
MSA
MSA(Micro Service Architecture)는 아마존, 넷플릭스 같은 해외 유스의 기업들이 사용하고 있는 아키텍처다.
서비스 규모는 점점 커지고 새롭게 추가되는 기능들은 기존 기능과 서로 엵혀서 점점 커진다. 시간이 지날 수록 코드들은 점점 얽히고 기능들은 서로 더욱 강하게 결합한다. 결국 시스템 유지 보수하는 시간이 새로운 기능을 개발하는 시간보다 더 걸리게 된다. 이를 해결하기 위해서 애플리케이션 코드를 리팩토링하거나 시스템 구조를 변경해서 시스템 복잡도를 낮춰야 한다.
모든 시스템은 하나 이상의 컴포넌트로 구성되어 있다. 즉, API 컴포넌트나 저장소 컴포넌트처럼 각자 역할이 분리되어 있다. 시스템 구조를 변경하기 위해 시스템과 서비스를 잘 이해하고 있는 사람이 시스템 구조를 설계해야 합니다. 이들은 시스템을 이루는 컴포넌트와 컴포넌트 사이의 관계를 정리하고 명확하게 역할을나누어야 합니다. 이렇게 시스템 컴포넌트를 나누고 합치는 사람을 아키텍트라고 하며, 컴포넌트와 컴포넌트의 관계를 정리한 것을 소프트웨어 아키텍처라고 한다. 그리고 서비스 기능을 하나의 API 컴포넌트에서 처리하는 구조를 모놀리식 시스템 아키텍처라고 하고 기능을 분리하여 두 개 이상의 API 컴포넌트에서 처리하는 구조를 분산 처리 시스템 아키텍처라고 한다.
모놀리식 아키텍처
모놀리식 아키텍처(Monolithic Architecture, MA)는 하나의 통합된 코드 베이스로 여러 비즈니스 기능을 수행하는 전통적인 소프트웨어 개발 모델입니다. 단일 애플리케이션 내에 서비스의 모든 로직이 통으로 들어가 있는 구조입니다.
이렇게 서비스를 애플리케이션 하나로만 처리할 때의 가장 큰 장점은 뭐니뭐니해도 간결하다는 점입니다. 중앙 집중된 구조이기 때문에 분산된 애플리케이션에 비해 엔드 투 엔드 테스트(End-to-End, E2E: 사용자 관점에서 애플리케이션의 흐름을 처음부터 끝까지 테스트하는 것)를 더 빠르게 수행할 수 있습니다. 단일 애플리케이션에 비즈니스 로직부터 UI, 콘텐츠 등 모든 구성 요소를 이루는 코드가 들어있기 때문에 디버깅하기도 간편합니다. 마이크로 서비스에서 데이터는 네트워크를 통해 전송된다. 그러므로 모놀리식 아키텍처는 네트워크로 인한 지연이나 데이터 유실은 걱정할 필요가 없다. 시스템 장애나 기능에 버그가 있다면 개발자는 하나의 애플리케이션에서 원인을 파악하면 된다. 여러 클래스에서 발생하는 로그를 하나의 파일에 기록할 수 있기 때문에 쉽게 원인을 파악할 수 있다. 또한 데이터 저장소가 한개이므로 RDB의 트랜잭션 기능을 쉽게 사용할 수 있다. 트랙잭션의 커밋(commit), 롤백(rollback)을 사용하면 데이터를 여러 테이블에 영속할 때 일 일관성을 유지할 수 있습니다.
하지만 서비스 규모가 커짐에 따라 모놀리식 아키텍처의 단점도 제기되기 시작했습니다. 단일 애플리케이션이 커지면 자연히 구동부터 빌드, 배포에 드는 시간이 오래 걸리죠. 더욱이 하나로 된 거대한 시스템 구조를 제대로 파악하지 않으면 특정 컴포넌트나 모듈에서 발생하는 성능 문제나 장애가 다른 영역에까지 영향을 주게 됩니다. 아무리 작은 부분만 수정하더라도 전체 애플리케이션을 통째로 컴파일해서 배포해야 하는 만큼 배포가 잦은 환경에서는 번거롭습니다.
분산 처리 시스템 아키텍처(Distributed Systems Architecture)
- 분산 처리 시스템은 여러 컴퓨터 또는 서버 간의 작업을 분산시켜 수행하는 시스템을 말합니다.
- 분산 시스템은 여러 컴퓨터 또는 노드가 네트워크를 통해 연결되어 있으며, 각 노드는 독립적으로 작동하면서 특정 작업을 수행하거나 데이터를 처리할 수 있습니다.
- 분산 시스템은 확장성, 가용성, 내결함성 등을 강조하며, 대규모의 데이터 처리나 서비스 제공에 사용됩니다.
마이크로 서비스 아키텍처는 분산 시스템 아키텍처 중 하나다. 특히 MSA는 다량의 요청을 처리하고 애플리케이션 복잡도를 낮추어 주는 여러 장점이 있다.
마이크로 서비스 아키텍처는 기능 위주로 나뉜 여러 애플리케이션이 있고 각각 독립된 데이터 저장소를 사용한다. 기능으로 분리된 애플리키에션들은 미리 정의된 인터페이스를 통해 서로 유기적으로 동작한다. 그리고 웹이나 APP 클라이언트에 일관된 형태의 API로 제공된다. 이렇게 기능별로 쪼개진 작은 서비스 혹은 시스템 마이크로 서비스라고 합니다.
마이크로 서비스 아키텍처의 특징을 대표하는 몇 가지 키워드가 있습니다. 대규모 시스템, 분산 처리 시스템, 컴포넌트들의 집합 그리고 시스템 확장 등이다. 이런 특징들은 서비스 지향 아키텍처와 공통점이 많다. 서비스 지향 아키텍처는 대규모 시스템을 설계할 때 서비스 기능 단위로 시스템을 묶어 시스템 기능을 구현한 것을 의미한다. 그래서 서비스 지향 아키텍처와 마이크로 서비스 아키텍츠는 공통점이 많다. 두 아키텍처 모두 서비스 기능 단위로 시스템을 만들고 각 시스템은 서로 표준화된 인터페이스를 통해 서비스를 통합한다. 이처럼 핵심 개념은 서로 같다.
