Pandas 기초
- Python에서 R 만큼의 강력한 데이터 헨들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 일각에서는 스테로이드를 맞은 엑셀로 표현함
Series
- index와 value로 이루어져 있다.
- 한 가지 데이터 타입만 가질 수 있습니다.
import pandas as pd
import numpy as nppandas는 통상 pd
numpy는 통상 np라고 한다.
Series 데이터란?
데이터프레임에서 컬럼 기준으로 한 줄 한 줄을 시리즈라고 부른다.
시리즈 데이터들이 한 줄 한 줄 모여서 데이터 프레임을 이룬다고 보면 된다.
이렇게 세로로 (컬럼) 한 줄 한 줄...
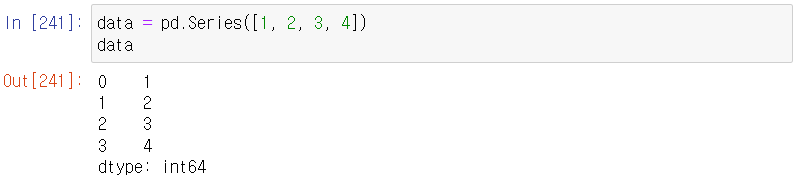
시리즈 데이터를 만들어보자: pd.Series()
pd.Series() -> 이게 가장 기본 형태
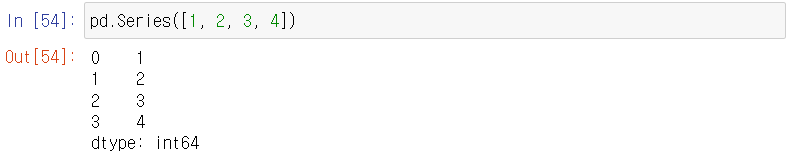
괄호 안에 무엇을 넣어야 할까? [1, 2, 3, 4] 를 넣어보자
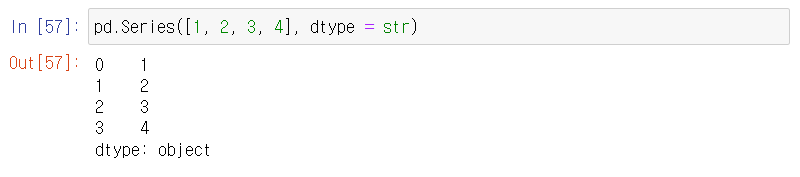
데이터 타입 / dtype을 정해줄 수도 있다.



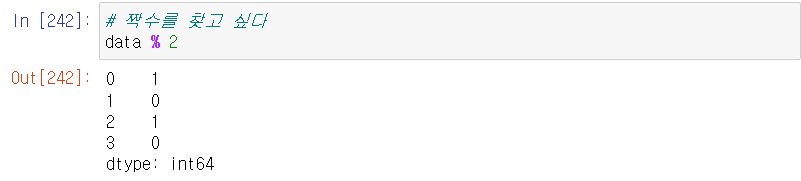
변수에 담긴 시리즈 데이터들을 계산할 수도 있다.
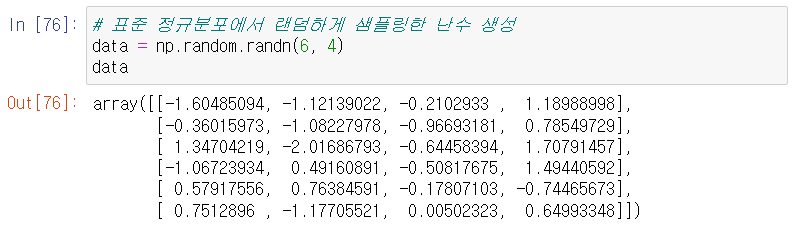
날짜 데이터를 만들어보자: pd.date_range()
pd.date_range("20230502", periods = 6)
이는 230502 를 시작으로 6개의 데이터를 만든다는 의미이다.

DataFrame
- pd.Series(): index, value
- pd.DataFrame() -index, value, column
- 데이터 프레임은 Series 들을 하나의 열로 취급한 집합이라고 보면 된다.
