강화학습
1.강화학습_Markov Decision Process

리턴이란, 현재 시점부터 앞으로 받을 것으로 기대되는 리워드 (n번째 보상) 들의 기댓값이다. $$Gt = R{t+1}+ \\gamma R{t+2}+ ...=\\sum{k=0}^{\\infty }\\gamma ^{k}R{t+k+1}$$현재의 밸류 = 현재 리워드 +
2023년 3월 27일
2.강화학습_Dynamic Programming 실습
본 포스팅은 openai gym Grid World 환경에서 Dynamic Programming 을 이용해 Iterative Policy Evaluation 을 하는 법을 다룹니다. 출처: 경희대학교 2023-1 강화학습 (황효석 교수님)Google Colab 에서 진
2023년 3월 27일
3.강화학습_Monte Carlo Algorithm
모델을 모를 때 사용할 수 있는 방법 여기서 모델을 모른다는 건, State Transition Matrix / Reward 등을 모른다는 뜻이다. 여기서 몬테카를로 방법은 '큰 수의 법칙' 을 전제로, 에피소드에 대한 경험을 토대로 학습한다. 몬테카를로 방법은
2023년 4월 1일
4.강화학습_Monte Carlo 실습
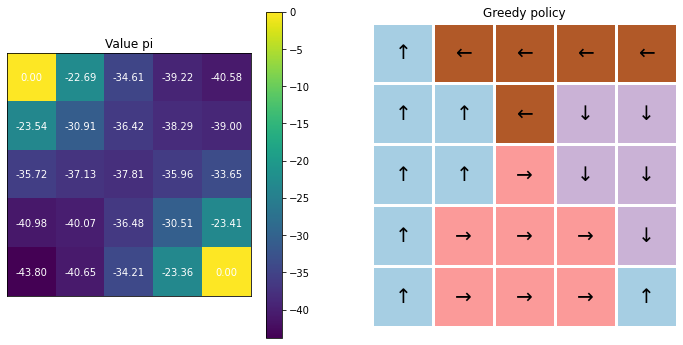
Grid World 초기화현재 state 에서 action 을 정의하는 함수.
2023년 4월 1일