마이크로서비스 아키텍처의 마이크로서비스들은 각각 마이크로서비스에서 독립적으로 구성되어야 한다. 독립적이지 않다면 스파게티 코드처럼 의존하면 복잡도가 증가되어 장애가 일어난다. 이처럼 독립적인게 느슨한 결합이라고 한다. 그러므로 마이크로 서비스마다 각각 독립된 데이터 저장소가 필요하다.
마이크로서비스들은 기능과 성격에 맞게 잘 분리되어야 한다. 그 기능은 너무 작게도 혹은 너무 크게도 설계되어서는 안된다. 기능을 너무 세밀하게 분리하면 수많은 마이크로서비스를 관리해야 한다. 데이터를 너무 잘게 쪼개면 간단한 기능이라도 여러 마이크로서비스의 데이터 통합이 필요하다.
각 마이크로 서비스 컴포넌트들은 기능을 연동할 때, API를 통해 서로 데이터를 주고받는다. 다시 말하면 API가 사용하는 네트워크 프로토콜이 성능 저하의 원이 될 수 있다. 그러므로 통신에 사용되는 네트워크 프로토콜은 가벼워야 한다. 네트워크를 통해 마이크로 서비스 사이에 데이터를 전달하려면 객체는 바이트 형태로 변경되어야 한다. 이 과정을 직렬화라고 한다. 반대로 바이트 데이터를 객체로 변환하는 과정을 역직렬화라고 한다. 직렬화된 바이트 데이터 크기가 원래 크기보다 크다면 성능 저하가 발생하고 직렬화/역직렬화 과정에서 CPU와 메모리 같은시스템 리소스를 많이 사용하면 성능 저하가 발생하므로 가벼운 프로토콜을 사용해서 성능 최적화해야 한다.
보통은 JSON 형식의 메시지를 주고받으며, HTTP 기반의 REST-API를 가장 많이 사용한다.
특징
- 잘 분리된 마이크로 서비스로 인한 탈중앙화
- 대규모 시스템을 위한 아키텍처
- 가벼운 네트워크 프로토콜
- 느슨한 결합
- 서비스 지향 아키텍처
장점
-
독립성
마이크로 서비스의 첫 번째 장점은
독립성이다. 하나의 마이크로 서비스는 하나의 비즈니스 기능을 담당하므로 다른 마이크로서비스와 간섭이 최소화된다. 특히 하나의 마이크로서비스는 독립된 데이터 저장소를 갖고 있으므로 데이터 간섭에도 자유롭다. -
대용량 데이터를 저장하고 처리하는데 비교적 자유롭다.
마이크로서비스는 독립된 데이터 저장소를 갖고 있기 때문에 대용량 데이터를 마이크로서비스마다 나누어 저장할 수 있다. 기본적으로 마이크로서비스 숫자만큼 데이터가 분산 저장된다. 또한 앞서 이야기한 샤딩이나 서비스에 적합한 캐시를 마이크로서비스 단위로 각각 적용할 수 있다.
-
시스템 장애에 견고하다.
마이크로서비스는 느슨하게 연결되어 있고 각각 독립적이기 때문에 서로 미치는 영향이 적다. 마이크로서비스들이 느슨하게 결합된 경우 하나의 마이크로서비스에 장내나 버그나 발생하더라도 다른 마이크로서비스는 이상 없이 서비스 된다. 마이크로서비스와 클라우드 서비스에서 제공하는 몇몇 기능이 결합되면 애플리케이션은 탄력 회복성을 갖게 된다.
탄력 회복성이란 애플리케이션 서버에 장애가 발생하면 새로운 컴퓨팅 자원을 추가해서 빠른 시간안에 서비스를 다시 제공하는 것을 의미한다. -
개별적인 컴포넌트로 스케일 관리가 쉽습니다.
-
기술에 대한 다양성을 가질 수 있습니다.
-
결함을 고립하여 전체 시스템의 다운을 방지할 수 있습니다.
-
서비스 배포 주기가 빠르다.
-
마이크로서비스 단위로 확장할 수 있어 확장성이 좋아진다.
작은 코드 베이스를 가지고 있으므로 관리가 용이 -
사용자 반응에 민첩하게 대응할 수 있다.
새로운 서비스를 마이크로서비스로 분리하여 설계하고 시스템에 포함하면 사용자 반응에 따라 시스템을 고도화거나 빠르게 시스템에서 제외할 수 있다.
단점
-
개발하기 어려운 아키텍처
다른 시스템이 네트워크상에 분산되어 있어 프로세스가 다른 마이크로서비스 개발할 때는 여러 상황을 고려해야 한다. 크게 고려할 것들은 분리된 데이터, 네트워크를 통한 데이터 통합이다. 통합하기 위해서는 표준화된 인터페이스로 데이터를 처리해야 한다. 강한 일관성을 달성하기 어렵습니다. 그리고 분산 환경이므로 디버깅과 추적이 어렵습니다.
-
서비스간 호출에 따른 커뮤니케이션 비용이 증가합니다.
-
운영하기 어려운 아키텍처
-
설계하기 어려운 아키텍처
-
마이크로서비스 아키텍처로 설계된 서비스 운영에는 여러 가지 자동화된 시스템이 필요하다.
-
마이크로서비스를 운영하고 개발하는 개발자의 기술력이 좋아야 한다.
