
CPU의 작동 원리
레지스터
-
스택 포인터
스택의 꼭대기 가리킴 -
프로그램 카운터
메모리에서 가져올 명령어 주소(메모리에서 읽어 들일 명령어 주소) -
명령어 레지스터
해석할 명령어 -
메모리 주소 레지스터
메모리의 주소를 저장 -
메모리 버퍼 레지스터
메모리와 주고받을 값(데이터와 명령어) -
플래그 레지스터
연산 결과 또는 CPU 상태에 대한 부가적인 정보 -
범용 레지스터
다양하고 일반적인 상황에서 자유롭게 사용 -
베이스 레지스터
기준 주소 저장 -
스택 주소 지정 방식
스택과 스택 포인터를 이용한 주소 지정 방식 -
메모리 안에 스택 영역이 존재합니다.
-
변위 주소 지정 방식
오퍼랜드 필드 값(변위)과 특정 레지스터의 값을 더하여 유효 주소 얻기 -
상대 주소 지정 방식
오퍼랜드 필드의 값(변위)과 프로그램 카운터의 값을 더하여 유효 주소 얻기 -
베이스 레지스터
기준 주소
정적 프로그램(static program)
컴퓨터에서 실행 할 수 있는 파일 window 기준으로 exe 파일들을 프로그램이라고 부른다. 그러나, 아직 실행 되지 않았기 때문에 정적 프로그램 (Static Program) 혹은 그냥 줄여서 프로그램(Program)이라고도 부른다.
그것을 실행하는 순간, 프로그램이 움직일 수있는 작업 공간이 생겨야 되는데, 이것이 바로 프로세스이다
프로세스
실행파일로 존재하던 프로그램이 메모리에 적재되어 CPU에 의해 실행되는 것을 process라고 한다. 실행 파일을 실행시키면 하나의 Process가 생성된다. 즉, 운영체제에서 실행중인 하나의 프로그램(하나 이상의 쓰레드를 포함한다.)이고 각각의 프로세스는 독립된 메모리 공간을 할당 받는다.
Process간의 통신
-
Process끼리는 메모리 공유가 안되기 때문에 통신을 해야 됨
-
HTTP도 좋고TCP도 좋고 편한거 쓰면 됨 -
MSA (MicroService Architecture)를 지향하는 현대 사회에서 Process간의 통신은 필수
-
Process간의 통신을 위해 프로토콜을 만들고 통신하는 코드를 만들고 서로 다른 언어를 써서 만든 Process끼리면 서로 패킷 모델을 주고받는 것도 스트레스다.
그래서 나온게
Google Protobuf나Apache Avro
Json Format을 사용해도 되지만 하지만 필드가 하나 추가되거나 하면 어떻게 상대방에게 알려줄 것인가 이런 문제가 있으니 위의 것을 사용하는 것이 편하다. 이것 외에 다른 방법도 있다.Redis의 특정 Key에 데이터를 넣고 Pub/Sub을 이용하는 방법도 있고 빠르게 통신할 필요가 없다면 AWS SQS같은 Queue에 넣고 데이타가 추가됐을때 특정 Topic으로 Event를 받는 방법도 있다.
단일 프로세스
한 번에 하나의 프로그램만 실행됨
단점
CPU 사용률이 좋지 않다.
스레드
크롬 브라우저가 실행 되는 순간, 프로세스 하나가 생성된다.
그러나, 사용자는 브라우저에서 한 번에 한가지 일만 하지는 않는다!! 게임을 다운 받으면서, 온라인 쇼핑을 할 수도 있고, 혹은 Youtube 영상의 데이터를 받아오면서, 받아진 데이터로 영상을 실행할 수도 있어야 한다. 다시 말해서, 하나의 프로세스 안에서도 여러가지 작업들이 동시에 진행될 필요가 있다!!

하나의 프로세서 내에서 동시에 진행되는 작업들, 프로세스 내에서 실행되는 흐름의 단위인데 이 갈래들을 스레드 (Thread)라고 부른다. 이걸 보면 Process안에 Thread가 만들어진다. 즉, 프로세스내에서 동시에 실행되는 독립적인 실행 단위를 말함, 장점으로는 자원을 많이 사용하지 않고 구현이 쉬우며 범용성이 높다.
그러나, 프로세스와는 다르게 하나의 스레드가 발생한다고 해서, 그것만을 위한 작업 공간을 제공하지는 않는다!!
스레드는 어디까지나 프로세스라는 하나의 프로젝트를 위한 하위 작업 일뿐이다. 개인 작업 공간을 가지고 있는 것보다 같은 프로세스를 위한 스레드들이 같은 작업 공간에서 같은 자원을 공유하는 것이 더 효율적이다.
Thread 장점
- 빠른 프로세스 생성
- 적은 메모리 사용
- 쉬운 정보 공유
Thread 단점
교착상태에 빠질 수 있다.
교착상태 : 다중프로그래밍 체제에서 하나 또는 그 이상의 프로세스가 수행 할 수 없는 어떤 특정시간을 기다리고 있는 상태.
Thread와 Process 차이
여러 분야에서 과정 또는 처리라는 뜻으로 사용되는 용어로 컴퓨터 분야에서는 실행중인 프로그램이라는 뜻으로 쓰인다. 이 프로세스 내에서 실행되는 각각의 일을 스레드라고 한다. 프로세스 내에서 실행되는 세부 작업 단위로 여러 개의 스레드가 하나의 프로세스를 이루게 되는 것이다.
Thread끼리는 메모리 공유가 되는데 Process끼리는 메모리 공유가 안된다.
스레드 상태
-
NEW
생성되고 아직 start가 호출되지 않은 상태 -
RUNNABLE
실행 중 또는 실행 가능한 상태 -
BLOCKED
동기화 블럭에 의해서 일시정지된 상태(lock이 풀릴 때까지 기다리는 상태) -
WAITING
다른 스레드가 통지할 때까지 기다리는 상태메인 스레드에서 별도 스레드를 만들고 별도 스레드.join()을 호출하면 메인 스레드는 별도 스레드가 끝날 때 까지 해당 위치에서 대기하다가 끝난 후에야 이 후 로직을 수행한다.
-
TIMED_WAITING
주어진 시간 동안 기다리는 상태스레드를 하나 만들고 run메서드에서 sleep을 시키고 메인 스레드에서 해당 스레드의 상태를 getState로 찍어보면 TIMED_WAITING 상태로 찍힌다.
-
TERMINATED
스레드의 작업이 종료된 상태스레드 스케줄링
-
sleep
주어진 시간동안 일시 정지 -
join
특정 스레드가 다른 스레드의 완료를 대기 -
interrupt
sleep, join에 의해 일시정지 상태인 스레드를 실행 대기 상태로 전환하는 것 -
yield
실행 중 다른 스레드에게 양보하고 실행 대기 상태가 되는 것스레드 그룹
-
서로 관련된 스레드를 그룹으로 묶어서 다루기 위한 것으로 모든 스레드는 반드시 하나의 스레드 그룹에 포함되어 있어야 한다.
-
스레드 그룹을 지정하지 않고 생성한 스레드는 main 스레드 그룹에 속한다.
-
자신을 생성한 스레드(부모 스레드)의 그룹과 우선 순위를 상속받는다.
💡쓰레드를 구현하기 위한 인터페이스, 클래스는 무엇이 있나요?
-
Runnable 인터페이스를 사용하여 람다 혹은 내부 클래스로
run()메서드 구현 -
새로운 클래스를 정의하고 Thread 클래스를 상속받은 후
run()메서드 구현
다른 클래스를 상속받지 않아도 될 때 => Thread 클래스 상속 후 구현
Thread 클래스에 존재하는 다른 메소드들도 사용하고 싶을 때 => Thread 클래스 상속 후 구현 그 외는 Runnable 구현
Single Thread란?
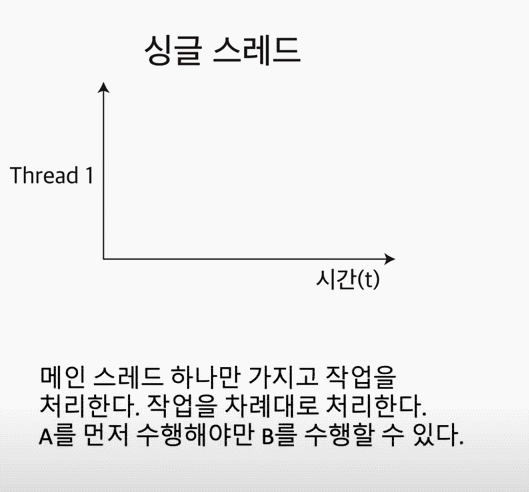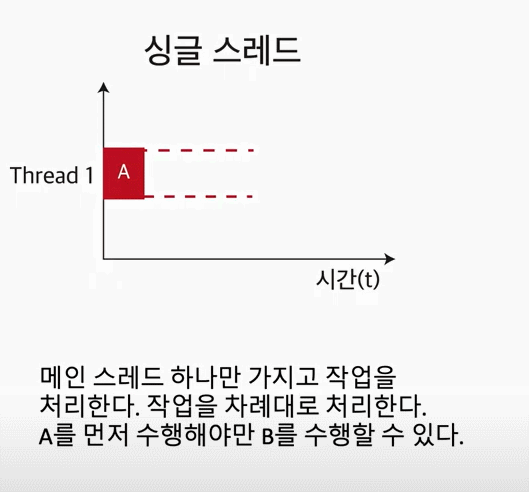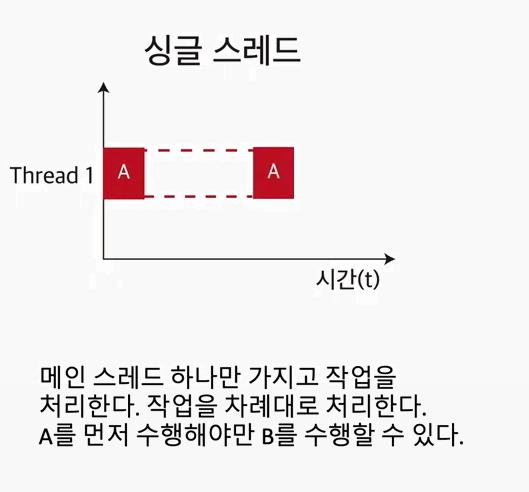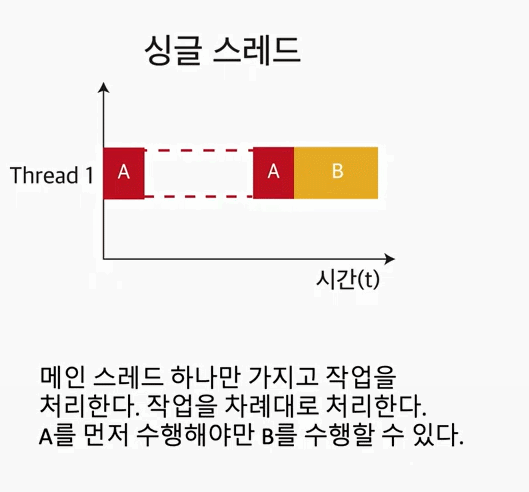
하나의 프로세스에서 오직 하나의 스레드로만 실행한다. 그렇기 때문에, 하나의 레지스터와 스택으로 표현이 가능하다.
싱글 스레드 장점
-
문맥 교환(context switch) 작업을 요구하지 않는다.
문맥 교환은 여러 개의 프로세스가 하나의 프로세서를 공유할 때 발생하는 작업으로 많은 비용을 필요로 한다.
-
자원 접근에 대한 동기화를 신경쓰지 않아도 된다.
여러 개의 스레드가 프로세스의 자원을 공유할 경우, 각 스레드가 원하는 결과를 얻게 하려면 공용 자원에 대한 접근을 제어해야 한다. 쉽게 말해서, 모든 스레드가 일정 자원에 동시에 접근하거나, 똑같은 작업을 실행하려는 경우, 에러가 발생하거나 원하는 값이 나오지 않는다. 그래서, 스레드들이 동시에 같은 자원에 접근하지 못하도록 제어해줘야만 한다. 이 작업은 프로그래머에게 많은 노력을 요구하고 비용을 발생시킨다.
-
단순히 CPU만을 사용하는 계산작업이라면, 오히려 멀티스레드보다 싱글스레드로 프로그래밍하는 것이 더 효율적이다.
-
프로그래밍 난이도가 쉽고, CPU, 메모리를 적게 사용한다. (코스트가 적게든다)
싱글 스레드 단점
-
여러 개의 CPU를 활용하지 못한다.
프로세서를 최대한 활용하게 하려면 cluster 모듈을 사용하거나 외부에서 여러 개의 프로그램 인스턴스를 실행시키는 방법을 사용해야 한다. 이 때 고려해야할 문제가 있는데, 바로 다수의 프로그램 인스턴스가 어떻게 상태를 공유할 것인가에 대한 문제다.
-
연산량이 많은 작업을 하는 경우, 그 작업이 완료되어야 다른 작업을 수행할 수 있다.
-
싱글 스레드 모델은 에러 처리를 못하는 경우 멈춘다.
Multi Thread란?
한 Process안에 Main Thread 외에 다른 Thread가 있으면 Multi Thread이지만 Thread간에 아무런 메모리 공유가 일어나지 않는다면 Multi Thread라고 부르기 애매함

멀티 스레드는 CPU의 최대 활용을 위해 프로그램의 둘 이상을 동시에 실행하는 기술이다.
이러한 작업은 컨텍스트 스위칭(Context Switching)을 통해서 이뤄진다. 위의 이미지에서 하나의 스레드에서 다음 스레드로 이동을 하면서, 컨텍스트 스위칭이 일어난다. 그리고, 스위칭이 일어나면서 부분적으로 조금씩 조금씩 각각의 스레드에 대한 작업을 끝내게 된다.
Context switching
실제 컴퓨터에서는 이 상태들에 해당하는 프로세스들을 번갈아가면서 지속적으로 실행한다. 그리고 프로세스를 변경해주는 주기를 사람이 눈치채기 힘들정도의 짧은 시간으로 설정하여 빠르게 실행중인 프로세스를 전환한다.
Process나 Thread가 중단됐다가 다시 실행될때 필요한 정보를 Context라고 한다. 현재 실행중인 Context를 잠시 중단 및 저장하고 새로운 Context를 로딩및 실행하는것을 Context Switching이라고 한다.
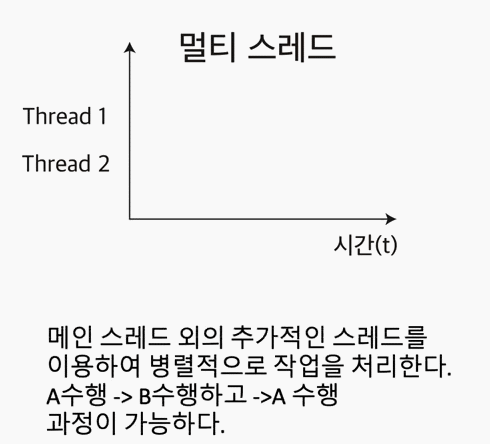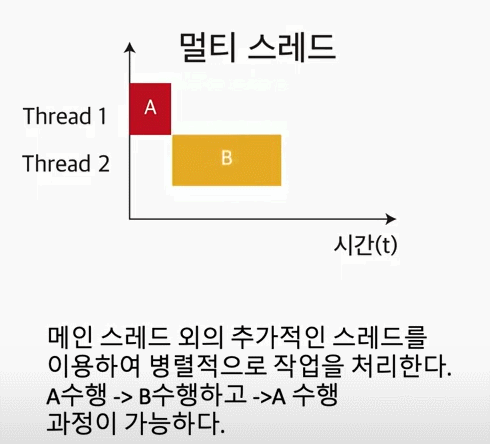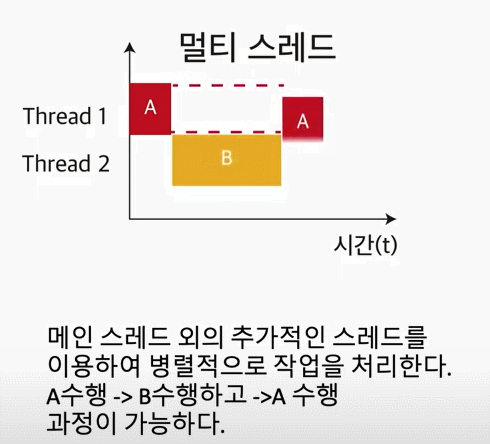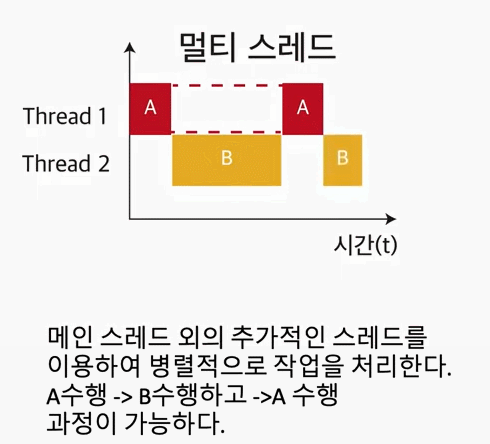
다시 말해서, context switching이 엄청 빠르게 일어나면서, 유저(=User)의 시선에서는 프로그램들이 동시에 수행되는 것처럼 보인다.
모든 Thread가 하나의 Queue를 공유한다면 괜찮을까?
괜찮지 않다. 이런 문제를 피하는 제어를
배타제어라고 한다.
멀티 스레드 장점
-
응답성
프로그램의 일부분(스레드 중 하나)이 중단되거나 긴 작업을 수행하더라도 프로그램의 수행이 계속 되어 사용자에 대한 응답성이 증가한다. 다시 말해서, 멀티 스레드 모델은 에러 발생 시 새로운 스레드를 생성하여 극복한다. 다만, 새로운 스레드 생성이나 놀고 있는 스레드 처리에 비용이 발생한다. ( 싱글 스레드는 프로그램 일부분이 중단되거나, 에러가 발생하면 프로그램이 멈춘다 ) -
경제성
프로세스 내 자원들과 메모리를 공유하기 때문에 메모리 공간과 시스템 자원 소모가 줄어든다. 스레드 간 통신이 필요한 경우에도 쉽게 데이터를 주고 받을 수 있으며, 프로세스의 context switching과 달리 스레드 간의 context switching은 캐시 메모리를 비울 필요가 없기 때문에 더 빠르다. -
멀티프로세서의 활용
다중 CPU 구조에서는 각각의 스레드가 다른 프로세서에서 병렬로 수행될 수 있으므로 병렬성이 증가한다.
멀티 스레드 단점
-
context switching, 동기화 등의 이유 때문에 싱글 코어 멀티 스레딩은 스레드 생성 시간이 오히려 오버헤드로 작용해 단일 스레드보다 느리다.
-
공유하는 자원에 동시에 접근하는 경우, 프로세스와는 달리 스레드는 데이터와 힙 영역을 공유하기 때문에 어떤 스레드가 다른 스레드에서 사용 중인 변수나 자료구조에 접근하여 엉뚱한 값을 읽어오거나 수정할 수 있다. 따라서 동기화가 필요!
-
멀티 스레딩을 위해서는 운영체제의 지원이 필요하다.
-
멀티 스레드 모델은 프로그래밍 난이도가 높다. 또한, 스레드 수만큼 자원을 많이 사용한다. 초보자의 경우, 동일한 프로그램을 만든다면, 싱글 스레드로는 완성이라도 한다. 그러나, 멀티 스레드의 경우는 완성도 못하는 경우도 많다.
💡멀티 스레드를 사용하는 이유?
-
멀티 스레드는 각 스레드가 자신이 속한 프로세스의 메모리를 공유하므로, 시스템 자원의 낭비가 적다.
-
하나의 스레드가 작업을 할 때 다른 스레드가 별도의 작업을 할 수 있어 사용자와의 응답성도 좋아진다.
💡멀티 쓰레드 프로그래밍을 개발할 때 주의해야 할 점은 무엇인가요?
공유 데이터를 사용하는 코드 영역인 임계구역에서 서로 다른 쓰레드가 간섭하지 않도록 쓰레드를 동기화 시켜 신뢰성 있는 데이터와 로직이 산출(?)될 수 있게끔 코드를 작성해야합니다. 락을 거는 행위는 성능에 영향을 미치고 데드락을 유발할 수도 있으니 조심해야 합니다.
배타제어
Concurrent
-
처음부터 망가뜨릴 수 없는 오브젝트를 만든다.
Concurrent가 Prefix로 붙는 클래스들을 사용함
-
Concurrent클래스가 어떻게 구현되어 있느냐에 따라
성능저하가 발생할수 있음 -
일반클래스도 Read는 Thread Safe한 경우가 있다. Write는 한 Thread에서만 하고 Read를 여러 Thread가 하는 경우 유용함
Lock
- 특정 코드 구간을 반드시 한 Thread만 실행하도록 막음
- 크리티컬 섹션이라고도 부름
- Lock을 건 코드의 구간의 실행시간이 길수록 성능저하가 발생함. 최악의 경우엔 차라리 Single Thread가 나음
그래서 One Process, One Thread Architecture가 나옴
Lock-Free
Lock을 사용하지 않고 배타제어를 하는데 목적을 두고 있음
Entry Point(진입점)란?
- 위 처럼 Process가 맨 처음 실행하는 함수
- Main Thread에서 실행됨
- 위 함수 실행이 종료되면 Process도 파괴
동기화
멀티 스레드 프로그래밍에는 하나의 프로세스를 동시에 여러 스레드가 접근하게 된다. 즉, 하나의 데이터를 공유해서 작업한다.
-
synchronized 키워드를 통해 공유 데이터에 lock을 걸어서 먼저 작업 중이던 스레드가 작업을 완전히 마칠 때까지 다른 스레드가 접근해도 공유 데이터가 변경되지 않도록 보호하는 기능을 제공한다.
-
synchronized 키워드는 어떤 것을 위한 wait, notify인지 명시적으로 알기 어렵기 때문에 lock, condition을 사용하기도 한다.
-
스레드 로컬을 사용하면 각 스레드만의 고유 공간을 만들어서 사용할 수 있다.
-
java.util.concurrent패키지에 동기화 컬렉션과 atomic 자료형을 제공한다.atomic은 CAS알고리즘을 사용한다.
특정 메모리 위치와 주어진 위치의 value를 비교해 다르면 대체하지 않는다.
CPU의 성능 향상 기법
명령어 파이프라인
명령어가 처리되는 과정을 비슷한 시간 간격으로 나누면?
- 명령어 인출
- 명령어 해석
- 명령어 실행
- 결과 저장
같은 단계가 겹치지만 않는다면 CPU는 각 단계를 동시에 실행할 수 있다.
데이터 위험
명령어 간의 의존성에 의해 야기
제어 위험
프로그램 카운터의 갑작스러운 변화
명령어 주소 지정 방식
유효 주소
연산에 사용할 데이터가 저장된 위치
명령어 주소 지정 방식
- 연산에 사용할 데이터가 저장된 위치를 찾는 방법
- 유효 주소를 찾는 방법
- 다양한 명령어 주소 지정 방식들
즉시 주소 지정 방식
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시
- 가장 간단한 형태의 주소 지정 방식
- 연산에 사용할 데이터의 크기가 작아질 수 있지만 빠름
서브넷
서브넷이란 부분적인 네트워크를 말합니다. 모든 네트워크망이 거대한 하나의 망으로 이루어진 것은 아닙니다. 네트워크망에서 서브넷을 통해 부분적인 네트워크망으로 나누어지고 서로 연결되어 있습니다.
서브넷 마스크
나누어진 서브넷은 서브넷 마스크로 구분할 수 있습니다. 서브넷 마스크는 IP 주소에 네트워크 ID와 호스트 ID를 구분하는 기준값입니다.
- 네트워크 ID는 서브넷을 식별하는 영역
- 호스트 ID는 서브넷에서 대상을 식별하는 영역
네트워크 기초
네트워크란 노드와 링크가 서로 연결되어 있거나 연결되어 있으며 리소스를 공유하는 집합을 의미합니다.
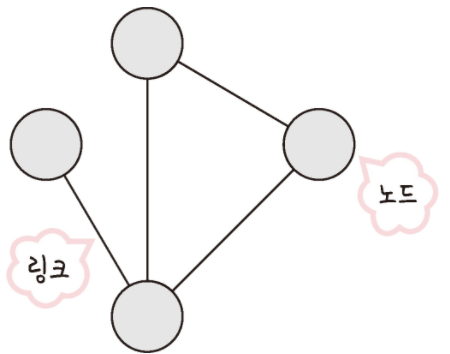
여기서 노드란 서버, 라우터, 스위치 등 네트워크 장치를 의미하고 링크는 유선 또는 무선을 의미합니다.
처리량과 지연 시간
네트워크를 구축할 때는 '좋은' 네트워크로 만드는 것이 중요합니다. 좋은 네트워크란 많은 처리량을 처리할 수 있으며 지연 시간이 짧고 장애 빈도가 적으며 좋은 보안을 갖춘 네트워크를 말합니다.
처리량
처리량은 링크 내에서 성공적으로 전달된 데이터의 양을 말하며 보통 얼만큼 트래픽을 처리했는지를 나타냅니다.
많은 트래픽을 처리한다 = 많은 처리량을 가진다는 의미

단위로는 bps(bits per second)를 씁니다. 초당 전송 또는 수신되는 비트 수라는 의미입니다. 처리량은 사용자들이 많이 접속할 때마다 커지는 트래픽, 네트워크 장치 간의 대역폭, 네트워크 중간에 발생하는 에러, 장치의 하드웨어 스팩에 영향을 받습니다.
앞으 그림을 보면 트래픽이 있는데 트래픽은 특정 시점에 링크 내에 '흐르는' 데이터의 양을 말합니다. 예를 들어 서버에 저장된 파일을 클라이언트(사용자)가 다운로드할 때 발생되는 데이터의 누적량을 뜻합니다.
- 트래픽이 많아졌다 = 흐르는 데이터가 많아졌다.
- 처리량이 많아졌다 = 처리되는 트래픽이 많아졌다.
대역폭
주어진 시간 동안 네트워크 연결을 통해 흐를 수 있는 최대 비트 수
지연 시간
지연 시간(latency)이란 요청이 처리되는 시간을 말하며 어떤 메시지가 두 장치 사이를 왕복하는데 걸린 시간을 말합니다.
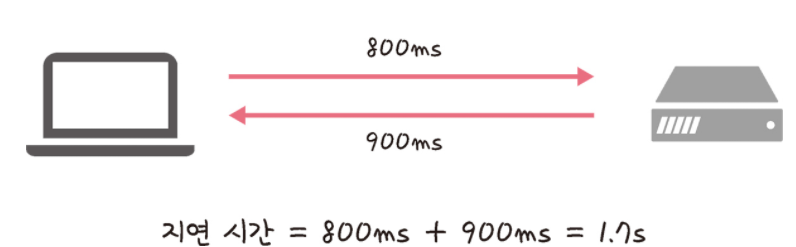
지연 시간은 매체 타입(무선, 유선), 패킷 크기, 라우터의 패킷 처리 시간에 영향을 받습니다.
네트워크 토폴로지와 병목 현상
네트워크를 설계할 때 고려하는 네트워크 토폴리지를 알아보겠습니다. 네트워크 토폴로지는 노드와 링크가 어떻게 배치되어 있는지에 대한 방식이자 연결 상태를 의미합니다.
트리 토폴로지
트리(tree) 토폴로지는 계층형 토폴로지라고 하며 트리 형태로 배치한 네트워크 구성을 말합니다.
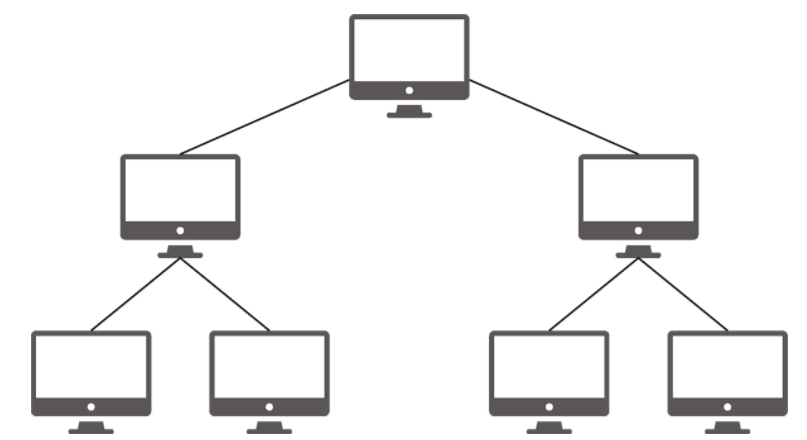
노드의 추가, 삭제가 쉬우며 특정 노드에 트래픽이 집중될 때 하위 노드에 영향을 끼칠 수 있습니다.
버스 토폴로지
버스(bus) 토폴로지는 중앙 통신 회선 하나에 여러 개의 노드가 연결되어 공유하는 네트워크 구성을 말하며 근거리 통신망(LAN)에서 사용됩니다.
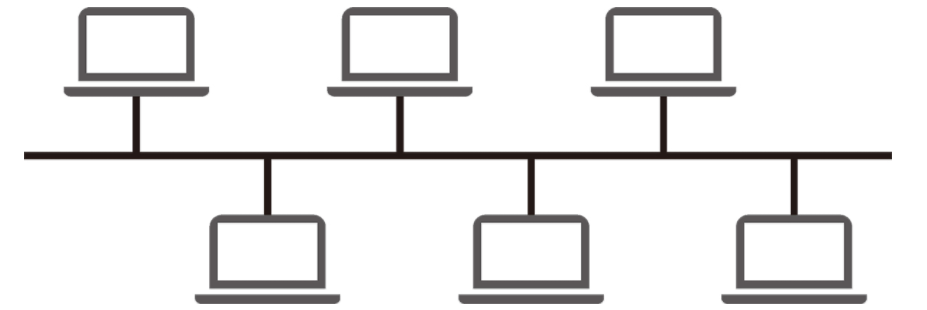
설치 비용이 적고 신뢰성이 우수하며 중앙 통신 회선에 노드를 추가하거나 삭제하기 쉽습니다. 그러나 스푸핑이 가능한 문제점이 있습니다.
스푸핑
스푸핑은 LAN 상에서 송신부의 패킷을 송신과 관련없는 다른 호스트에 가지 않도록 하는 스위칭 기능을 마비시키거나 속여서 특정 노드에 해당 패킷이 오도록 처리하는 것을 말합니다.
앞의 그림처럼 스푸핑을 적용하면 올바르게 수신부로 가야할 패킷이 악의적인 노드에 전달되게 합니다.