- 데이터들을 표의 형태로 처리하는 자료구조
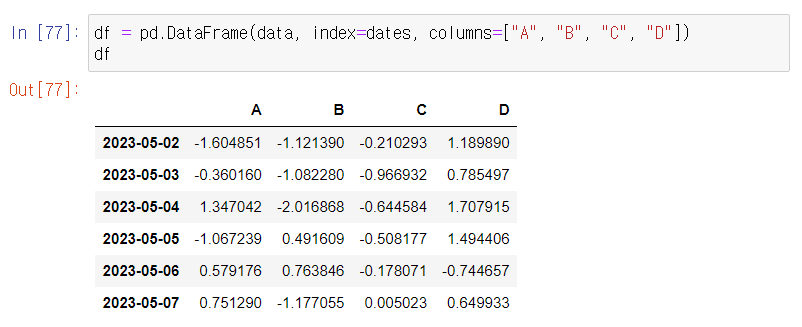
DataFrame 생성 방법: pd.DataFrame()
기본 구조: pd.DataFrame(data, index, columns)
예시) df = pd.DataFrame(data, index=dates, columns=["A", "B", "C", "D"])
하지만, 데이터프레임 안에 넣을 데이터가 필요하니, 먼저 데이터프레임 안에 담길 데이터를 만들어줘야 한다.
이제 데이터를 만들었으니, 데이터 프레임을 출력시켜보자
데이터 프레임 정보 탐색도 head()와 tail() !!
- df.index -> 인덱스(세로)만 검색
- df.values -> 안의 데이터들만 검색
- df.columns -> 컬럼들만 검색
- df.info() -> 데이터 프레임의 기본 정보 출력
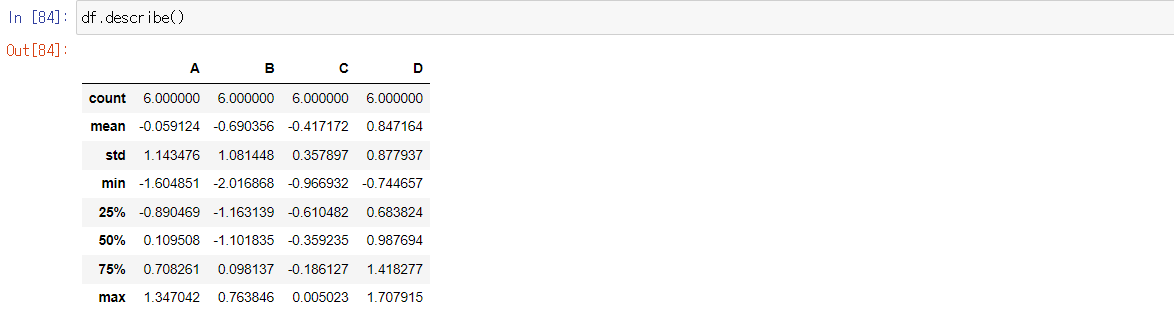
- df.describe() -> 데이터 프레임의 기술 통계 정보 확인
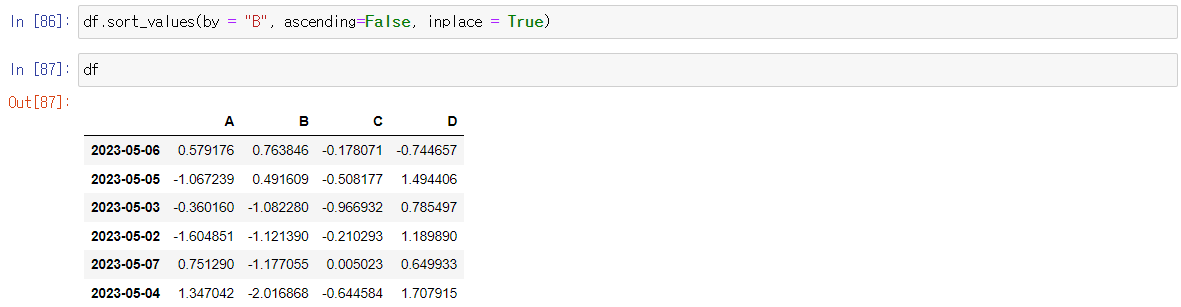
★ 데이터 정렬: sort_values()
- 특정 컬럼(열)을 기준으로 데이터를 정렬합니다.
