Recommender System with Deep Learning (2)
00. 학습 내용
- GNN을 활용한 추천 시스템에 대하여 학습
- RNN을 활용한 추천 시스템에 대하여 학습
01. GNN을 활용한 추천 시스템
1) Graph Neural Network
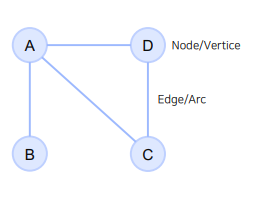
- Graph는 위 그림과 같이 Node와 그 Node들을 잇는 Edge들을 모아 구성한 자료구조를 말함
- Graph 자료 구조는 관계, 상호작용과 같은 추상적인 개념을 다루기에 적합하여 사용함
- 소셜 네트워크, 바이러스 확산 등 연결되어 있는 상황을 표현하는데 적합한 자료구조임(Node 와 Edge를 사용하여 단순한 관점으로 데이터를 나타낼 수 있음)
- Graph 자료 구조는 Non-Euclidean Space의 표현 및 학습이 가능하여 사용함
- 이미지, 텍스트, 정형 데이터는 Euclidean Space 형태의 데이터, 즉 유한한 실수 값으로 표현할 수 있는 데이터
- 소셜 네트워크, 분자 구조 등의 데이터는 Non-Euclidean Space 형태의 데이터, 즉 실수형으로 표현이 불가능한 데이터임 (상호 작용을 단순히 이미지처럼 0~255의 실수값으로 표현할 수 없음, 이에 필요한 것이 바로 그래프 형태의 자료구조)
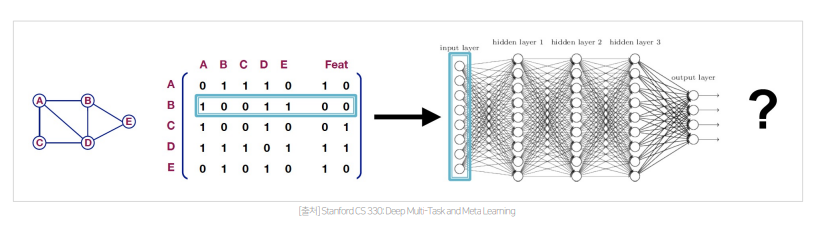
- GNN은 위에서 설명한 Graph 자료 구조를 표현할 수 있는 신경망임
- 아주 간단한 형태의 GNN은 위 그림과 같이 단순히 그래프를 인접 행렬 형태로 만들고 각 노드에 대한 feature를 열로 concat하여 MLP 에 넣는 방식임
- 그러나 이와 같은 단순한 방식은 노드가 많아질수록, 연산량이 증가하고, 노드의 순서가 바뀌면 의미가 달라질 수 있다는 매우 큰 한계가 존재
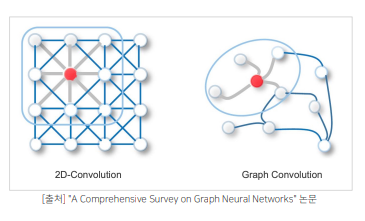
- 이러한 단순한 GNN의 접근법에 대한 한계를 해결한 방식이 바로 위 그림과 같은 형태의 Graph Convolution Network임
- GCN은 local connectivity, shared weights, multi-layer를 이용하여 convolution 효과를 만들어, 연산량은 줄이고 깊은 네트워크로 직접 연결된 노드 뿐만 아니라 간접적으로 연결된 노드와의 관계적 특징 까지 추출함
- GCN은 CNN과 매우 유사하다고 볼 수 있는데, 하나의 레이어가 shared weights를 이용해 필터와 비슷한 느낌으로 local connectivity를 학습하고 이는 곧 노드간의 관계적 특징을 추출한다고 볼 수 있고, 여기서 나온 아웃풋 임베딩을 다음 레이어에 활용함으로써 간접적으로 연결된 노드와의 관계적 특징 까지 추출한다고 볼 수 있음, 즉 multi-layer를 사용해 이웃노드와의 관계적 특징을 추출하는 것임