마이크로서비스 아키텍처 설계
서비스 세분화 원칙
서비스 세분화 원칙은 서비스 지향 아키텍처의 여러 핵심 원칙 중 하나다. 마이크로서비스 아키텍처가 서비스 지향 아키텍처에서 개념적으로 많은 영향을 받았으므로 서비스 세분화 원칙 또한 서비스를 마이크로서비스로 나눌 때 많은 도움이 된다. 세분화 원칙은 네 개의 요소로 구성되어 있으며 이 네 가지 요소를 기반으로 서비스를 나누도록 제안한다. 이렇게 분리된 서비스들은 모듈화되어 서로 느슨하게 결합된 상태를 유지한다. 느슨하게 결합된 서비스들은 독립성을 갖고 서비스 복잡도는 낮아진다. 네 개의 요소를 알아보자.
-
비즈니스 기능
비즈니스 기능으로 서비스를 나눈다. 이상적으로 각각의 서비스는 비즈니스 동작과 일대일로 연결되어 있다. 하나의 서비스가 여러 비즈니스 동작을 제공하면 서비스 복잡도가 높아지고 복잡도가 높아진 코드는 유지보수가 어려워 진다. -
성능
성능이 떨어지는 마이크로서비스가 너무 많은 기능을 처리하고 있지 않는지 체크해야 한다. -
메시지 크기
성능과 어느정도 연관이 있다. API를 설계하는데 메시지가 크다면 마이크로서비스를 나누는 것을 고려하자. 메시지 크기가 너무나 크면 메시지를 직렬화/역직렬화하는데 성능 문제를 일으킨다. 단 비즈니스 기능이나 일관성을 유지하는데 트랜잭션에 문제가 없다면 이는 무시해도 좋다. -
트랜잭션
데이터 정합성을 유지하는 트랜잭션으로 서비스를 나누는 것도 좋다. 보통 이는 데이터를 기준으로 서비스를 분리하는 방법이라고 할 수 있다. 트랜잭션으로 보장되는 서비스라면 에러가 발생했을 때 데이터 유실이나 정확한 데이터를 유지하는 데 도움이 된다. 보통 트랜잭션을 유지할 수 있는 데이터들은 하나의 비즈니스 로직을 처리하는 데 하나의 세트로 동작하기 때문에 최소한의 마이크로서비스를 설계하는데 도움이 된다.
도메인 주도 설계(DDD)의 바운디드 컨텍스트
전체 서비스를 마이크로서비스 단위로 구분하는 일은 어렵다. 얼마나 작게 나누어야하는지 모호하기 때문이다. 이럴때 도메인 주도 설계의 핵심 개념 중 하나인 바운디드 컨텍스트를 이해한다면 마이크로서비스로 나누는 기준을 잡느데 도움이 된다.
-
단일 책임 원칙
단일 책임 원칙은 모든 클래스는 하나의 책임을 가지며, 그 클래스의 기능은 이 책임을 기반으로 개발되어야 함을 의미한다. 그렇다면 책임을 어떻게 구분할까? 우리가 무언가를 변경할 때 이때 함께 변경되는 것들은 서로 연관성이 있음을 의미한다. 연관성이 있으면 하나로 모으면 된다. 그리고 서로 다른 이유로 변경되는 것들은 분리하자. 이렇게 설계된 클래스는 응집도가 높고 결합도가 낮다. 즉, 클래스의 책임 영역이 확실해진다. 마이크로서비스도 마찬가지다. 하나의 책임을 갖는 마이크로서비스도 바운디드 컨텍스트처럼 독립 영역을 갖게 된다. 그래서 다른 마이크로서비스들과 간섭이 줄어들고 변경도 자유롭다. -
가벼운 통신 프로토콜
모놀리식 아키텍처 시스템은 모든 서비스가 하나의 애플리케이션에서 처리된다. 애플리케이션 내부에서는 클래스가 다른 클래스의 메서드를 호출하면서 결과를 만들어 낸다. 다시 말하자면 아무리 복잡한 서비스라도 클래스 사이에 의존성이 발생하므로 성능면에서 뛰어나다. 아무리 잘 설계해도 데이터를 참조하거나 수정하는 상황이 발생하는데 이때 마이크로서비스들은 데이터를 통합하기 위해 네트워크를 사용하여 기능을 제공하는데 이 때문에 여러 문제가 발생한다. 응답지연뿐만 아니라 시스템 리소스를 사용하고 데이터를 직렬화/역직렬화해야 하므로 시스템에 부하를 준다. -
외부 공개 인터페이스
마이크로서비스들은 네트워크를 이용하여 서로 통신한다. -
마이크로서비스마다 독립된 데이터 저장소
도메인은
영역이라는 뜻이다. 특히 소프트웨어 개발에서 말하는 도메인은 프로그램이 쓰이는 대상 분야라는 의미로 쓰인다.
도메인
개발자 입장에서 온라인 서점은 구현해야할 소프트웨어의 대상이 된다. 온라인 서점 소프트웨어는 온라인으로 책을 판매하는데 필요한 상품 조회, 구매, 결제, 배송 등의 기능을 제공해야 한다.
이 때, 온라인 소점은 소프트웨어로 해결하고자 하는 문제 영역, 즉 도메인에 해당한다. 한 도메인은 다시 하위 도메인으로 나눌 수 있다. 예를들어 다음 그림은 온라인 서점 도메인 몇 개의 하위 도메인으로 나타낸 것이다.

카탈로그 하위 도메인은 고객에게 구매할 수 있는 상품 목록을 제공하고, 주문 하위 도메인은 고객의 주문을 처리한다. 혜택 하위 도메인은 쿠폰이나 특별 할인과 같은 서비스를 제공한다. 한 하위 도메인은 다른 하위 도메인과 연동하여 완전한 기능을 제공하게 된다. 특정 도메인을 위한 소프트웨어라고 해서 도메인이 제공해야 할 모든 기능을 구현해야 하는 것은 아니다. 많은 온라인 쇼핑몰이 자체적으로 배송 시스템이나 결제 시스템의 경우에는 외부 업체의 시스템을 사용하고, 정보 제공 기능만 구현한다. 그리고 메인마다 고정된 하위 도메인이 존재하는 것은 아니다. 모든 온라인 쇼핑몰이 고객 혜택을 제공하는 것은 아니고, 정산은 엑셀과 같은 도구를 이용해서 수작업으로 처리할 수도 있다. 하위 도메인을 어떻게 구성할지 여부는 상황에 따라 달라진다.
