Context-aware Recommendation
00. 학습 내용
- Context-aware Recommendation에 대하여 학습
- Factorization Machine에 대하여 학습
- Field-aware Factorization Machine에 대하여 학습
- Gradient Boosting Machine에 대하여 학습
01. Context-aware Recommendation
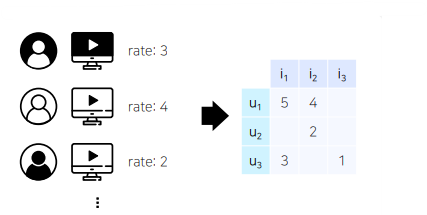
- 우리가 앞서 배운 MF, NCF 등의 모델은 유저 - 아이템 상호작용 정보를 사용하는 모델임
- 그런데 이러한 모델들은 유저의 데모그래픽이나 아이템의 카테고리 및 태그 등 여러 특성(feature)들을 추천 시스템에 반영할 수 없다는 단점이 존재함
- 따라서 상호 작용 정보가 아직 부족한 아이템 또는 유저의 경우 추천을 할 수 없는 cold-start problem이 발생함
- 이에 유저와 아이템의 맥락적 정보(유저, 아이템 관련 정보)도 반영하며 모델링을 할 필요성이 증가함
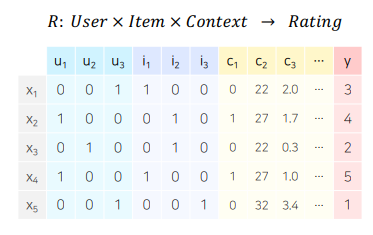
- 유저와 아이템 간 상호작용 정보 뿐만 아니라, 맥락(context)적 정보도 함께 반영하는 추천 시스템이 바로 Context-aware Recommender System
- 컨텍스트 기반 추천 시스템의 대표적인 예시가 바로 유저가 주어진 아이템을 클릭할 확률(probability)을 예측하는 문제인 CTR 예측임(대표 예시가 광고이며, 광고가 노출된 상황의 다양한 유저, 광고, 컨텍스트 피쳐를 모델의 입력 변수로 사용하여 광고를 클릭할 확률을 예측함)
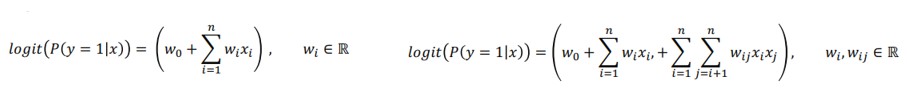
- CTR 예측의 타겟 값은 0(클릭 X) 또는 1(클릭 O)이기 때문에 이진 분류(binary classification) 문제에 해당함
- 따라서 위 그림에 왼쪽 식과 같이 단순히 Logistic Regression로 접근할 수도 있고, 변수 간 상호 작용을 고려하는 Polynomial Model로도 접근할 수 있음
- 추천에서는 변수 간 상호 작용, 즉 아이템간 유저간 상호 작용을 모델에 반영하는 것이 핵심이기 때문에 Polynomial Model의 형태를 많이 사용함(사실 딥러닝의 선형 결합 자체가 다양한 변수의 상호 작용을 고려하는 것이라고 볼 수 있기 때문에 딥러닝도 넒은 의미에서는 Polynomial Model에 한 형태라고 생각함)
- 우리가 보통 유저와 아이템 관련 정보, 즉 카테고리 변수의 경우 One-hot Encoding 형태의 sparse feature로 나타내게 되는데 이는 모델의 파라미터의 수를 증가시켜서 과적합과 과소적합을 유발하기 때문에, 우리는sparse feature를 dense feature로 나타내기 위해서 Feature Embedding을 사용함(우리가 앞으로 다룰 모델들도 Feature Embedding을 사용하는 형태임)
02. Factorization Machine
- Factorization Machine은 sparse한 데이터에 대해서 좋은 성능을 보이는 MF와 커널 공간을 활용하여 비선형 데이터셋에 대해서 높은 성능을 보이는 SVM을 서로 결합한 모델임
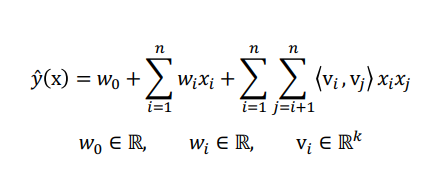