원래 데이터 프레임과 내가 임의대로 정렬한 데이터 프레임을 비교해보자
원래 데이터 프레임
sort_values()를 써서 수정한 데이터 프레임
컬럼 선택하기: ["A"], 그 외 방법
type을 알아보자
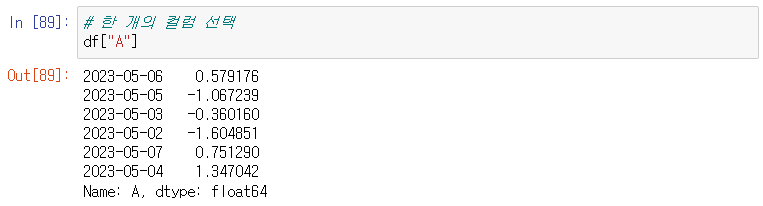

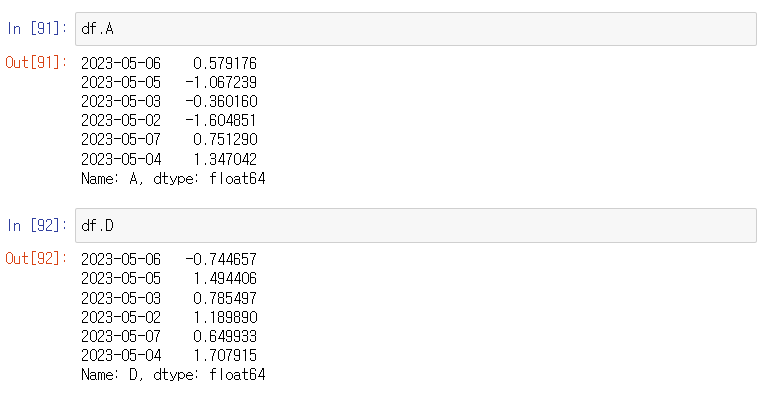
df.A, df.B 등으로도 알 수 있다.
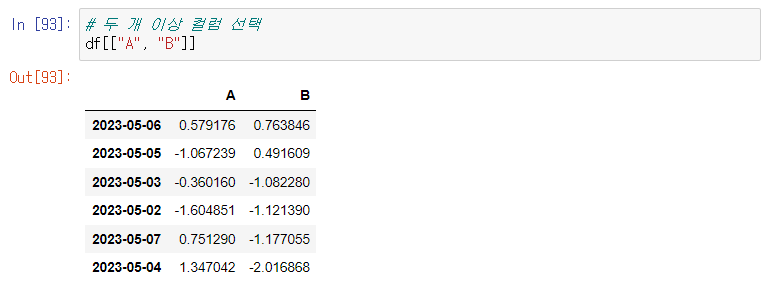
두 개 이상 컬럼 선택도 가능!
데이터 슬라이싱
offset index
- [n:m] : n부터 m-1까지
- 인덱스나 컬럼의 이름으로 slice 하는 경우는 끝을 포함합니다.
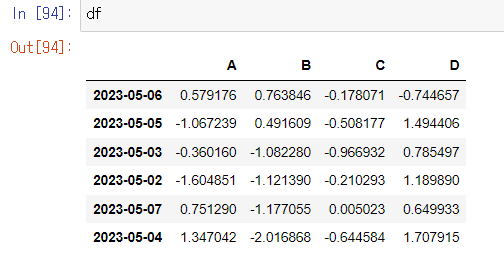
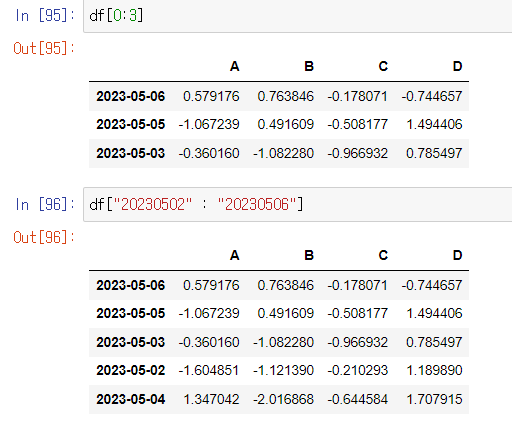
.loc []
- loc: location
- index 이름으로 특정 데이터 행, 열을 선택합니다.