도메인 모델
기본적으로 도메인 모델은 특정 도메인을 개념적으로 표현한 것이다. 주문 도메인을 객체 기반 모델로 구성하면 아래 그림처럼 만들 수 있다.
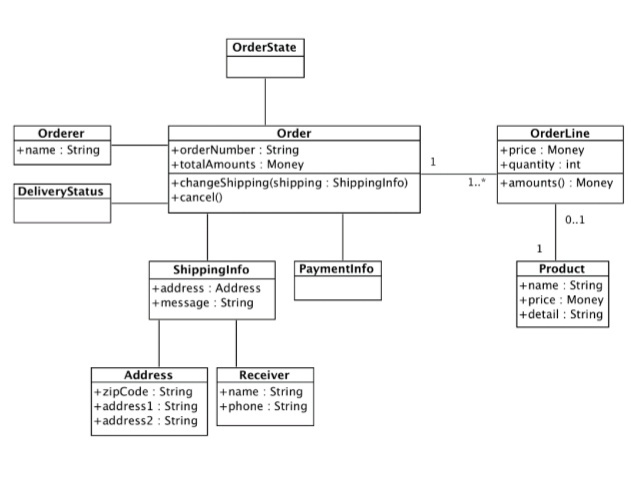
도메인을 이해하려면 도메인이 제공하는 기능과 도메인의 주요 데이터 구성을 파악해야 하는데, 이런 면에서 기능과 데이터를 함께 보여주는 객체 모델은 도메인을 모델링하기에 적합하다.
도메인 모델링이란?
사건 혹은 개념을 추상화하는 작업을 모델링이라고 한다. 그리고 모델링 결과를 모델이라고 한다. 도메인 주도 설계에서는 도메인 개념을 모델링한 모델을 도메인 모델이라고 한다.
도메인 모델 패턴
도메인 계층은 도메인의 핵심 규칙을 구현한다. 주문 도메인의 경우 출고전에 배송지를 변경할 수 있다라는 규칙과 주문 취소는 배송 전에만 할 수 있다라는 규칙을 구현한 코드가 도메인 게층에 위치하게 된다. 이런 도메인 규칙을 객체 지향 기법으로 구현하는 패턴이 도메인 모델 패턴이다.
DDD의 개념
DDD 또는 도메인 주도 설계라고 부른다. 도메인 패턴을 중심에 놓고 설계하는 방식을 말합니다.
도메인이란 사전적 의미는 영역, 집합이다. '실세계에서 사건이 발생하는 집합' 이라고 생각하면 쉬울 것 같다. DDD에서 말하는 도메인은 비즈니스 도메인을 말하며, 비즈니스 도메인은 유사한 업무의 집합이다. 쇼핑몰을 예로 들면, 쇼핑몰에서는 손님들이 주문하는 도메인(Order Domain)이 있을 수 있고, 직원입장에선 옷들을 관리하는 도메인(Manage Domain)이 있을 수 있고, 결제를 담당하는 도메인(Payment Domain)이 있을 수 있다. 이렇게 여러가지 도메인들이 상호작용하며, 비즈니스 도메인별로 나누어 설계하는 것이 바로 도메인 주도 설계(이하 DDD)이다.
DDD의 계층구조(Layered Architecture)
Layered Architecture는 말 그대로 계층이 나뉘어져 있는 아키텍쳐를 뜻한다. Layered Architecture의 주된 목표는 각각의 layer는 하나의 관심사에만 집중할 수 있도록 하는 것이다. 일반적으로 3 계층 또는 4 계층으로 나누어 사용한다.
※ 3계층으로 나눌 때는 표현계층(Presentation Layer - 서비스계층(Business Layer) - 영속성계층(Persistence Layer)으로 나누어 사용하곤 한다.
대표적으로 DDD에서는 아래와 같은 구조의 Layered Architecture를 가진다.
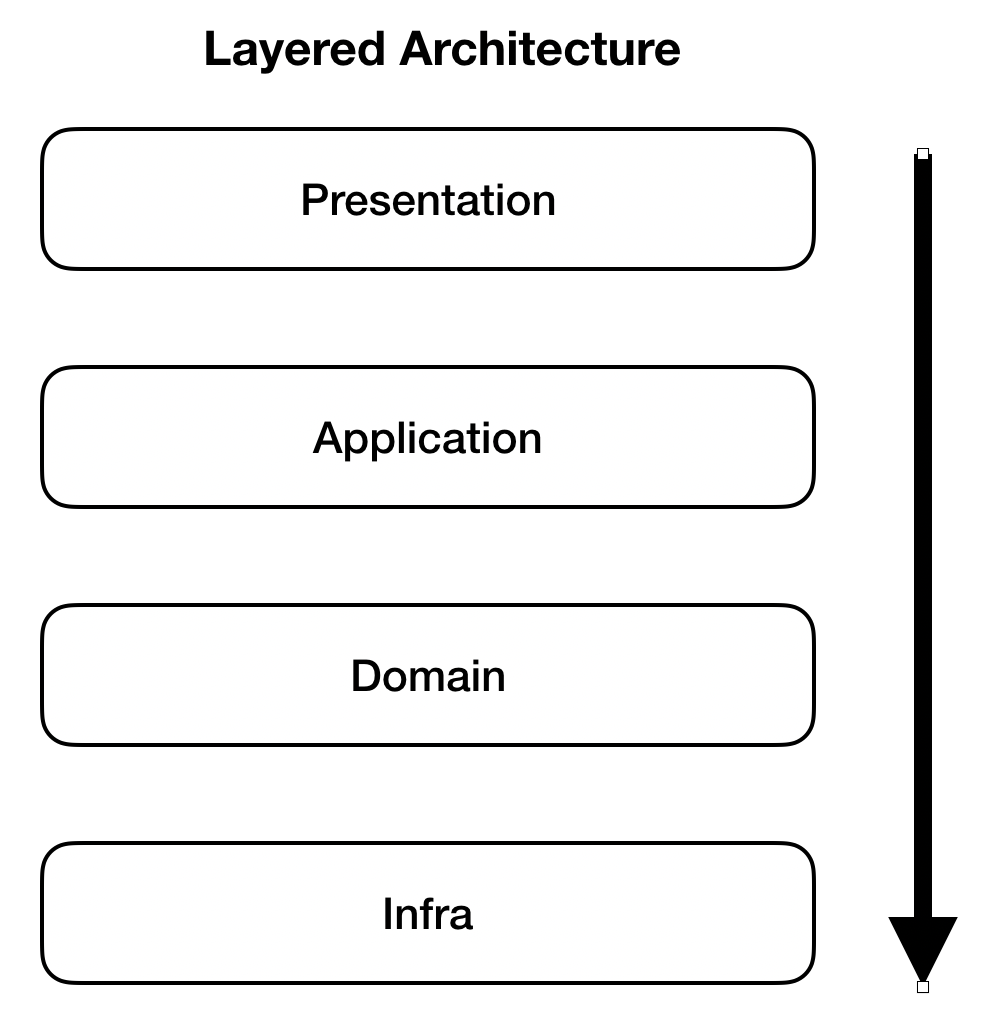
Layered Architecture를 올바르게 구현하기 위한 두 가지 중요한 규칙이 있다.