스타 토폴로지
스타(star, 성형) 토폴로지는 중앙에 있는 노드에 모두 연결된 네트워크 구성을 말합니다.

노드를 추가하거나 에러를 탐지하기 쉽고 패킷의 충돌 발생 가능성이 적습니다. 또한 어떠한 노드에 장애가 발생해도 쉽게 에러를 발견할 수 있으며 장애 노드가 중앙 노드가 아닐 경우 다른 노드에 영향을 끼치는 것이 적습니다. 하지만 중앙 노드에 장애가 발생하면 전체 네트워크를 사용할 수 없고 설치 비용이 고가입니다.
링형 토폴로지
링형(ring) 토폴로지는 각각의 노드가 양 옆의 두 노드와 연결하여 전체적으로 고리처럼 하나의 연속된 길을 통해 통신을 하는 망 구성 방식입니다.
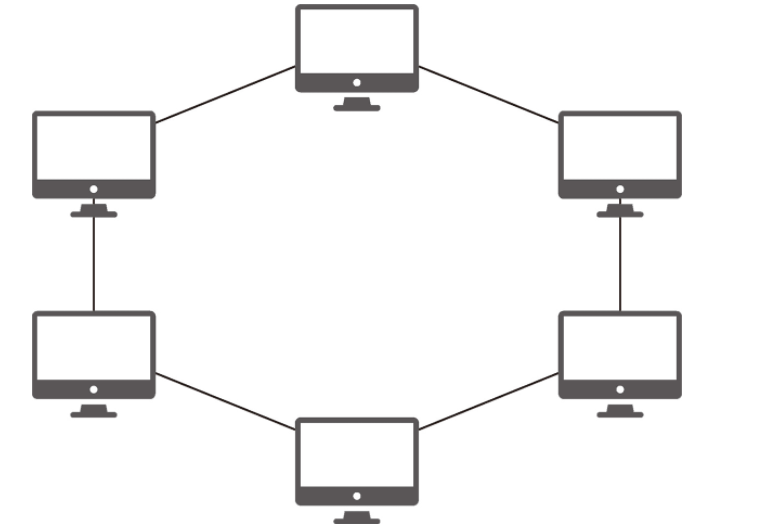
데이터는 노드에서 노드로 이동을 하게 되며 각각의 노드는 고리 모양의 길을 통해 피킷을 처리합니다. 노드 수가 증가되어도 네트워크 손실이 거의 없고 충돌이 발생하는 가능성이 적고 고장 발견을 쉽게 할 수 있습니다. 하지만 네트워크 구성 변경이 어렵고 회선에 장애가 발생하면 전체 네트워크에 영향을 크게 끼치는 단점이 있습니다.
메시 토폴로지
메시(mesh) 토폴로지는 망형 토폴로지라고도 하며 그물망처럼 연결되어 있는 구조입니다.
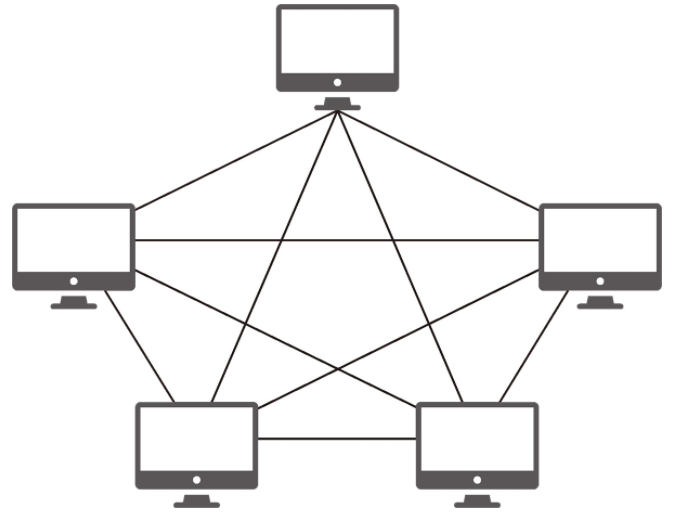
한 단말 장치에 장애가 발생해도 여러 개의 경로가 존재하므로 네트워크를 계속 사용할 수 있고 트래픽도 분산 처리가 가능합니다. 하지만 노드 추가가 어렵고 구축 비용과 운용 비용이 고가인 단점이 있습니다.
병목 현상
네트워크 구조라고도 일컫는 토폴로지가 중요한 이유는 병목 현상을 찾을 때 중요한 기준이 되기 때문입니다.
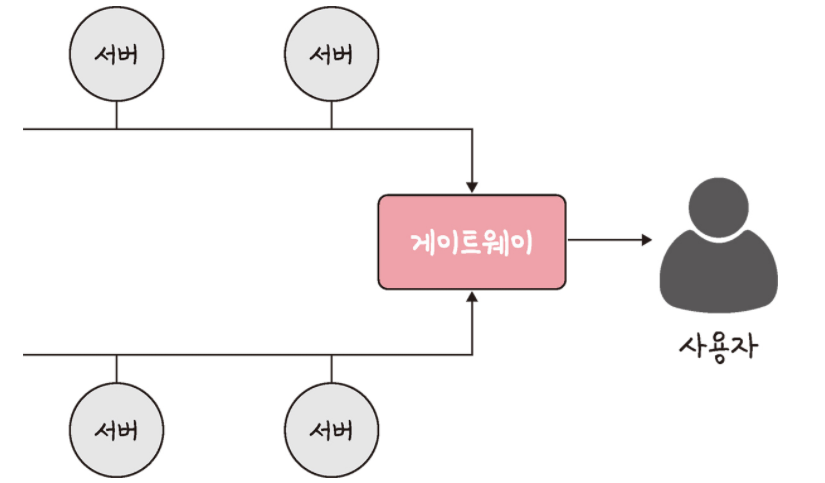
예를 들어, 앞의 그림처럼 서비스를 만들었는데, 병목 현상이 일어나서 사용자가 서비스를 이용할 때 지연 시간이 길게 발생하고 있다고 해봅시다. 관리자가 지연 시간을 짧게 만들기 위해 대역폭을 크게 설정했음에도 성능이 개선되지 않았습니다.
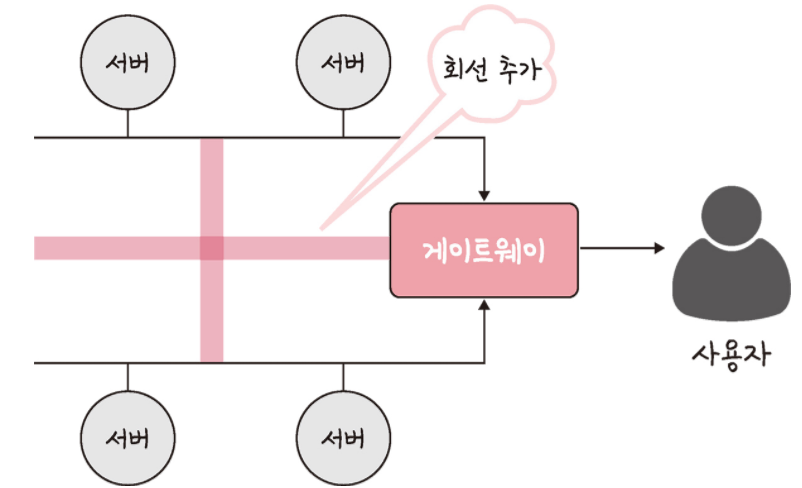
관리자가 네트워크 토폴리지가 어떻게 되어 있나 확인했고 서버와 서버 간 그리고 게이트 웨이로 이어지는 회선을 추가해서 병목 현상을 해결했습니다. 이처럼 네트워크가 어떤 포폴리지를 갖는지, 또한 어떠한 경로로 이루어져 있는지 알아야 병목 현상을 올바르게 해결할 수 있습니다.
병목 현상
병목 현상은 전체 시스템 성능이나 용량이 하나의 구성 요소로 인해 제한을 받는 현상을 말한다. 예를 들어 병의 몸통보다 병의 목 부분 내부 지름이 좁아서 물이 상대적으로 천천히 쏟아짖는 것에 비유할 수 있다. 서비스에서 이벤트를 열었을 때 트래픽이 많이 생기고 그 트래픽을 잘 관리하지 못하면 병목 현상이 생겨 사용자는 웹 사이트로 들어가지 못한다.
네트워크 분류
네트워크는 규모를 기반으로 분류할 수 있습니다. 사무실과 개인적으로 소유 가능한 규모인 LAN(Local Area Network)과 서울시 등 시 정도 규모인 MAN(Metropolitan Area Network), 그리고 세계 규모인 WAN(Wide Area Network)으로 나뉩니다.

네트워크 성능 분석 명령어
애플리케이션 코드상에는 전혀 문제가 없는데 사용자가 서비스로부터 데이터를 가져오지 못하는 상황이 발생되기도 하며, 이는 네트워크 병목 현상일 가능성이 있습니다. 네트워크 병목 현상의 주된 원인은 다음과 같습니다.
- 네트워크 대역폭
- 네트워크 토폴리지
- 서버 CPU, 메모리 사용량
- 비효율적인 네트워크 구성
이때는 네트워크 관련 테스트와 네트워크와 무관한 테스트를 통해 네트워크로부터 발생한 문제점인 것을 확인한 후 네트워크 성능 분석을 해봐야 합니다. 이때 사용하는 명령어를 알아보겠습니다.
ping
ping(Packet INternet Groper)은 네트워크 상태를 확인하려는 대상 노드를 향해 일정 크기의 패킷을 전송하는 명령어 입니다. 이를 통해 해당 노드의 패킷 수신 상태와 도달하기까지 시간 등을 알 수 있으며 해당 노드까지 네트워크가 잘 연결되어 있는지 확인할 수 있습니다. ping은 TCP/IP 프로토콜 중에 ICMP 프로토콜을 통해 동작하며, 이 때문에 ICMP 프로토콜을 지원하지 않는 기기를 대상으로는 실행할 수 없거나 네트워크 정책상 ICMP나 traceroute를 차단하는 대상의 경우 ping 테스팅은 불가능합니다.
netstat
netstat 명령어는 접속되어 있는 서비스들의 네트워크 상태를 표시하는데 사용되며 네트워크 접속, 라우팅 테이블, 네트워크 프로토콜 등 리스트를 보여줍니다. 주로 서비스의 포트가 열려 있는지 확인할 때 씁니다.

위 그림을 통해 지금 접속하고 있는 사이트 등에 관한 상태 리스트를 볼 수 있는 것을 알 수 있습니다.
nslookup
nslookup은 DNS에 관련된 내용을 확인하기 위해 쓰는 명령어입니다. 특정 도메인에 매핑된 IP를 학인하기 위해 사용합니다.
tracert
윈도우에서는 tracert이고 리눅스에서는 traceroute라는 명령어로 구동됩니다. 이것은 목적지 노드까지 네트워크 경로를 확인할 때 사용하는 명령어 입니다. 목적지 노드까지 구간들 중 어느 구간에서 응답 시간이 느려지는지 등을 확인할 수 있습니다.
네트워크 프로토콜 표준화
네트워크 프로토콜이란 다른 장치들끼리 데이터를 주고받기 위해 설정된 공통된 인터페이스를 말합니다. 이러한 프로토콜은 기업이나 개인이 발표해서 정하는 것이 아니라 IEEE 또는 IETF라는 표준화 단체가 이를 정합니다.
IEEEE802.3은 유선 LAN 프로토콜로 유선으로 LAN을 구축할 때 쓰이는 프로토콜입니다. 이를 통해 만든 기업이 다른 장치라도 서로 데이터를 수신할 수 있는 것이죠. 예를들어, 웹을 접속할 때 쓰이는 HTTP가 있습니다. 서로 약속된 인터페이스인 HTTP라는 프로토콜을 통해 노드들은 웹 서비스를 기반으로 데이터를 주고받을 수 있습니다.
TCP/IP 4계층 모델
인터넷 프로토콜 스위트(internet protocal suite)는 인터넷에서 컴퓨터들이 서로 정보를 주고 받는데 쓰이는 프로토콜 집합이며, 이를 TCP/IP 4계층 모델로 설명하거나 OSI 7계층 모델로 설명하기도 합니다.


계층 구조
TCP/IP 계층은 4개의 계층을 가지고 있으며 OSI 7계층과 많이 비교합니다.
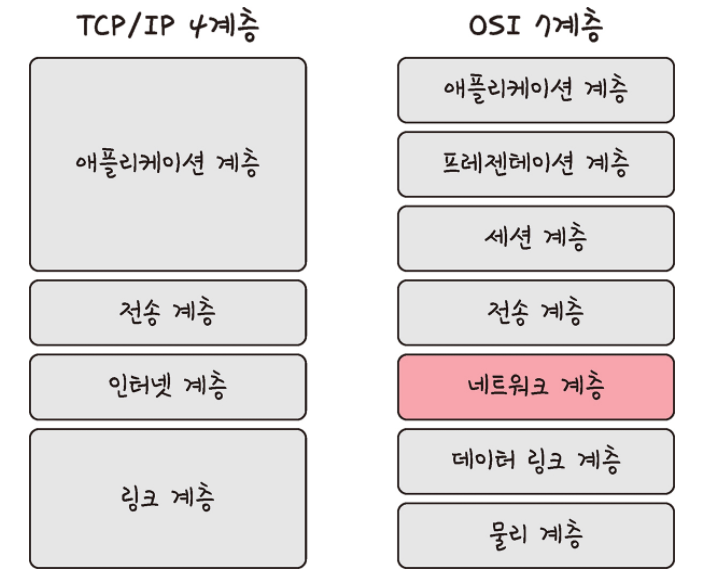
위의 그림처럼 TCP/IP 계층과 달리 OSI 계층은 애플리케이션 계층을 세 개로 쪼개고 링크 계층을 데이터 링크, 계층, 물리 계층으로 나눠서 표현하는 것이 다르며 인터넷 계층을 네트워크 계층으로부터 부른다는 점이 다릅니다.
이 계층들은 특정 계층이 변경되었을 때 다른 계층이 영향을 받지 않도록 설계되었습니다. 예를 들어, 전송 계층에서 TCP를 UDP로 변경햇다고 해서 인터넷 웹 브라우저를 다시 설치해야 하는 것은 아니듯 유연하게 설계된 것입니다.
- 7 계층(응용 계층) : 사용자에게 통신을 위한 서비스 제공. 인터페이스 역할
- 6 계층(표현 계층) : 데이터의 형식(Format)을 정의하는 계층 (코드 간의 번역을 담당)
- 5 계층(세션 계층) : 컴퓨터끼리 통신을 하기 위해 세션을 만드는 계층
- 4 계층(전송 계층) : 최종 수신 프로세스로 데이터의 전송을 담당하는 계층 (단위 :Segment) (ex. TCP, UDP)
- 3 계층(네트워크 계층) : 패킷을 목적지까지 가장 빠른 길로 전송하기 위한 계층 (단위 :Packet) (ex. Router)
- 2 계층(데이터링크 계층) : 데이터의 물리적인 전송과 에러 검출, 흐름 제어를 담당하는 계층 (단위 :frame) (ex. 이더넷)
- 1 계층(물리 계층) : 데이터를 전기 신호로 바꾸어주는 계층 (단위 :bit) (장비: 케이블,리피터,허브)

▼ 각 계층을 대표하는 스택
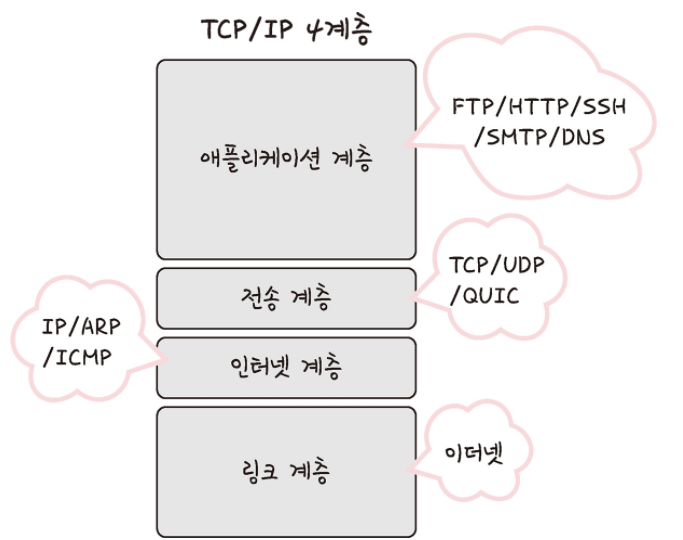
애플리케이션 계층
애플리케이션 계층은 FTP, HTTP, SSH, SMTP, DNS 등 응용 프로그램이 사용되는 프로토콜 계층이며 웹 서비스, 이메일 등 서비스를 실질적으로 사람들에게 제공하는 층입니다.

전송 계층

전송 계층은 송신자와 수신자를 연결하는 통신 서비스를 제공하며 연결 지향 데이터 스트림 지원, 신뢰성, 흐름 제어를 제공할 수 있으며 애플리케이션과 인터넷 계층 사이의 데이터가 전달될 때 중계 역할을 합니다. 대표적으로 TCP와 UDP가 있습니다.
TCP
패킷 사이의 순서를 보장하고 연결지향 프로토콜을 사용해서 연결을 하여 신뢰성을 구축해서 수신 여부를 확인하며
가상회선 패킷 교환 방식을 사용합니다.가상회선 패킷 교환방식
가상회선 패킷 교환 방식은 각 패킷에는 가상회선 식별자가 포함되며 모든 패킷을 전송하면 가상회선이 해제되고 패킷들은 전송된순서대로도착하는 방식을 말합니다.

UDP
순서를 보장하지 않고 수신 여부를 확인하지 않으며 단순히 데이터만 주는
데이터그램 패킷 교환 방식을 사용합니다.데이터그램 패킷 교환방식
패킷이 독립적으로 이동하며 최적의 경로를 선택하여 가는데, 하나의 메시지에서 분할된 여러 패킷은 서로 다른 경로로 전송될 수 있으며 도착한 순서가 다를 수 있는 방식을 뜻합니다.
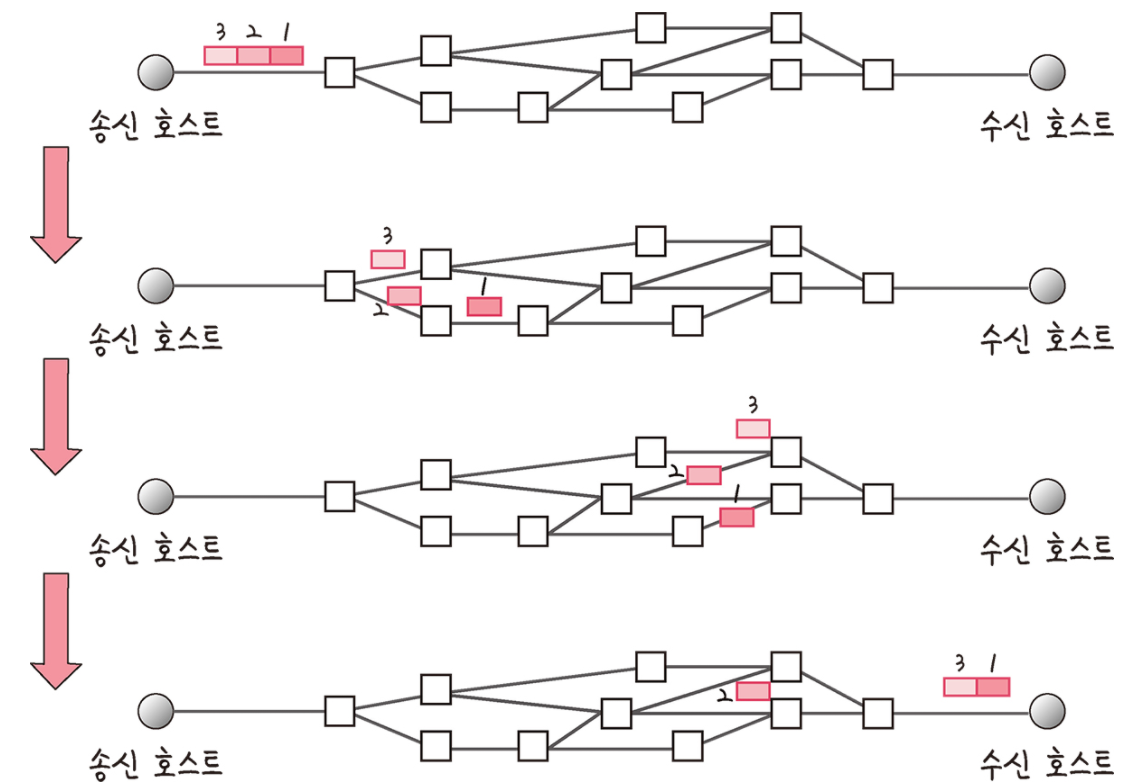
TCP 연결 성립 과정
TCP는 신뢰성을 확보할 때 3-웨이 핸드셰이크(3-way handshake)라는 작업을 진행합니다.


