
2. CCTV 데이터 훑어보기
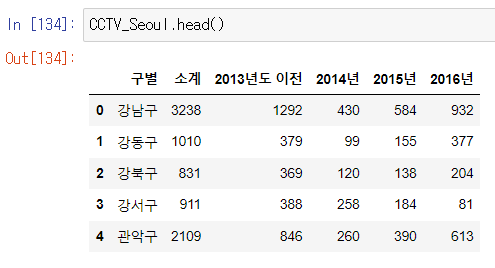
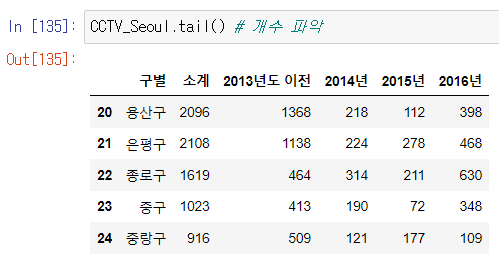
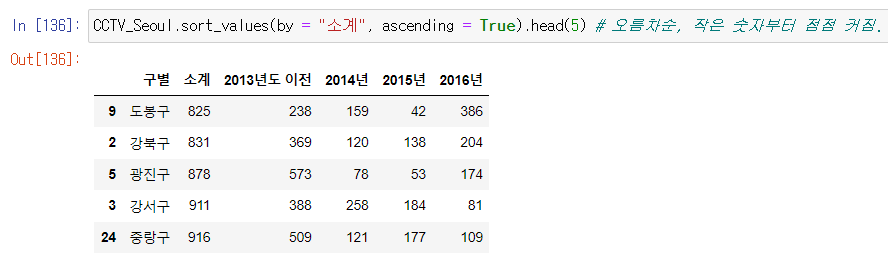
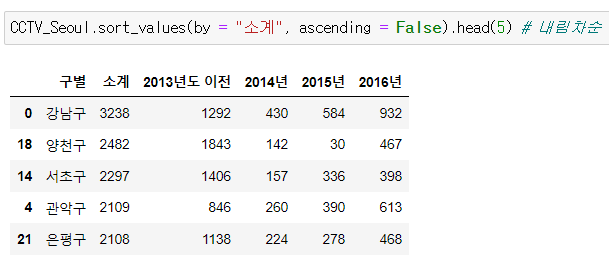
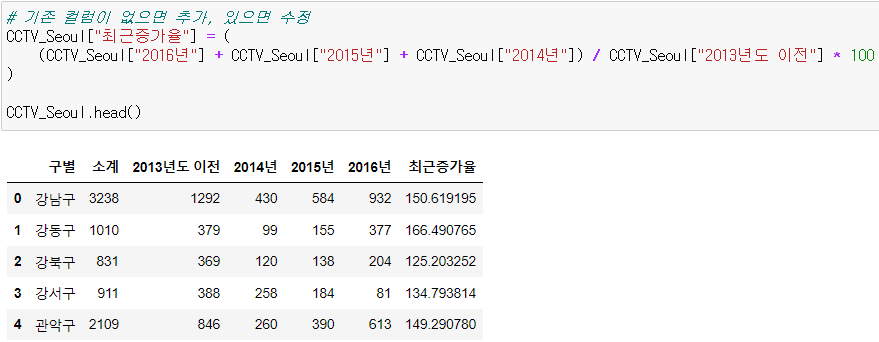
- 컬럼 추가 하는 법 주의 !
3. 인구현황 데이터 훑어보기
※ axis = 1 이면 세로, axis = 0 이면 가로 ※
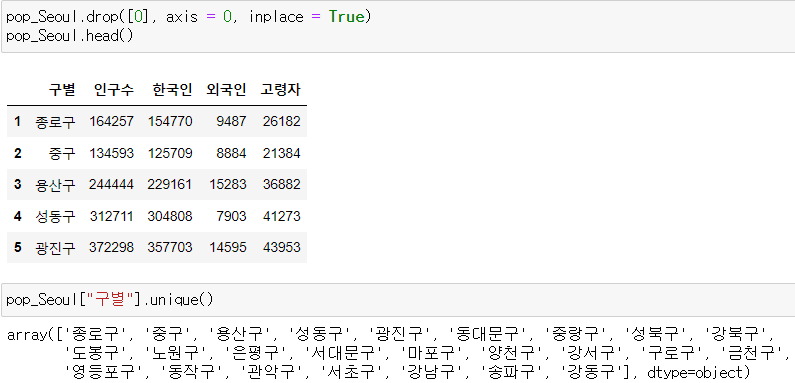
unique() 메서드란? : 데이터가 중복되지 않게 한 번만 나오게 출력해줌.