-
위의 계층에서 아래 계층에는 접근이 가능하지만 아래에서 위로는 불가능한 것을 기본으로 한다.
-
한 계층의 관심사와 관련된 어떤 것도 다른 계층에 배치되어서는 안된다.

특징
-
도메인 그 자체와 도메인 로직에 초점을 맞춥니다. 일반적으로 많이 사용하는 데이터 중심의 접근법을 탈피해서 순수한 도메인의 모델과 로직에 집중한다.
-
보편적인 언어의 사용입니다. 도메인 전문가와 소프트웨어 개발자 간의 커뮤니케이션 문제를 없애고 상호가 이해할 수 있고 모든 문서와 코드에 이르기까지 동일한 표현과 단어로 구성된 단일화된 언어체계를 구축해나가는 과정을 말합니다. 이로서 분석 작업과 설계 그리고 구현에 이르기까지 통일된 방식으로 커뮤니케이션이 가능해집니다.
-
소프트웨어 엔티티와 도메인 컨셉트를 가능한 가장 가까이 일치시키는 것입니다. 분석 모델과 설계가 다르고 그것과 코드가 다른 구조가 아니라 도메인 모델부터 코드까지 항상 함께 움직이는 구조의 모델을 지향하는 것이 DDD의 핵심 원리입니다.
Layered Architecture의 장단점
장점
- 각 레이어를 loosely coupling 된 형태로 구축하면서, 각각 자신의 관심사에만 집중할 수 있다.