2) Neural Graph Collaborative Filtering
- NGCF는 유저-아이템 상호작용을 GNN을 활용해 인코딩하는 모델임
- 우리가 전에 다루었던 MF 기반의 CF 모델들은 대부분 유저-아이템의 상호 작용을 내적으로 표현하여 임베딩을 학습시켰기 때문에(또는 단순한 비선형 결합으로), 유저와 아이템 임베딩 자체에는 상호 작용 정보가 들어있지 않다고 볼 수 있고, 이는 부정확한 추천의 원인이 될 수 있음
- 그런데 NGCF는 유저-아이템의 상호 작용 정보를 임베딩에도 포함하는 방식으로 모델을 학습시킬 수 있음
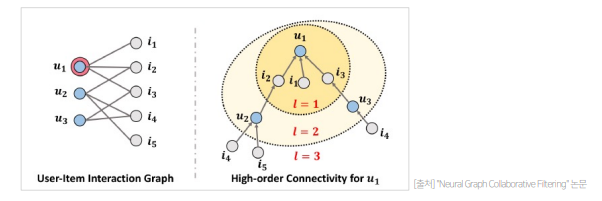
- 위처럼 GNN을 활용하면 High-order Connectivity를 임베딩할 수 있음
- 간단하게 말하자면 Layer를 쌓아가며 모델을 학습시키면서 유저와 아이템의 간접 관계를 학습시키는 것임
- High-order Connectivity를 임베딩 하게 되면, 위 그림에서 u1과 u2가 i2를 두고 서로 상호작용 할 수 있다고 볼 수 있는데, 이 임베딩을 활용해 u1에게 u2가 사용한 i4 or i5를 추천해줄 수 있게 되는 것임(즉 좀더 풍부하게 유저와 아이템간 상호작용 정보를 임베딩에 표현할 수 있는 것)
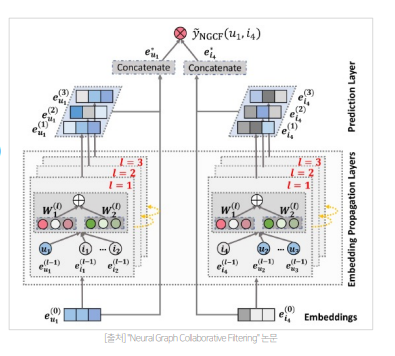
- NGCF는 유저-아이템의 초기 임베딩 정보를 제공하는 Embedding Layer, high-order connectivity 학습하는 Embedding Propagation Layer, 서로 다른 전파 레이어에서 refine된 임베딩 concat하여 유저-아이템 선호도를 예측하는 Prediction Layer로 이루어짐
- 그림으로 보면 각 학습이 병렬적으로 이루어지는 것처럼 보이지만 사실은 각 학습은 순차적으로 이루어짐(Layer1이 Item 임베딩과 User 임베딩을 학습하고, 그 임베딩을 활용하여 그 다음 Item 임베딩과 User 임베딩을 구함)

- Embedding Layer의 Embedding은 위 그림과 같이 각 아이템과 유저의 수 만큼 존재함
- 기존의 MF, NCF는 임베딩이 곧바로 interaction function에 입력되었다면(내적, MLP 레이어 등), NGCF에서는 이 임베딩을 GNN 상에서 전파시켜 계속해서 refine함(Collaborative Signal을 명시적으로 임베딩 레이어에서 주입하기 위한 과정임)

- Embedding Propagation Layer는 위 식을 활용해 유저-아이템의 collaborative signal을 담을 'message'를 구성하고 결합함