이렇게 3-웨이 핸드셰이크 과정 이후 신뢰성이 구축되고 데이터 전송을 시작합니다. 참고로 TCP는 이 과정이 있기 때문에 신뢰성이 있는 계층이라고 하며 UDP는 이 과정이 없기 때문에 신뢰성이 없는 계층이라고 합니다.
TCP 연결 해제 과정
TCP가 연결을 해제할 때는 4-웨이 핸드 셰이크 과정이 발생합니다.
- 1번 : 먼저 클라이언트가 연뎔을 닫으려고 할 때 FIN으로 설정된 세그먼트를 보냅니다. 그리고 클라이언트는 FIN_WAIT_1 상태로 들어가고 서버의 응답을 기다립니다.
- 2번 : 서버는 클라이언트로 ACK라는 승인 세그먼트를 보냅니다. 그리고 CLOSE_WAIT 상태에 들어갑니다. 클라이언트가 세그먼트를 받으면 FIN_WAIT_2상태에 들어갑니다.
- 3번 : 서버는 ACK를 보내고 일정 시간 이후에 클라이언트에 FIN이라는 세그먼트를 보냅니다.
- 4번 : 클라이언트는 TIME_WAIT 상태가 되고 다시 서버로 ACK를 보내서 서버는 CLOSED 상태가 됩니다. 이후 클라이언트는 어느 정도 시간을 대기한 후 연결이 닫히고 클라이언트와 서버의 모든 자원의 연결이 해제됩니다.
이 과정 중 눈여겨 봐야할 것은 TIME_WAIT입니다. 그냥 연결을 닫으면 되지 왜 굳이 일정 시간 뒤에 닫을까요?
-
지연 패킷이 발생할 경우를 대비하기 위함입니다. 패킷이 뒤늦게 도달하고 이를 처리하지 못한다면 데이터 무결성 문제가 발생합니다. 예를 들어 전체 데이터가 100일 때 일부 데이터인 50만 들어오는 현상이 발생할 수 있습니다.
-
두 장치가 연결이 닫혔는지 확인하기 위해서입니다. 만약 LAST_ACK 상태에서 닫히게 되면 다시 새로운 연결을 하려고 할 때 장치는 줄곧 LAST_ACK로 되어 있기 때문에 접속 오류가 나타나게 될 것입니다.
이러한 이유로 TIME_WAIT라는 잠시 기다릴 시간이 필요합니다.
TIME_WAIT
소켓이 바로 소멸되지 않고 일정 시간 유지되는 상태를 말하며 지연 패킷 등의 문제점을 해결하는데 사용합니다. CentOS6, 우분투에는 60초로 설정되어 있고 윈도우는 4분으로 설정되어 있습니다.
데이터 무결성
데이터의 정확성과 일관성을 유지하고 보증하는 것
인터넷 계층
인터넷 계층은 장치로부터 받은 네트워크 패킷을 IP주소로 지정된 목적지로 전송하기 위해 사용되는 계층입니다. IP, ARP, ICMP 등이 있으며 패킷을 수신해야 할 상대의 주소를 지정하여 데이터를 전달합니다. 상대방이 제대로 받았는지에 대해 보장하지 않는 비연결형적인 특징을 가지고 있습니다.
링크 계층
링크 계층은 전선, 광섬유, 무선 등으로 실질적으로 데이터를 전달하며 장치 간에 신호를 주고 받는 규칙을 정하는 계층입니다. 네트워크 접근 게층이라고도 합니다. 이를 물리 계층과 데이터 링크 계층으로 나누기도 하는데 물리 계층은 무선 LAN과 유선 LAN을 통해 0과 1로 이루어진 데이터를 보내는 계층을 말하며, 데이터 링크 계층은 이더넷 프레임을 통해 에러확인, 흐름 제어, 접근 제어를 담당하는 계층을 말합니다.
유선 LAN(IEEE802.3)
유선 LAN을 이루는 이더넷은 IEEE802.3이라는 프로토콜을 따르며 전이중화 통신을 씁니다.
전이중화통신
전이중화 통신은 양쪽 장치가 동시에 송수신할 수 있는 방식을 말합니다. 이는 송신로와 수신로로 나눠서 데이터를 주고받으며 현대의 고속 이더넷은 이 방식을 기반으로 통신하고 있습니다.

CSMA/CD
이 방식은 데이터를 보낸 이후 충돌이 발생한다면 일정 시간 이후 재전송하는 방식을 말합니다. 이는 수신로를 각각 둔 것이 아니고 한 경로를 데이토를 보내기 때문에 데이터를 보낼 때 충돌에 대비해야 했기 때문입니다.
무선 LAN
무선 LAN 장치는 수신과 송신에 같은 채널을 사용하기 때문에 반이중화 통신을 사용합니다.
반이중화 통신
반이중화통신은 양쪽 장치는 서로 통신할 수 있지만 동시에는 통신할 수 없으며 한 번에 한 방향만 통신할 수 있는 방식

CSMA/CA
CSMA/CA는 반이중화 통신 중 하나로 장치에서 데이터를 보내기 전에 캐리어 감지 등으로 사전에 가능한 충돌을 방지하는 방식을 사용하며 과정은 다음과 같이 이루어집니다.
- 데이터를 송신하기 전에 무선 매체를 살핍니다.
- 캐리어 감지 : 회선이 비어있는지를 확인
- IFS(Inter FrameSpace) : 랜덤 값을 기반으로 정해진 시간만큼 기다리며, 만약 무선 매체가 사용 중이면 점차 그 간격을 늘려가며 기다립니다.
- 이후에 데이터를 송신
참고로 이와 반대되는 전이중화 통신은 양방향 통신이 가능하므로 충돌 가능성이 없기 때문에 충돌을 감지하거나 방지하는 매커니즘이 필요없습니다.
무선 LAN을 이루는 주파수
무선 LAN(WLAN, Wireless Local Network)은 무선 신호 전달 방식을 이용하여 2대 이상의 장치를 연결하는 기술입니다.
비유도 매체인 공기에 주파수를 쏘아 무선 통신망을 구축하는데 주파수 대역은 2.4GHz 대역 또는 5GHz 대역 중 하나를 써서 구축합니다. 2.4GHz는 장애물에 강한 특성을 가지고 있지만 전자레인지, 무선 등 전파 간섭이 일어나는 경우가 많고 5GHz 대역은 사용할 수 있는 채널 수도 많고 동시에 사용할 수 있기 때문에 상대적으로 깨끗한 전파 환경을 구축할 수 있습니다. 그렇기 때문에 보통은 5GHz 대역을 사용하는게 좋습니다.
이더넷 프레임
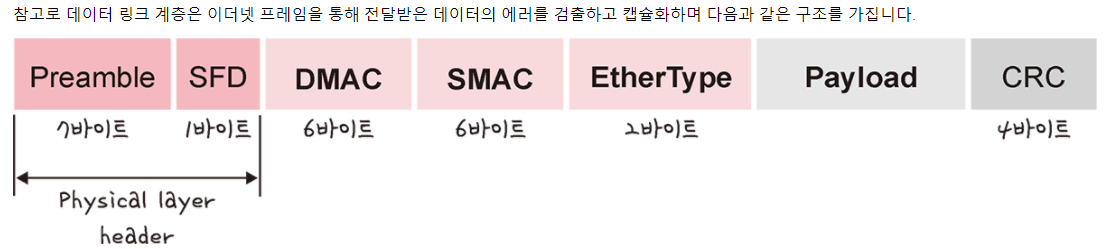


계층 간 데이터 송수신 과정

애플리케이션 계층에서 전송 계층으로 필자가 보내는 요청(request) 값들이 캡슐화 과정을 거쳐 전달되고 다시 링크 계층을 통해 해당 서버와 통신을 하고 해당 서버의 링크 계층으로부터 애플리케이션까지 비캡슐화 과정을 거쳐 데이터가 전송됩니다.
캡슐화 과정
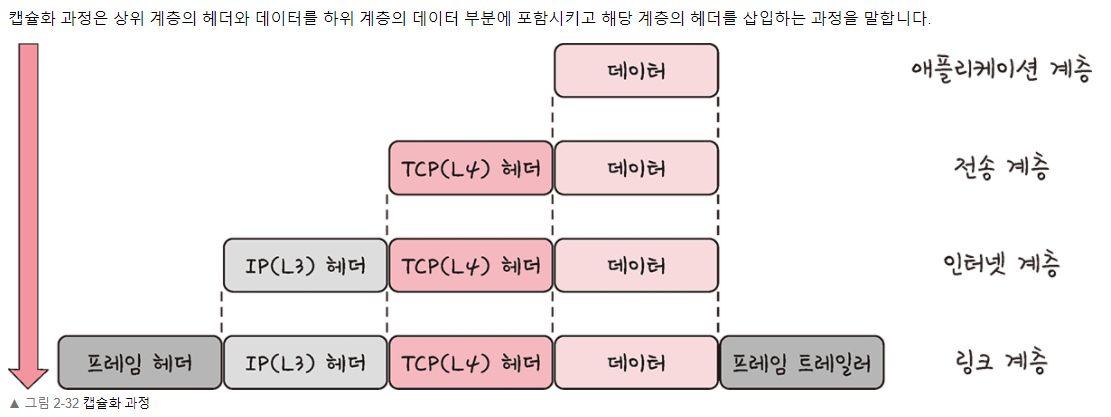

비캡슐화 과정

PDU

DNS란?
IP주소를 문자로 표현한 주소로 바꾸는 시스템 혹은 서버
포트와 소켓

CIDR(사이더)
사이더(Classless inter-Domain Routing, CIDR)는 직역 그대로 클래스없는 도메인간 라우팅 기법 이다. 기존 IP 주소 할당 방식이었던 클래스를 대체하며 IP주소의 네트워크 영역, 호스트영역을 유연하게 나누어준다. 서브넷 마스크는 /를 사용해서 명시한다.
서브넷

MTU(Maximum Transmission Unit)
패킷이나 프레임의 최대 크기 로 데이터의 크기가 크다면 단편화해야 한다.
캐스트
- 유니 캐스트 : 특정 대상과 1:1 통신
- 멀티 캐스트 : 특정 다수와 1:N 통신
- 브로드 캐스트 : 네트워크에 있는 모든 대상과 통신
네트워크 기기
네트워크는 여러 개의 네트워크 기기를 기반으로 구축됩니다.



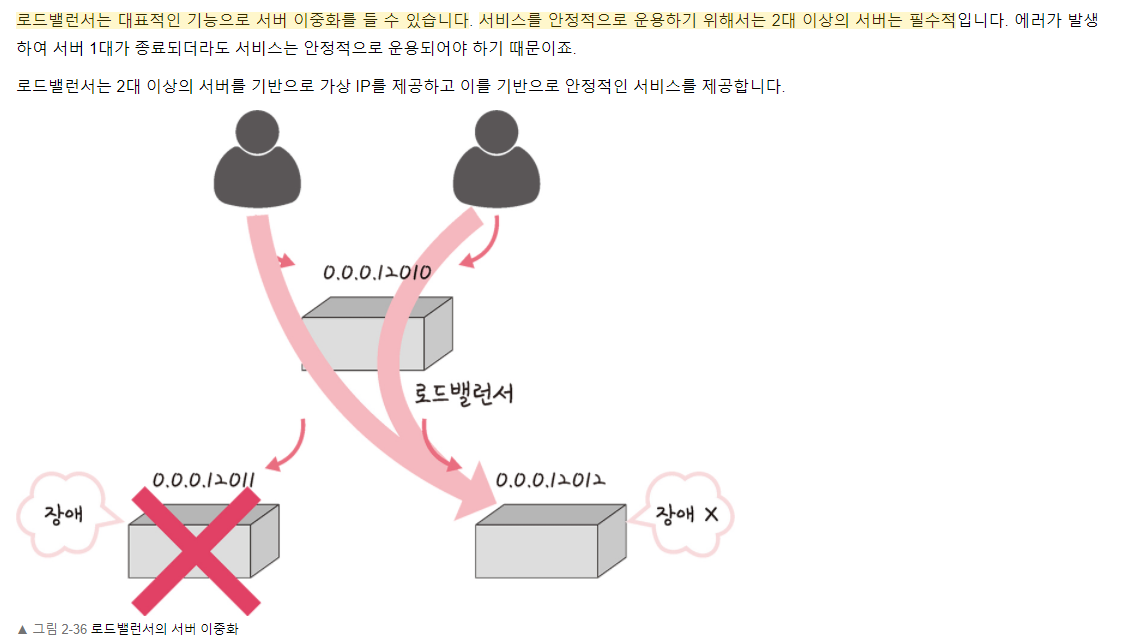
L4 스위치와 L7 스위치 차이

헬스 체크

로드밸런서를 이용한 서버 이중화
인터넷 계층을 처리하는 기기
인터넷 계층을 처리하는 기기로는 라우터, L3 스위치가 있습니다.


데이터 링크 계층을 처리하는 기기
데이터 링크 계층을 처리하는 기기로는 L2 스위치가 있습니다.

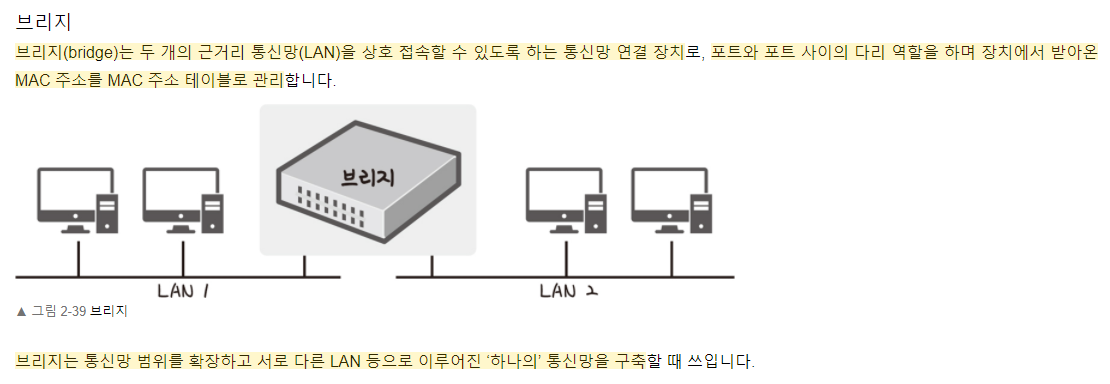
물리 계층을 처리하는 기기

각 LAN 카드에는 주민등록번호처럼 각각을 구분하기 위한 고유의 식별번호인 MAC 주소가 있습니다.

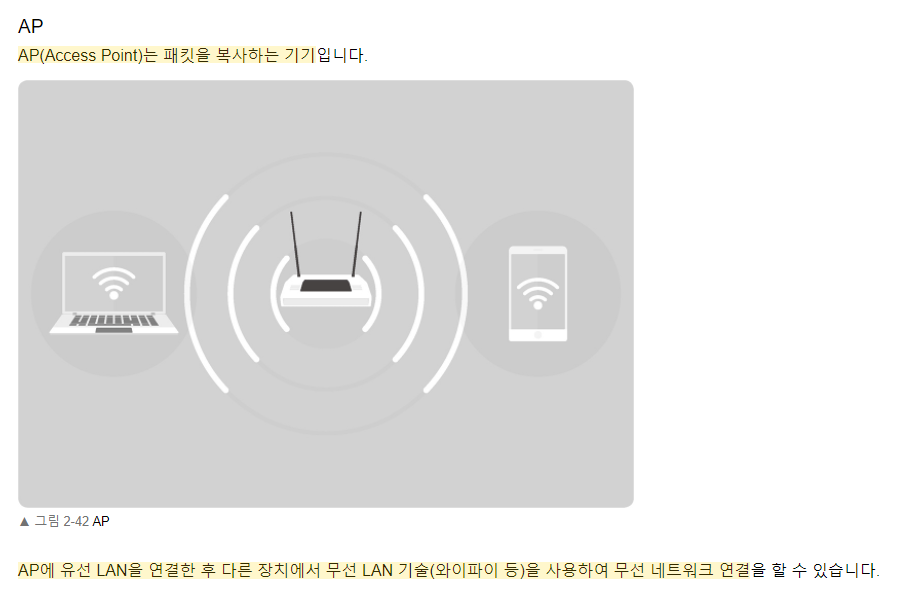
IP 주소
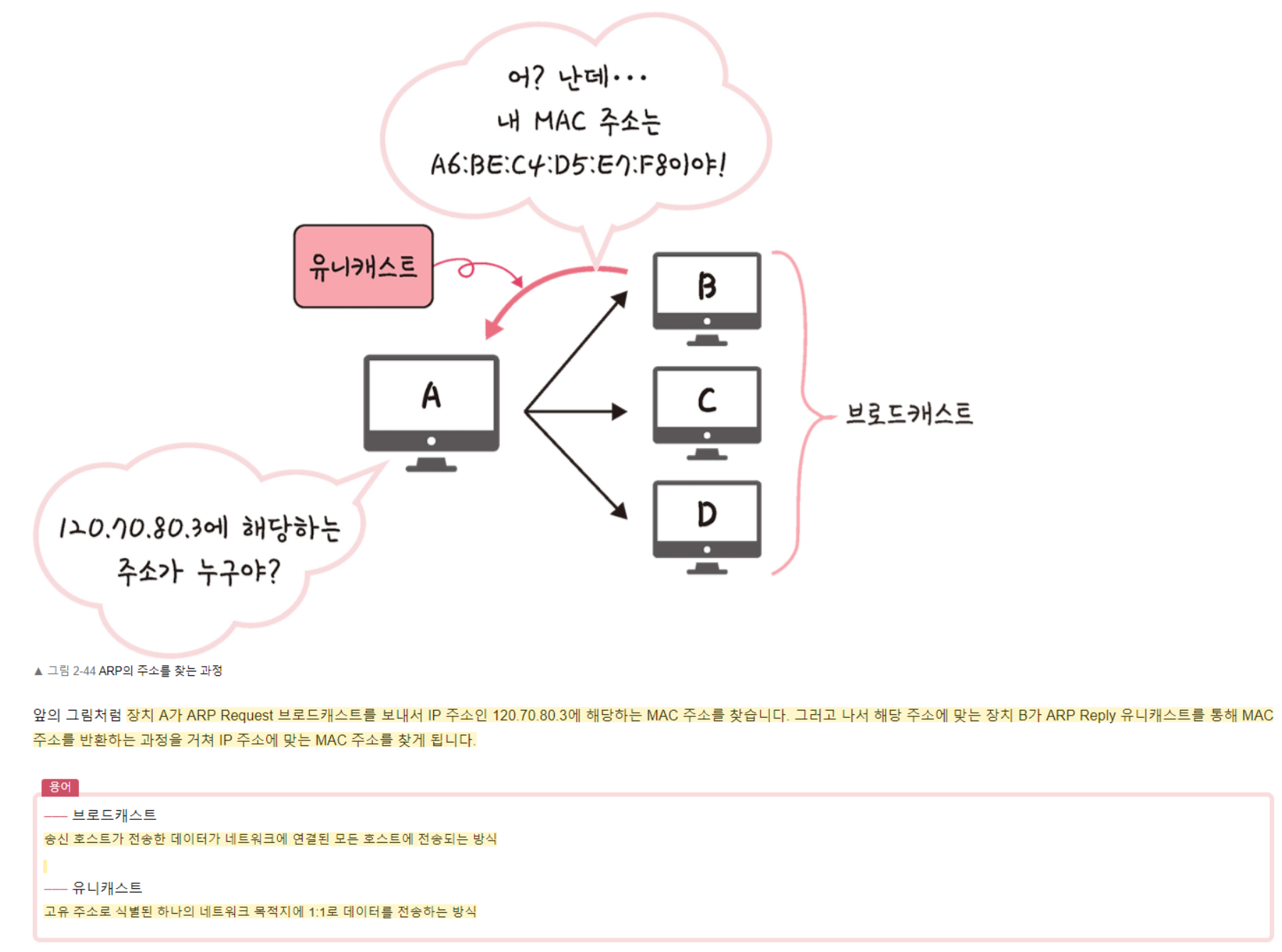
ARP

홉바이홉 통신


라우팅 테이블

게이트 웨이

IP 주소 체계
클래스 기반 할당 방식




DHCP

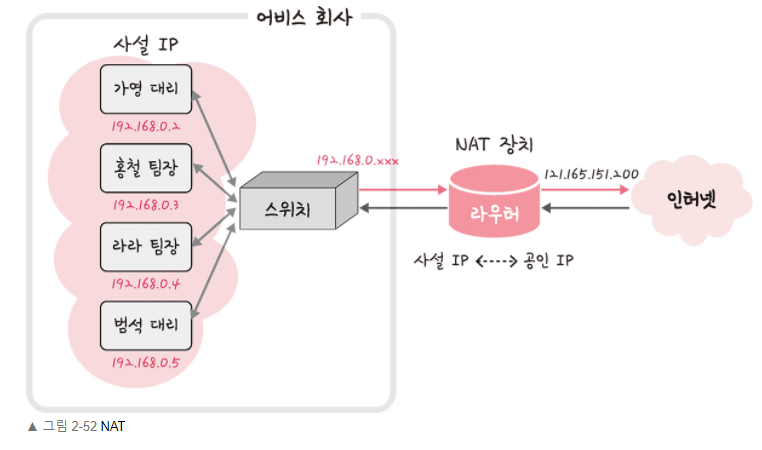
NAT



IP주소를 이용한 위치 정보

HTTP
- HTTP란 HyperText Transfer Protocol의 약자
- 텍스트 기반의 통신 규약으로 인터넷에서 데이터를 주고받을 수 있는 프로토콜


keep-alive 헤더
HTTP는 매번 연결을 끊고 새로 생성한다.
특정 시간까지는 access가 없더라도 기다리고 연결상태를 유지하는 헤더이다.
HTTP 1.1부터는 defualt로 keep-alive를 지원한다.
HTTP/1.0
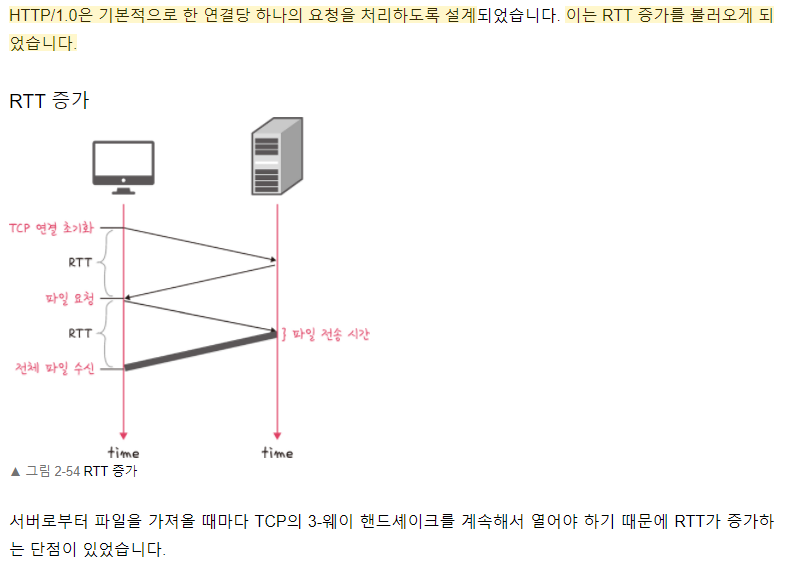

RTT의 증가를 해결하기 위한 방법




이미지 Base64 인코딩
이미지 파일을 64진법으로 이루어진 문자열로 인코딩하는 방법이 있습니다. 이 방법을 사용하면 서버와의 연결을 열고 이미지에 대해 서버에 HTTP 요청을 할 필요가 없다는 장점이 있습니다. 하지만 Base64 문자열로 변환할 경우 37% 정도 크기가 더 커지는 단점이 있습니다.

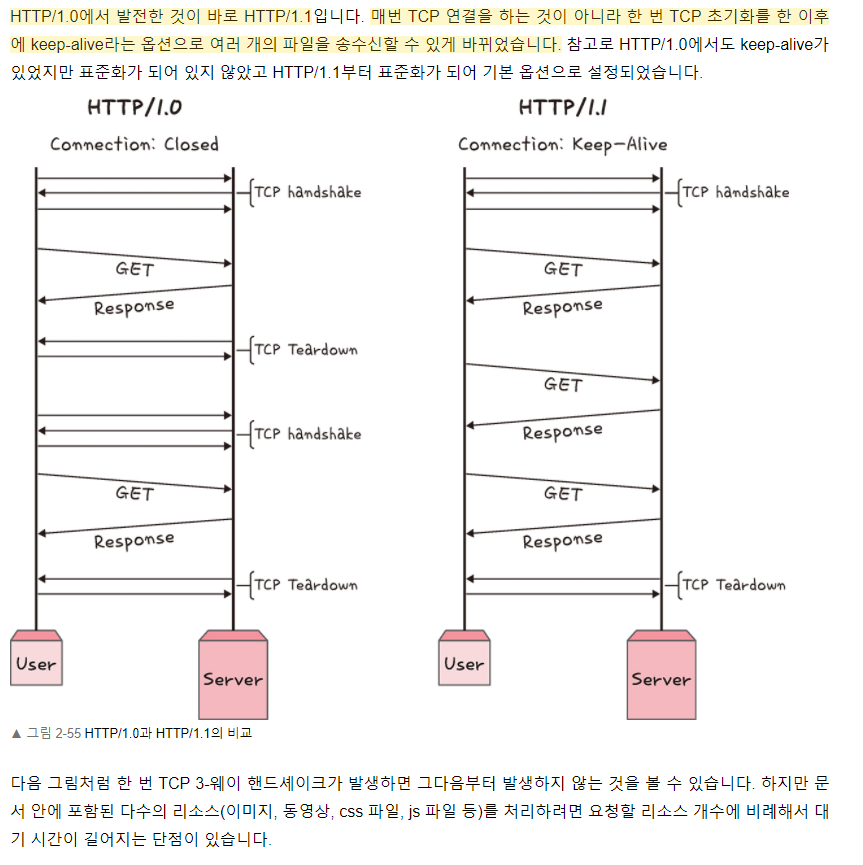
HTTP/1.1
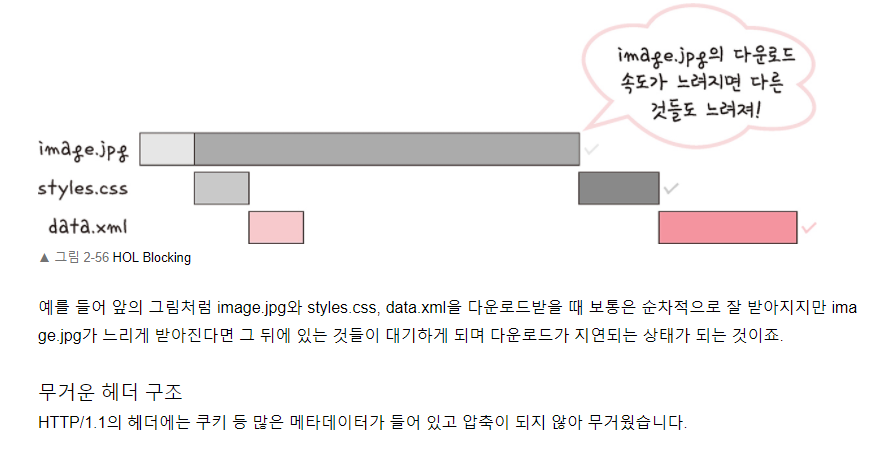
HOL Blocking

HTTP 1.0 vs HTTP 1.1

HTTP/2
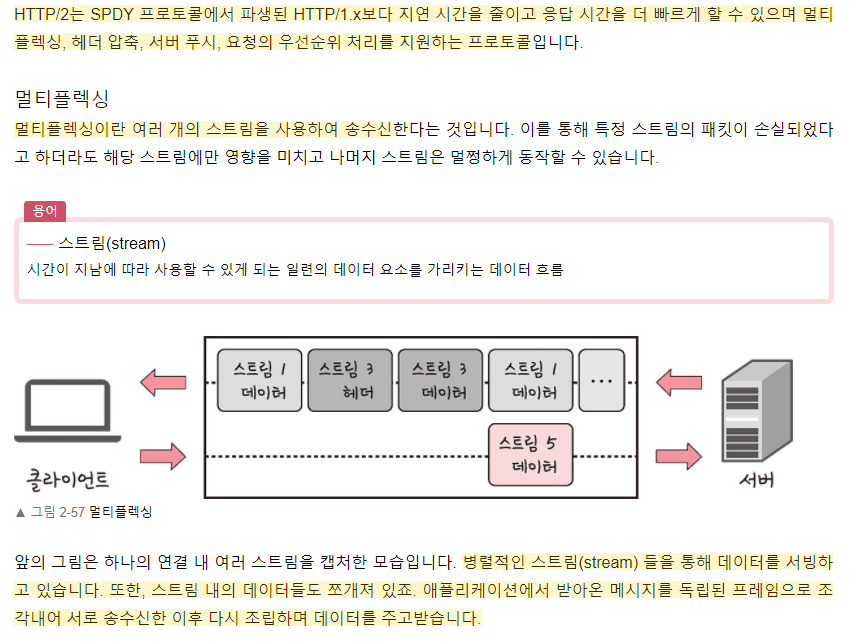
HTTP/2.0
-
하나의 커넥션으로 동시에 여러 개의 메세지를 주고 받을 수 있으며, response는 순서에 상관없이 stream으로 주고받는다.
-
서버는 클라이언트의 요청에 대해 요청하지 않은 리소스를 마음대로 보낼 수 있다.
-
Header의 내용과 중복되는 필드를 재전송하지 않아 데이터를 절약한다.
헤더 압축