- 핵심 비즈니스 로직을 순수하게 유지함으로써 유지보수와 확장성 측면에서 이득을 얻을 수 있다.
- 각 레이어에 서로 다른 추상화 수준을 가진 상태와 행동을 위치시킴으로써 코드 재사용성을 높일 수 있다.
단점
- 서비스가 커질수록 복잡도가 증가하여 확장성이 떨어진다.
- 레이어로 분리된 관심사 외에 다른 관심사가 생길 경우 패키지 분리 및 코드 배치가 어렵다.
Layered Architecture를 사용해야 하는 경우
작고 단순하며 확장성보다는 일관성을 가져가는 것이 목표인 어플리케이션이나 웹사이트에 적합하다.또한 단순성 및 구현 용이성으로 인해 어플리케이션 시작점으로 사용하기에 좋다.
구조

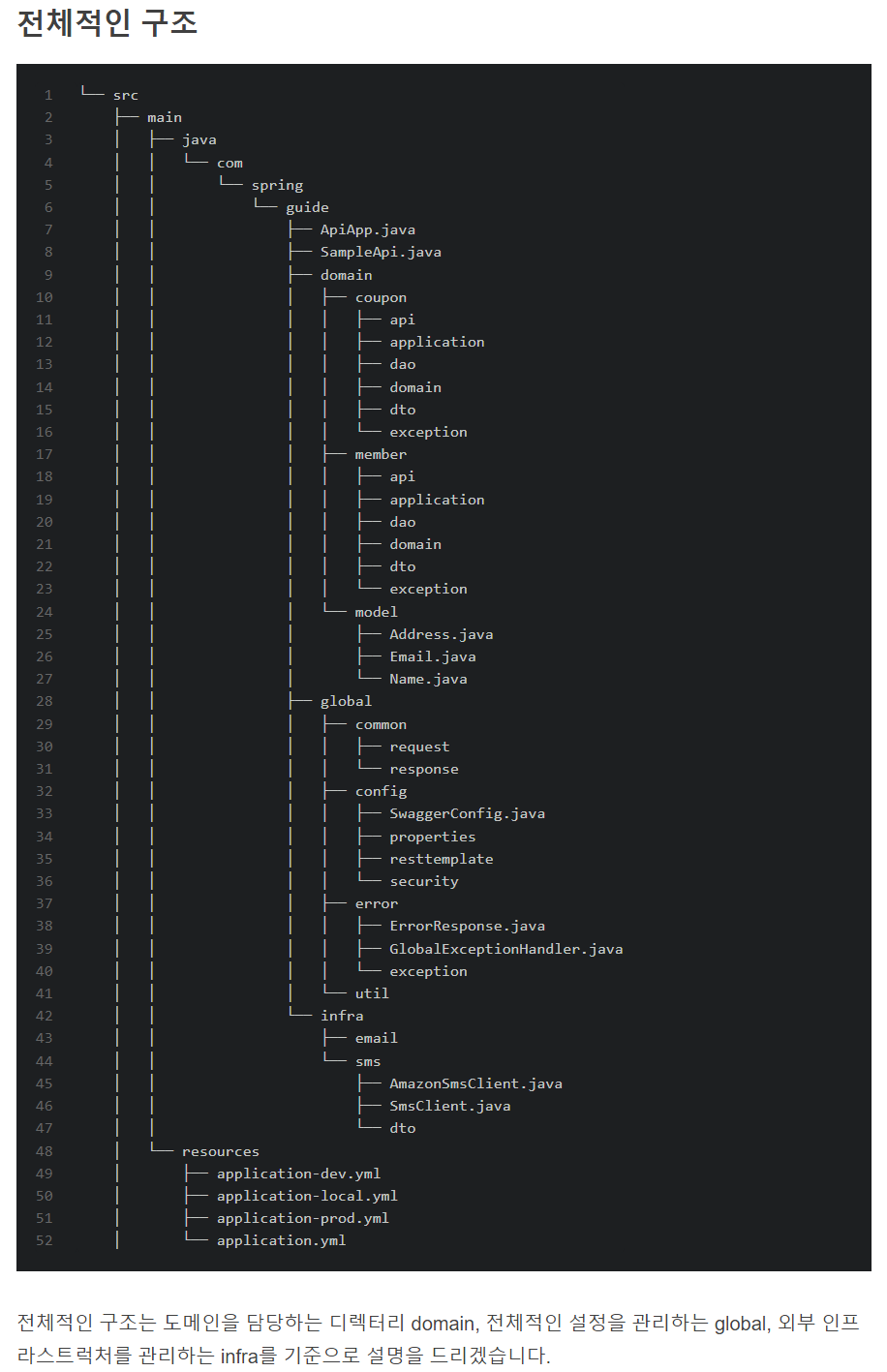
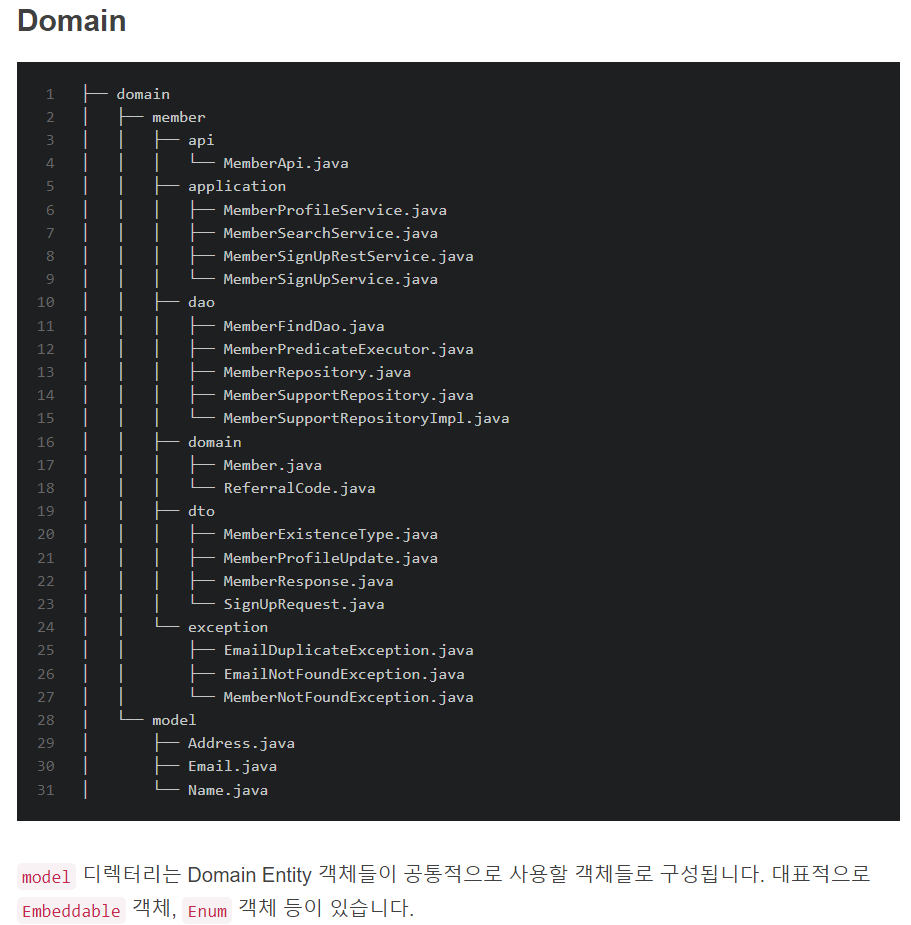
- api
컨트롤러 클래스들이 존재합니다.
- domain
도메인 엔티티에 대한 클래스로 구성됩니다. 특정 도메인에만 속하는 Embeddable, Enum 같은 클래스도 구성됩니다.
- dto
주로 Request, Response 객체들로 구성됩니다.
- exception
해당 도메인이 발생시키는 Exception으로 구성됩니다.