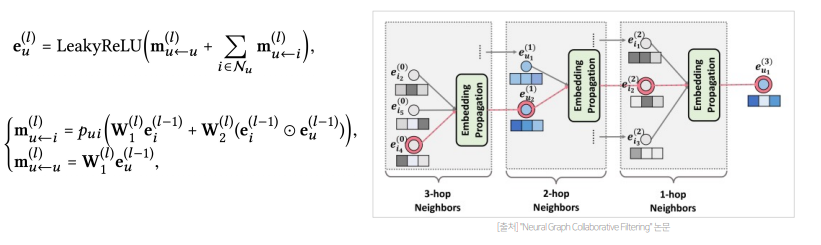
- 위처럼 l 단계에서 유저 u의 임베딩은 (l − 1) 단계의 임베딩을 통해 재귀적으로 학습됨으로써, high-order connectivity 학습할 수 있음(item도 동일함)
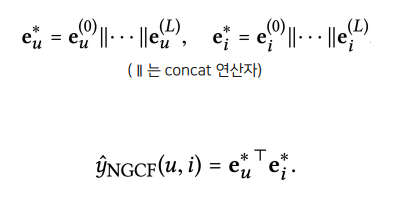
- 최종적으로 각 레이어마다 refine된 임베딩을 모두 concat하여 최종 임베딩 벡터를 계산 후(유저와 아이템 임베딩 벡터를 각각 서로 다른 linear layer에 태운다는 것), 유저-아이템 벡터를 내적하여 최종 선호도 예측값을 계산함
- 위 과정을 코드로 구현하면, 전체 임베딩을 활용하여 계산 후에 각 배치에 맞는 user, pos item, neg item의 임베딩만 추출하여 Loss를 계산하여 임베딩을 업데이트 함
- 결과적으로 임베딩 전파 레이어가 많아질수록 모델의 추천 성능 향상되지만, 레이어가 너무 많이 쌓이면 overfitting 발생 가능하기 때문에 대략 3 ~ 4일 때 가장 좋은 성능을 보인다고 함
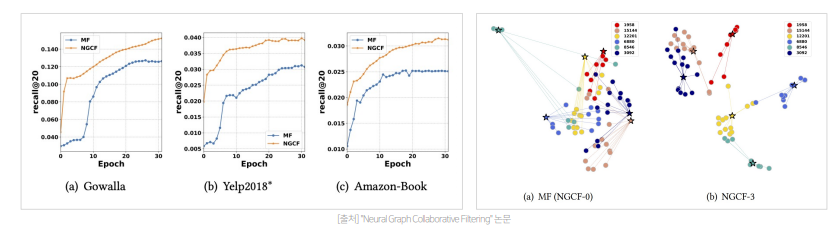
- MF에 비해 NGCF는 Model Capacity가 크고 임베딩 전파를 통해 representation power가 좋아졌기 때문에 MF와 비교하여 유저-아이템이 임베딩 공간에서 더 명확하게 구분되고 더 좋은 성능을 보임
3) LightGCN
- LightGCN은 GCN의 가장 핵심적인 부분을 약간 수정하여 만든 더 정확하고 가벼운 형태의 모델임
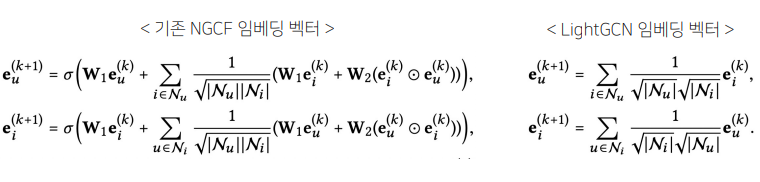
- LightGCN은 NGCF와 달리 feature transformation이나 nonlinear activation를 제거하고 단순히 가중합으로 convolution을 구성하여 학습 파라미터와 연산량이 감소함(Light Graph Convolution)
- 따라서 학습 파라미터는 0번째 임베딩 레이어에만 존재하고, 연결된 노드만 사용하였기 때문에 self-connection이 없음
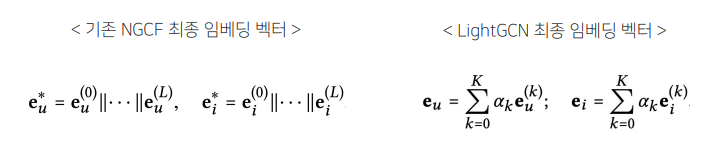
- 레이어가 깊어질수록 강도가 약해질 것이라는 아이디어를 적용해 단순히 k-층으로 된 레이어의 임베딩을 각각 ak배 하여 가중합으로 최종 임베딩 벡터를 계산함
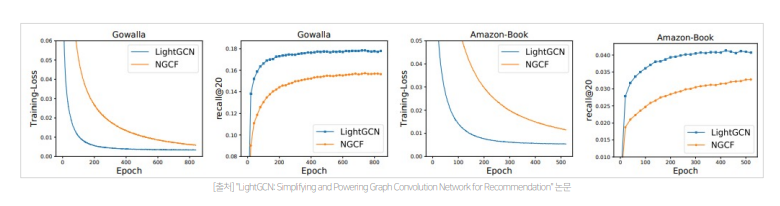
- 학습을 통한 손실 함수와 추천 성능 모두 NGCF보다 뛰어남(학습해야할 파라미터의 수가 매우 적어짐에 따라서 모델의 Generalization Power가 커진 것으로 생각됨)
