DeepCTR
00. 학습 내용
- CTR 예측을 위해 DNN이 필요한 이유에 대하여 학습
- Wide & Deep Model에 대하여 학습
- DeepFM에 대하여 학습
- Deep Interest Network에 대하여 학습
- Behavior Sequence Transformer에 대하여 학습
01. CTR 예측을 위해 DNN이 필요한 이유
- CTR 예측은 유저가 주어진 아이템을 클릭할 확률(probability)을 예측하는 문제를 말함
- 현실의 CTR 예측 문제를 기존의 선형 모델로 예측하는 데에는 한계가 존재함
- 현실의 CTR 데이터는 Highly sparse & super high-dimensional features와 highly non-linear association between the features라는 특징을 가짐
- 이에 이러한 데이터셋에서 효과적인 성능을 보이는 딥러닝 기법들을 사용하여 CTR 예측 문제를 해결하기 시작함
02. Wide & Deep Model
- 추천 시스템에서 해결해야 할 두 가지 과제는 Memorization과 Generalization 이라고 할 수 있음
- Memorization은 함께 빈번히 등장하는 아이템 혹은 특성(feature) 관계를 과거 데이터로부터 학습하는 것이라고 할 수 있음
- Generalization은 드물게 발생하거나 전혀 발생한 적 없는 아이템/특성 조합을 기존 관계로부터 발견하는 것이라고 할 수 있음
- Memorization은 선형 모델이 강점을 가지고, Generalization은 딥러닝 모델이 강점을 가짐
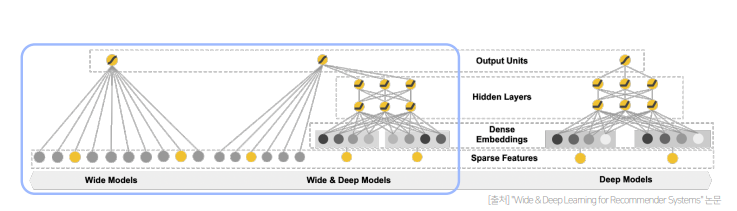
- Wide & Deep Model은 Memorization에 강점을 가지는 Wide Component와 Generalization에 강점을 가지는 Deep Component로 구성된 Model임
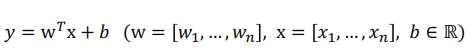
- Wide Component는 단순한 Linear Model이라고 할 수 있으나, 추가로 Cross-Product Transformation이 적용됨
- Cross-Product Transformation는 “gender=female=1”, “language=en=1” 이라는 변수가 있을 때 변수를 조합하여 "(gender=female, language=en) = 1”이라는 변수를 추가하는 것임
- 따라서 Cross-Product Transformation은 사람의 도메인 지식이 필요한 feature engineering 과정이라고 볼 수 있음
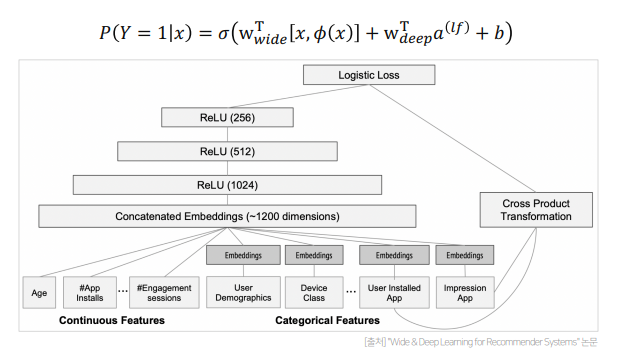
- Deep Component는 단순히 ReLU 함수를 활성화 함수로 사용하는 3 layer로 구성되어있고, 연속형 변수는 그대로 카테고리형 변수는 피쳐 임베딩 후 사용함
- 모델 구조를 간단하게 이야기하면 선형 모델과 단순하 MLP가 결합된 모델이라고 생각할 수 있음
03. DeepFM
- DeepFM은 Wide & Deep Model과 달리 두 요소(wide, deep)가 입력값을 공유하도록 한 end-to-end 방식의 모델임
- 추천 시스템에서는 low-order과 high-order feature interaction을 학습하는 것이 중요함(여러 변수와의 상호작용을 의미함)
- 그런데 기존의 모델들은 low-나 high-order feature interaction 중 한쪽에만 강한 형태였음(low-order의 경우 단순한 선형 모델이 강하고, high-order의 딥러닝 모델이 강함)
- Wide & Deep은 두 형태의 모델을 결합하여 이 방식을 해결했지만, wide component에 feature engineering이 필요하다는 단점이 존재하여, FM을 wide component로 사용하여 입력값을 공유하도록 하는 Factorization Machine과 Deep Neural Network를 합친 DeepFM이 만들어지게됨