- application
서비스 클래스들이 존재
- dao
레포지토리 클래스가 존재
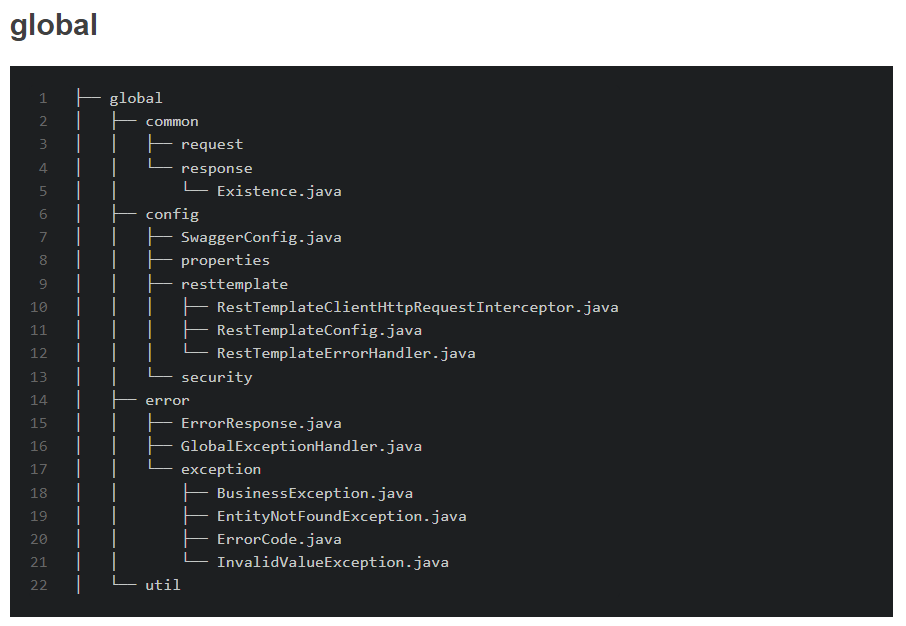
global은 프로젝트 전방위적으로 사용되는 객체들로 구성됩니다.
- config
스프링 각종 설정들로 구성됩니다.
- error
예외 핸들링을 담당하는 클래스로 구성됩니다.
- util
유틸성 클래스들이 위치합니다.
MDD의 개념
MDD는 모델에 중점을 둔 개발 방법론으로 모델을 이용하여 목표 시스템을 단순화함으로써, 사용자는 시스템을 쉽게 이해할 수 있고 개발자는 개발을 용이하게 하는 것을 목적으로 한 개발 방법론입니다.
MDD의 특징
- 모델 개발 중점
-
특징을 추출하여 단순화하는 표현 방식
상위, 하위 모델로 구분하며 하위모델로 갈수록 구체적으로 표현
-
사용자와 기술자가 소통할 수 있는 언어로 표현
일반적인 모델링 언어로는 UML, SQL, BPMN, ER-D 등이 있습니다.
-
모델을 중심으로 분석, 설계를 수행하고 이를 기반으로 소스코드 및 산출물을 자동으로 생성
프로그램 코드간의 변환을 자동화함으로써 코드를 작성하는 번거로움과 오류 줄여 생산성을 향상 시킵니다.
-
개발 플랫폼에 종속되지 않는 메타모델 사용
MDD의 표준의 하나인 OMG의 MDA는 CIM, PM, PSM을 정의하고 모델의 변환을 통해 소프트웨어를 생성 -
모델간의 변환, 모델과 소스간의 변환을 구현하는 MDD 도구 지원 필수
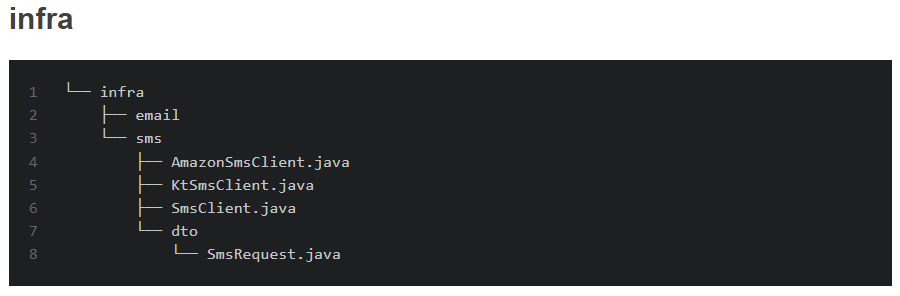
infra 디렉터리는 인프라스트럭처 관련된 코드들로 구성됩니다. 인프라스트럭처는 대표적으로 이메일 알림, SMS 알림 등 외부 서비스에 대한 코드들이 존재합니다. 그렇기 때문에 domain, global에 속하지 않습니다. OAuth2, 외부 기능을 사용한 이메일 인증, S3 설정 등과 같은 외부 기능이나 외부 인프라스트럭처와 관련된 코드는 일반적으로 "infra" 디렉터리에 속합니다. 이 디렉터리는 프로젝트의 인프라스트럭처 계층에 해당하며, 외부 서비스나 리소스와의 연동, 설정, 클라이언트 등을 다루는 코드들을 포함합니다.
서버 간 통신
최근에 개발되는 서비스들은 마이크로서비스 아키텍쳐(MSA)를 주로 채택하고 있습니다. MSA는 말 그대로 애플리케이션이 가지고 있는 기능(서비스)이 하나의 비즈니스 범위만 가지는 형태입니다. 각 애플리케이션은 자신이 가진 기능을 API로 외부에 노출하고, 다른 서버가 그러한 API를 호출해서 사용할 수 있게 구성되므로 각 서버가 다른 서버의 클라이언트가 되는 경우도 많습니다. 이번에는 이러한 트랜드에 맞추어 다른 서버로 웹 요청을 보내고 응답을 받을 수 있게 도와주는 RestTemplate과 WebClient에 대해 살펴보겠습니다.
RestTemplate란?
Spring에서 제공하는 REST API Server와의 HTTP 통신을 위한 객체, 서버와 서버간의 연동을 위해 사용된다. RestTemplate은 스프링에서 HTTP 통신 기능을 손쉽게 사용하도록 설계된 템플릿입니다. HTTP 서버와 통신을 단순화한 이 템플릿을 이용하면 RESTful 원칙을 따르는 서비스를 편리하게 만들 수 있습니다. RestTemplate은 기본적으로 동기 방식으로 처리되며, 비동기 방식으로 사용하고 싶을 경우 AsyncRestTemplate을 사용하면 됩니다. 다만 RestTemplate은 현업에서는 많이 쓰이나 지원 중단(deprecated)된 상태라서 향후 빈번하게 쓰게될 WebClient방식도 함께 알아두면 좋습니다.