02. RNN을 활용한 추천 시스템
1) Session based Recommender System
- Session은 유저가 서비스를 이용하는 동안의 행동을 기록한 데이터
- 고객의 선호는 고정된 것이 아님, 예를 들어 어제와 오늘 고객이 좋아하는 아이템이 달라질 수 있고, 현재 핸드폰을 샀다면 유저에게 핸드폰을 추천해주어도 핸드폰을 구매할 확률을 매우 적을 것임
- 따라서 이처럼 고객의 행동 정보를 모델링 하는 것은 중요하고 이러한 고객의 행동 정보 데이터인 Session을 가지고 '지금' 고객이 좋아하는 것을 추천하는 방식이 바로 Session based Recommender System 임
2) GRU4Rec
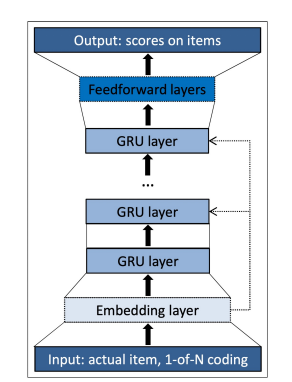
- GRU4Rec은 Session이라는 시퀀스를 GRU 레이어에 입력하여 바로 다음에 올 확률이 가장 높은 아이템을 추천하는 모델임
- one-hot encoding된 session을 입력으로 받아서 시퀀스 상 모든 아이템들에 대한 맥락적 관계를 GRU 레이어를 이용해 학습하고 다음에 골라질 아이템에 대한 선호도 스코어 값을 출력함
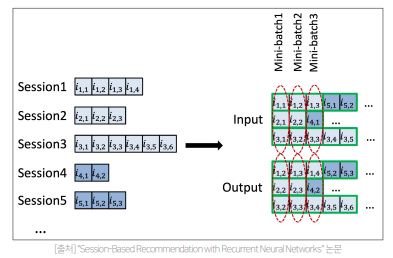
- 대부분의 세션은 매우 짧지만 길이가 긴 것도 존재하여, 길이가 짧은 세션들이 단독 사용되어 idle 하지 않도록, 세션을 병렬적으로 구성하여 미니 배치 학습(Session Parallel Mini batches)
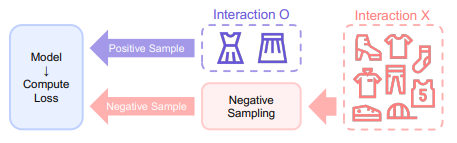
- 현실에서는 아이템의 수가 많기 때문에 모든 후보 아이템의 확률을 계산하는 것은 매우 많은 시간이 걸림, 따라서 아이템을 negative sampling하여 subset만으로 loss를 계산
- 여기서 negative sampling은 모델에 성능에 많은 영향을 끼칠 것임 (유저가 현재 구매하지 않은 아이템일 뿐이지 미래에 구입할 아이템이 negative sampling에 포함된다면 그 유저에게 해당 아이템을 추천할 기회를 잃게 됨)
- 따라서 인기에 기반한 Negative Sampling 제시함
- 아이템의 인기가 높은데도 상호작용이 없었다면 사용자가 관심이 없는 아이템이라고 가정하여 Negative Sampling을 진행함(인기가 적은데 상호작용이 없다면 유저가 그 아이템을 싫어하기 보다는 존재 자체를 모르는 것일 확률이 높음)

Machine Learning Engineer at Konan Technology
정말 유익한 포스트입니다..추천시스템의 딥러닝 카테고리는 정말 다양한데 깔끔하게 핵심 정리해주셔서 넘 감사합니다. 특히 NGCF 관련 내용은 정말 흥미롭네요 :)