- FM의 공식은 Polynomial Model과 매우 유사한 것을 알 수 있고, global bias와 단순한 선형 결합, 피쳐간의 상호작용을 표현하는 Factorization term으로 이루어짐

- Factorization term은 위 식과 같이 유도되며 선형의 시간복잡도를 갖게됨
- 또한 각 상호 작용 변수마다 서로 다른 Weigh는 갖게 되어 모델이 상호작용을 표현할 수 있게됨
- MF와 달리 유저, 아이템 ID 외에 다른 부가 정보들을 모델의 피쳐로 사용할 수 있다는 장점과, SVM과 달리 선형의 시간복잡도를 가져 모델의 학습이 빠르다는 장점을 가짐
03. Field-aware Factorization Machine
- Field-aware Factorization Machine은 Pairwise Interaction Tensor Factorization 모델의 아이디어를 FM에 추가하여 성능을 높인 모델임
- PITF는 (user, item, tag) 3개의 필드에 대한 클릭률을 예측하기 위해 (user, item), (item, tag), (user, tag) 각각에 대해서 서로 다른 latent factor를 정의하여 구했는데, FFM은 이를 일반화하여 여러 개의 필드에 대해서 latent factor를 정의하여 모델을 학습시킴 (간단하게 말하면 하나의 변수와 여러 필드의 결합으로 표현되는 파라미터를 사용하여 조금 더 상호 작용을 고도화 하는 방식이라고 볼 수 있음)
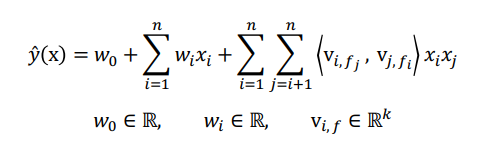
- FFM의 식은 위와 같으며, Factorization term을 보면 입력 변수를 필드(field)로 나누어 필드별로 서로 다른 latent factor를 가지도록 factorize하는 것을 알 수 있음
- 따라서 기존 FM은 하나의 변수에 대해서 k개로 factorize하기 때문에 k개 만큼의 파리미터를 학습하지만, FFM은 f개의 필드에 대해 각각 k개로 factorize하기 때문에 필드 개수 x k 만큼의 파라미터를 학습함(이 부분이 조금 더 고도화된 상호작용을 반영하는 부분이라고 할 수 있음, 그런데 파라미터의 수가 증가한 만큼 과적합이 발생할 확률도 더 높아지지 않을까라고 생각됨)
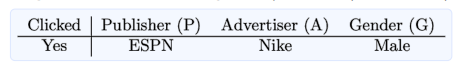
- 조금더 자세하게 설명하면, 클릭을 예측하는데 feature가 총 3개 Publisher, Advertiser, Gender가 존재하고, 각 feature를 필드 P, A, G로 정의한다면
- FM은 예측 값이 로 정의됨
- FFM은 예측 값이 로 정의됨
- 이처럼 FFM은 각 변수마다 해당하는 필드 값의 학습 파라미터가 따로 존재한다는 것을 알 수 있음
- 그런데 지금까지 다룬 FM, FFM은 모두 선형 모델이라는 한계점을 가지기 때문에 우리가 앞으로 다룰 DeepFM이 더 많이 쓰일 수도 있음
04. Gradient Boosting Machine
- GBM은 의사결정 나무(decision tree)로 된 weak learner들을 연속적으로 학습하여 결합하는 방식인 Boosting 기반의 Ensemble 모델임
- 유저 정보, 아이템 정보, 유저-아이템 상호작용 정보 등을 GBM의 인풋으로 넣어서 CTR 예측을 할 수 있음
- GBM에 대한 자세한 설명은 과거 투빅스에서 내가 강의했던 자료를 보는 것을 추천함

Machine Learning Engineer at Konan Technology