RestTemplate은 다음과 같은 특징을 가지고 있습니다.
- HTTP 프로토콜의 메서드에 맞는 여러 메서드를 제공
- RESTful 형식을 갖춘 템플릿
- HTTP 요청 후 JSON, XML, 문자열 등의 다양한 형식으로 응답을 받을 수 있습니다.
- 블로킹(blocking) I/O 기반의 동기 방식을 사용합니다.
- 다른 API를 호출할 때 HTTP 헤더에 다양한 값을 설정할 수 있습니다.
RestTemplate의 동작 원리

여기서 애플리케이션은 우리가 직접 작성하는 애플리케이션 코드 구현부를 의미합니다. 애플리케이션에서는 RestTemplate을 선언하고 URI와 HTTP 메서드, Body 등을 설정합니다. 그리고 외부 API로 요청을 보내게 되면 RestTemplate에서 HttpMessageConverter를 통해 RequestEntity를 요청 메시지로 변환합니다.
RestTmeplate에서는 변환된 요청 메시지를 ClientHttpReqestFactory를 통해 ClientHttpRequest로 가져온 후 외부 API로 요청을 보냅니다.
외부에서 요청에 대한 응답을 받으면 RestTemplate은 ResponseErrorHandler로 오류를 확인하고, 오류가 있다면 ClientHttpResponse에서 응답 데이터를 처리합니다.
받은 응답 데이터가 정상적이라면 다시 한번 HttpMessageConverter를 거쳐 자바 객체로 변환해서 애플리케이션으로 반환합니다.
RestTemplate 대표적인 메서드
RestTemplate에서는 더욱 편리하게 외부 API로 요청을 보낼 수 있도록 다음과 같은 다양한 메서드를 제공합니다.
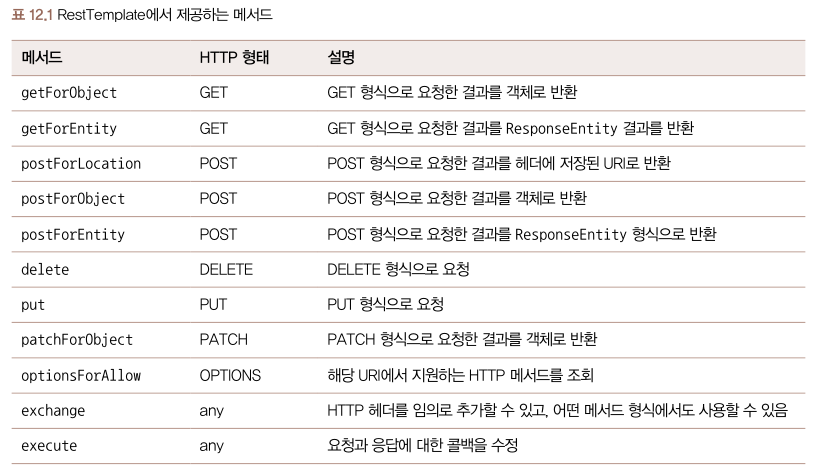
RestTemplate 구현하기
일반적으로 RestTemplate은 별도의 유틸리티 클래스로 생성하거나 서비스 또는 비즈니스 계층에 구현됩니다. 앞서 생성한 서버 프로젝트에 요청을 날리기 위해 서버의 역할을 수행하면서 다른 서버로 요청을 보내는 클라이언트의 역할도 수행하는 새로운 프로젝트를 생성합니다. 이걸 간단하게 도식화하면 다음과 같습니다.
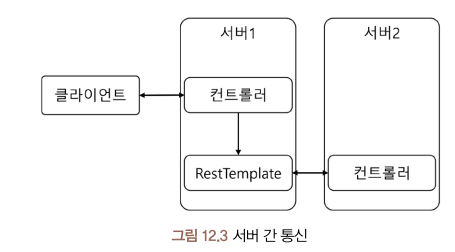
위 그림에서 클라이언트는 서버를 대상으로 요청을 보내고 응답을 받는 역할을 하고 구현한 서버 프로젝트는 서버2가 됩니다.
WebClient란?
일반적으로 실제 운영환경에 적용되는 애플리케이션은 정식 버전으로 출시된 스프링 부트의 버전보다 낮은 경우가 많습니다. 그렇기 때문에 RestTemplate을 많이 사용하고 있습니다. 하지만 최신 버전에서는 RestTemplate가 지원 중단되어 WebClient를 사용할 것을 권고하고 있습니다. 이러한 흐름에 맞춰 현재 빈번히 사용되고 있는 RestTemplate과 앞으로 많이 사용될 WebClient 모두 알고 있는 것이 좋습니다.
Spring WebFlux는 HTTP 요청을 수행하는 클라이언트로 WebClient를 제공합니다. WebClient는 리액터(Reactor) 기반으로 동작하는 API입니다. 리액터 기반이므로 스레드와 동시성 문제를 벗어나 비동기 형식으로 사용할 수 있습니다. WebClient의 특징을 먼저 살펴보겠습니다.
- 논블로킹(Non-Blocking) I/O를 지원합니다.
- 리액티브 스트림(Reactive Streams)의 백 프레셔(Back Pressure)를 지원합니다.
- 적은 하드웨어 리소스로 동시성을 지원합니다.
- 함수형 API를 지원합니다.
- 동기, 비동기 상호작용을 지원합니다.
- 스트리밍을 지원합니다.
최근 프로그래밍 추세에 맞춰 스프링에도 리액티브 프로그래밍(Reactive Programming)이 도입되면서 여러 동시적 기능이 제공되고 있습니다.
WebClient 구성
WebClient를 사용하려면 WebFlux 모듈에 대한 의존성을 추가해야 합니다.
// maven
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
// gradle
dependencies {
compile 'org.springframework.boot:spring-boot-starter-webflux'
}