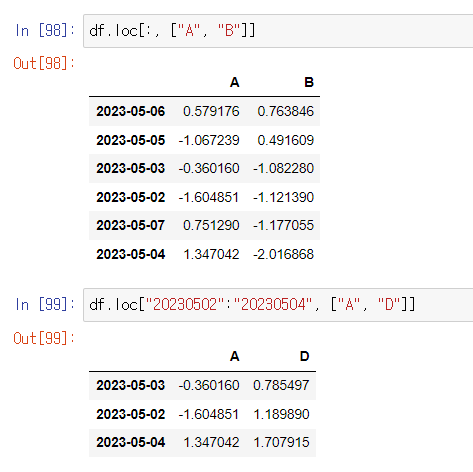
.iloc[]
-
사용 예시) df.iloc[3] / df.iloc[3:5, 0:2]
-
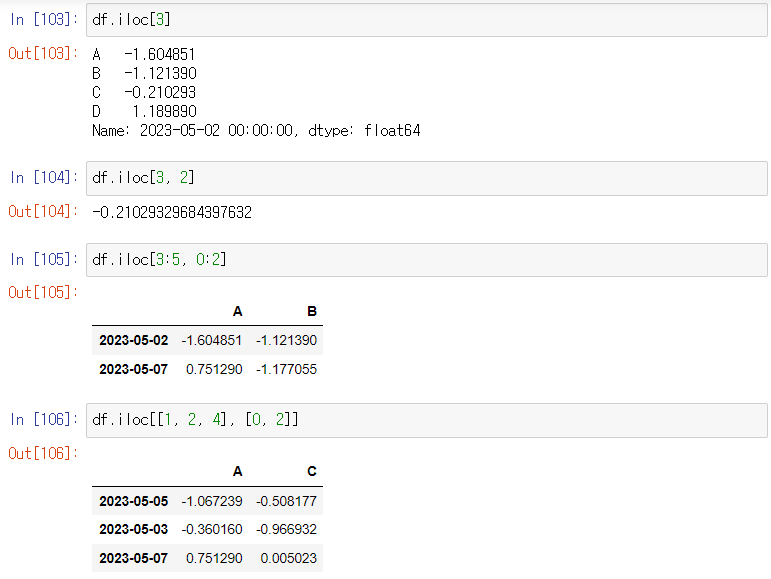
이 사진과 비교해서 어떻게 .iloc[] 가 작동하는지 익혀보자.
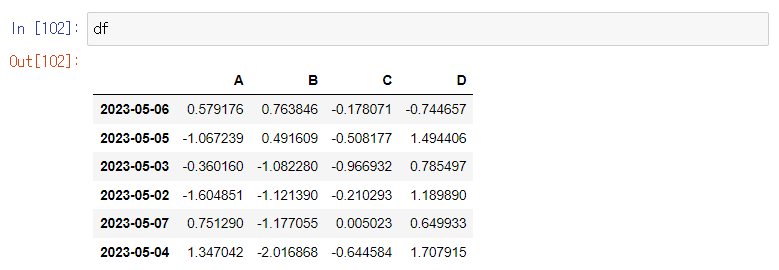
-
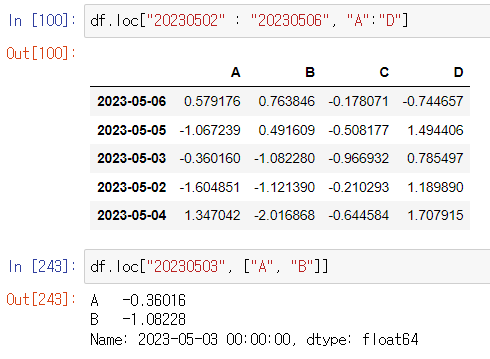
사용 예시 2) df.iloc[:, 1:3] => 앞에 있는 none 은 인덱스, 1:3은 특정 범위의 컬럼 지정
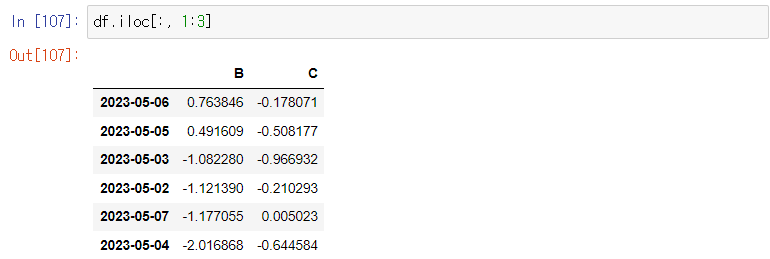
-
사용 예시 3) : 범위를 지정해서 범위에 해당되는 데이터만 갖고 올 수도 있다.