외국인 비율, 고령자 비율을 만들어 표에 삽입해보자
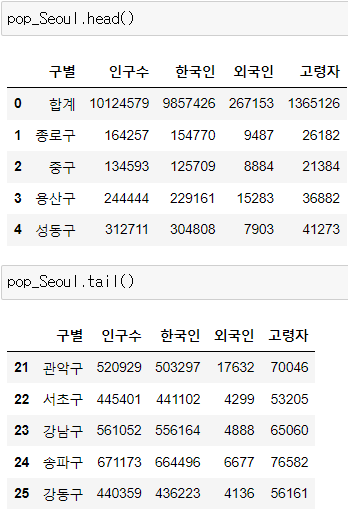
먼저, 보기 데이터
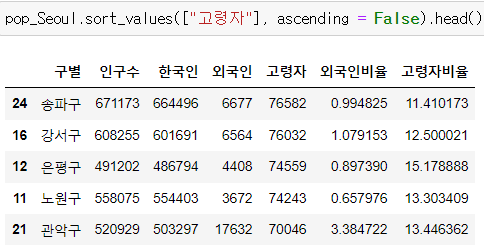
이렇게 컬럼은 구별, 인구수, 한국인, 외국인, 고령자 이렇게 5개 밖에 없다. 그러나 우리는 외국인 비율이 얼만큼되는지, 고령자 비율은 얼만큼 되는지를 알아내서 그 비중을 알아내고자 한다.
이렇게 외국인비율 컬럼과 고령자비율 컬럼을 만들어낸다.
이제 이리저리 인구현황 데이터들을 살펴보자, 여기에서는 코드만 주어지니, 결과를 보고 알아서 코드 내용을 유추해보자.
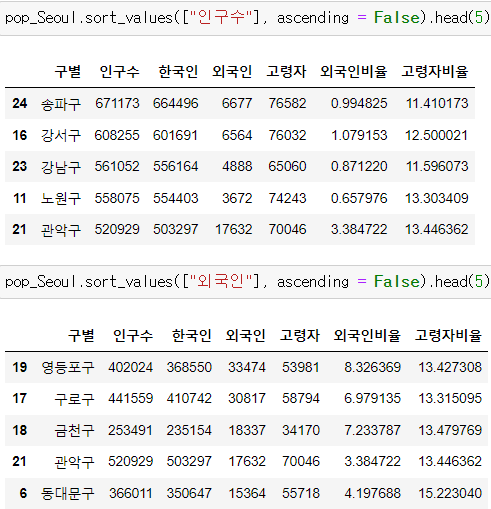
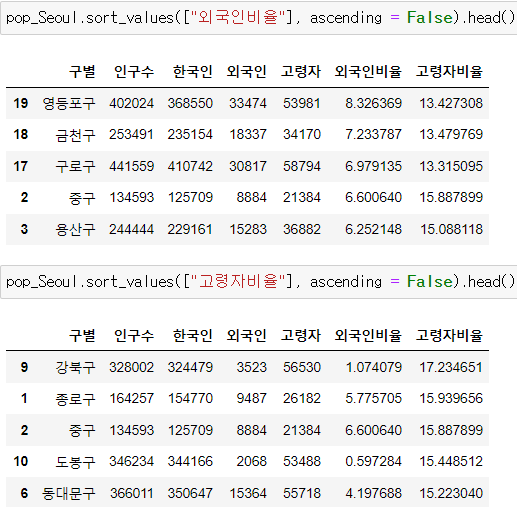
4. 두 데이터 합치기
판다스에서 데이터를 병합하는 방법
- pd.concat()
- pd.merge()
- pd.join()
pd.merge()
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 데이터를 병합해주는 방법
- 기준이 되는 컬럼이나 인덱스를 "키" 값이라고 합니다.
- 기준이 되는 기 값은 두 데이터 프레임에 모두 포함되어 있어야 합니다.
데이터 병합하는 순서는 다음과 같다.
우선 병합할 데이터 2개(혹은 그 이상, 그러나 여기서는 두 개로 가정)가 필요하다.
그 다음 병합. 이 순서이다.
데이터 만들기: 데이터 이름을 left, right라고 하자.
여기서는 딕셔너리 안에 키의 벨류를 리스트 형태로 만들어 기술하여 데이터를 만들었다.
하지만 여기서는 리스트 안에 딕셔너리 형태로 데이터를 만들었다.
이제 두 데이터를 만들었으니, 합쳐보자!
기본 형태 => pd.merge(데이터1, 데이터2)
더 세분화하면...
이렇게 어떠한 컬럼을 기준으로 병합을 해라 라고 설정을 할 수 도 있다.
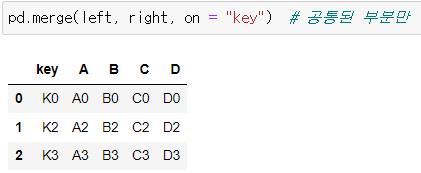
또한, 자세히 보면 right랑 left 데이터들이 갖고 있는 키 컬럼의 키 값이 다르다.