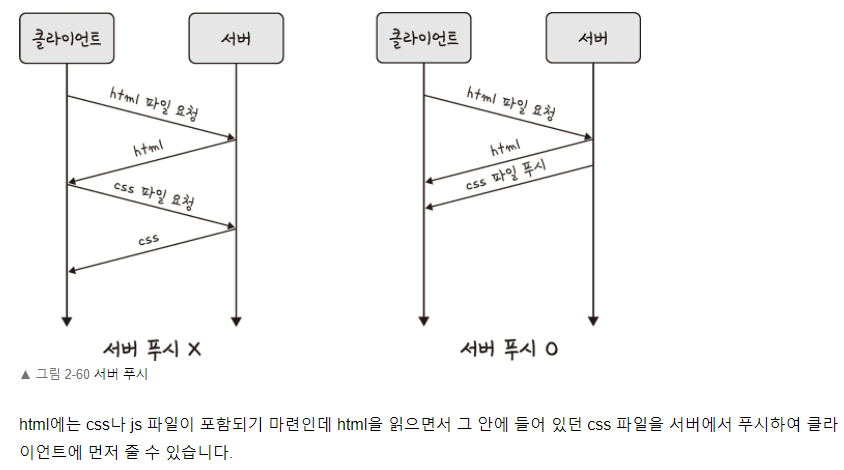
서버 푸시

HTTPS

SSL/TLS




HTTP 메서드 종류
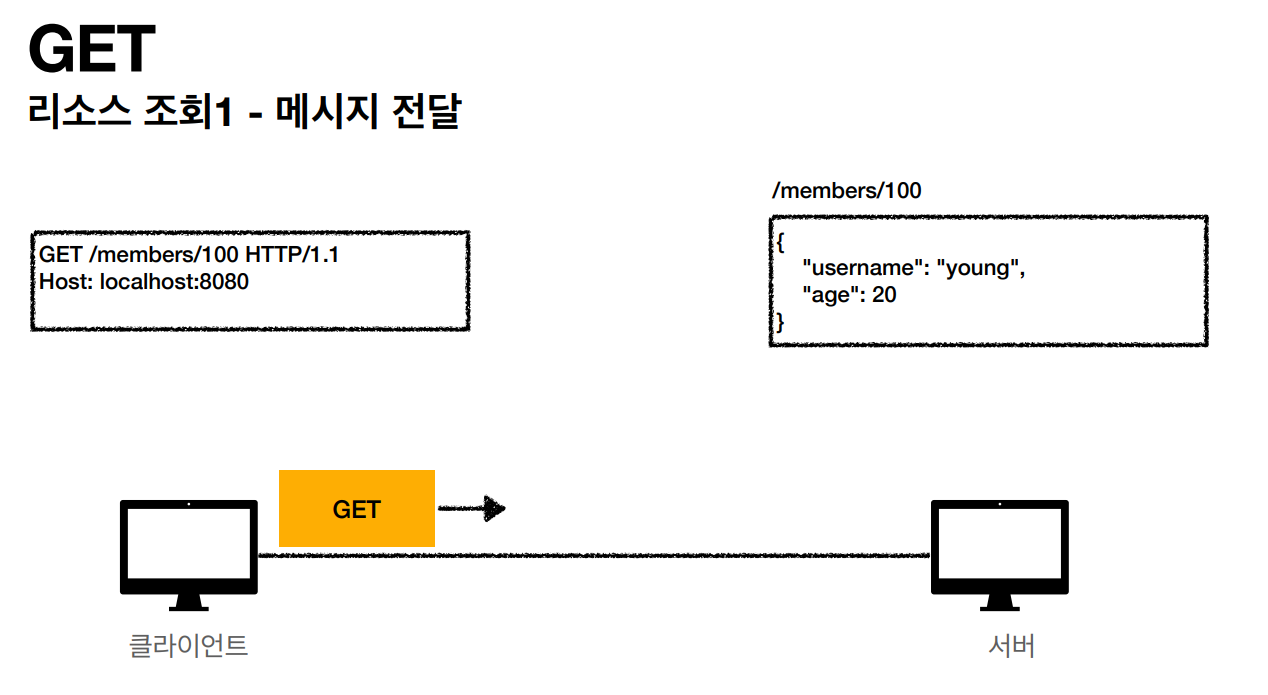
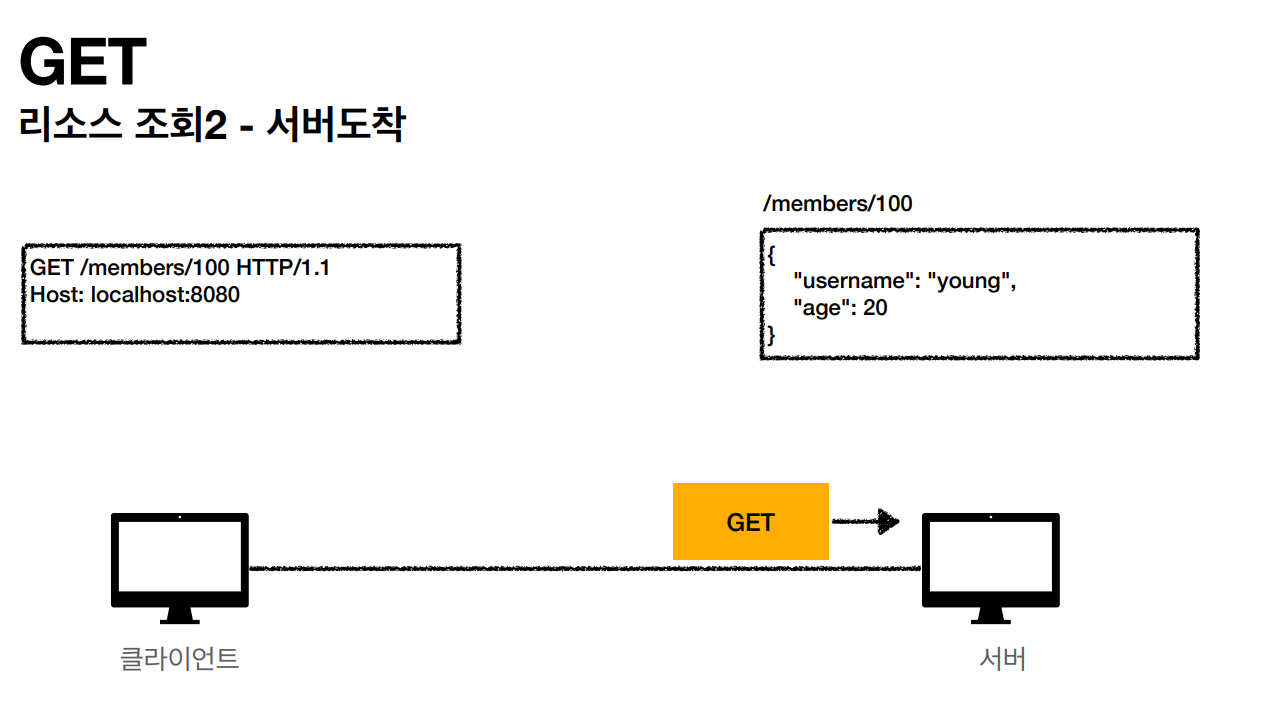
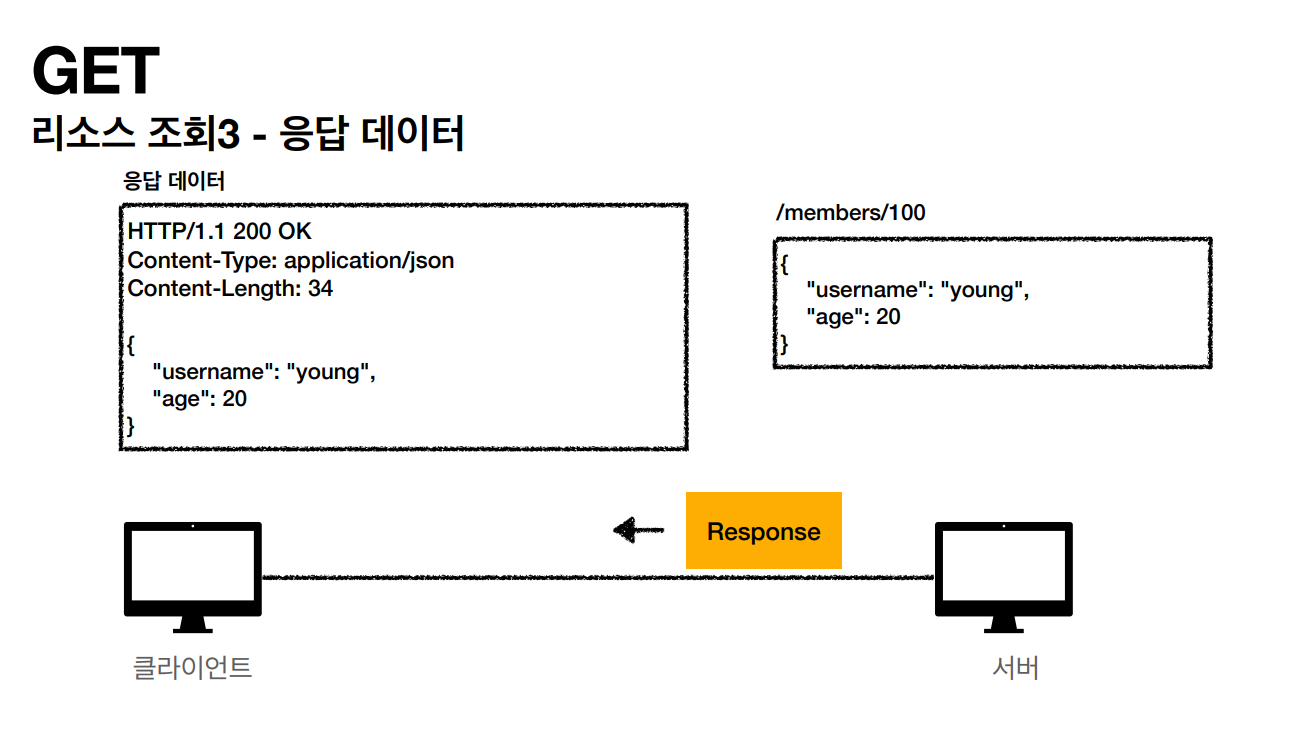
- GET: 리소스 조회
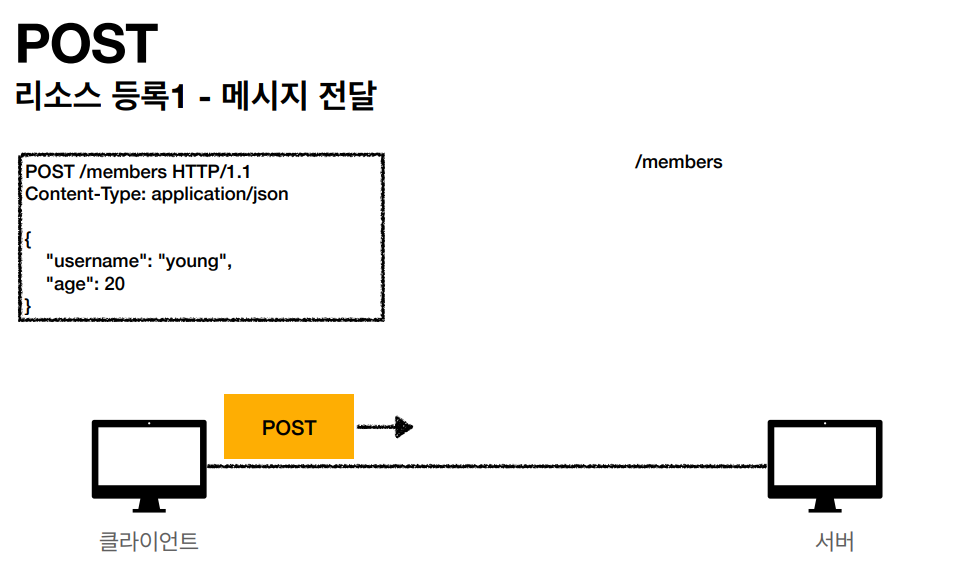
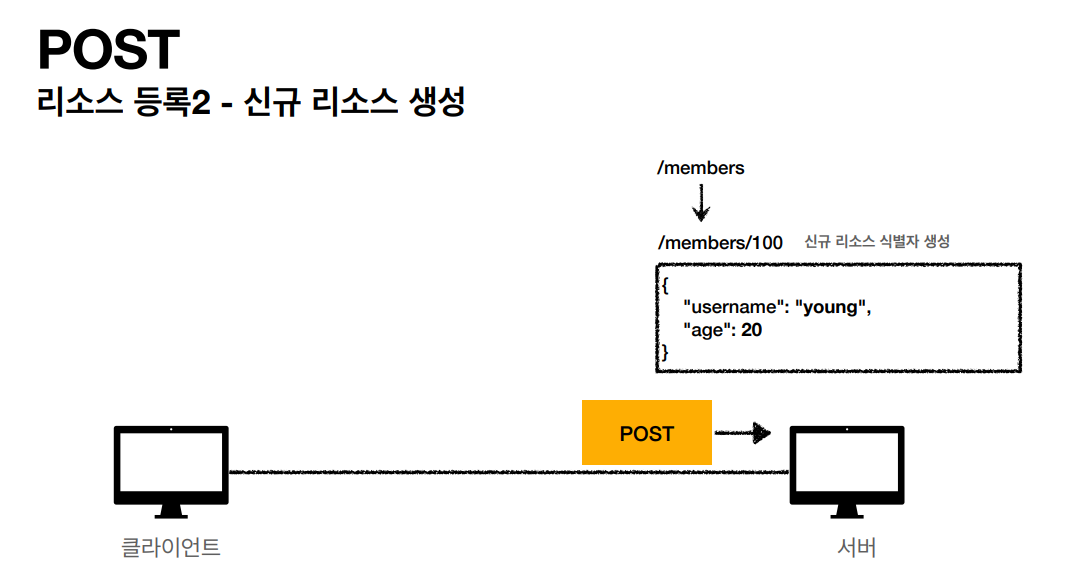
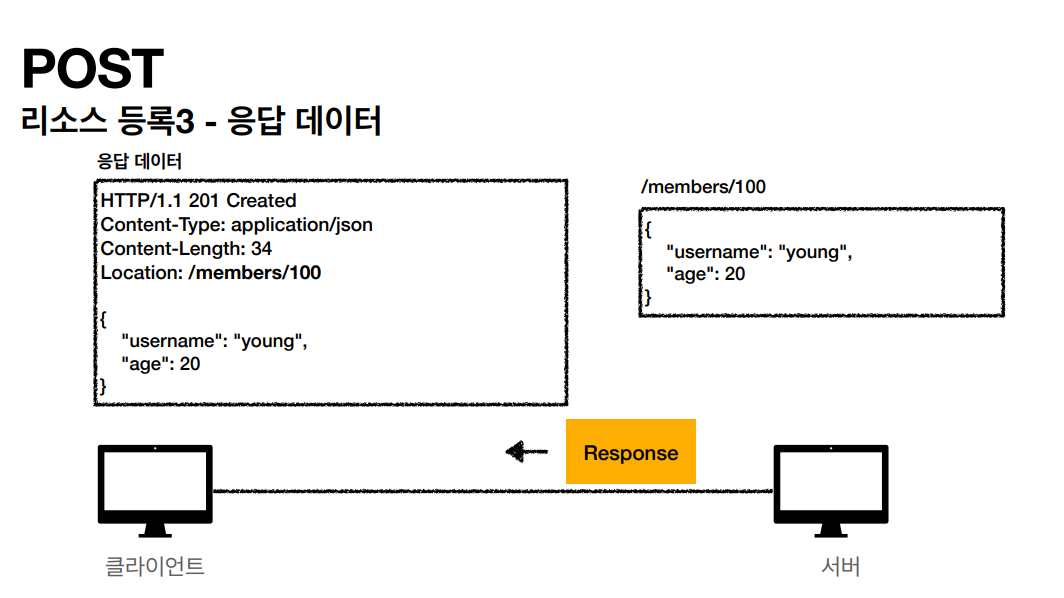
- POST: 요청 데이터 처리, 주로 등록에 사용
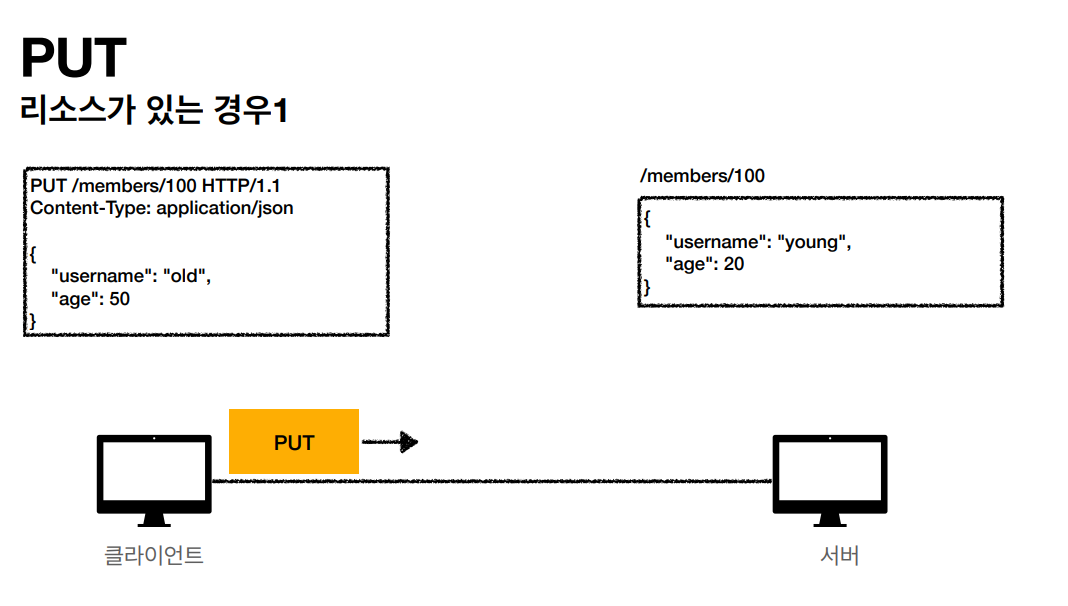
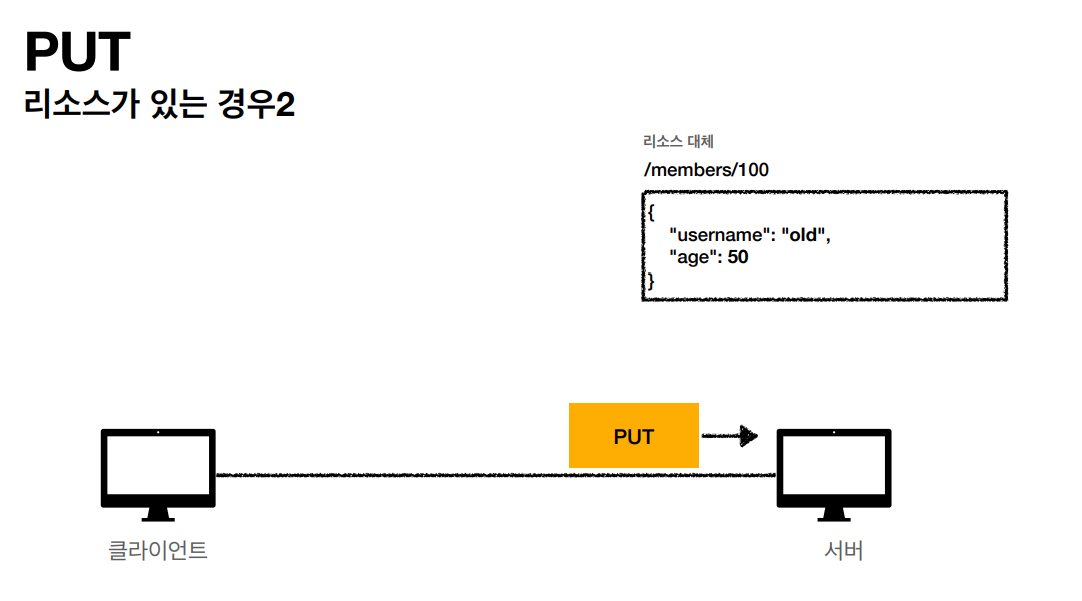
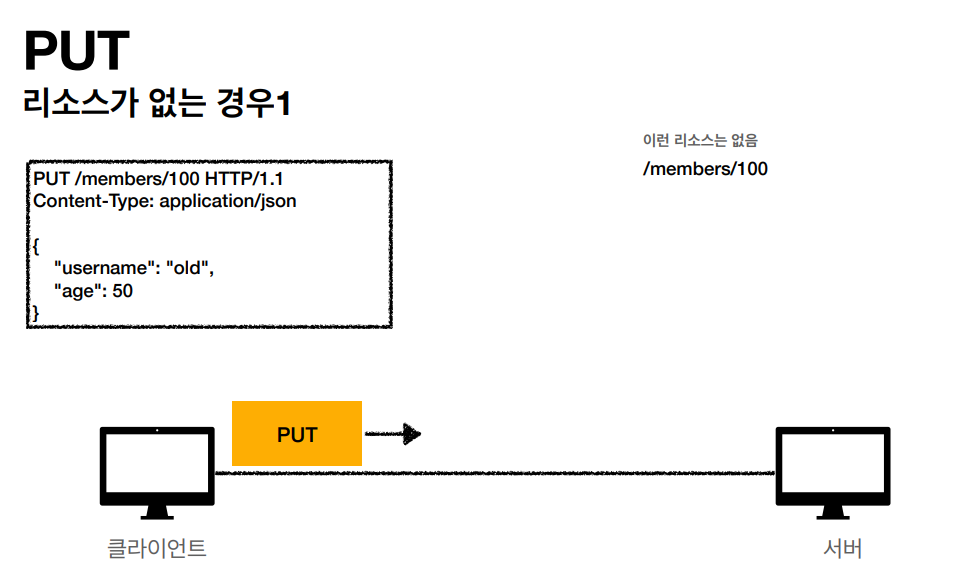
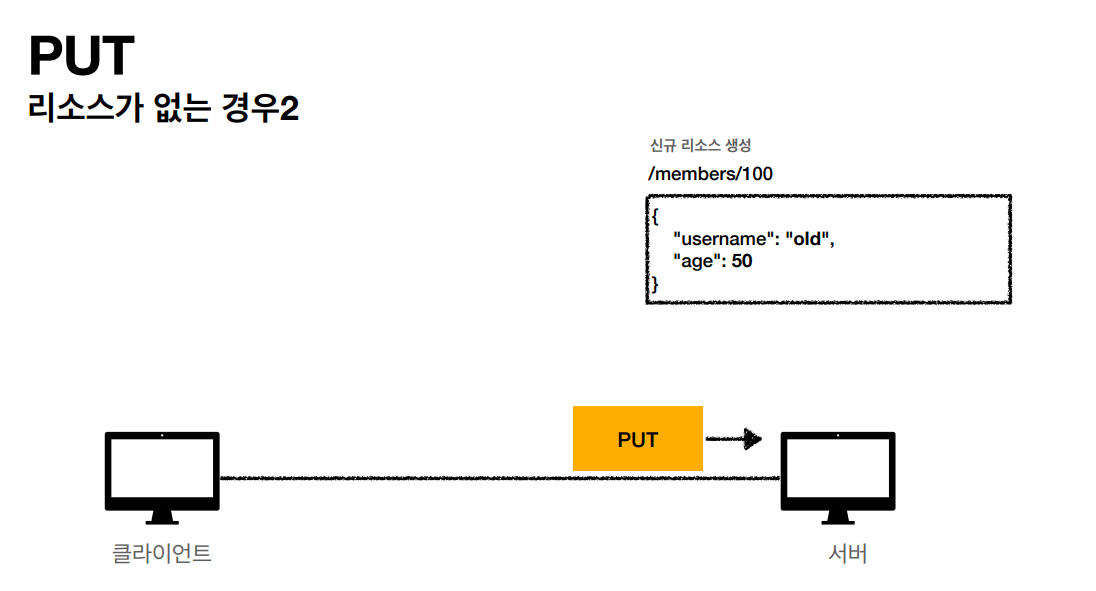
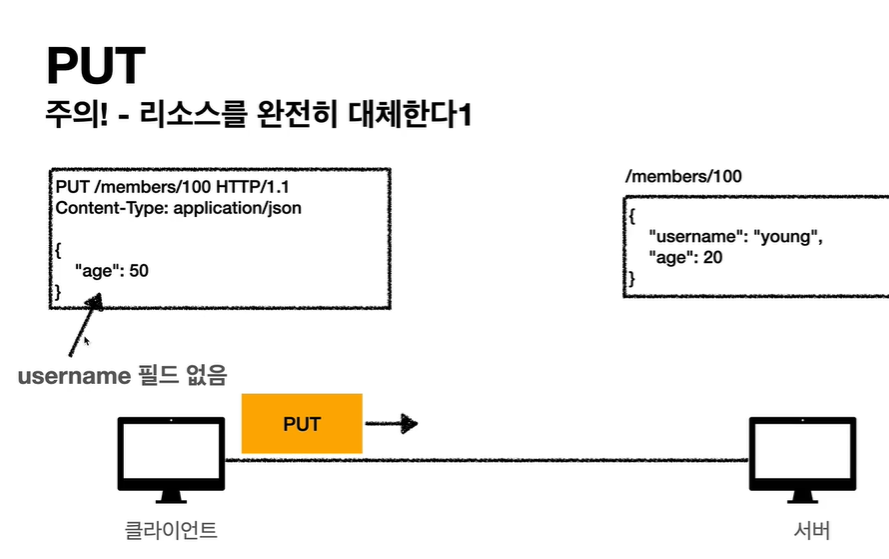
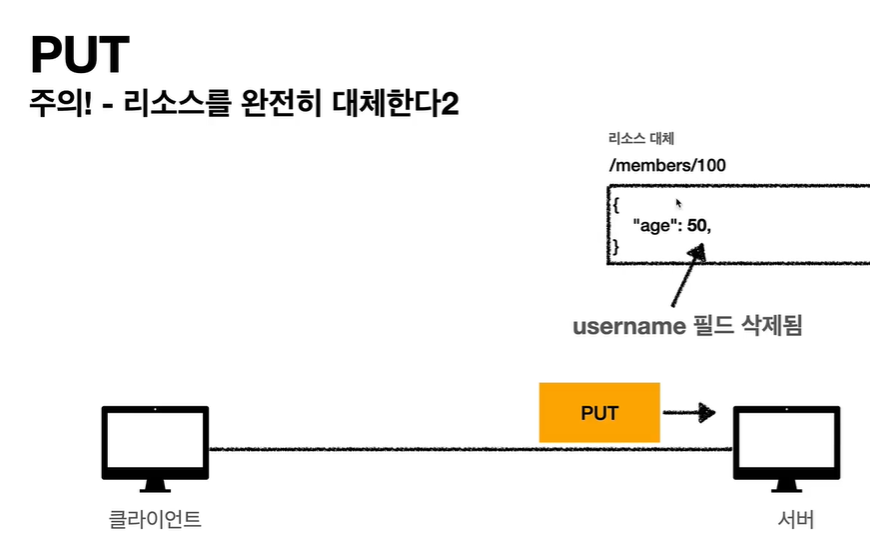
- PUT: 리소스를 대체, 해당 리소스가 없으면 생성
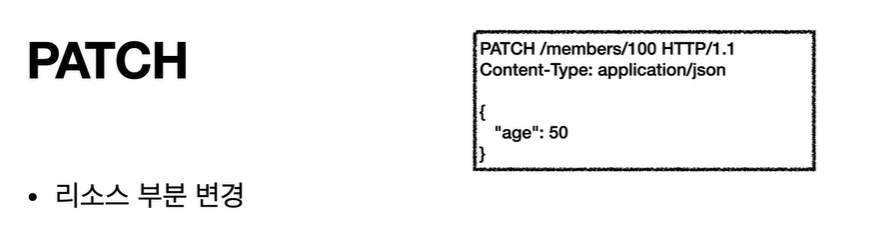
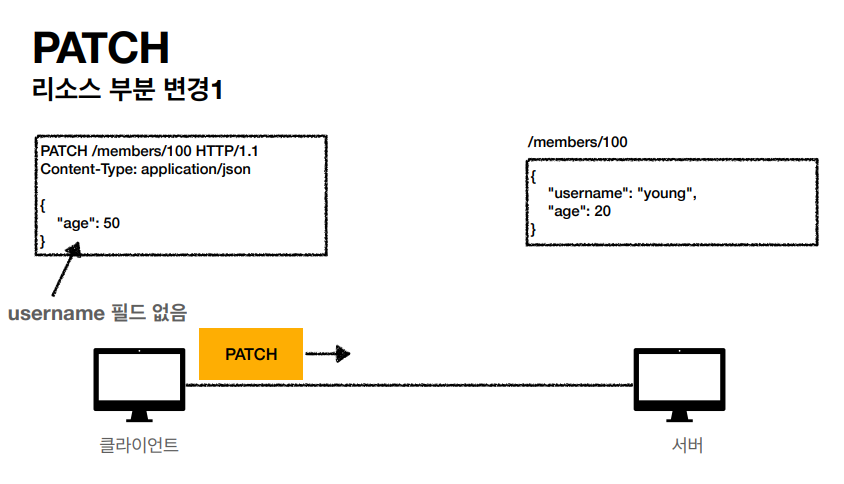
- PATCH: 리소스 부분 변경
- DELETE: 리소스 삭제