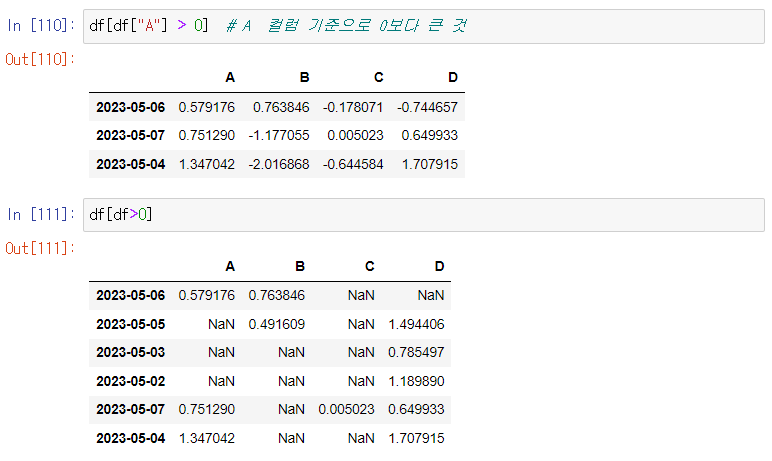
참고 - NaN : Not a Number
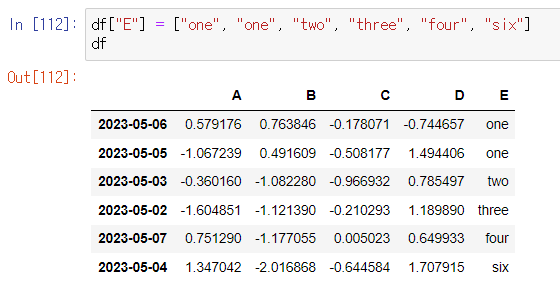
컬럼 추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
새로운 컬럼 "E"가 생겼다 !
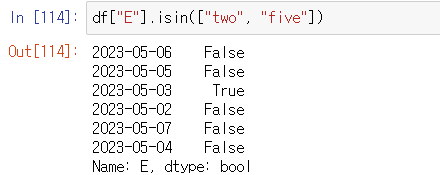
특정 요소가 있는지 확인하기: isin()
사용 예시) df["E"].isin(["two"])

df["E"].isin(["two", "five"])
df["E"].isin(["two", "five", "three"])

- isin()을 특정 조건을 거는 것으로 활용하여 찾고자하는 데이터를 찾을 수도 있다.
사용 예시) df[df["E"].isin(["two", "five", "three"])]
df 안에 담아두는 것이다.

여기에서 five 값이 있는 행이 없으니 2 개의 행만 나온 것이다.