그래서 어떤 것을 기준으로 병합을 할지도 정해줄 수 있다.
how = "left" : left를 기준으로 병합

how = "right" : right를 기준으로 병합!
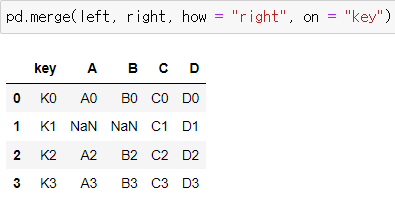
두 개다 포함 시키는 것: how = "outer" / 공통 분모만 포함: how = "inner"

데이터 컬럼 삭제
- del
- drop()
ex) del data_result["2013년도 이전"] => "2013년도 이전" 컬럼 삭제
ex) data_result.drop(["2015년", "2016년"], axis = 1, inplace = True) # axis가 기본 0으로 되어있고 이는 가로 축을 의미함
=> "2015년", "2016년" 컬럼 삭제
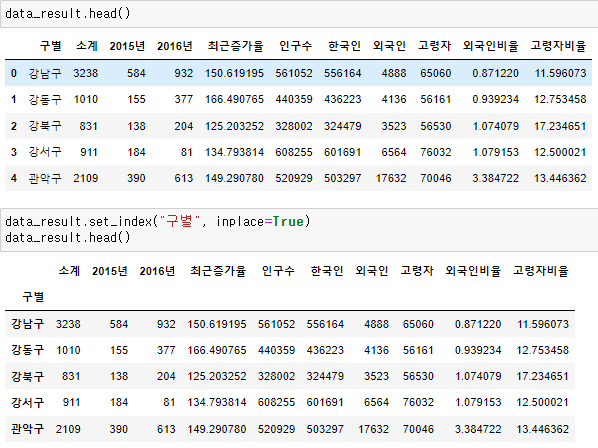
인덱스 변경
- set_index()
- 선택한 컬럼을 데이터 프레임의 인덱스로 지정
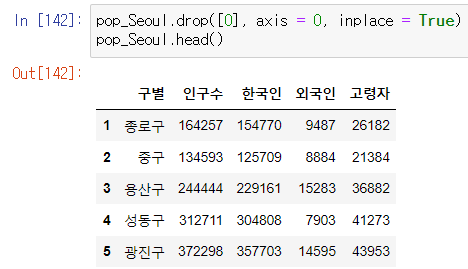
원래 데이터 프레임의 인덱스는 숫자였다. 다음 사진을 보자.
이제 데이터 프레임의 인덱스를 구 이름으로 바꿔보자
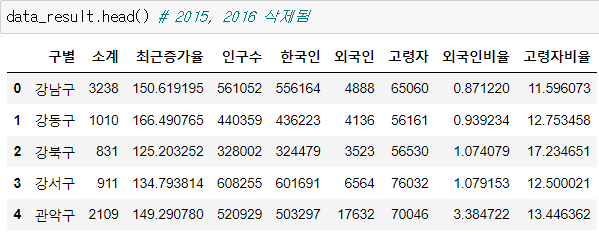
data_result.set_index("구별", inplace = True)
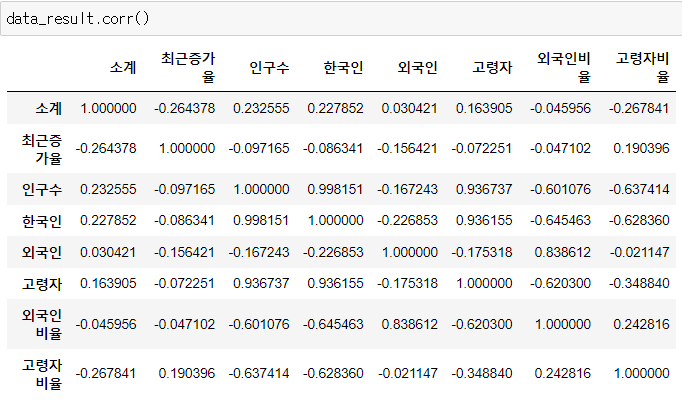
상관계수
- corr()
- correlation의 약자
- 상관계수가 0.2 이상인 데이터를 비교
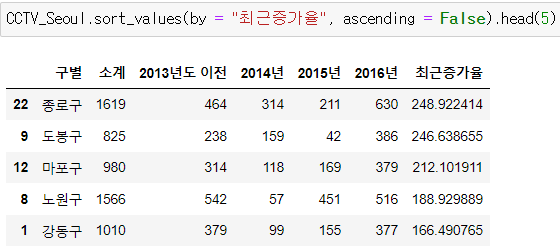
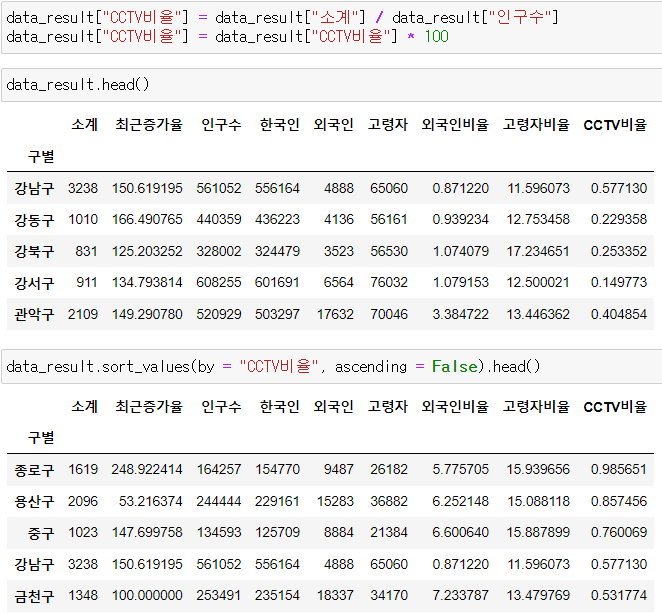