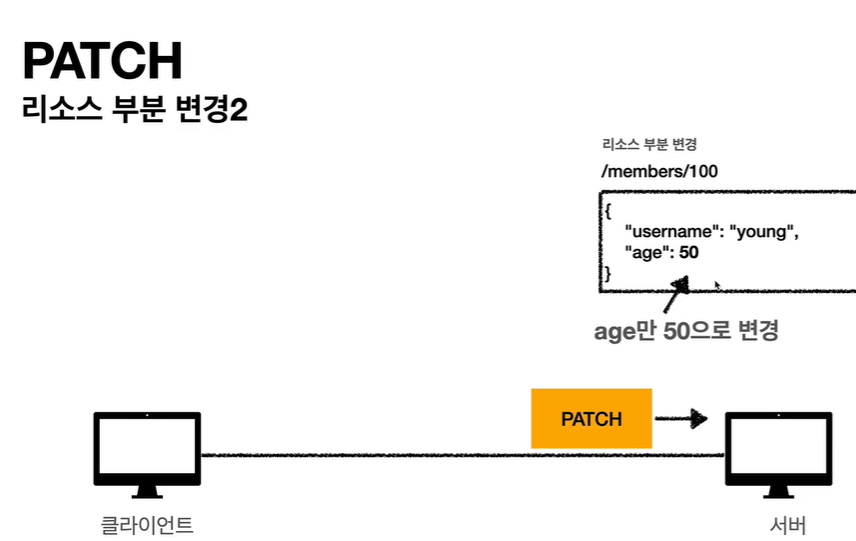

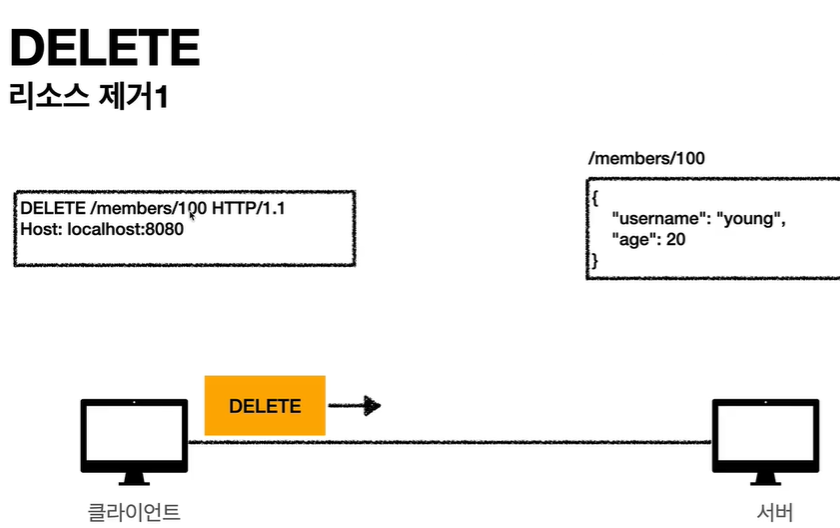
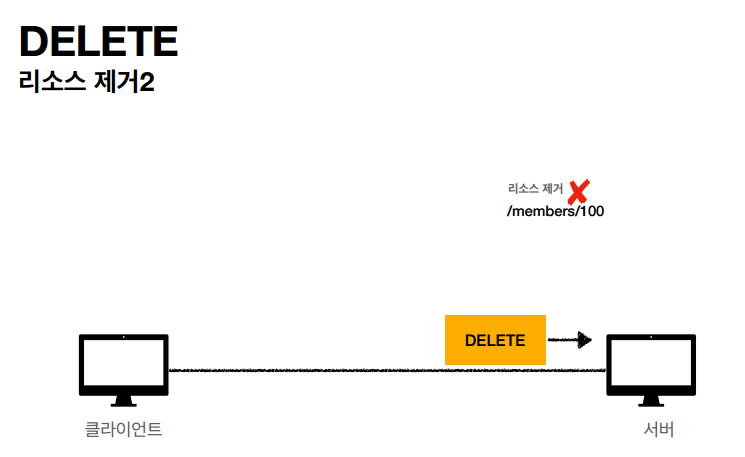
HTTP 메서드 속성
- 안전(Safe Methods)
- 멱등(Idempotent Methods)
- 캐시가능(Cacheable Methods)
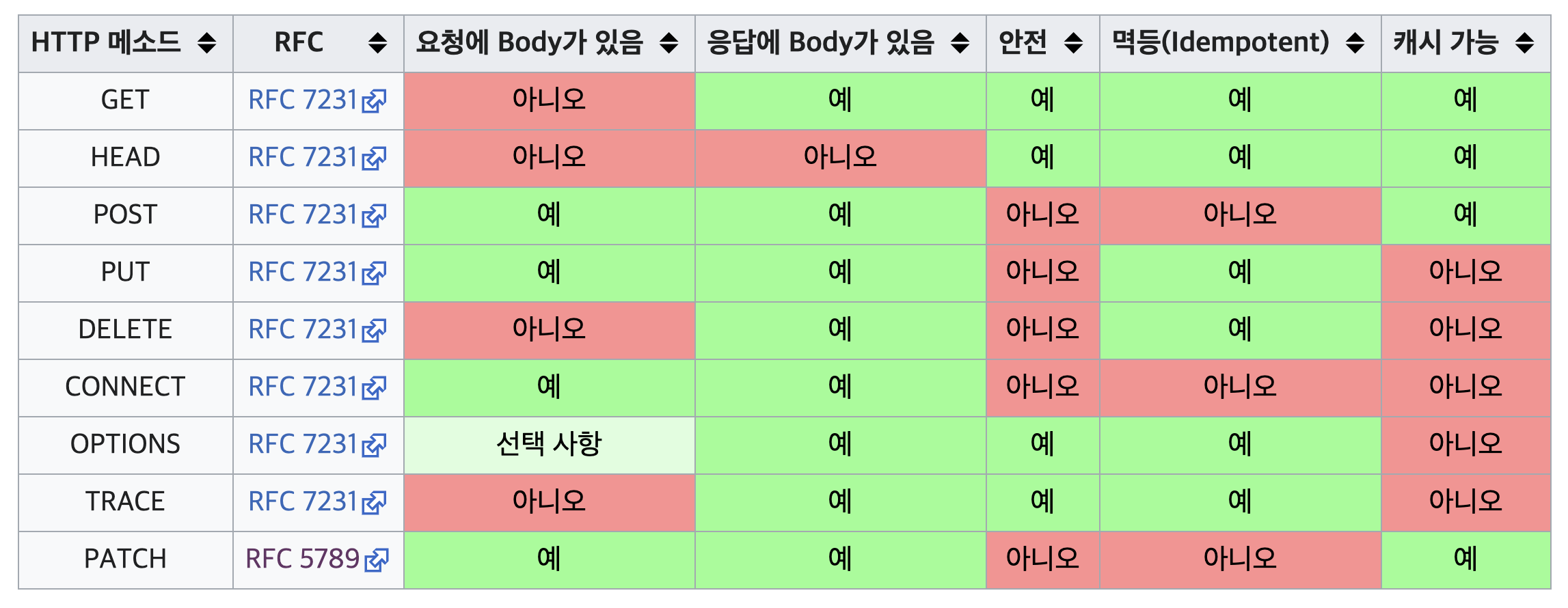
안전(Safe)
- 호출해도 리소스를 변경하지 않는다.
- Q : 계속 호출해서 로그 같은게 쌓여서 장애가 발생하면?
A : 안전은 해당 리소스만 고려한다. 그런 부분은 고려하지 않는다.
멱등(Idempotent)
- f(f(x)) = f(x)
- 한 번 호출하든 두번 호출하든 100번 호출하든 결과가 똑같다.
- 멱등 메서드
- GET : 한 번 조회하든, 두 번 조회하든 같은 결과가 조회
- PUT : 결과를 대체한다. 따라서 같은 요청을 여러번 해도 최종 결과는 같다.
- DELETE : 결과를 삭제한다. 같은 요청을 여러번 해도 삭제된 결과는 같다.
- POST : 멱등이 아니다! 두 번 호출하면 같은 결과가 중복해서 발생할 수 있다.


캐시가능(Cacheable)
- 응답 결과 리소스를 캐시해서 사용해도 되는가?
- GET, HEAD, POST, PATCH 캐시 가능
- 실제로는 GET, HEAD 정도만 캐시로 사용
POST, PATCH는 본문 내용까지 캐시 키로 고려해야 하는데 구현이 쉽지 않음
운영체제

운영체제의 역할과 구조



modebit


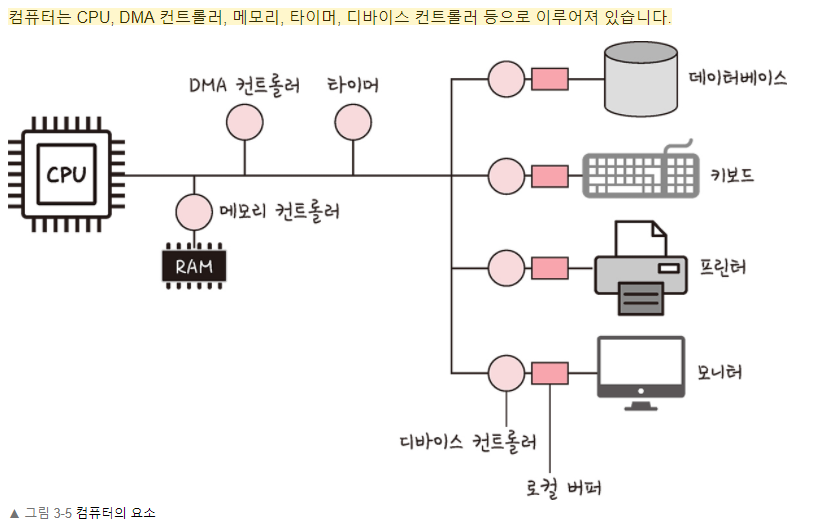
컴퓨터의 요소
CPU


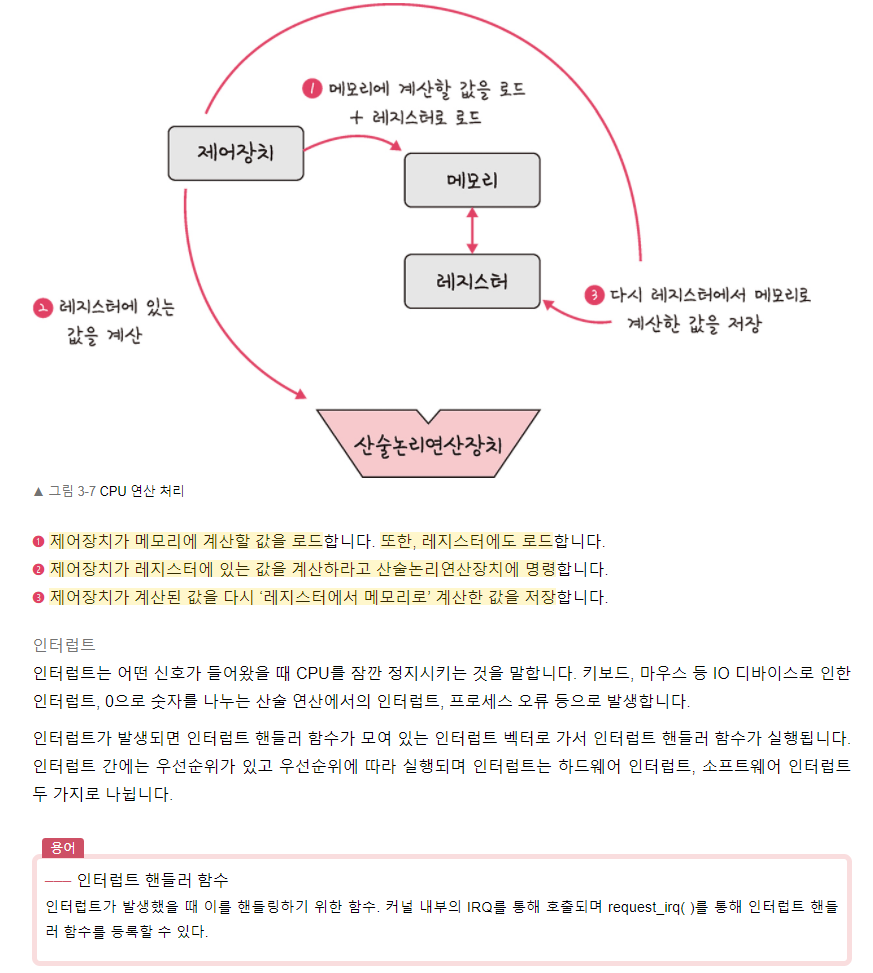
제어장치

레지스터

산술논리연산장치

CPU의 연산 처리
하드웨어 인터럽트

소프트웨어 인터럽트

DMA 컨트롤러

메모리

타이머

디바이스 컨트롤러

메모리
- 프로그램이 실행되기 위해서는 메모리에 저장되어야 함
- 메모리는 실행되는 프로그램의 명령어와 데이터를 저장
- 메모리에 저장된 값의 위치는 주소로 알 수 있다.
메모리 계층

캐시


시간 지역성

공간 지역성

캐시히트와 캐시미스


쿠키

로컬 스토리지

세션 스토리지

메모리 관리
가상 메모리



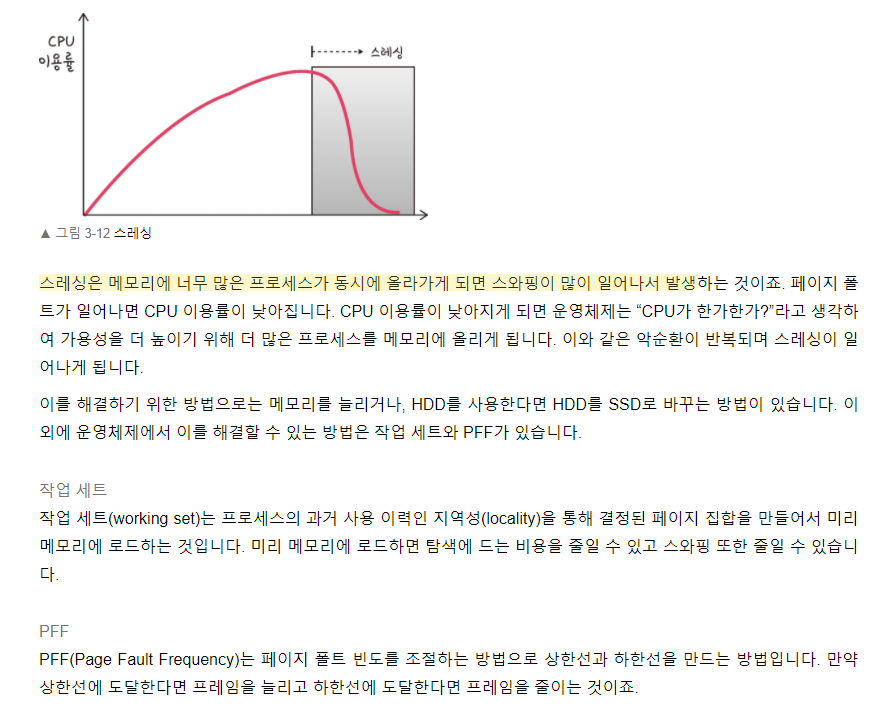
스레싱
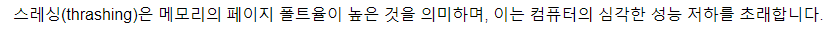
메모리 할당


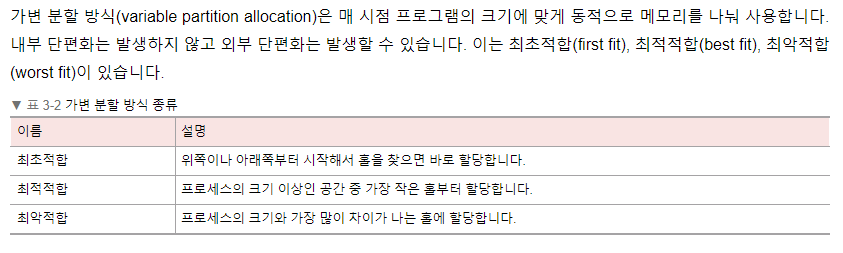
고정 분할 방식

가변 분할 방식

프로세스와 스레드
-
프로세스는 실행중인 프로그램을 의미하며 독자적인 주소공간을 보유하고 있고, CPU 스케줄링의 대상이 됩니다.
-
쓰레드는 프로세스 내의 작업의 흐름 단위입니다. 프로세스는 여러 쓰레드를 가질 수 있습니다.

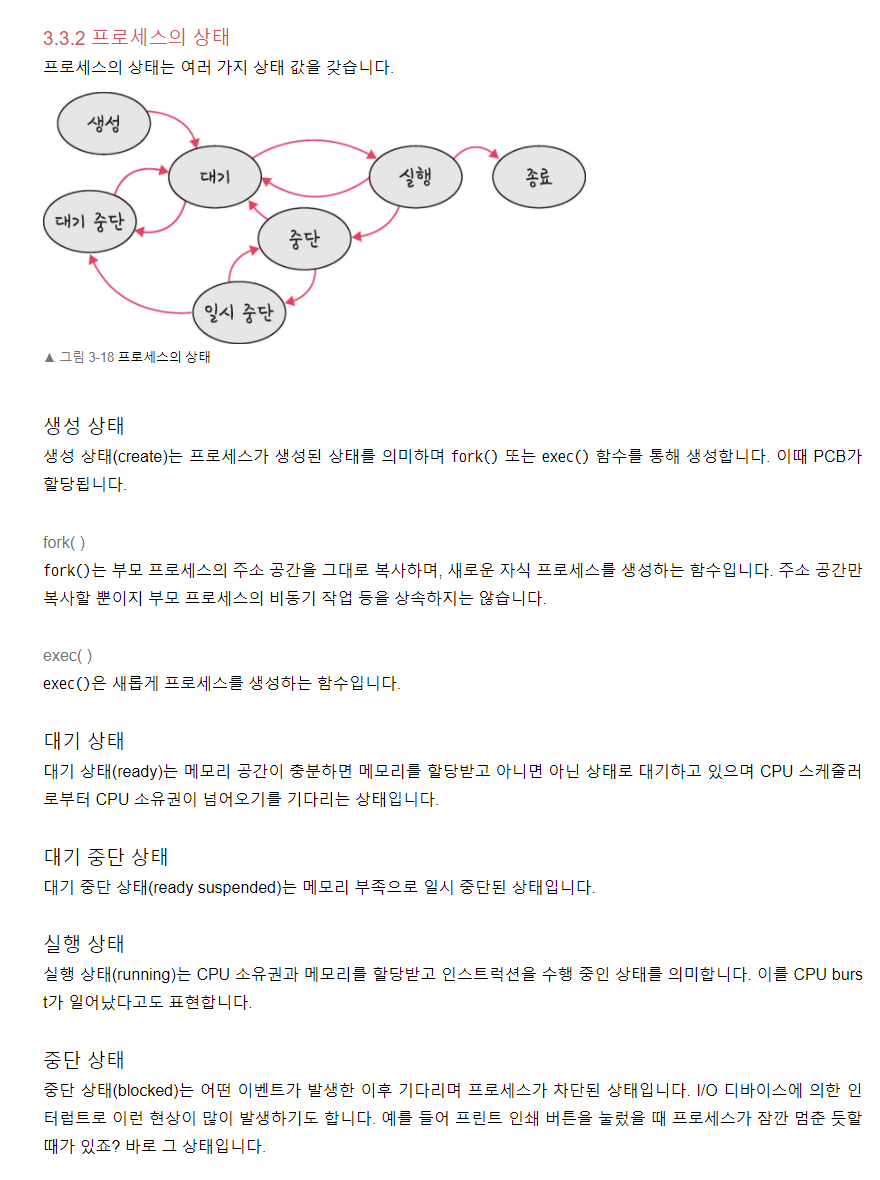
일시 중단 상태

종료 상태






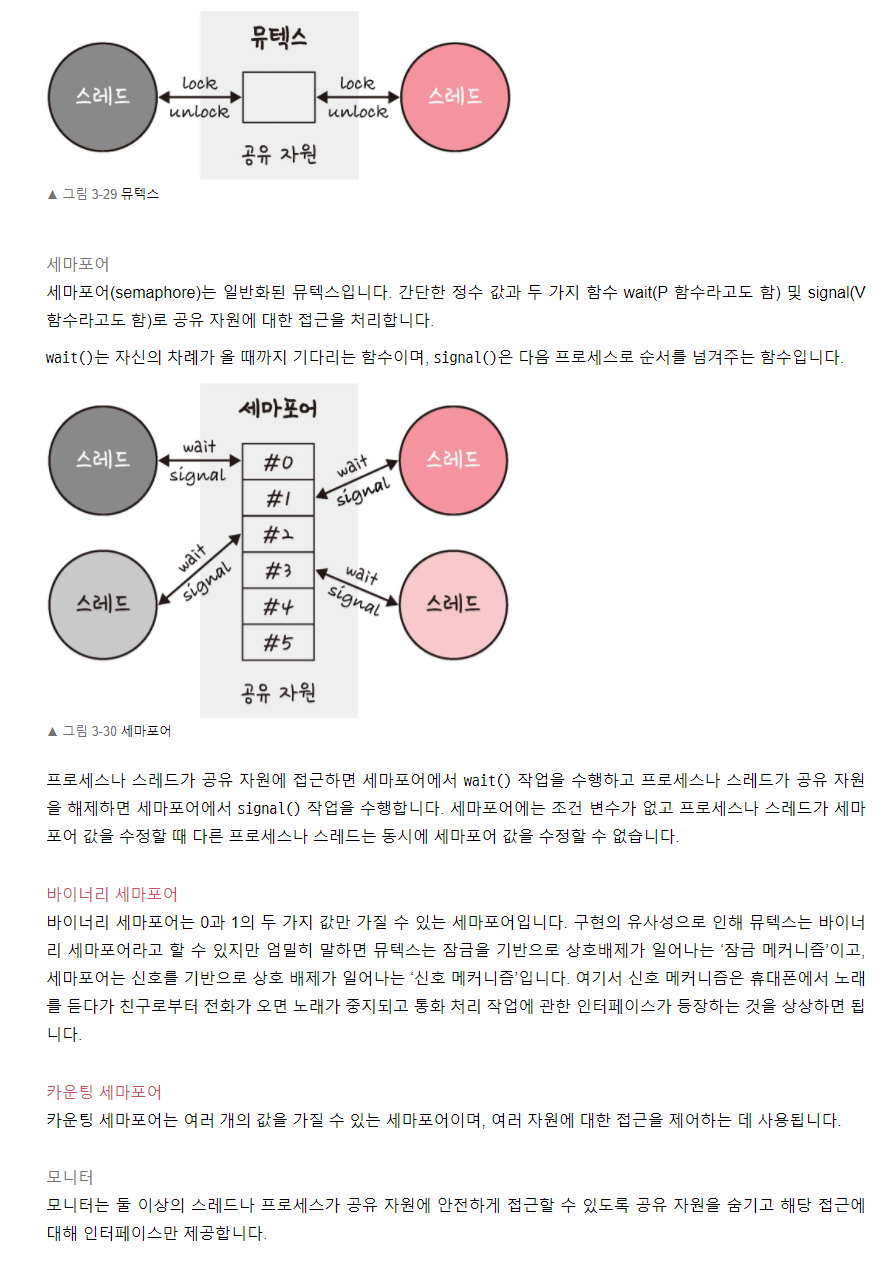


CPU 스케쥴링 알고리즘
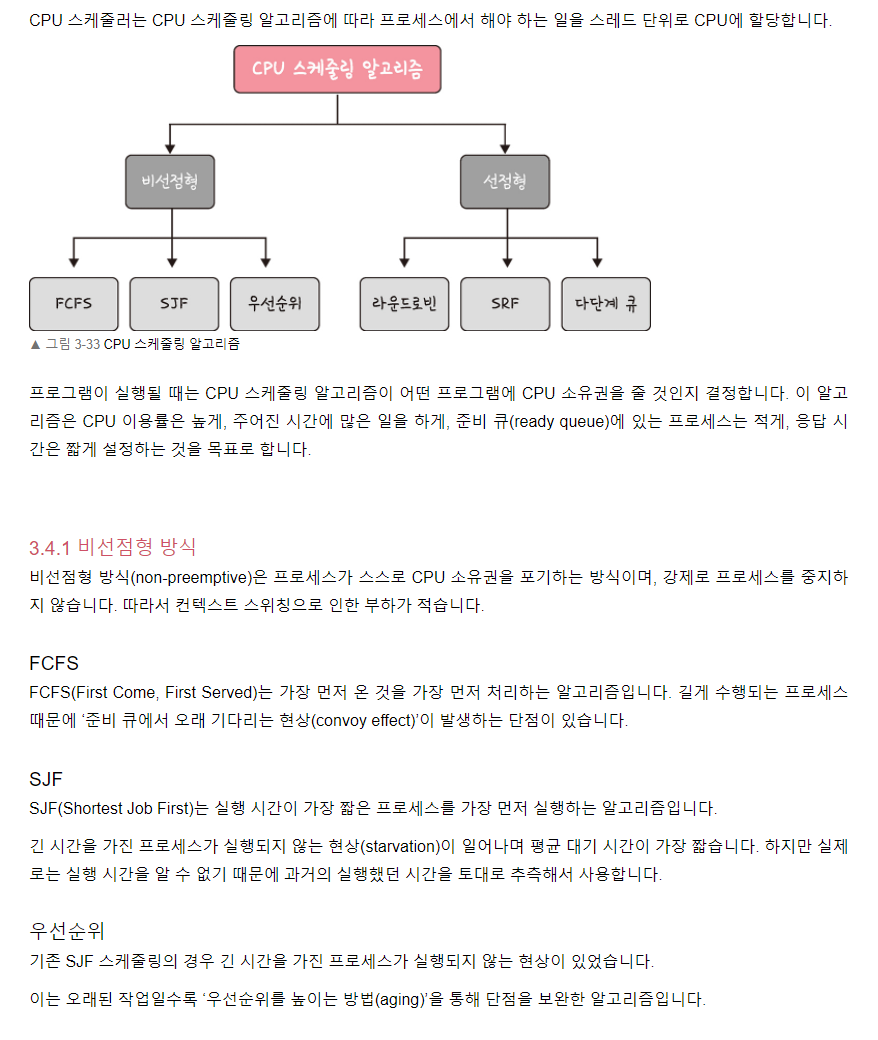
선점형 방식

예상질문
운영체제의 역할은 무엇인가요?