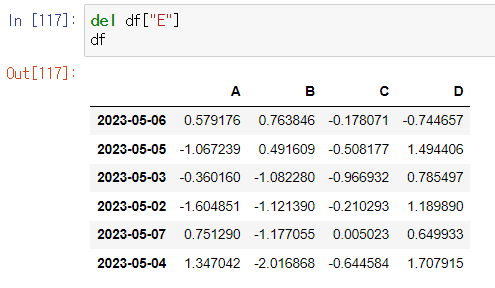
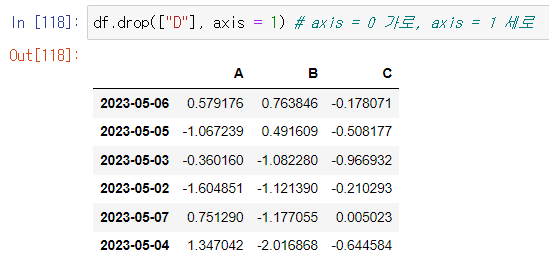
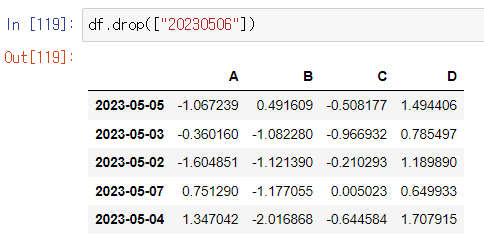
특정 컬럼 제거
- del
- drop
사용 예시)
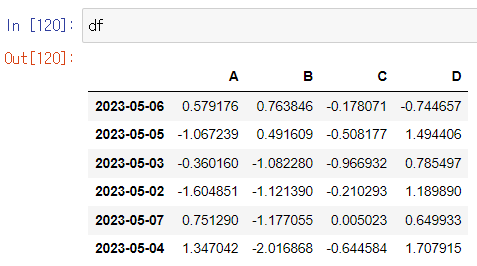
데이터끼리 연산을 해보자!: apply()
- 보기용 데이터
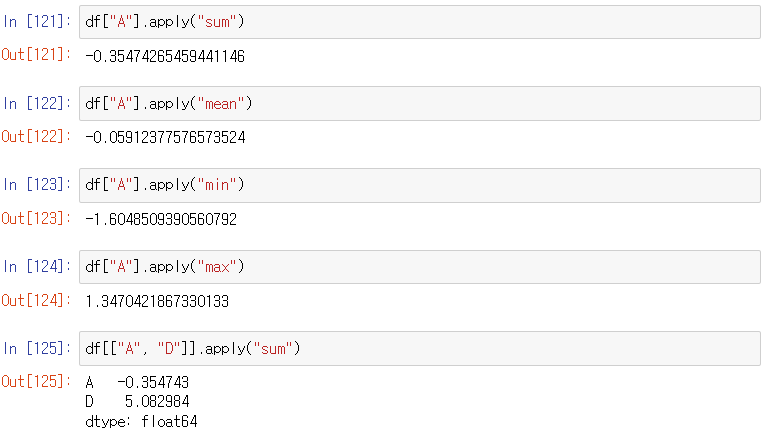
사용 예시)![]
df["A"].apply("sum") -> A 컬럼에 있는 모든 데이터 더하기
df["A"].apply("mean") -> A 컬럼에 있는 모든 데이터 빼기
df["A"].apply("min") -> A 컬럼에 있는 모든 데이터 중 최솟값
df["A"].apply("max") -> A 컬럼에 있는 모든 데이터 중 최댓값
df[["A", "D"]].apply("sum") -> A 컬럼에 있는 모든 데이터 더하고, D 컬럼에 있는 모든 데이터 더한 후, 그 두 값을 또 더해버린다.