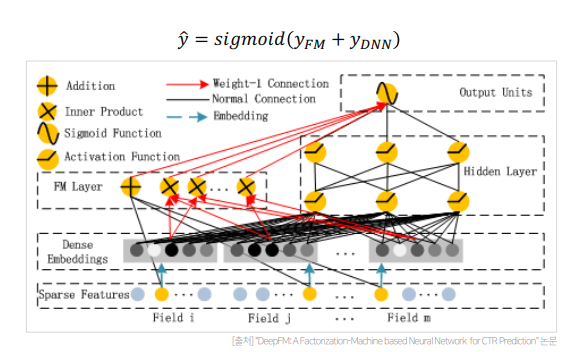
- DeepFM은 FM Component와 Deep Component로 구성됨

- FM Component는 low-order feature interaction을 캡쳐하는데 강점을 보이는 부분으로(선형 결합), 기존의 FM 모델과 완전히 동일한 구조로 이루어짐
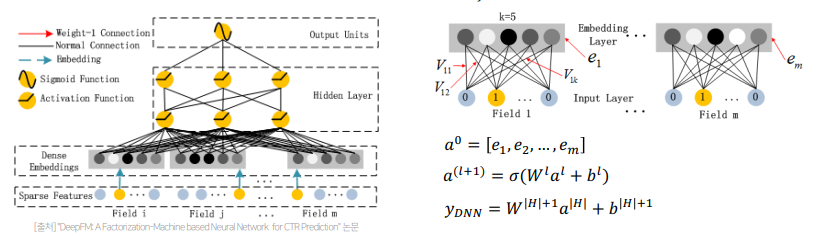
- Deep Component는 high-order feature interaction을 캡쳐하는데 강점을 보아는 부분으로(비선형 결합), 모든 feature들을 동일한 차원(k)의 임베딩으로 변환하고, 이 임베딩에 FM Component의 가중치와 동일하게 적용하여 hidden Layer의 인풋으로 사용함
04. Deep Interest Network
- 기존의 DNN 기반의 모델은 sparse feature들을 저차원 임베딩으로 변환 후 fully connected layer(=MLP)의 입력으로 사용하는 방식으로 학습됨
- 그런데 이러한 방식은 사용자의 다양한(diverse) 관심사를 반영할 수 없음(식재료와 생필품을 같이 찾을 때의 추천과 생필품만을 찾을 때의 추천은 서로 다름)
- 따라서 사용자가 기존에 소비한 아이템의 리스트를 User Behavior Feature(한명의 유조가 상황에 따라 여러 행동 특성을 보이는 것을 서로 다른 feature로 표현하는 것)를 만들어 예측 대상 아이템와 이미 소비한 아이템 사이의 관련성을 학습시킬 필요가 있음
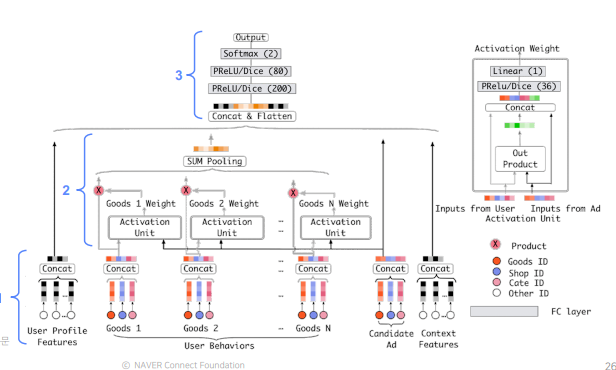
- DIN은 User Behavior Feature를 처음 사용한 모델로, 크게 Embedding Layer, Local Activation Layer, Fully-connected Layer로 이루어짐
- 나머지 부분은 다른 모델들과 서로 유사하기 때문에 우리가 다룰 부분은 Local Activation Layer임
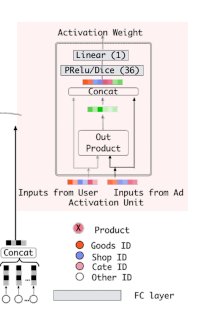
- transformer의 attention 메커니즘과 유사하게 Local Activation Unit은 후보군이 되는 광고를 기존에 본 광고들의 연관성을 계산하여 가중치로 표현(모든 광고에 대해서 집중을함)
- 그리고 Weighted Sum Pooling을 사용하여 여러 개의 표현 벡터를
가중 합한 값을 출력으로 사용함 - 따라서 Local Activation Layer를 이용하면 후보 광고에 따라 과거 User Behavior에서 소비했던 광고들의 weight 크기가 달라지게됨(집중해해야할 정보가 달라지는 것)
05. Behavior Sequence Transformer
- Behavior Sequence Transformer는 user behavior sequence를 가지고 Transformer의 Encoder를 사용하여 CTR 예측을 하는 모델임(DIN의 user behavior feature를 user behavior sequence로, local activation layer를 transformer layer로 표현함)
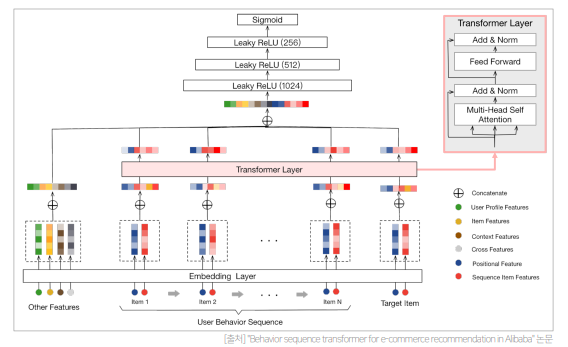
- 전체적인 구조는 Transformer와 유사하나, (Transformer에 대한 설명은 본 포스팅을 참고) dropout과 leakyReLU 추가되고 Layer를 1개만 사용하고, Target item을 사용한 시간에서 input item을 사용한 시간을 뺀 Custom Positional Encoding을 사용한다는 것이 특징임
- 본 논문에서 Transformer 블록을 2개 이상 쌓을 때 오히려 성능이 감소한다고 함, 이 이유는 CTR 예측 Task의 sequence는 machine translation와 같은 NLP sequence보다는 덜 복잡하기 때문인 것으로 생각됨

Machine Learning Engineer at Konan Technology