PCB는 뭔가요?

메모리 계층에 대해 설명하세요

예상질문
💡HTTP, HTTPS 설명하세요

💡HTTP 상태 코드란 무엇입니까?
HTTP 상태에서 사용되는 표준 코드는 설정된 서버 작업 완료 상태에 해당합니다. 예를 들어, HTTP 상태 404는 서버에 요청된 리소스가 없음을 나타냅니다.
HTTP 메시지에 모든 것을 전송
• HTML, TEXT
• IMAGE, 음성, 영상, 파일
• JSON, XML (API)
• 거의 모든 형태의 데이터 전송 가능
• 서버간에 데이터를 주고 받을 때도 대부분 HTTP 사용
• 지금은 HTTP 시대
💡HTTP 응답의 핵심 구성 요소는 무엇입니까?
HTTP 응답에는 다음과 같은 네 가지 주요 구성 요소가 있습니다.
-
응답 상태 코드 - 리소스 요청에 대한 응답으로 서버의 상태 코드를 표시합니다. 예: 클라이언트 측 오류는 400으로 표시되는 반면 성공적인 응답은 200으로 표시됩니다.
-
HTTP 버전 - HTTP 프로토콜 버전은 HTTP 버전으로 표시됩니다.
-
응답 헤더 - 응답 메시지의 메타데이터가 이 섹션에 포함됩니다. 데이터는 콘텐츠 길이, 유형, 응답 날짜, 서버 유형 등과 같은 항목을 제공하는 데 사용할 수 있습니다.
-
응답 본문 - 서버가 실제로 반환한 리소스 또는 메시지는 응답 본문에 포함됩니다.
💡HTTP와 HTTPS의 차이점은?
-
HTTP는 암호화가 되지 않은 평문 데이터를 전송하는 프로토콜이기 때문에 보안상 취약점이 있습니다. 이에 따라 TLS 또는 SSL로 알려진 보안 통신을 위한 프로토콜 위에 HTTP 프로토콜을 얹어 통신을 하게 되었고 이것이 HTTPS입니다(HTTP over TLS)
-
HTTP는 별도의 암호화 과정이 없기 때문에 속도가 빠르고, HTTPS는 대칭키 또는 비대칭키를 이용한 암호화 과정이 필요하기 때문에 HTTP에 비해 속도가 느리다는 단점이 있습니다(그러나 현재는 차이가 없는 수준).
-
HTTP는 80번 포트를 사용하고, HTTPS는 443 포트를 사용한다.
💡HTTP Method
HTTP method는 요청 자원에 대해 웹 서버에게 내리는 명령입니다.
대표적으로는 데이터 조회를 위한 GET, 데이터 등록을 위한 POST, 데이터 수정을 위한 PUT, 데이터 삭제를 위한 DELETE 메소드가 있습니다.
-
GET
GET 메소드는 클라이언트에서 서버로 어떤 데이터를 요청할때 사용하는 메소드 입니다. 값이나 내용, 상태 등을 바꾸지 않는 경우에 사용합니다. HTTP 명세에 의하면 GET 요청은 오로지 데이터를 읽을 때만 사용되고 수정할 때는 사용하지 않습니다. 또한 GET 에 대한 응답은 캐싱이 가능하기 때문에 조회 속도를 개선할 수 있습니다. GET으로 요청하는 경우 서버에 보낼 데이터는 URL에 포함해서 보냅니다. 예시로는 웹 브라우저 주소창에 URL을 입력하는 경우에 GET 요청을 보내게 됩니다. -
POST
POST 메소드는 주로 새로운 리소스를 생성(Create)할 때 사용됩니다. GET과는 다르게 같은 POST 요청이 항상 동일한 응답을 받지않고 캐시되지 않습니다. -
PUT
PUT 메소드는 리소스를 생성, 업데이트 하기 위해 사용합니다. 동일한 PUT 요청을 여러 번 호출하면 항상 동일한 결과가 생성됩니다. -
DELETE
DELETE 메소드는 지정된 리소스를 삭제하기 위해 사용합니다. 데이터를 삭제하는 것이기 때문에 요청시에 Body 값과 Content-Type 값이 비워져 있습니다. URL을 통해서 어떠한 데이터를 삭제할지 파라미터를 받습니다.
GET과 POST의 차이는?
GET 방식은 캐싱을 하기 때문에 여러번 요청 시 저장된 데이터를 활용하므로 POST 방식의 요청보다 조금 더 빠를 수 있다. GET은 요청을 전송할 때 필요한 데이터를 body에 담지 않고 쿼리스트링을 통해 전송합니다. POST는 전송할 데이터를 body에 담아서 전송합니다.
POST와 PUT은 무슨 차이가 있는지?
POST와 PUT은 구분해서 사용해야 합니다. POST는 새로운 데이터를 계속 생성하기 때문에 요청시 마다 데이터를 생성하지만, PUT은 사용자가 데이터를 지정하고 수정하는 것이기 때문에 같은 요청을 계속하더라도 데이터가 계속 생성되지는 않습니다.
PUT과 비슷한 PATCH라는 메소드도 있는데 PUT과는 어떤 차이가 있는지?
정보를 수정할 수 있는 PATCH라는 메소드가 또 있습니다. 정보를 수정한다는 점에서 PUT과 같을 것 같지만 PUT은 지정한 데이터를 전부 수정하고 PATCH는 정보의 일부분이 변경된다는 차이가 있습니다.
언제 HTTP를 쓰고, 언제 HTTPS를 쓰는 것이 좋을지 설명해주세요
개인정보와 같은 민감한 데이터를 주고 받아야 한다면 HTTPS를 이용해야 하지만, 노출이 되어도 문제가 되지 않는 단순한 정보 조회등을 처리하기 위해서는 HTTP를 이용하면 됩니다.
HTTP 멱등성
특정 HTTP 메서드를 여러 번 요청을 했을 경우, 매번 요청 결과가 같다면 해당 메소드를 멱등성 메소드라고 한다. GET, PUT, DELETE가 멱등성 메서드에 속하고 POST는 멱등성 메서드가 아니다. 같은 POST를 연속적으로 보낸다면 명령은 여러 번 내린 것처럼 부가적인 결과를 가져오기 때문이다.(POST 요청을 반복하면 같은 내용이더라도 다른 데이터가 계속 추가된다.)
GET은 여러 번 수행해도 서버의 상태가 변하지도 않고 같은 결과를 가져온다.
PUT은 여러 번 수행해도 결과적으로 데이터는 요청한 값으로 수정된 항상 같은 상태이다. DELETE도 여러 번 수행해도 이미 존재하든, 존재하지 않든 그 데이터는 DELETE 요청을 보낸 시점에 사라진다.
cf 안전성
안전성은 호출해도 리소스를 변경하지 않는 특성으로 서버에 영향을 끼치는 여부로 생각하면 된다.
GET 메서드만 안전성 메서드다.
💡HTTP와 TCP의 관계
TCP/IP 모델에서 봤을 때, 개념적으로 TCP는 4계층에 존재하고 HTTP는 5계층에 존재한다. 따라서 HTTP는 TCP위에서 동작한다고 할 수 있다. 쉽게 말해, 메시지 형식에 대해서는 HTTP가 제공해주고, 이 메시지를 TCP 방식으로 전달하는 것이다.
HTTPS 데이터 통신 과정(암호화)
HTTPS 데이터 통신 과정에서는 속도에 이점이 있는 대칭키 암호화와 보안에 이점이 있는 비대칭키 암호화를 모두 사용합니다. 데이터를 주고 받을 때는 빠른 속도가 중요하기 때문에 대칭키를 사용하는 것이 유리하지만 대칭키가 유출되는 경우 누구나 데이터를 복호화할 수 있다는 문제점이 있어 매우 조심해야 합니다. 따라서 서버와 클라이언트가 대칭키를 주고 받을 때 비대칭키를 이용합니다.
보다 구체적으로 설명드리면,
1. 클라이언트가 서버에 HTTPS 연결 요청을 보냅니다.
2. 서버에서 자신의 공개키를 클라이언트에 전달합니다.
3. 클라이언트가 해당 공개키의 유효성을 확인하고 향후 통신에 사용될 대칭키(세션키)를 해당 공개키로 암호화하여 서버에 전송합니다.
4. 서버는 도착한 대칭키를 개인키로 복호화합니다.
5. 서버와 클라이언트가 안전하게 대칭키를 주고받았으므로 해당 키를 이용하여 암호화된 통신을 진행합니다.
💡 HTTP 1.1의 keep alive 기능에 대해 간략히 설명해주세요.
HTTP 기본 구조는 1회성 request와 이에 대한 response로 이뤄집니다. 따라서, 매번 request 및 response로 인한 종료시마다 TCP 프로토콜 단계에서 3-way-handshake 및 4-way-handshake 과정이 필요합니다. keep alive 기능은 이러한 불필요한 연결과 종료 과정을 줄여주는 기능으로, keep alive timeout 기간에는 동일한 source에서 이루어지는 HTTP request에 대해서 연결을 유지하게 됩니다. 이 결과 성능 개선이 가능합니다.
💡HTTP/2를 설명하고 장점 2가지 설명하세요
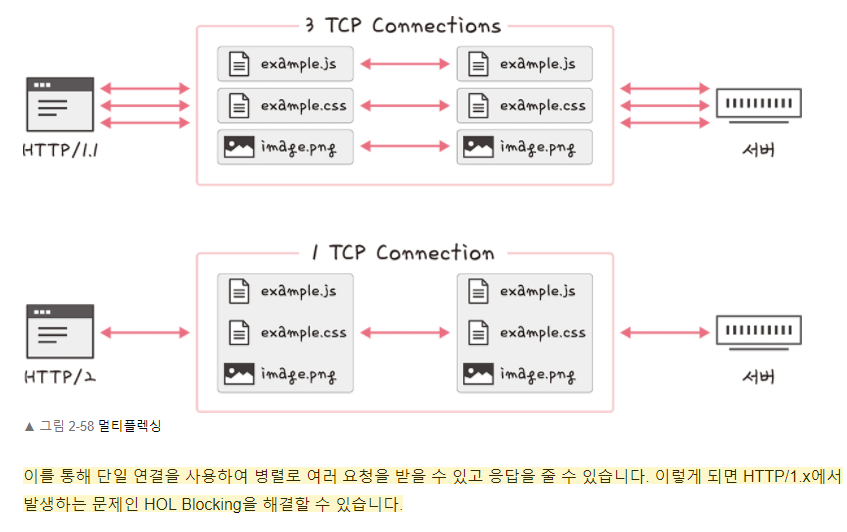
HTTP/2는 HTTP/1.x보다 지연시간을 줄이고 응답 시간을 더 빠르게 할 수있으며 멀티 플렉싱, 헤더 압축, 서버 푸시, 요청의 우선 순위 처리를 지원하는 프로토콜입니다.
장점 2가지는 멀티 플렉싱과 서버 푸시를 들겠습니다.
멀티 플렉싱이란 여러 개의 스트림을 사용하여 송수신한다는 것입니다. 이를 통해 특정 스트림의 패킷이 손실되었다고 하더라도 해당 스트림에만 영향을 끼지치고 나머지 스트림은 멀쩡하게 동작할 수 있습니다. 서버 푸시란 HTTP/1.1에서는 클라이언트가 서버에 요청을 해야 파일을 다운로드받을 수 있었다면, HTTP/2는 클라이언트 요청 없이 서버가 바로 리소스를 푸시하는 것을 말합니다. html에는 css나 js파일이 포함되기 마련인데 html을 읽으면서 그 안에 들어있던 css 파일을 서버에서 푸시하여 클라이언트에 먼저 줄 수 있습니다.
💡DNS(Domain Name System)이 무엇인가요?
도메인 이름을 IP 주소로 변환해주는 시스템 입니다.
💡웹브라우저를 실행시켜서 주소창에 특정 URL값을 입력한 후, 엔터를 눌렀을 때 페이지가 렌더링되는 과정을 웹 통신 흐름에 중점을 두어 가능한 구체적으로 설명해주세요.
우선 네트워크 상으로는 DNS 프로토콜을 사용해서 주소창에 넣은 URL의 IP 주소를 알아냅니다. 이후 해당 IP 주소로 HTTP request를 송신합니다. 이를 통해 서버로부터 HTTP response를 받게 되며, 통상 HTTP response는 HTML 파일이 됩니다. 브라우저는 해당 파일을 표시해주기 위해 DOM tree를 생성하고 이를 기반으로 렌더링을 수행합니다.
DOM이란 무엇인가?
Document Object Model의 줄임말로, 브라우저가 HTML 코드를 트리 형태로 파싱한 결과물을 말합니다. Javascript는 이러한 DOM을 이용하여 페이지 내의 요소들을 동적으로 변경할 수 있게 됩니다.
💡네트워크 관련 명령어 중 ping은 어떤 명령어인가요?
네트워크 상태를 확인하려는 대상 노드를 향해 일정 크기의 패킷을 전송하는 명령어입니다. 해당 노드의 패킷 수신 상태와 도달하기까지의 시간을 알 수 있습니다.
💡네트워크 관련 명령어 중 netstat은 어떤 명령어인가요?
접속되어 있는 서비스들의 네트워크 상태를 표시하는데 사용됩니다. 주로 서비스의 포트가 열려있는지 확인할 때 사용합니다.
💡네트워크 관련 명령어 중 netstat은 어떤 명령어인가요?
네트워크 관련 명령어 중 nslookup은 어떤 명령어인가요?
DNS에 관련된 내용을 확인하기 위해 사용하는 명령어입니다. 특정 도메인에 매핑된 IP를 확인하기 위해 사용합니다.
💡회선 교환 (Circuit switching) vs 패킷 교환 (Packet switching)
회선 교환은 대표적으로 전화에서 쓰이는 데이터 전달 방법입니다. 전화는 시간단위로 요금을 청구하며 실시간성이 중요하기 때문에, 중간에 누군가 그 회선에 끼어들면 안되며 서킷 전체를 독점하며 속도도 일정하게 됩니다. 패킷 교환은 데이터를 패킷단위로 쪼개서 보내는 것이며, 서킷을 독점하지 않고 공용선을 이용합니다.
💡인터넷이 어떻게 작동하는지?
Internet은 IP(Internet Protocol), TCP(Transport Control Protocol) 등 프로토콜에 합의된 방식으로 Packet을 주고 받는 거대한 네트워크입니다.
프로토콜은 컴퓨터가 네트워크 내에서 어떤 방식으로 통신해야하는지 정한 규칙의 집합입니다.
Internet으로 전달되는 데이터를 Message라고 할 때, Message가 전송될 때, 먼저 해당 Message를 packet이라는 조각으로 잘게 나눕니다. 이 패킷들은 서로 독립적으로 전송되며 IP(Internet Protocol)은 어떤식으로 패킷화되어야 하는지 명시하고 있습니다.
💡packet routing network이 무엇인가?
Packet Routing Network란 패킷을 시작 지점 컴퓨터로부터 도착 지점 컴퓨터까지 전달하는 네트워크입니다. 인터넷은 수많은 Router들로 이루어져 있으며 각 router의 역할은 패킷을 출발지점으로부터 목적지로 옮기는데에 있습니다. 패킷은 도착지까지 도달하기 위해 다수의 Router를 지나게 됩니다.
한 Router로부터 다음 Router까지 이동하는 것을 Hop이라고 부릅니다. Internet Protocol에 의하면 Router는 packet의 header에 address를 명시하여 보내야 합니다.
💡이 인터넷 공유기들은 어디서 온 것일까요? 누가 소유하고 있을까요?
1960년대 ARPANET이 인터넷의 시초가 된 이후 ISP(Internet Service Providers)가 router들을 네트워크 내로 추가하였습니다. 인터넷 라우터의 주인이 되는 개인은 없습니다. ARPANET 이후 정부기관, 대학, AT&T와 같은 기관이 router를 점진적으로 추가하였습니다.
💡패킷들은 항상 순서대로 도착합니까? 그렇지 않다면 메시지는 어떻게 재조립됩니까?
Internet Protocol은 패킷이 목적지에 도달한다는 것에 대해 확신을 제공하지 않습니다. Packet Loss가 일어날 수 있습니다. Transmission Control Protocol은 packet loss를 retransmission으로 해결합니다. 도착지에서 출발지점으로 ACK 패킷을 보내게 합니다. 도착지에서 누락된 패킷이 있음을 인식하면 출발지에 retransmission을 요청합니다.
💡이 인터넷 주소들은 어떻게 생겼습니까?

💡약 40억 개의 IPv4 주소만 있는 경우 어떻게 인터넷에 80억 개 이상의 네트워크 장치가 있을 수 있습니까?

💡라우터는 패킷을 보낼 위치를 어떻게 알 수 있습니까? 인터넷에서 모든 IP 주소가 어디에 있는지 알아야 합니까?

💡새 라우터가 인터넷에 추가되면 이러한 모든 네트워크 접두사에 대한 패킷을 처리하는 방법을 어떻게 알 수 있습니까?
새로 설치된 라우터가 패킷을 어디로 라우트해야할 지 모르는 경우가 나올 수 있습니다. 그럴 때는 라우터가 이웃하는 라우터들에게 해당 패킷을 전송해야할 곳의 정보를 알고 있는지 쿼리를 보냅니다. 그리고 이웃한 라우터들은 정보를 파악하여 시작점이었던 라우터에게 되돌려 줍니다. 그리고 라우터는 그 정보를 저장하여 다음에 바로 전송할 수 있도록 준비합니다. 이 알고리즘은 원래 더 복잡한데 생략합니다. 이 방법으로 라우터는 Routing Table이라는, Network Prefix와 Outbound Link를 묶은 정보들을 가집니다.
💡네트워크로 연결된 컴퓨터는 도메인 이름을 기반으로 IP주소를 어떻게 알아냅니까?

💡응용 프로그램은 인터넷을 통해 어떻게 통신합니까?

💡3 way-handshake와 4 way-handshake를 설명해주세요.
-
3 way-handshake란 TCP 네트워크에서 통신 하는 장치가 서로 연결이 잘 되었는지 확인하는 방법입니다. 송신자와 수신자는 총 3번에 걸쳐 데이터를 주고 받으며 통신이 가능한 상태인지 확인합니다.
-
4 way-handshake란 TCP 네트워크에서 통신 하는 장치의 연결을 해제하는 방법입니다. HTTP 요청과 응답 과정이 끝나면 연결과정을 종료하는 4-way-handshaking이 진행된다. 송신자와 수신자는 총 4번에 걸쳐 데이터를 주고 받으며 연결을 끊습니다.

- 클라이언트가 서버로 연결을 종료하겠다는 FIN 패킷 전송
- 서버는 클라이언트에게 우선적으로 ACK 패킷 전송
- 서버는 자신의 통신의 끝날 때까지 기다리고 끝나면 클라이언트에게 FIN 패킷 전송
- 클라이언트는 확인했다는 의미로 ACK 패킷을 서버에게 전송
- 서버가 보내는 FIN보다 서버가 보내는 데이터가 늦게 보내질 경우를 대비해 클라이언트는 일정 시간 동안 소켓을 닫지 않고 잉여 패킷을 기다림(time wait)
- 이후에 연결 종료
💡3 way-handshaking 얘기 해주셨는데, TCP 통신은 종료시에도 3 way-handshaking을 사용하나요?
TCP는 3 way-handshaking 과정을 통해 연결을 설정하고, 4 way-handshaking 과정을 통해 연결을 해제합니다.
💡소켓 통신(TCP, UDP)
TCP(Transmission Control Protocol)
- 연결형 서비스를 지원하는 전송계층 프로토콜
- 인터넷 환경(HTTP)에서 기본으로 사용
- 연결의 설정(3-way handshaking)와 연결의 해제(4-way handshaking) 필요
- 멀티캐스팅이나 브로드캐스팅을 지원하지 않는다.
- 데이터 흐름 제어(송수신 측의 데이터 처리 속도차이 해결), 혼잡 제어(송신측의 전달과 네트워크 데이터 처리 속도 해결), 오류 제어(오류 검출과 재전송)을 통해 높은 신뢰성 보장
3-way handshaking 과정을 통해 연결을 설정하기 때문에 높은 신뢰성 보장하지만 속도는 비교적 느림
- 전이중, 점대점 방식
- 전이중 : 전송이 양방향으로 동시에 일어날 수 있다.
- 점대점 : 각 연결이 정확히 2개의 종단점을 가지고 있다.
UDP(User Datagram Protocol)
- 비연결형 서비스를 지원하는 전송 프로토콜
- checksum 필드를 통해 최소한의 오류만 검출한다.
- 데이터의 전송 순서가 바뀔 수 있음
- 데이터 수신 여부 확인 안함(3-way handshaking과 같은 과정 X)
이로 인해 신뢰성이 떨어지지만 속도가 빠름
- 신뢰성이 낮지만 TCP보다 전송속도가 빠름
- 전송을 위한 논리적인 경로가 없다.
참고
UDP와 TCP는 각각 별도의 포트 주소 공간을 관리하므로 같은 포트 번호를 사용해도 무방하다. 즉, 두 프로토콜에서 동일한 포트 번호를 할당해도 서로 다른 포트로 간주한다.
💡TCP와 UDP의 차이를 설명해주세요.