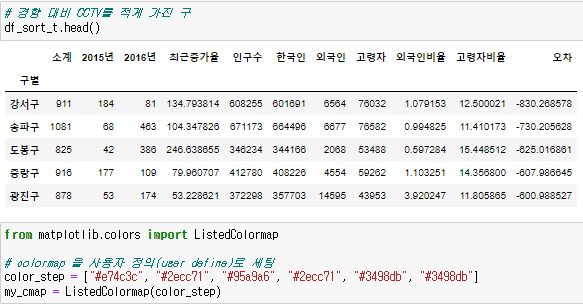
CCTV 비율 컬럼을 새로 만들고 CCTV 비율이 가장 높은 구를 알아보자!
matplotlib 기초
matplotlib 이란?
데이터를 다양한 그래프로 만들어주는 파이썬 라이브러리
데이터 시각화를 도와주는 라이브러리.
시작하는 방법
import matplotlib.pyplot as plt
%matplotlib inline # -> jupyter notebook에 그래프 표시하도록 설정하기, 이것이 " get_ipython().run_line_magic("matplotlib", "inline") " 랑 같은 기능을 한다.
참고 : https://defineall.tistory.com/811
matplotlib 그래프 기본 형태
- plt.figure(figsize = (10, 6)) => 사이즈 결정
- plt.plot(x, y) => x 축, y 축 결정
- plt.show() => 그래프 보이게 하기
예제1: 그래프 기초
삼각함수 그리기
- np.arange(a, b, s): a부터 b까지 s의 간격
- np.sin(value)
그래프를 그리기 전에 x 축 범위와 y축 범위를 먼저 설정해야 하는 것을 잊지 말자.
하지만, 여기서 끝이 아니다! 그래프가 아직은 조금 허전해 보인다.
- 격자 무늬 추가
- 그래프 제목 추가
- x축, y축 제목 추가
- 주황색, 파란색 선 데이터 의미 구분
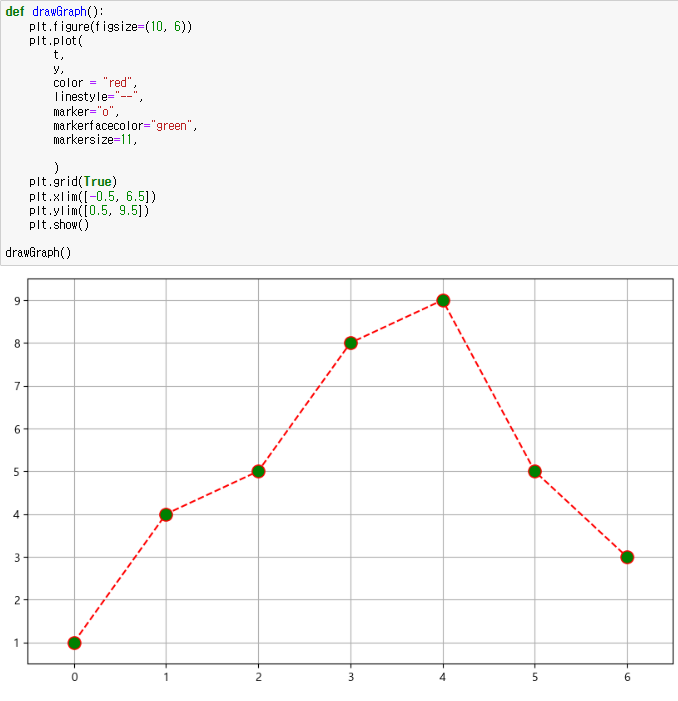
예제 2 그래프 커스텀
지금까지는 그래프의 기초를 배웠다. 그러나 그래프를 더욱더 세심하게 커스텀할 수도 있다!