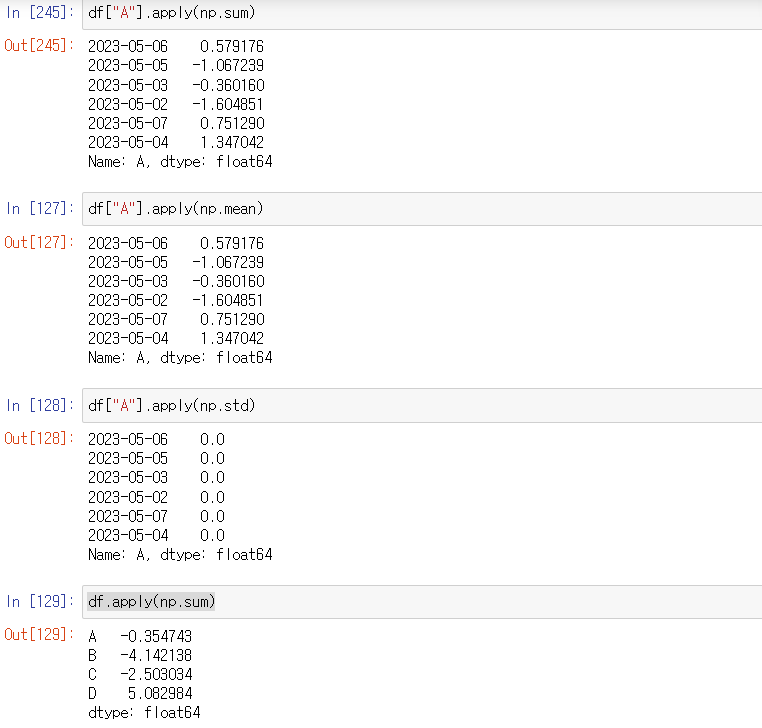
df["A"].apply(np.sum) ->
df["A"].apply(np.mean) ->
df["A"].apply(np.std) ->
df.apply(np.sum) ->
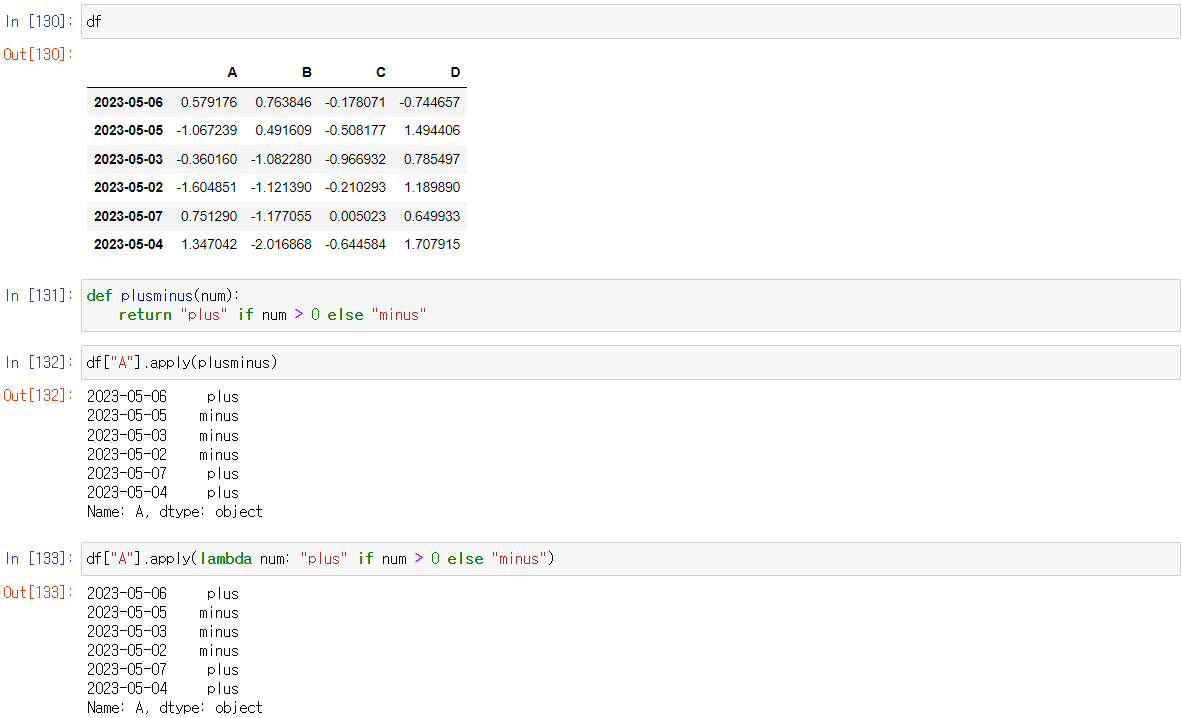
함수 만들어서 apply()와 함께 사용해보기
- 우선 함수를 만들자.
예시) def plusminus(num):
return "plus" if num > 0 else "minus"
함수를 만들었으니 이제, 사용해보자.
df["A"].apply(plusminus)
df.["A"].apply(lambda num: "plus" if num > 0 else "minus")