💡TCP/IP 4계층 모델에 대해 간략히 설명해주세요
-
애플리케이션 계층 > 전송 계층 > 인터넷 계층 > 링크 계층으로 이뤄져 있습니다.
-
애플리케이션 계층은 서비스를 실질적으로 사람들에게 제공하는 층입니다.
-
전송 계층은 송신자와 수신자를 연결하는 통신 서비스를 제공하는 계층이며 대표적인 프로토콜은 TCP와 UDP가 있습니다. TCP는 신뢰성 있고 순차적인 데이터 전송과 흐름제어, 혼잡제어 기능을 제공하고 UDP는 이러한 기능을 제공하지 않는 대신 데이터 전송 속도가 빠르다는 특징이 있습니다.
OSI 7계층 모델, TCP/IP 4계층 모델처럼 계층을 나눠서 사용하는 이유가 무엇인가요?
특정 계층이 변경되었을 때 다른 계층이 영향을 받지 않도록 설계하기 위함입니다. 계층별로 독립적인 구조로 설계하면 특정 계층에서 오류나 수정이 발생하여도 전체 시스템을 변경하지 않고 사용할 수 있게 되기 때문입니다.
흐름 제어와 혼잡 제어에 대해 설명해주세요.
흐름 제어는 데이터를 받는 쪽의 성능을 고려하여 보내는 데이터의 양을 과하지 않게 제어하는 것을 말합니다. Stop and Wait 방식과 Sliding Window 방식이 대표적입니다. 최근에는 윈도우 사이즈 설정 후 RTT를 기반으로 재설정합니다. 컴퓨터 성능이 충분히 좋아져서 RTT가 더 중요한 변수가 되었기 때문입니다.
혼잡 제어는 네트워크의 혼잡을 피하기 위해 송신측에서 데이터 전송 속도를 제어하는 것을 말합니다. 특정 라우터에 처리할 수 없을 정도의 많은 데이터가 몰리면 데이터가 유실되는데, 이렇게 되면 송신측에서는 데이터를 다시 보내고 혼잡만 가중시키게 됩니다. 이러한 상황을 피하기 위한 방법입니다.
흐름 제어: Sliding Window에 대해 설명해주세요.
상대방 컴퓨터의 성능을 기반으로 한 번에 처리할 수 있는 데이터의 양을 측정합니다. 이를 윈도우사이즈라고 합니다. 이후, 최대 해당 사이즈만큼의 데이터를 ACK 없이 연속해서 송신하는 방식을 말합니다(반드시 윈도우 사이즈만큼의 데이터를 전송하지는 않습니다).
혼잡 제어 방식에 대해 아는 대로 설명해주세요
-
AIMD
Congestion Window 크기를 초기 1에서 시작하여 ACK를 받을 때마다 1씩 증가시키는 방식입니다. 만약 패킷 전송에 실패하는 경우 CWND의 사이즈를 반으로 줄입니다. -
Slow Start
CWND를 1로 시작하여 ACK를 받을 때마다 2배씩 증가시킵니다. 패킷 전송에 실패하는 경우 초기값부터 다시 시작합니다. -
혼잡 회피
Slow Start처럼 동작하다 일정 크기에 도달하면 CWND를 1씩 증가시키는 방식으로 변화합니다.
💡채팅 서버-클라이언트간에는 TCP와 UDP중 어떤 프로토콜을 사용하는 것이 좋을지에 대해 가능한 구체적으로 설명해주세요.
해당 경우에는 빠른 데이터 송신보다 신뢰성 있는 데이터 송수신이 더 중요하므로 TCP 프로토콜을 사용하는 것이 좋겠습니다.
💡TCP의 연결 과정에서 3way와 4way가 단계 차이가 나는 이유
Client가 데이터 전송을 마쳤다고 하더라도 Server는 아직 보낼 데이터가 남아있을 수 있기 때문에 일단 ACK만 먼저 보내고, 데이터를 모두 전송한 후에 자신도 FIN 메시지를 보내기 때문이다.
💡서킷 스위칭과 패킷 스위칭에 대해 설명해보세요.
-
서킷 스위칭
하나의 회선을 할당받아 데이터를 주고받는 방식을 말합니다. 데이터를 송수신하기 전에 통신을 위한 연결이 선행되며 연결 후 출발지부터 도착지까지의 회선을 독점하게 됩니다. 따라서 다른 사람이 끼어들 수 없습니다(예: 전화선). -
패킷 스위칭
데이터를 패킷 단위로 나눠 전송하는 방식을 말합니다. 패킷은 다음 링크로 전달하기 전에 저장하고 전달하는 store and forward 방식을 따릅니다. 패킷의 헤더에는 출발지와 목적지 정보가 있습니다. 라우팅 알고리즘을 통해 경로를 설정하게 됩니다. 다음 라우터로 이동할 때까지 큐에서 대기하게 되는데 한도를 초과하면 loss가 발생할 수 있습니다.
💡가상회선 패킷 교환 방식과 데이터그램 패킷 교환 방식에 대해 설명해보세요.
가상회선 패킷 교환 방식은 각 패킷에 가상 회선 식별자가 포함되어 해당 회선을 따라 순서대로 패킷이 전달되는 방식을 말합니다. 서킷 스위칭과 비슷하나 패킷이 일시적으로 라우터에 저장된다는 점이 다릅니다. 모든 패킷을 전송하면 가상회선이 해제됩니다.
데이터그램 패킷 교환 방식은 패킷이 독립적으로 이동하며 최적의 경로를 선택하여 가는 방식을 말합니다. 패킷이 도착하는 순서가 다를 수 있습니다.
💡Server에서 FIN 플래그를 전송하기 전에 전송한 패킷이 Routing 지연이나 패킷 유실로 인한 재전송 등으로 인해 FIN 패킷보다 늦게 도작한 상황이 발생하면?
이러한 현상을 대비하여 Client는 Server로부터 FIN 플래그를 수신하더라도 일정기간 time wait동안 세션을 남겨 놓고 잉여 패킷을 기다리는 과정을 거친다.
💡초기 Sequence Number인 ISM을 0부터 시작하지 않고 난수를 생성해서 설정하는 이유
커넥션을 맺을 때 사용하는 포트는 시간이 지남에 따라 재사용된다. 따라서 두 통신이 과거에 사용된 포트 번호 쌍을 사용할 가능성이 생기고 난수가 아닌 순차적 Number가 전송된다면 이전의 커넥션으로부터 오는 패킷으로 인식할 가능성이 생긴다.
Server Push
서버는 클라이언트 요청에 대해 요청하지 않은 리소스도 보낼 수 있다.
HTTP/1.1에서는 HTML문서를 요청하고 받은뒤 그 안에 css,image 파일이 있다면 서버로 재요청했으나, HTTP/2.0에서는 Server Push 기능으로 클라이언트에서 요청하지 않은 (HTML문서에 포함된 리소스) 리소스를 Push 해주는 방법으로 클라이언트의 요청을 최소화하여 성능을 향상시킨다.
CORS
교차 출처 리소스 공유(Cross-Origin Resource Sharing, CORS)는 추가 HTTP 헤더를 사용하여, 한 출처에서 실행 중인 웹 애플리케이션이 다른 출처의 선택한 자원에 접근할 수 있는 권한을 부여하도록 브라우저에 알려주는 체제이다.
웹 애플리케이션은 리소스가 자신의 출처(도메인, 프로토콜, 포트)와 다를 때 교차 출처 HTTP 요청을 실행한다.
브라우저는 보안상의 이유로, 스크립트에서 시작한 교차 출처 HTTP 요청을 제한한다.
예를 들면, domain-a.com <-> domain-b.com 간의 요청은 CORS정책 위반으로, 브라우저에서 요청을 제한한다.
따라서 다른 출처의 리소스를 불러오기 위해서는, 그 출처에서 교차 출처 리소스 공유에 대한 헤더(CORS)를 응답 시 반환해주어야 한다. 기본적으로는 다음과 같이 동작한다.
- 실제 요청을 보내기 전에 Preflight라는 예비 요청을 보낸다. 이때 HTTP의 OPTIONS 메서드를 이용해 서버에 보낸다.
- 서버는 예비 요청이 CORS를 위반하고 있는지를 확인하고 정보를 클라이언트에게 보낸다.
- Preflight에 대해 서버 응답이 안전하다면 실제 요청을 보낸다.

CSRF(Cross-site request forgery)에 대해 설명하고, 이를 막기 위한 방법에 대해 설명해주세요.

URI, URL, URN


💡OSI 7계층에 대해 간략히 설명해주세요
OSI 7계층은 컴퓨터간 통신 과정을 추상화한 모델로, 물리 계층, 데이터 링크 계층, 네트워크 계층, 전송 계층, 세션 계층, 표현 계층, 응용 계층으로 나뉩니다. 물리 계층은 시스템간 물리적 연결을 담당하고, 데이터 링크 계층은 네트워크 기기간 데이터 전송을 담당하고, 네트워크 계층은 다른 네트워크와의 통신 경로 설정을 담당하고, 전송 계층은 신뢰할 수 있는 통신을 담당하고, 세션 계층은 세션을 처리하며, 표현 계층은 데이터 변환, 응용 계층은 응용 프로그램에 대한 서비스 제공을 담당합니다.
💡OSI 7계층과 TCP/IP 4계층의 차이는?
TCP/IP 계층과 달리 OSI 계층은 애플리케이션 계층을 세 개로 쪼개고 링크 계층을 데이터 링크 계층, 물리 계층으로 나눠서 설명하는 것이 다르며, 인터넷 계층을 네트워크 계층으로 부른다는 점에서 다릅니다.
💡URI란 무엇입니까?
URI(Uniform Resource Identifier)를 URI라고 합니다. REST의 URI는 웹 서버의 리소스를 지정하는 문자열입니다. 각 리소스에는 HTTP 요청에서 사용될 때 클라이언트가 이를 대상으로 지정하고 작업을 수행할 수 있도록 하는 고유한 URI가 있습니다. 주소 지정은 URI를 사용하여 리소스로 트래픽을 보내는 프로세스입니다.
URI 형식은 다음과 같습니다.
<프로토콜>://<서비스 이름>/<리소스 유형>/<리소스 ID>
URI에는 두 가지 유형이 있습니다.
-
URL - 해당 위치에서 리소스 검색에 대한 정보는 Uniform Resource Locator에서 사용할 수 있습니다.
URL에는 네트워크 호스트 이름(sampleServer.com) 및 콘텐츠 경로(/samplePage.html)에 대한 정보가 포함되어 있으며 프로토콜(예: FTP, HTTP 등)로 시작합니다. 검색 기준이 있을 수도 있습니다.
-
URN - 고유하고 내구성 있는 이름을 사용하여 균일한 자원 이름이 자원을 식별합니다.
인터넷에서 리소스의 위치는 URN에 의해 반드시 지정되지는 않습니다. 리소스를 식별할 때 다른 파서가 사용할 모델 역할을 합니다.
URN이 문서를 식별할 때마다 "resolver"를 사용하여 빠르게 URL로 변환하여 다운로드할 수 있습니다.
중간자 공격

WebSocket과 Socket.io

gRPC

쿠키와 세션 차이

쿠키
-
쿠키는 정보를 클라이언트에 저장한다. (개인 PC)
-
데이터 형태는 key, value 형태이며, String으로 이루어져 있다.
이름, 값, 만료일, 경로 정보로 구성되어있다.쿠키는 사용자의 컴퓨터에 저장이 된다. 웹 브라우저가 보관하고 있는 데이터로, 웹 서버에 요청을 보낼 때 쿠키들을 헤더에 담아서 전송한다. 전송이라는 것은 헤더란 부분과 바디라는 부분으로 두 가지로 나뉘는데 바디는 실제 요청에 대한 데이터들을 가지고 있고 헤더에는 그 요청에 대한 설정을 가지고 있다.
-
쿠키는 클라이언트(브라우저) 로컬에 저장되는 키와 값이 들어있는 작은 데이터 파일입니다.
-
사용자 인증이 유효한 시간을 명시할 수 있으며, 유효 시간이 정해지면 브라우저가 종료되어도 인증이 유지된다는 특징이 있습니다.
-
쿠키는 클라이언트의 상태 정보를 로컬에 저장했다가 참조합니다.
-
클라이언트에 300개까지 쿠키저장 가능, 하나의 도메인당 20개의 값만 가질 수 있음, 하나의 쿠키값은 4KB까지 저장합니다.
-
Response Header에 Set-Cookie 속성을 사용하면 클라이언트에 쿠키를 만들 수 있습니다.
-
쿠키는 사용자가 따로 요청하지 않아도 브라우저가 Request시에 Request Header를 넣어서 자동으로 서버에 전송합니다.
구성요소
- 이름 : 각각의 쿠키를 구별하는 데 사용되는 이름
- 값 : 쿠키의 이름과 관련된 값
- 유효시간 : 쿠키의 유지시간
- 도메인 : 쿠키를 전송할 도메인
- 경로 : 쿠키를 전송할 요청 경로
장단점
클라이언트의 일정 폴더에 정보를 저장하기 때문에 서버의 부하를 줄일 수 있다. 데이터가 사용자 컴퓨터에 저장되기 때문에 보안의 위협을 받을 수 있다. 데이터 저장 용량에 한계가 있다.(소용량의 문자열 데이터) 일반 사용자가 브라우저 내의 기능인 "쿠키차단"을 사용하면 무용지물이 된다.
보안 문제
-
쿠키 값은 임의로 변경 가능
-
쿠키에 보관된 정보를 훔칠 수 있음
동작 방식
- 클라이언트가 페이지를 요청
- 서버에서 쿠키를 생성
- HTTP 헤더에 쿠키를 포함 시켜 응답
- 브라우저가 종료되어도 쿠키 만료 기간이 있다면 클라이언트에서 보관하고 있음
- 같은 요청을 할 경우 HTTP 헤더에 쿠키를 함께 보냄
- 서버에서 쿠키를 읽어 이전 상태 정보를 변경 할 필요가 있을 때 쿠키를 업데이트 하여 변경된 쿠키를 HTTP 헤더에 포함시켜 응답

세션
-
세션은 정보를 웹서버에 저장한다.
-
세션은 웹 브라우저 당 1개씩 생성되고 웹 컨테이너에 저장한다.
-
브라우저가 종료되면 세션도 삭제된다.
-
로그아웃을 하면 쿠키가 삭제되어 보안성이 좋다.
-
브라우저를 닫거나 세션을 삭제해야만 삭제가 된다.
-
저장 데이터 제한이 없다.
-
내장객체로서 브라우저마다 한개씩 존재하고, 고유한 SessionID 생성 후 정보를 추출한다.
-
서버에 중요한 정보를 보관하고 연결을 유지하는 방법
-
세션은 쿠키를 기반하고 있지만, 사용자 정보 파일을 브라우저에 저장하는 쿠키와 달리 세션은 서버 측에서 관리합니다.
-
서버에서는 클라이언트를 구분하기 위해 세션 ID를 부여하며 웹 브라우저가 서버에 접속해서 브라우저를 종료할 때까지 인증상태를 유지합니다.
-
물론 접속 시간에 제한을 두어 일정 시간 응답이 없다면 정보가 유지되지 않게 설정이 가능 합니다.
-
사용자에 대한 정보를 서버에 두기 때문에 쿠키보다 보안에 좋지만, 사용자가 많아질수록 서버 메모리를 많이 차지하게 됩니다.
-
즉 동접자 수가 많은 웹 사이트인 경우 서버에 과부하를 주게 되므로 성능 저하의 요인이 됩니다.
-
클라이언트가 Request를 보내면, 해당 서버의 엔진이 클라이언트에게 유일한 ID를 부여하는 데 이것이 세션 ID입니다.
세션 동작 방식
- 클라이언트가 서버에 접속 시 세션 ID를 발급 받음
- 클라이언트는 세션 ID에 대해 쿠키를 사용해서 저장하고 가지고 있음
- 클라리언트는 서버에 요청할 때, 이 쿠키의 세션 ID를 같이 서버에 전달해서 요청
- 서버는 세션 ID를 전달 받아서 별다른 작업없이 세션 ID로 세션에 있는 클라언트 정보를 가져와서 사용
- 클라이언트 정보를 가지고 서버 요청을 처리하여 클라이언트에게 응답
핵심!
👉 회원과 관련된 정보는 전혀 클라이언트에 전달하지 않음
👉 추정 불가능한 세션 ID만 쿠키를 통해 클라이언트에 전달
특징
-
각 클라이언트에게 고유 ID를 부여
-
세션 ID로 클라이언트를 구분해서 클라이언트의 요구에 맞는 서비스를 제공
-
보안 면에서 쿠키보다 우수
-
사용자가 많아질수록 서버 메모리를 많이 차지하게 됨
장점
보안성이 좋고 저장용량의 한계가 거의 없다. 서버에 데이터를 저장하므로 부하에 걸릴 수 있다. 쿠키보다 세션을 쓰는것이 더 안정적이다.

💡세션 기반 인증과 토큰 기반 인증의 차이에 대해 얘기해주세요.
세션 기반 인증은 클라이언트로부터 요청을 받으면 클라이언트의 상태 정보를 저장하므로 Stateful한 구조를 가지고, 토큰 기반 인증은 상태 정보를 서버에 저장하지 않으므로 Stateless한 구조를 가집니다.
Stateful과 Stateless는, 클라이언트와 서버간의 네트워크 통신이 어떻게 이루어지는지에 대한 개념입니다. 즉, 네트워크 프로토콜입니다.
Stateful
Stateless