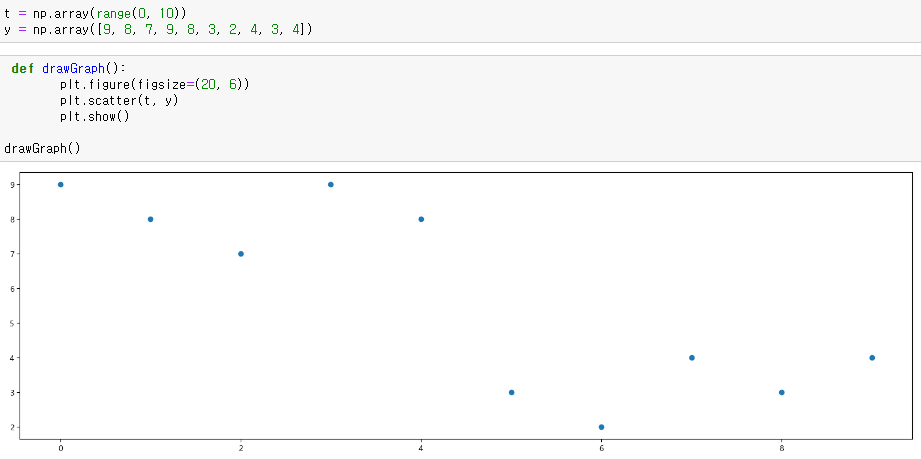
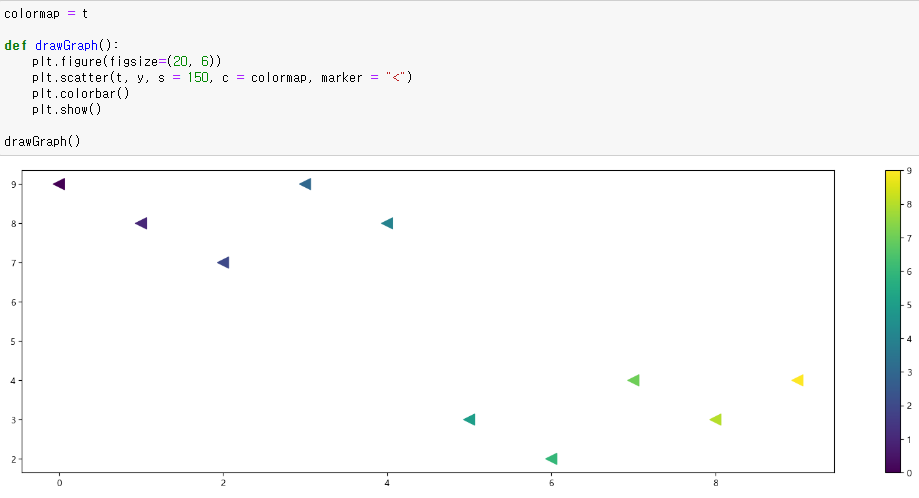
예제 3 scatter plot
예제 4 Pandas에서 plot 그리기
- matplotlib을 가져와서 사용한다.

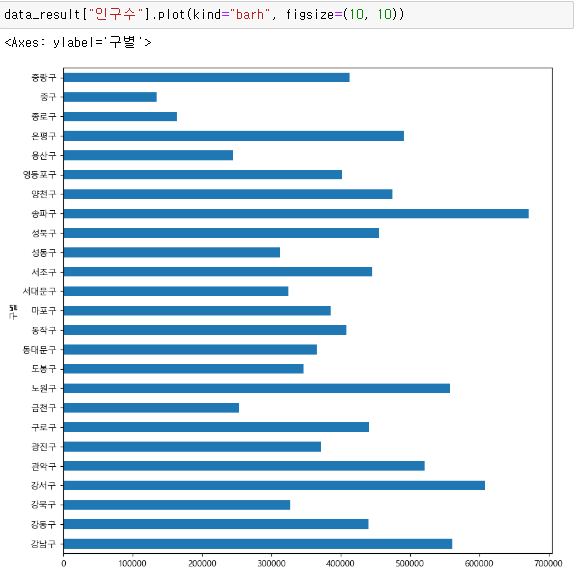
5. 데이터 시각화
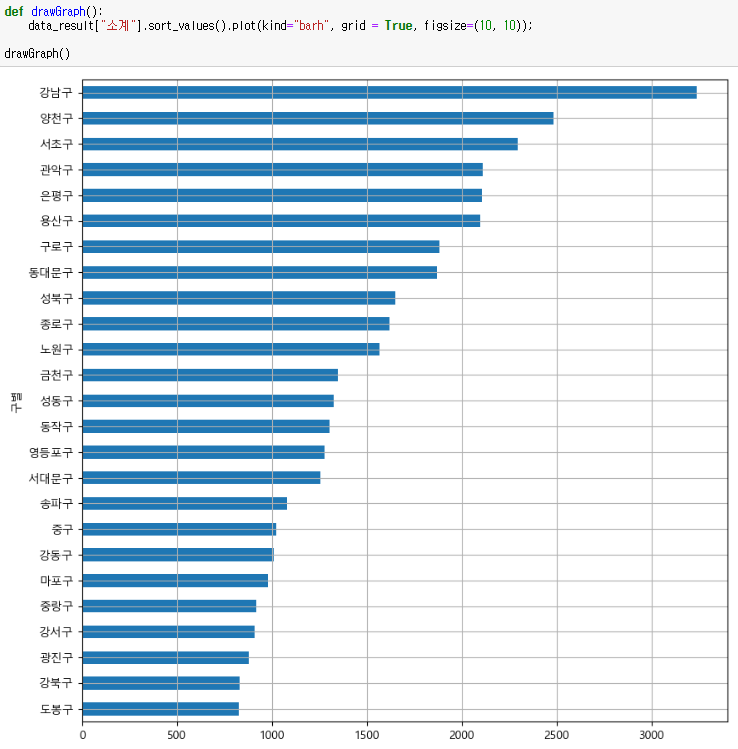
