본 포스팅은 openai gym Grid World 환경에서 Dynamic Programming 을 이용해 Iterative Policy Evaluation 을 하는 법을 다룹니다.
출처: 경희대학교 2023-1 강화학습 (황효석 교수님)
Google Colab 에서 진행되었습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from gridworld import *
np.random.seed(0)
import copyInitialize GridWorld
- nx = 5 : 가로
- ny = 5 : 세로
- ns = env.nS : state 의 개수 (25개)
- na = env.nA : action 의 개수 (4개 / 위아래좌우)
- policy : [25,4] 행렬 : 각각의 state 마다 action 의 확률을 담고 있음.
- P : 상태전이확률함수 [4,25,25]
- R : [25,4] 보상함수
nx = 5
ny = 5
env = GridworldEnv([ny, nx])
ns=env.nS
na=env.nA
policy=np.ones([env.nS, env.nA]) / env.nA # [num. states x num. actions] 정책함수
P=env.P_tensor # [num. actions X num. states X num. states] 상태천이확률함수
R=env.R_tensor # [num. states x num. actions] 보상함수
gamma=1.0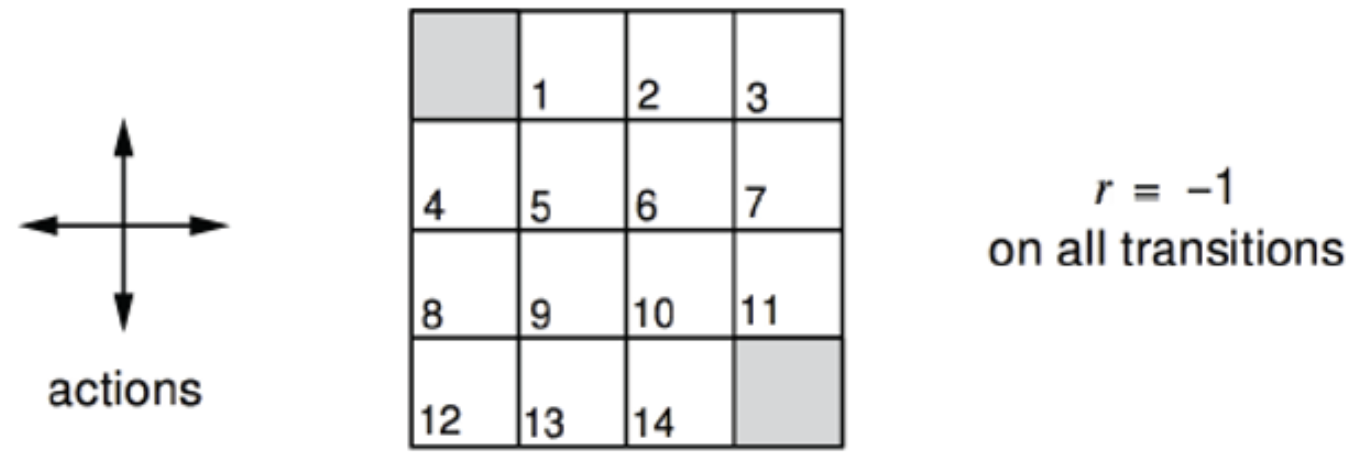
그러면 이런 5x5 Grid World 가 생긴다.
Iterative Policy Evaluation

위 식을 참고하여 코드를 작성해보자.
#input - v : value, pi : policy, no_iter: number of iteration
def IternativePolicyEvaluation (v, pi, no_iter=1):
new_v = copy.deepcopy(v)
for i in range(no_iter):
for s in range(ns): #state 를 돌면서
new_v[s] = 0
for a in range(na): # action 마다
val = 0
for s_ in range(ns):
val = val + P[a,s,s_] * v[s_]
new_v[s] = new_v[s] + pi[s,a]*(R[s,a] + gamma * val)
v = copy.deepcopy(new_v)
return v
위 식을 시행하면 요렇게 결과가 나온다.