💡그렇다면 Stateful한 세션 기반의 인증 방식을 사용하게 된다면 어떠한 단점이 있을까요?
-
서버에 세션을 저장하기 때문에 사용자가 증가하면 서버에 과부하를 줄 수 있어 확장성이 낮습니다.
-
해커가 훔친 쿠키를 이용해 요청을 보내면 서버는 올바른 사용자가 보낸 요청인지 알 수 없습니다. (세션 하이재킹 공격)
💡그렇다면 세션 기반 인증과 토큰 기반 인증은 각각 어느 경우에 적합한가요?
단일 도메인이라면 세션 기반 인증을 사용하고, 아니라면 토큰 기반 인증을 사용하는 것이 적합하다고 생각합니다.
왜? - 세션을 관리할 때 사용되는 쿠키는 단일 도메인 및 서브 도메인에서만 작동하도록 설계되어 있기 때문에 여러 도메인에서 관리하는 것은 어렵습니다. (CORS 문제)
💡Connection Timeout과 Read Timeout의 차이에 대해 설명해주세요.
서버 자체에 클라이언트가 어떤 사유로 접근을 실패했을 시 적용되는 것이 Connection Timeout입니다. 즉, 접근을 시도하는 시간 제한이 Connection Timeout 되는 것을 말합니다.
클라이언트가 서버에 접속을 성공 했으나 서버가 로직을 수행하는 시간이 너무 길어 제대로 응답을 못 준 상태에서 클라이언트가 연결을 해제하는 것이 Read Timeout입니다.
이 경우는 클라이언트는 해당 상황을 오류로 인지하고, 서버는 계속 로직을 수행하고 있어 성공으로 인지해 양 사이드간 싱크가 맞지 않아 문제가 발생할 확률이 높습니다.
💡공인(public) IP와 사설(private) IP의 차이에 대해 설명해주세요.
-
공인 IP는 ISP(인터넷 서비스 공급자)가 제공하는 IP 주소이며, 외부에 공개되어 있는 IP주소 입니다.
-
사설 IP는 일반 가정이나 회사 내 등에 할당된 네트워크 IP 주소이며, IPv4의 주소부족으로 인해 서브넷팅된 IP이기 때문에 라우터(공유기)에 의해 로컬 네트워크상의 PC나 장치에 할당됩니다.
-
사설 IP 주소만으로는 인터넷에 직접 연결할 수 없고, 라우터를 통해 1개의 공인 IP를 할당하고, 라우터에 연결된 개인 PC는 사설 IP를 각각 할당 받아 인터넷에 접속 할 수 있습니다.
💡goole.com/ naver.com을 주소창에 입력했을 때 벌어지는 일
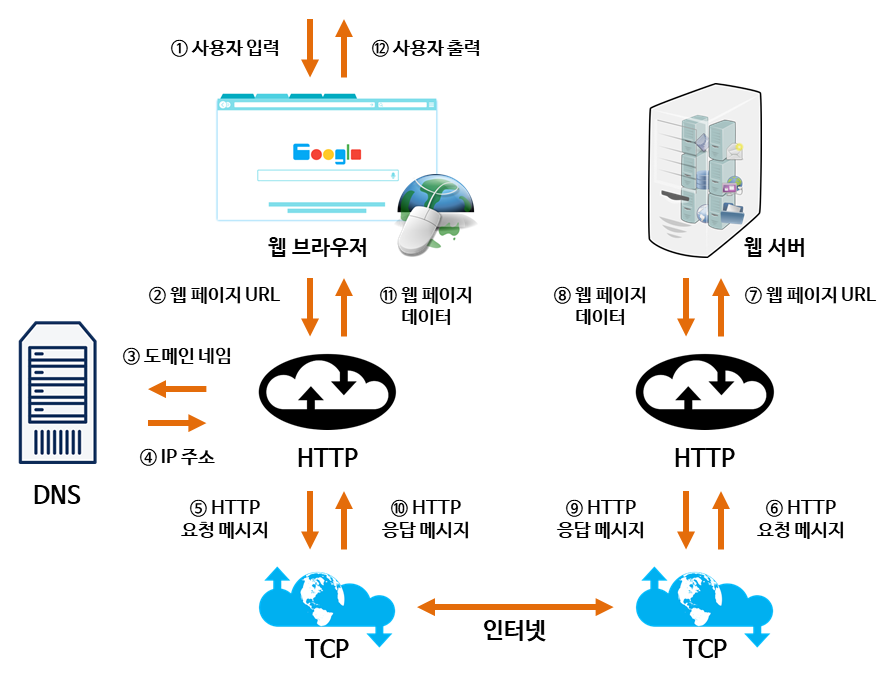
① naver.com
→ 원래는 119.255.212:5000같은 형식으로 되어 있다.
② 웹 브라우저 도메인(naver.com)을 통해 DNS라는 도서관(서버)에 저장
( HTTP 통신규약을 사용하여 도메인서버(DNS)에 맞는 도메인(naver.com)을 탐색)
③ IP 주소로 웹 서버에 TCP 3 handshake로 연결 수립
④ 웹 브라우저가 해당 사이트 서버에 데이터를 요청(HTTP 요청 메세지)
WAS(서버 도우미) - 동적 처리(사용자에 입력에 따라 처리되는 경우) → (Tomcat)
DB(데이터베이스)를 통해 데이터 요청
⑤ 작업을 처리하고 처리한 결과를 다시 웹 브라우저에 전송(HTTP 응답 메시지)
⑥ 웹 브라우저는 웹 페이지의 데이터들을 파싱(가공) 후 화면에 출력
💡HTML 파싱(가공) 과정
① 웹 브라우저에 전달된 데이터를 브라우저 로더가 분석(구분)
② HTML(DOM tree), CSS(CSSOM)
③ DOM tree에 CSSOM의 css가 합치면서 랜더링 트리
④ HTML에 css 결정 후 레이아웃 과정(크기, 위치 계산)
⑤ 랜더링 JS가 적용
⑥ 페인트(처음 화면에 그려주는 과정) --- 리페인트(변화가 생겼을 때)
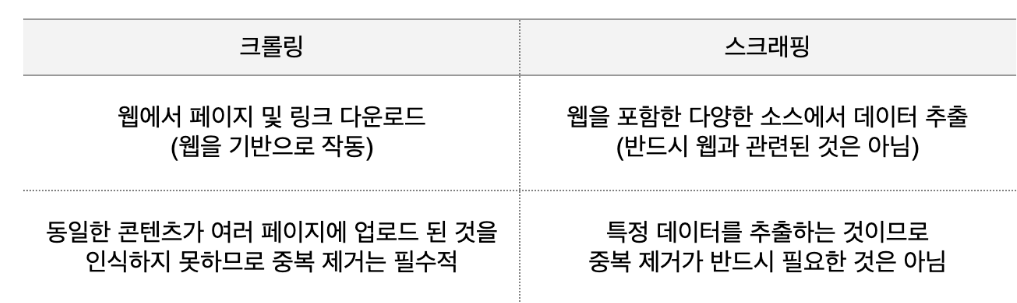
💡크롤링이란?
Web상에 존재하는 Contents를 수집하는 작업(프로그래밍으로 자동화 가능)
- HTML 페이지를 가져와서, HTML/CSS등을 파싱하고, 필요한 데이터를 추출하는 기법
- Open API(Rest API)를 제공하는 서비스에 Open API를 호출해서 받은 데이터 중 필요한 데이터만 추출하는 기법
- Selenum등 브라우저를 프로그래밍으로 조작해서 필요한 데이터만 추출하는 기법
웹상의 정보들을 탐색하고 수직하는 작업을 의미한다. 규칙에 따라 자동으로 웹 문서를 탐색하는 프로그램,
웹 크롤러(Web Crawler)를 만들었다. 크롤러는 인터넷을 돌아다니며 여러 웹 사이트에 접속하고 페이지의 내용과 링크의 복사본을 생성하여 다운로드하고 요약본을 만듭니다. 그리고 검색 시 유요한 정보만을 노출하도록 검색 색인을 붙입니다.예를들어, 도서관에서 책을 찾기위해 도서의 주제, 제목 등에 따라 분류 기준을 구성하는 것과 비슷한 작업입니다.
Web Crawler
- 웹 크롤러란 자동화된 방법으로 웹에서 다양한 정보를 수집하는 소프트웨어
- 원하는 서비스에서 원하는 정보를 편하게 얻어올 수 있다.
- 언어를 막론하고 구현할 수 있지만 주로 Python을 이용한다.
💡웹 스크래핑(Web Scraping)
웹 스크래핑은 특정 웹 사이트나 페이지에서 필요한 데이터를 자동으로 추출해 내는 것을 의미합니다. 웹 스크래핑은 다음과 같이 작동합니다. 원하는 정보를 추출하기 위해 스크래퍼 봇이 특정 웹 사이트에 콘텐츠를 다운로드하기 위한 HTTP GET 요청을 보냅니다. 사이트가 이에 응답하면 스크래퍼는 HTML 문서를 분석하여 특정 패턴을 지닌 데이터를 뽑아 냅니다. 그리고 추출된 데이터를 원하는 대로 사용할 수 있도록 데이터베이스에 저장합니다.
웹 크롤링과 웹 스크래핑의 장점
심층 분석과 실시간 정보 제공에 유용한 웹 크롤링
웹 크롤링은 웹상을 돌아다니며 방대한 양의 정보를 수직하기 때문에 특정 키워드에 대한 심층 분석이 필요할 때 유용합니다. 또한 크롤러는 실시간 정보 수집을 위해 계속해서 작동하므로 자주 변화하는 데이터를 파악하기 좋습니다.
정확한 정보를 요구할 때 쓰이는 웹 스크래핑
웹 스크래핑은 특정 사이트나 페이지에 대한 정보를 찾는데 집중하므로 데이터 포인터를 정확히 잡고 확실한 정보만을 수집할 수 있다는 점에서 유용합니다. 장기적으로 서비스 대역폭이나 비용을 절약할 수 있다는 장점이 있습니다.
💡크롤링(crawling)과 스크래핑(scraping)의 차이
- 웹 크롤링 : 웹 크롤러(자동화 봇)가 일정 규칙으로 웹페이지를 브라우징 하는 것
- 웹 스크래핑 : 웹 사이트 상에서 원하는 정보를 추출하는 기술
💡컨텍스트 스위칭에 대해 가능한 상세하게 설명해주세요.
-
컨텍스트 스위칭이란 멀티 태스킹 등 프로세스 스위칭이 필요할 때, 실행할 프로세스를 CPU에 교체해주는 기술입니다.
-
다시 말하면, 하나의 프로세스가 CPU를 사용 중인 상태에서 다른 프로세스가 CPU를 사용하도록 하기 위해, 이전의 프로세스의 상태를 보관하고 새로운 프로세스의 상태를 적재하는 작업을 말합니다.
-
구체적으로는 현재 실행중인 프로세스의 PID, PC/SP와 같은 레지스터값 등 주요 프로세스 상태 정보를 해당 프로세스의 PCB에 저장하고, 다음에 실행할 프로세스의 PCB 정보에서 주요 프로세스 상태 정보를 CPU에 업데이트한 후, 해당 프로세스를 실행시킵니다.
💡캐시의 시간 지역성, 공간 지역성이란?
-
시간 지역성
데이터의 읽기/쓰기를 위해 특정 메모리가 사용됐을 대 가까운 시일 내에 해당 메모리가 다시 사용될 가능성이 높다는 특성 -
공간 지역성
대부분의 실제 프로그램이 참조된 주소와 인접한 주소의 내용이 다시 참조되는 특성
💡프로세스 구조에 대해 가능한 상세하게 설명해주세요.
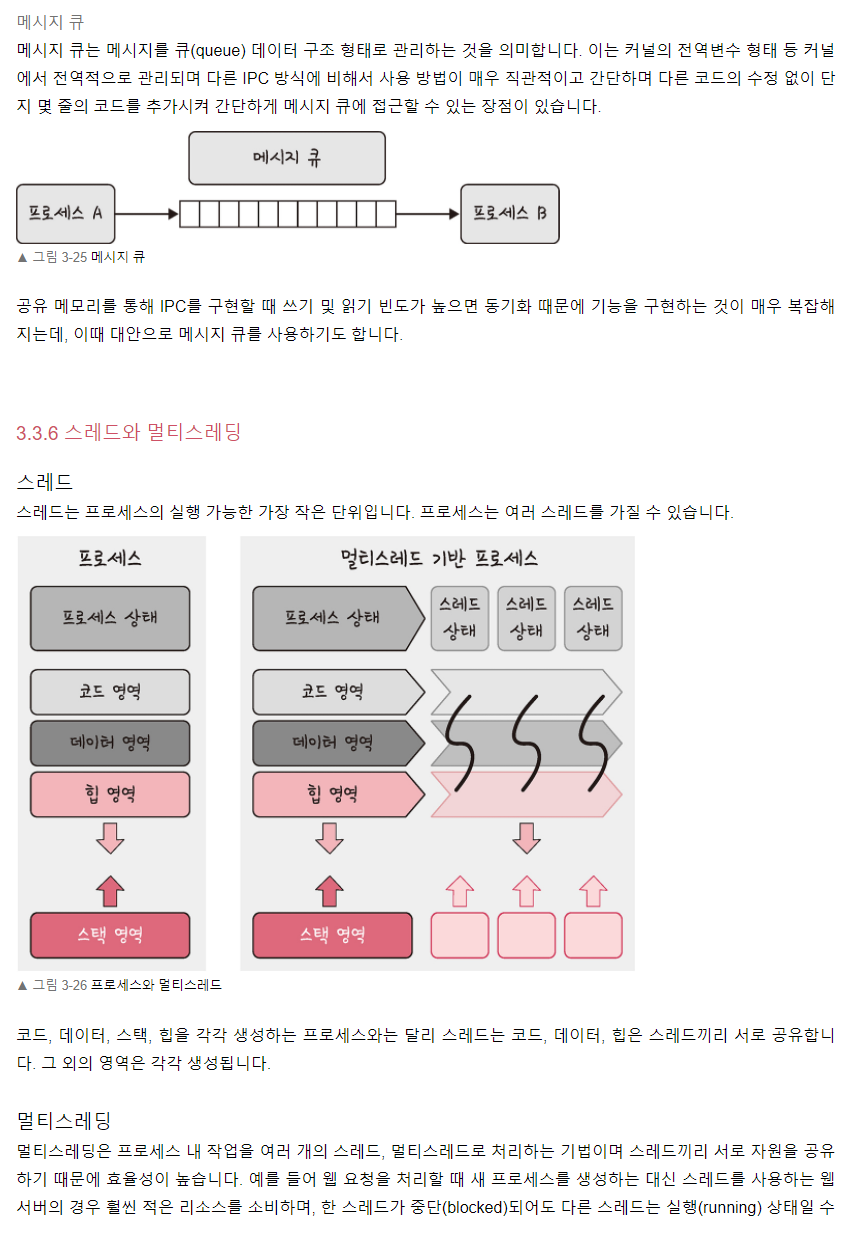
프로세스는 일반적으로 코드, 데이터, 힙, 스택 영역으로 이루어져있습니다. 코드 영역은 프로그램 코드가 저장되고, 데이터 영역은 전역 변수등이 저장되며, 힙 영역은 동적으로 할당된 메모리를 위한 공간이고, 스택 영역은 함수 실행을 위한 지역 변수 등이 저장됩니다.
💡프로세스간에는 어떤 기술을 사용해서 통신하는지, 왜 해당 기술을 사용해서 통신해야하는지를 쓰레드와 비교해서 설명해주세요.
-
프로세스간에는 주소공간이 분리되어 있기 때문에, 프로세스간 통신을 위해서는
IPC라고 하는 별도의 기술을 사용해야 합니다. -
쓰레드의 경우에는 하나의 프로세스 주소공간 안에서 CODE/DATA/HEAP 공간을 공유하기 때문에, 별도의 통신 기술은 필요 없습니다.
IPC는 종류가 무엇이 있나요?
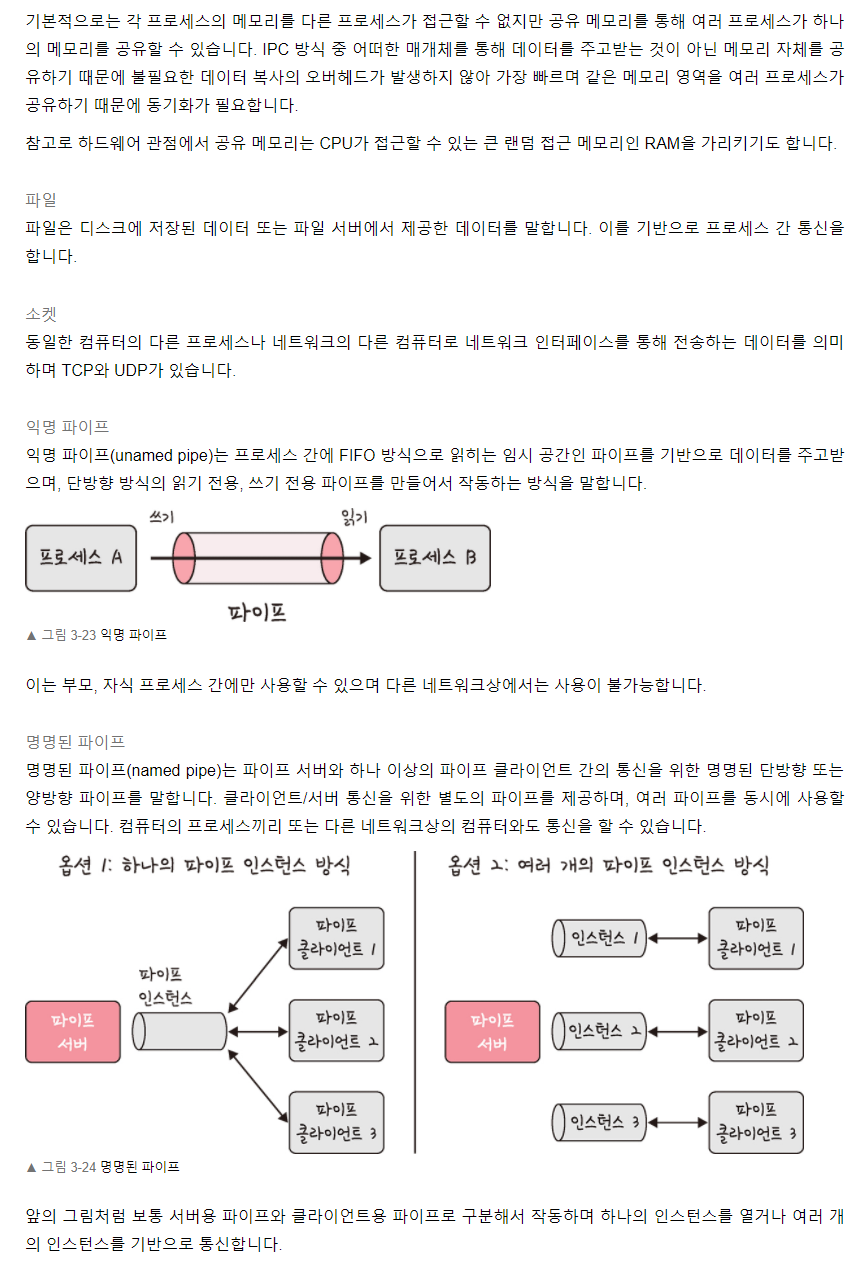
공유 메모리, 파일, 소켓, 익명 파이프, 명명 파이프, 메시지 큐 등이 있습니다.
공유 메모리 방법을 설명해주세요
기본적으로는 각 프로세스의 메모리는 다른 프로세스에서 접근할 수 없지만, 메인 메모리 공간에 공유할 수 있는 메모리 영역을 두어 이를 통해 서로 통신하는 방법입니다.
💡프로세스와 쓰레드의 차이점에 대해 설명해주세요.
-
프로세스는 운영체제로부터 자원을 할당받아 실행하고,쓰레드는 프로세스로부터 자원을 할당받아 실행합니다. -
하나의 프로세스 안에서 쓰레드는 프로세스의 CODE/DATA/HEAP 공간을 공유하지만, 해당 쓰레드만의 스택을 가지고 동작합니다. 그래서 하나의 프로세스 안에서 생성된 쓰레드간에는 별도 기술을 쓰지 않고도 데이터 공유가 가능합니다.
-
프로세스는 컨텍스트 스위칭이 발생하면 캐시 메모리를 비워야 하기 때문에 오버헤드가 심하지만, 스레드는 캐시 메모리를 그대로 사용하기 때문에 오버헤드가 적고 더 빠릅니다.
-
멀티 프로세스로 실행되고 있을 때 한 프로세스에 문제가 생기면 나머지는 영향을 받지 않지만, 멀티쓰레드는 해당 프로세스 관련 쓰레드 전체에 영향을 줍니다.
💡언제 멀티 프로세스를 사용하고, 언제 멀티 쓰레드를 써야하는지 구체적으로 설명해주세요.
멀티 쓰레드는 프로세스 주소공간을 공유하고 있기 때문에, 쓰레드간 통신을 위해 별도 기술을 사용할 필요는 없지만, 공유한 데이터를 읽고 쓰는 과정에서 동기화 이슈가 발생하여, 비정상 동작이 일어날 수 있습니다. 이에 반해 멀티 프로세스는 IPC 기술을 사용해서 프로세스간 통신을 해야 합니다. 만약 쓰레드 간 공유한 데이터를 읽기만 할 경우에는 동기화 이슈를 막기 위해 동기화 기술을 쓰지 않아도 되기 때문에 데이터 통신을 위한 추가적인 기능 구현이 필요 없으므로, 멀티 쓰레드를 사용하는 것이 좋습니다. 데이터를 읽고 쓰는 작업이 빈번하다면, 뮤텍스 등 동기화 기술을 많이 사용해야 하고, 이 경우 데드락과 같은 예기치 않은 비정상동작이 일어날 수 있으므로 멀티 프로세스를 고려해보는 것이 좋습니다.
💡비동기 방식은 언제나 멀티쓰레드로 동작하나요?
그렇지 않습니다. 싱글쓰레드로 비동기 방식을 구현할 수도 있습니다.
💡경쟁상태(Race Condition)이란 무엇인가요?
경쟁상태란 공유 자원에 서로 다른 프로세스나 쓰레드가 동시에 접근하는 상황을 의미합니다. 즉, 동시에 접근을 시도할 때 접근의 타이밍이나 순서등이 결괏값에 영향을 줄 수 있는 상태입니다. 서로 다른 프로세스나 쓰레드가 동시에 접근하는 것을 막으면 경쟁상태를 막을 수 있으므로 Mutex로 해결이 가능합니다. 그러나, Mutex는 데드락이라는 또 다른 문제의 원인이 될 수도 있습니다.
💡기아상태란 무엇인가요?
여러 프로세스가 부족한 자원을 점유하기 위해 경쟁할 때 발생하는 것으로 보통 우선순위가 낮은 프로세스가 계속해서 자원을 점유하지 못하는 상황을 말합니다. 오래 기다린 프로세스의 우선순위를 높여주는 방식 등으로 해결할 수 있습니다.
💡임계영역(Critical Section)이란 무엇인가요
공유 데이터에 접근할 수 있는 코드 영역을 말합니다.
💡쓰레드 동기화란 무엇이며 왜 사용해야하는지 설명해주세요.
쓰레드간 공유 데이터를 읽고 쓸 시에, 쓰레드간 실행 순서에 따라 공유한 데이터를 읽고 쓰는 작업이 누락될 수 있으며, 이로 인해 쓰레드의 비정상 동작을 야기할 수 있습니다. 쓰레드 동기화란 이러한 문제를 막기 위해 여러 쓰레드가 동시에 공유한 데이터를 읽고 쓰지 못하도록 하는 기술입니다.
💡뮤텍스와 세마포어의 차이점에 대해 간략히 설명해주세요.
쓰레드 동기화 기술로 뮤텍스는 쓰레드간 공유한 데이터 접근시 일정 순간에 하나의 쓰레드만 해당 데이터를 접근할 수 있도록 하는 기술이며, 세마포어는 일정 순간 세마포어에서 정한 동시 접근 쓰레드 수만큼만 공유한 데이터를 접근할 수 있도록 하는 기술입니다.
💡데드락에 대해 간략히 설명해주세요.
-
두 개 이상의 프로세스들이 서로가 가진 자원을 기다리며 중단된 상태를 교착상태(Deadlock)이라고 합니다.
-
데드락은 프로세스가 자원을 얻지 못하고 무한 대기 상태로 있는 경우를 의미하며, 교착상태라고도 불립니다.
데드락 발생 조건이 무엇인가요?
상호 배제, 점유 대기, 비선점, 순환대기의 네 가지 조건이 모두 만족하면 발생합니다.
데드락을 해결하기 위한 방법은?
예방하는 방법, 회피하는 방법, 탐지/복구하는 방법, 무시하는 방법이 있습니다.
- 예방: 교착상태 발생 조건 중 하나 이상을 제거함으로써 해결
- 회피: 교착상태가 발생하기 전에 예측하여 회피. 오버헤드가 커 현실성 없음.
- 탐지/복구: 자원을 얻기 위한 대기 그래프에 순환이 발생하면 교착상태라고 판단. 탐지가 되면 프로세스 종료 또는 자원 선점 방식으로 해결한다.
- 무시: 특별한 조치 취하지 않음.
현재 시스템에서는 어떤 방식으로 데드락을 해결할까?
Window나 Linux에서는 교착상태를 무시하는 방식으로 데드락을 해결하고 있습니다. 교착상태를 주기적으로 탐지하거나 예방하기 위해 필요한 오버헤드가 크기 때문에 이를 무시하는 것이 더 이득이라고 판단하여 이러한 방법을 채택한 것으로 알고 있습니다.
💡가상 메모리와 페이징 시스템에 대해 구체적으로 설명해주세요.
가상 메모리는 가상 주소와 물리 주소를 분리하여 실제 사용하는 메모리만 물리주소에 할당하는 기술입니다. 멀티태스킹을 지원하는 운영체제에서 여러 프로세스 실행시 실제 메모리보다 큰 메모리 영역을 제공하기 위해 주로 사용합니다. 페이징 시스템은 프로세스를 일정한 크기인 페이지로 잘라서 물리 주소와 가상 주소를 관리하는 방식입니다.
페이징은 왜 하는 걸까요?
페이징 없이 물리 메모리에 필요한 정보를 적재하다보면 외부 단편화가 발생할 수 있습니다. 이렇게 되면 비싼 메모리 공간을 효율적으로 사용할 수 없기 때문에 프로세스를 일정한 크기인 페이지 단위로 잘라 적재하고 관리하게 된 것입니다.
💡프로세스의 생성부터 소멸까지의 과정에 대해 설명해주세요.
새로운 프로세스가 부모 프로세스로부터 fork되어 생성됩니다. 해당 프로세스는 생성과 동시에 READY 상태가 되며 CPU에 의해 실행되기까지 대기합니다. 실행이 되면 RUNNING 상태가 되고, 자신에게 할당된 시간을 전부 사용하거나 IO작업 등으로 인해 BLOCKED 상태가 되는 경우 작업을 멈춥니다. 전자의 경우 다시 READY 상태가 되며, 후자의 경우 BLOCKED의 원인이 된 작업이 끝날 때까지 CPU에 의 해 실행될 수 없습니다. 해당 작업이 끝나면 다시 READY 상태가 됩니다. 마지막으로 프로세스가 종료되는 경우 BLOCKED 상태를 거쳐 EXIT 상태가 됩니다.
💡요구 페이징과 페이지 폴트에 대해 구체적으로 설명해주세요.
요구 페이징은 프로세스의 데이터를 사전에 메모리에 올리지 않고 프로세스 실행 중 데이터가 필요한 시점에 비로소 메모리에 올리는 기술입니다. 페이지 폴트는 물리 메모리에 없는 주소를 요청할 때 발생하는 현상이며, 일반적으로 이 때에는 페이지폴트 인터럽트가 발생한 후, 해당 페이지 정보를 물리 메모리에 적재합니다.
💡MMU와 TLB에 대해 설명해주세요.
MMU는 가상 주소와 물리 주소 매핑 동작을 관리하는 하드웨어이며 TLB는 가상주소를 물리주소로 변환하는 속도를 높이기 위해 사용하는 캐시입니다.
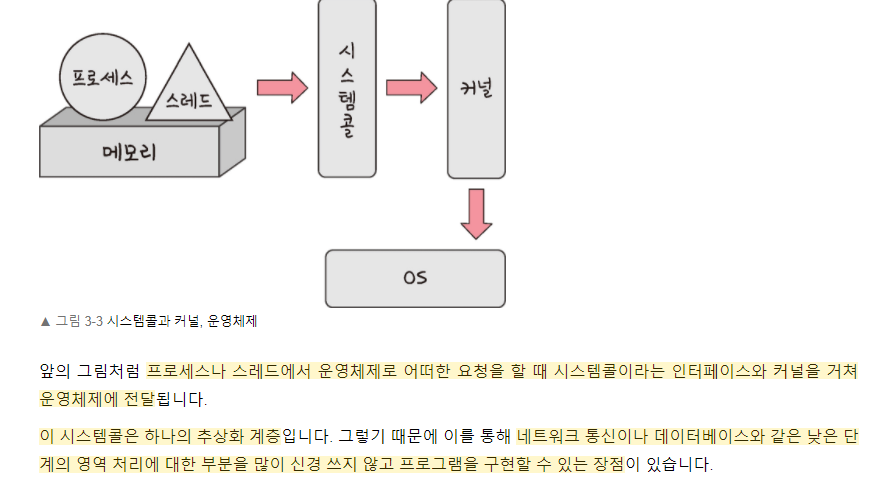
💡시스템콜에 대해 간결하게 설명해주세요
시스템콜이란, 운영체제 기능을 응용 프로그램이 사용할 수 있도록 운영 체제가 제공하는 인터페이스입니다. 커널 모드에서 실행되어 컴퓨터 자원에 대한 직접 접근을 차단할 수 있습니다.
💡인터럽트에 대해 간결하게 설명해주세요.
인터럽트란 CPU가 프로그램을 실행하고 있을 때, 입출력 하드웨어 등의 장치나 예외 상황이 발생하여 처리가 필요한 경우 CPU에 알려서 처리하는 기술입니다.
💡멀티태스킹에 대해 간결하게 설명해주세요.
단일 CPU에서 여러 응용프로그램이 동시에 실행되는 것처럼 보이도록 하는 스케쥴링 기법을 의미합니다.
💡메모리 계층 구조에 대해 간결히 설명해주세요.
메모리 계층 구조란 메모리를 필요에 따라 여러가지 종류로 나누어 사용하는 구조를 의미합니다. 보통 CPU를 기준으로 접근이 빠른 순서대로 표현하는 경우가 많습니다. 기본적인 저장매체를 기준으로 메모리 계층을 표현하면 레지스터, CPU 캐쉬, 메모리, SSD 또는 하드디스크 순으로 표현할 수 있습니다.
💡캐시란 무엇인가요?
데이터를 미리 복사해 놓는 임시 저장소이자 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리를 말합니다. 캐시에서 원하는 데이터를 찾았다면 캐시 히트라고 하고, 캐시에 없다면 주 메모리로 가서 데이터를 찾아오는 것을 캐시 미스라고 합니다.
💡캐시 매핑에 대해서 설명해주세요
직접매핑, 연관매핑, 직접연관매핑이 있습니다.
-
직접매핑(Direct Mapping)이란?
메인 메모리와 캐시를 똑같은 크기로 나누고 순서대로 매핑하는 것을 말합니다. 메모리가 1~100까지 있고 캐시가 1~10까지 있다면 1~10까지의 메모리는 캐시의 1에 위치하고 11~20까지의 메모리는 캐시의 2에 위치시키는 것입니다. 캐시 미스율이 높지만, 구현 방법이 간단합니다. -
연관매핑(Associative Mapping)이란?
순서를 일치시키지 않는 매핑 방법입니다. 필요한 메모리값이 캐시에 어디든 저장될 수 있습니다. 캐시 적중률이 높습니다. 캐시에 저장된 데이터를 찾는 과정은 느릴 수 있지만 캐시는 속도가 빠르기 때문에 적중률이 높은게 더 성능이 좋습니다. -
직접연관매핑(Set Associative Mapping)이란?
연관매핑과 직접매핑을 합쳐 놓은 방식입니다. 메모리가 1~100까지 있고 캐시가 1~10까지 있다면 캐시 1~5에는 1~50의 데이터를 무작위로 저장시키는 방법입니다.
💡가상 메모리에서 스와핑에 대해 아는 대로 설명해주세요.
가상 메모리에는 존재하지만 물리 메모리에는 현재 없는 데이터나 코드에 접근할 경우 페이지 폴트가 발생합니다. 이 때 메모리에서 당장 사용하지 않는 영역을 하드디스크로 옮기고 하드디스크의 일부분을 마치 메모리처럼 불러와 쓰는 것을 스와핑이라고 합니다.
페이지 폴트와 스와핑 과정에 대해 조금 더 자세히 설명해주세요.
CPU는 물리 메모리를 확인하여 해당 페이지가 없으면 인터럽트를 통해 운영체제에 알립니다. 운영체제는 CPU의 동작을 잠시 멈춥니다. 운영체제는 페이지테이블을 확인하여 가상 메모리에 페이지가 존재하는지 확인하고, 없으면 프로세스를 중단하고 현재 물리 메모리에 비어 있는 프레임이 있는지 찾습니다. 없다면 스와핑이 발동됩니다. 비어 있는 프레임에 해당 페이지를 로드하고 페이지테이블을 최신화합니다. 중단되었던 CPU를 다시 시작합니다.
알고 있는 페이지 교체 알고리즘이 있나요?
FIFO 알고리즘, LRU(Least Recently Used) 알고리즘, LFU(Least Frequently Used) 알고리즘 등이 있습니다.
💡메모리 할당기법에 대해서 설명해주세요
연속할당과 불연속할당 방법이 있습니다. 연속할당은 프로그램이 메모리에 올라갈때 통째로 메모리에 올라가는 방식입니다. 즉, 각각의 프로세스가 메모리의 연속적인 공간에 적재됩니다. 불연속할당은 프로그램을 구성하는 주소공간을 분할해서 메모리에 여러 영역에 분산되어 할당하는 방법입니다.
-
연속할당 종류
-
고정분할 방식
고정분할 방식은 메인 메모리를 고정된 크기의 파티션으로 미리 나눠놓고 그 분할된 파티션에 들어갈 수 있는 프로세스를 올리는 방식입니다.(프로세스의 메모리 전체를 올립니다.) 내부 단편화와 외부 단편화가 생길 수 있습니다. -
가변분할 방식
가변분할 방식은 메인 메모리를 미리 나누지 않고 프로그램이 실행될 때 마다 순서대로 메모리에 올려놓는 방법입니다. 처음에는 프로그램이 순서대로 메모리에 올라가지만 도중에 중단되는 프로그램들에 의해서 중간중간 Hole이 생깁니다. 이 Hole에 순서대로 다시 프로그램을 적재해야 합니다. 외부 단편화가 생길 수 있습니다.(내부 단편화는 X) 어떤 메모리 Hole 공간에 새로운 프로그램을 올릴것인가 결정하는 최초적합, 최적적합, 최악적합 알고리즘이 있습니다. 최초적합은 처음 발견되는 Hole에 할당하는방법입니다. 최적적합은 Hole을 다 탐색한 후 가장 잘 맞는 Hole에 할당하는 방법입니다. 최악적합은 가장 큰 Hole에 할당하는 방법입니다.
-
-
불연속할당 종류
-
페이징 기법
프로그램을 구성하는 주소 공간을 동일한 크기의 페이지 단위로 나누어 물리 메모리의 서로 다른 위치에 페이지들을 저장하는 기법입니다. 물리 메모리도 페이지 단위인 페이지 프레임으로 분할되고 그 공간에 페이지를 저장합니다. 내부단편화, 외부단편화가 발생하지 않습니다. 주소변환이 복잡해집니다. -
세그멘테이션 기법
프로세스를 의미 단위인 세그먼트로 분할해서 메모리에 할당하는 기법입니다. 의미 단위는 코드, 데이터, 스택, 힙 등이 될 수도 있고, 코드에서 함수 단위가 될 수도 있습니다. 외부단편화가 발생하며, Hole을 할당하는 알고리즘이 사용됩니다. -
페이지드 세그멘테이션 기법
세그먼트 하나를 다수의 페이지로 구성하는 방식입니다.
-
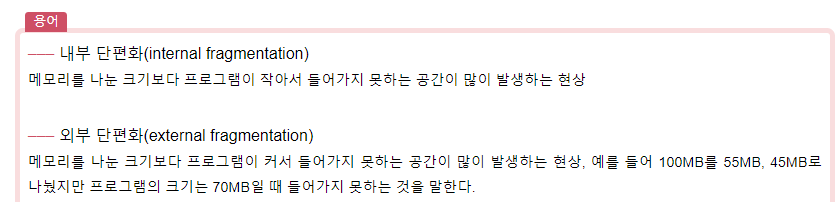
💡내부 단편화, 외부 단편화에 대해 설명해주세요.
내부 단편화는 메모리 상에 사용하는 공간들 사이에 남는 공간이 있는 경우를 의미합니다. 반면에 외부 단편화는 메모리 상에 남아 있는 총 공간은 할당 요청한 공간보다 크지만, 남아 있는 공간이 연속적이지 않아, 할당할 수 없는 경우를 의미합니다.
💡CPU 스케쥴링 알고리즘에는 무엇이 있나요?
FCFS, SJF, 우선순위, 라운드로빈(RR), 다단계 큐 등이 있습니다. FCFS는 가장 먼저 온 것을 가장 먼저 처리하는 알고리즘이고, SJF는 가장 짧은 작업을 가장 먼저 처리하는 알고리즘입니다.
우선순위 알고리즘은 우선순위를 기반으로 프로세스를 실행하는 알고리즘입니다. SJF 스케쥴링에서 발생하던 ‘긴 시간을 가진 프로세스가 실행되지 않는 현상’을 해결하기 위해 오래된 작업일 수록 우선순위를 높이는 방식 등이 대표적입니다.
라운드로빈은 우선순위 스케쥴링의 일종으로 프로세스에 동일한 할당 시간을 주고 그 시간 안에 끝나지 않으면 준비 큐의 뒤로 가는 알고리즘입니다. 전체 작업 시간은 길어지지만 평균 응답 시간은 짧아진다는 특징이 있습니다.
다단계 큐는 우선순위에 따른 준비 큐(Ready Queue)를 여러 개 사용하고, 큐 마다 다른 스케줄링 알고리즘을 적용한 방식을 말합니다.