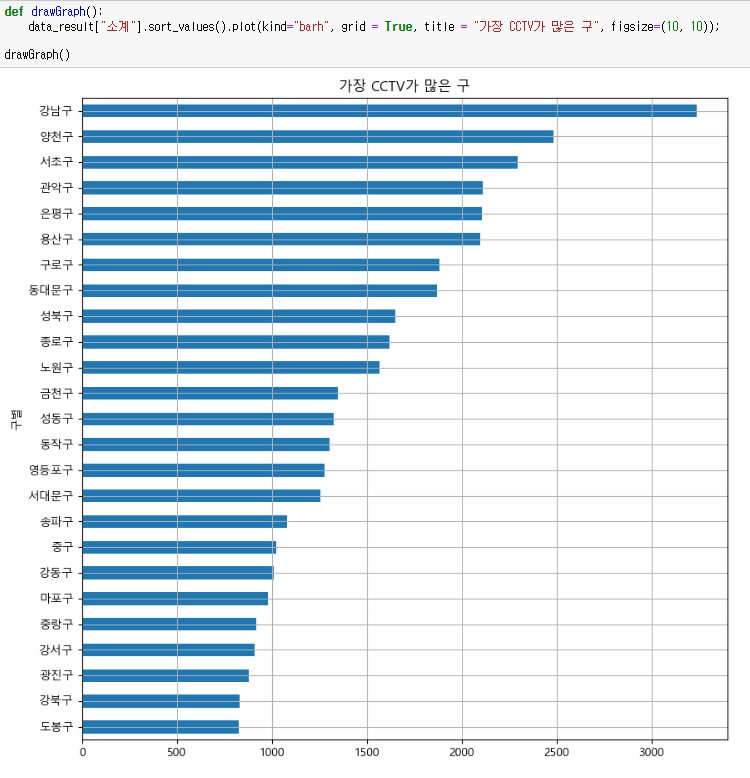
소계 컬럼을 시각화 해보자!
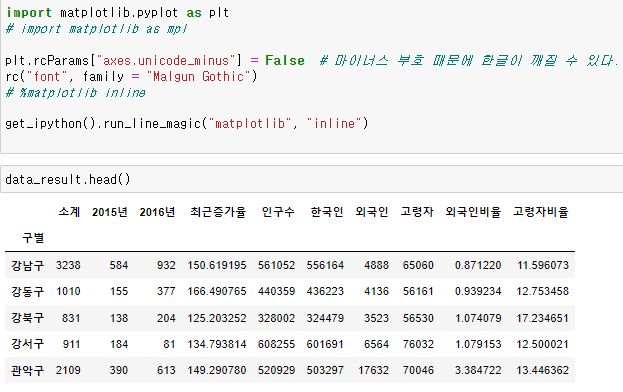
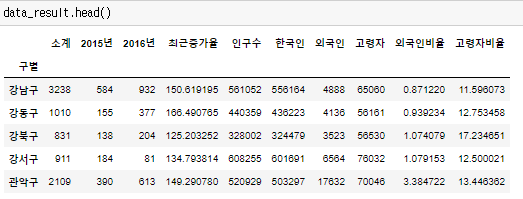
데이터 보기
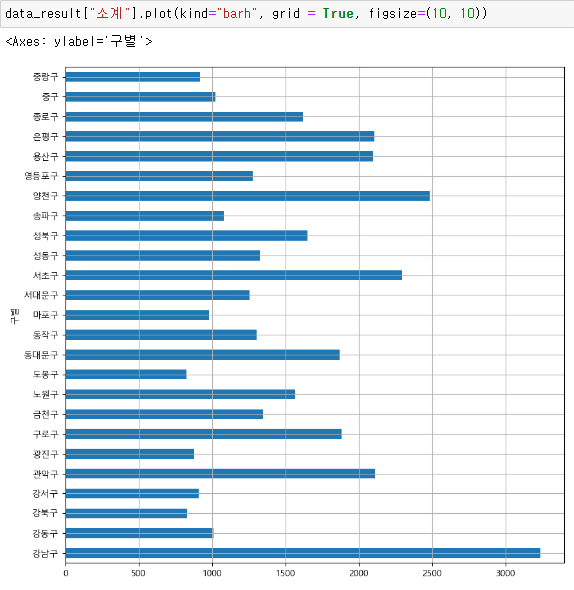
6. 데이터 경향 표시
데이터 보기

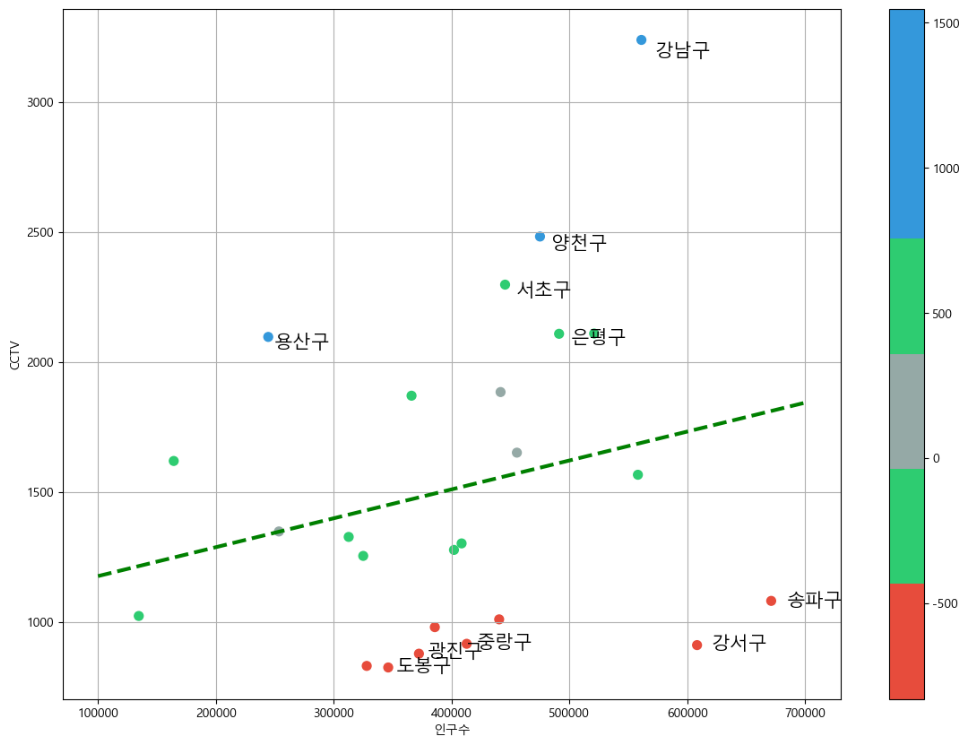
인구 수와 소계 컬럼으로 scatter plot 그리기
