유저와 아이템 간의 상호작용 정보)를 활용해 유저-아이템 행렬을 생성
- 유사도 기준을 정하고, 유저 혹은 아이템 간의 유사도를 측정
- 주어진 평점과 유사도를 활용하여 행렬의 비어있는 값을 예측
- 우선 앞으로 다룰 Collaborative Filtering 방법은 모두 비어있는 평점을 예측하는 것이 목표임
02. Similarity Measure Method
- 유사도 측정법이란, 두 개체 간의 유사성을 수량화하는 함수 혹은 척도
- 유사성에 대한 여러 정의가 존재하지만, 일반적으로 거리의 역수 개념을 사용
- 따라서 두 개체 간 거리를 어떻게 측정하냐에 따라 유사도 측정 방법이 달라짐
1) Mean Squared Difference Similarity
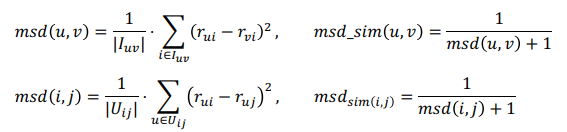
- 추천시스템에서 주로 사용되는 유사도로 각 기준에 대한 점수의 차이를 계산, 유사도는 유클리드 거리에 반비례함
- 분모가 0이 되는 것을 방지하기 위해 분모에 1이 더해짐 (smoothing)
2) Cosine Similarity
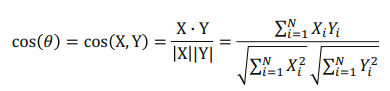
- 두 벡터의 각도를 이용하여 구하는 유사도, 두 벡터의 차원이 같아야 한다는 특징을 가짐
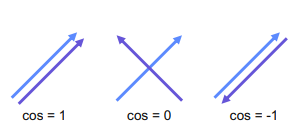
- 위 그림처럼 구한 유사도 값은 두 벡터가 가리키는 방향이 얼마나 유사한지를 의미함
3) Pearson Similarity
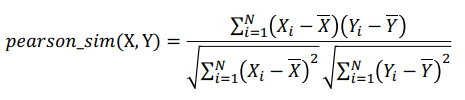
- 각 벡터를 표본평균으로 정규화한 뒤에 코사인 유사도를 구한 값
- 직관적으로 해석하면 (X와 Y가 함께 변하는 정도) / (X와 Y가 따로 변하는 정도)
- 1에 가까우면 양의 상관관계, 0일 경우 서로 독립, -1에 가까울수록 음의 상관관계를 나타냄
4) Jaccard Similarity
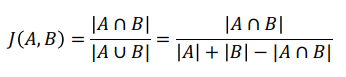
- 집합의 개념을 사용한 유사도 앞의 두 유사도와 달리 길이(차원)가 달라도 이론적으로 유사도 계산 가능
- 두 집합이 같은 아이템을 얼마나 공유하고 있는지를 나타냄
- 두 집합이 가진 아이템이 모두 같으면 1, 두 집합에 겹치는 아이템이 하나도 없으면 0
03. Neighborhood-based Collaborative Filtering
1) 개요
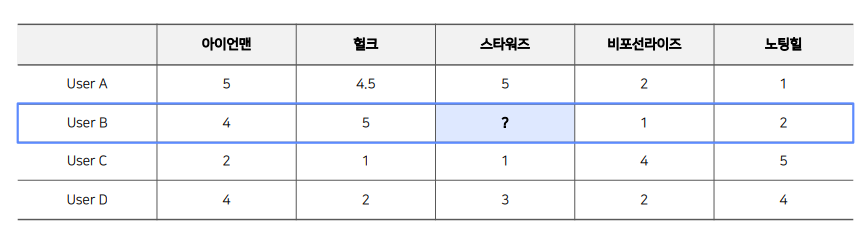
- User-based CF는 위 그림처럼 유저를 기준으로 유저 간 유사도를 구한 뒤, 타겟 유저와 유사도가 높은 유저들이 선호하는 아이템을 추천하는 방법
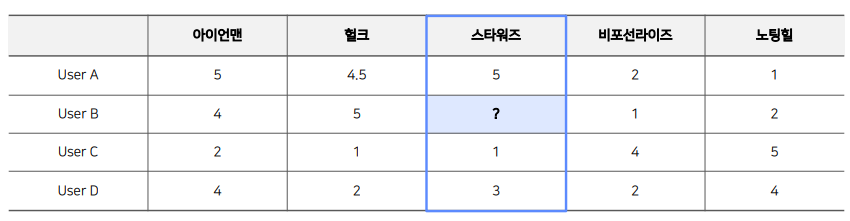
- Item-based CF는 위 그림 처럼 아이템을 기준으로 아이템간 유사도를 구한 뒤, 타겟 아이템과 유사도가 높은 아이템 중 선호도가 큰 아이템을 추천하는 방법
2) 특징
- 구현이 간단하고 이해가 쉽다는 장점
- 아이템이나 유저가 계속 늘어날 경우 확장성이 떨어진다는 단점(Scalability, 그때 그때 마다 다시 계산해야함)
