- Grid World 초기화
nx, ny =5,5
env = GridworldEnv([ny,nx])
- 현재 state 에서 action 을 정의하는 함수.
def get_action(state):
action = np.random.choice(range(4))
return action
def run_episode(env, timeout=1000):
env.reset()
states = []
actions = []
rewards = []
i = 0
timeouted = False
while True:
state = env.s
action = get_action(state)
next_state, reward, done, info = env.step(action)
states.append(state)
actions.append(action)
rewards.append(reward)
if done:
break;
else:
i += 1
if i >= timeout:
timeouted = True
break
if not timeouted:
episode = (states, actions, rewards)
return episode
episodes = []
no_episode = 10000
for _ in range(no_episode):
episodes.append(run_episode(env))
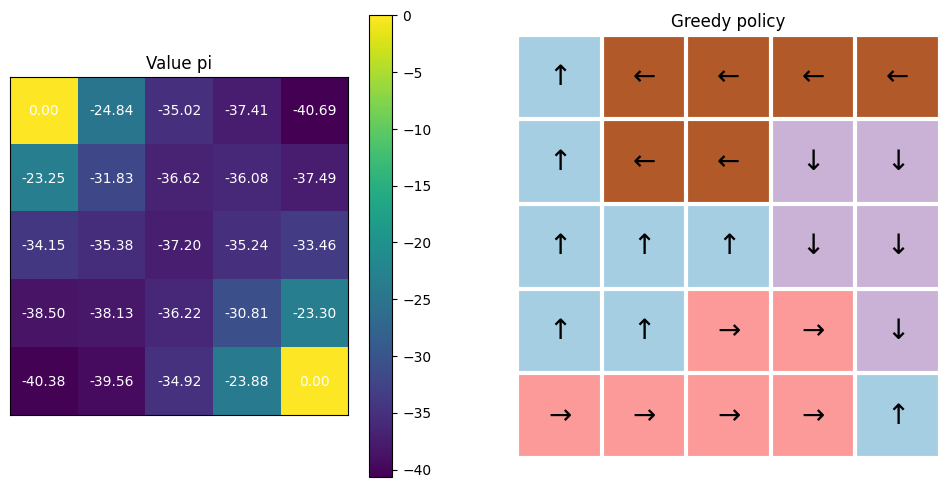
MC
s_v=np.zeros(shape=nx*ny)
s_q = np.zeros(shape=(nx*ny,4))
n_v=np.zeros(shape=nx*ny)
n_q = np.zeros(shape=(nx*ny,4))
gamma=1.0
lr=1e-3
for episode in episodes:
states, actions, rewards = episode
states = reversed(states)
actions = reversed(actions)
rewards = reversed(rewards)
iter = zip(states, actions, rewards)
cum_r = 0
for s, a, r in iter:
cum_r *= gamma
cum_r += r
n_v[s] += 1
n_q[s, a] += 1
s_v[s] += cum_r
s_q[s, a] += cum_r
v = s_v / (n_v)
q = s_q / (n_q)
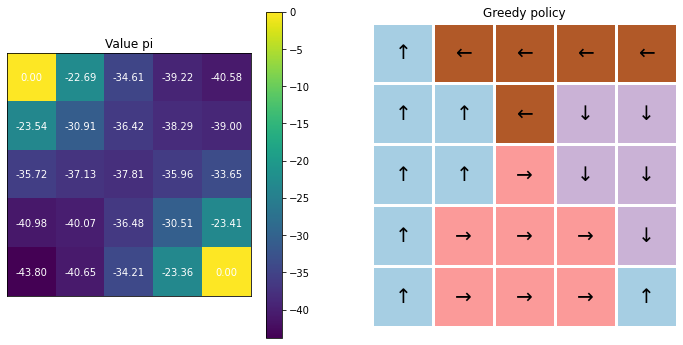
Incremental MC
v=np.zeros(shape=nx*ny)
q = np.zeros(shape=(nx*ny,4))
gamma=1.0
alpha=1e-3
for episode in episodes:
states, actions, rewards = episode
states = reversed(states)
actions = reversed(actions)
rewards = reversed(rewards)
cum_r = 0
iter = zip(states, actions, rewards)
for s, a, r in iter:
cum_r += r
v[s] = v[s] + alpha*(cum_r-v[s])
q[s,a] = q[s,a] + alpha*(cum_r-q[s,a])