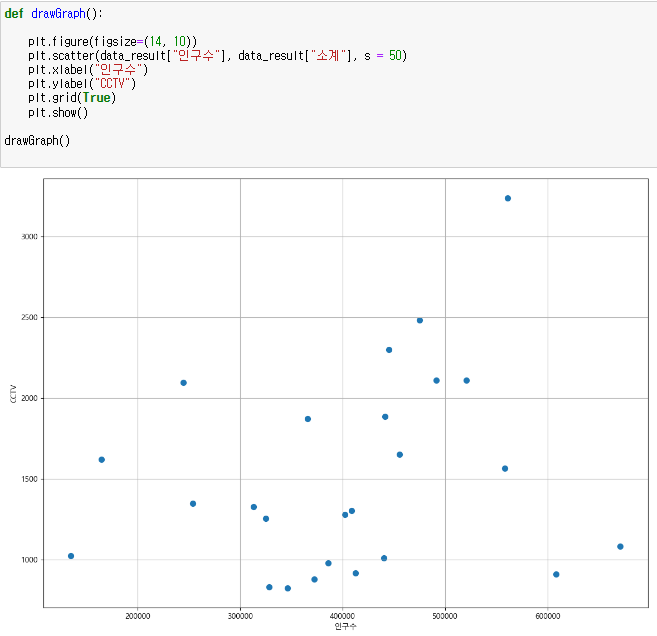
Numpy를 이용한 1차 직선 만들기
- np.polyfit(): 직선을 구성하기 위한 계수를 계산
- np.poly1d(): polyfit 으로 찾은 계수로 파이썬에서 사용할 수 있는 함수로 만들어주는 기능
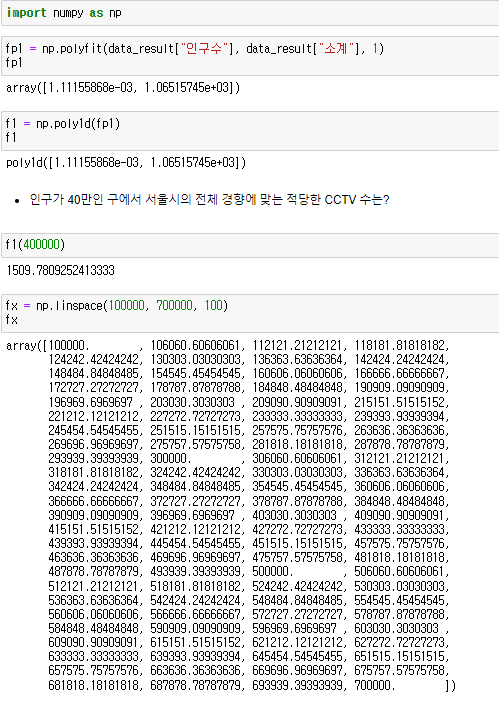
경향선을 그리기 위한 X 데이터 생성
- np.linspace(a, b, n): a부터 b까지 n개의 등간격 데이터 생성