- 주어진 평점/선호도 데이터가 적을 경우, 성능이 저하된다는 단점(Sparsity, 주어진 데이터를 활용해 유저-아이템 행렬을 만들면 대부분의 유저가 모든 아이템을 소비한 것이 아니기 때문에 실제로 행렬 대부분의 원소는 비어있음, 따라서 NBCF를 적용하려면 적어도 sparsity ratio가 99.5%를 넘지 않는 것이 좋음, 그렇지 않다면 MF 같은 모델 기반 CF를 사용해야 함)
04. K-Nearest Neighbors Collaborative Filtering
1) 개요
- NBCF의 경우 아이템 i에 대한 평점 예측을 하기 위해서는, 아이템 i에 대해 평가를 한 유저 집합에 속한 모든 유저와의 유사도를 구해야 함
- 그런데, 유저가 많아지면 많아질수록 계속해서 연산은 늘어나고 오히려 성능이 떨어지는 경향을 보임
- 따라서 아이템 i에 대해 평가를 한 유저 집합에 속한 유저 가운데 유저 u와 가장 유사한 k명의 유저(KNN)를 이용해 평점을 예측하는 방식이 바로 K-Nearest Neighbors Collaborative Filtering
2) 방법
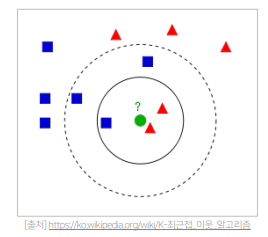
- 유저 u와 가장 유사한 k명의 유저를 찾는다. (보통 k = 25 ~ 50을 많이 사용하지만 직접 튜닝해야 하는 하이퍼파라미터)
- k명의 유저 Set을 이용하여 유저 u가 보지 않은 아이템 i에 대한 평점을 예측
05. Rating Prediction
1) Rating Prediction
- Absolute Rating Formula
- 단순히 유저의 평점을 사용하는 방법
- 유저가 평점을 주는 기준이 제각기 다를 수 있어 평점 예측의 정확도가 떨어질 수 있음(대부분을 5점을 주는 유저, 대부분 1~2점을 주고 가끔 4점을 주는 유저)
- 단순히 유저 평점의 평균 값 또는 유사도를 가중치로 사용하여 평점을 예측하는 방식
- Relative Rating Formula
- Absolute Rating Formula의 단점을 보완한 방식
- 유저의 평균 평점에서 얼마나 높은지 혹은 낮은지를 의미하는 편차(Deviation)를 사용하는 방법
- 유저의 편차를 평균 또는 유사도를 가중치로 사용하여 예측하여, 유저의 평균 평점에 더하여 예측하는 방식
2) Recommendation
- Collaborative Filtering의 목적은 유저 u가 아이템 i에 부여할 평점을 예측하는 것
- Recommendation System의 최종 목적은 예측 평점이 높은 아이템을 유저에게 추천하는 것
- 따라서 타겟 유저에 대한 아이템의 예측 평점 계산 완료되면 높은 순으로 정렬하여 상위 N개만 뽑아 추천이 가능함(Top-N Recommendation)
- 그런데 사실은 단순히 평점이 높은 순으로 추천을 하는 것 보다는, 다양한 모델을 통해서 다양한 추천 후보 집단을 생성하고, 그 후보 집단 속에서 Ranking Model등 다양한 Ranking을 부여하는 방법을 사용하여 순위를 매기고 그 순위를 가지고 추전이 이루어지는 것으로 안다.

Machine Learning Engineer at Konan Technology