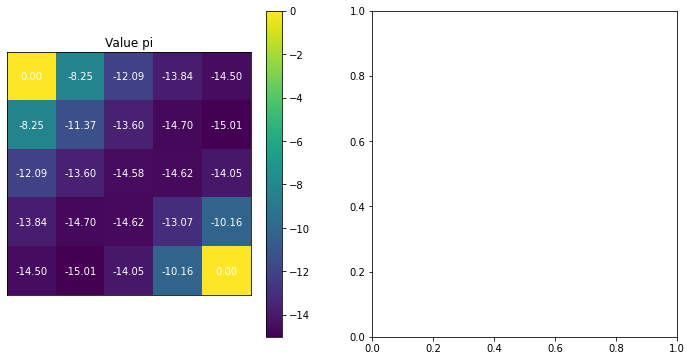
10번 iteration 을 진행했을 때, 각 state 의 value 가 다음과 같이 update 되는 것을 볼 수 있다.
Policy Improvement
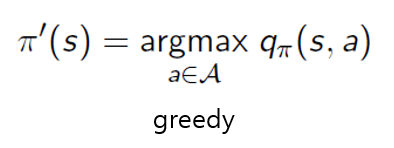
q : action-value function
state s 에서 policy pi 를 따르면서 action a 를 했을 때 기대되는 리턴
def PolicyImprovement(v, pi):
for s in range(ns):
best_q = -1
best_Q = -100000
for a in range(na):
val = 0
for s_ in range(ns):
val = val + P[a,s,s_] * v[s_]
if val > best_Q:
best_Q = val
best_q = a
pi[s,:] = 0
pi[s, best_q] = 1
return pi
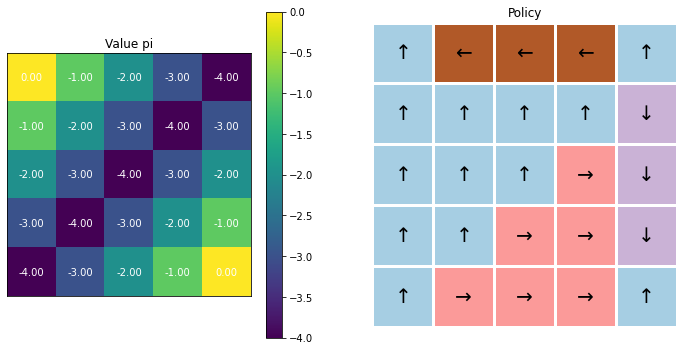
이 코드를 실행하면 다음과 같은 결과가 나온다.
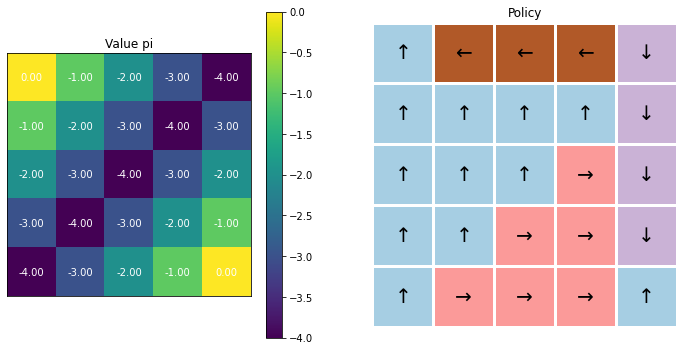
Value Iteration
최적의 Policy 를 찾기 위해
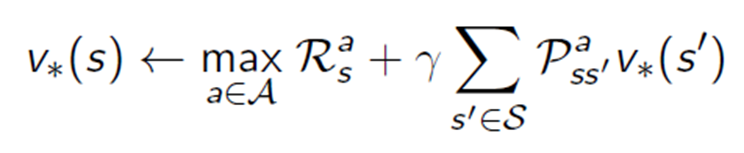
def ValueIteration(v,p,no_iter):
v_opt = copy.deepcopy(v)
pi_opt = copy.deepcopy(p)
for i in range(no_iter):
for s in range(ns):
v_opt[s] = 0
max_v = -10000
max_a = -1
for a in range(na):
val = 0
for s_ in range(ns):
val = val + P[a,s,s_] * v[s_]
if (R[s,a] + gamma * val) > max_v:
max_v = (R[s,a] + gamma * val)
max_a = a
v_opt[s] = max_v
pi_opt[s,:] = 0
pi_opt[s, max_a] = 1
v = copy.deepcopy(v_opt)
return v_opt, pi_opt
이를 실행하면 다음과 같은 결과를 얻을 수 있다.