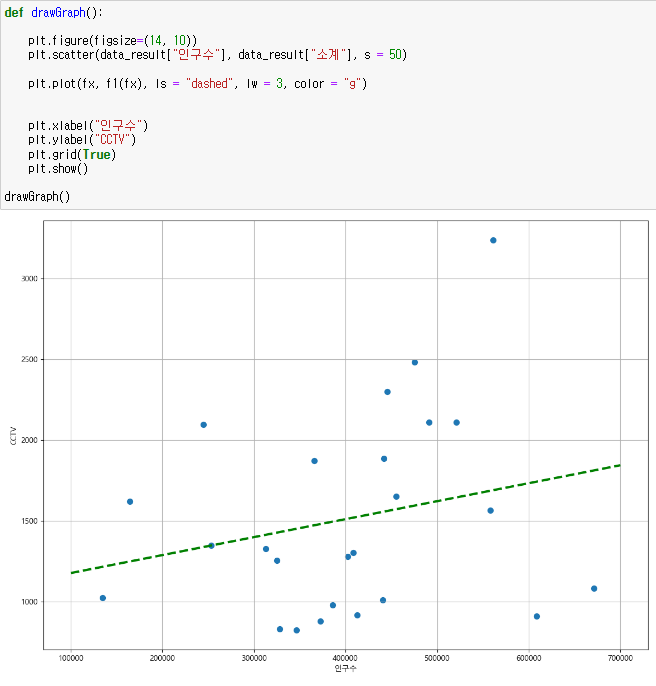
7. 강조하고 싶은 데이터를 시각화해보자
그래프 다듬기
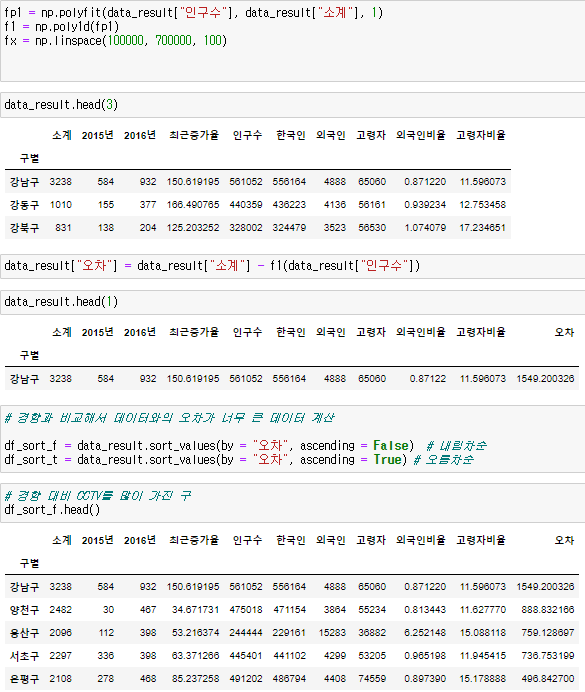
경향과의 오차를 만들고 그래프로 표현하기
- 경향(trend)과의 오차를 만들자
- 경향은 f1함수에 해당 인구를 입력
- f1(data_result["인구수"])

참고하면 좋은 곳
https://pinkwink.kr/1127
