
Abstract
- 대규모 언어 모델인 GPT-3는 다양한 NLP 작업에서 우수한 성능을 보여줌
- GPT-3는 소수의 샘플을 통해 새로운 언어 작업을 수행할 수 있음
- 이 모델은 번역, 질문 응답, 클로즈 작업 등 다양한 데이터셋에서 강력한 성능을 발휘함
- 도메인 적응이나 즉석 추론을 필요로 하는 작업에서도 성능을 나타냄
- 일부 데이터셋에서는 GPT-3의 소수 샘플 학습이 여전히 어려움을 겪음
- GPT-3는 사람 평가자가 구별하기 어려운 뉴스 기사 샘플을 생성할 수 있음
- 이러한 결과와 GPT-3의 일반적인 영향에 대한 사회적 영향을 논의함
1 Introduction
- pre-trained LM이 성장함.
- 주요한 문제는 task-agnostic함.
- task-specific dataset, fine-tuning이 필요함
- 매 새로운 task마다 큰 dataset을 필요로 하는 것은 비효율적임
- training data의 가짜 연관성을 더 많이 사용하게 됨.
- 너무 많이 training distribution에 특정됨. 일반화 잘 하지 못한다.
- 인간은 그렇게 큰 surpervised dataset을 필요하지 않는다.
- zero-shot transfer가 필요하다.
- training time에 넓은 pattern recognition을 습득하고
- inference time에 사용한다.
- 이러한 것을 in-context learning이라고 함.
2 Approach
- Fint-Tuning
- Few-Shot
- One-Shot
- Zero-Shot
2.1 Model and Architectures
- GPT-2 구조.
- initialization 수정
- pre-normalization
- reversible tokenization
- 다양한 model size ⇒ 제일 큰 175B
3 Results
- 8개의 model들의 training curves
- 6개의 더 작은 model도 추가함
- power-law에 따라 성능이 향상함.
- 작은 이탈만 보임
- CE Loss만 보는게 잘못된거 아님? ⇒ 하지만 CE loss를 줄이는게 성능 향상에 일관 된다.
- 3.1에서 traditional language modeling task, 그거와 비슷한 것을 실험함.
- 3.2에서 closed book answering task
- 3.3 번역
- 3.4 Winograd Schema-like task
- 3.5 commonsense reasoning 또는 question answering을 평가하는 데이터셋
- 3.6 reading comprehension task
- 3.7 SuperGLUE benchmark suite
- 3.8 NLI
- 3.9 in-context learning abilities 증명
3.6 Reading Comprehension
-
reading comprehension (독해 능력)
-
5개의 datasets을 사용함
- abstractive, multiple choice, span based answer formats이 dialog와 단일 질문에 포함됨
-
다양한 정답 형식에도 GPT-3는 성능이 잘 나왔다.
-
CoQA에서 제일 잘 했다
> **CoQA** contains 127,000+ questions with answers collected from 8000+ conversations. Each conversation is collected by pairing two crowdworkers to chat about a passage in the form of questions and answers. The unique features of CoQA include 1) the questions are conversational; 2) the answers can be free-form text; 3) each answer also comes with an evidence subsequence highlighted in the passage; and 4) the passages are collected from seven diverse domains. CoQA has a lot of challenging phenomena not present in existing reading comprehension datasets, e.g., coreference and pragmatic reasoning. >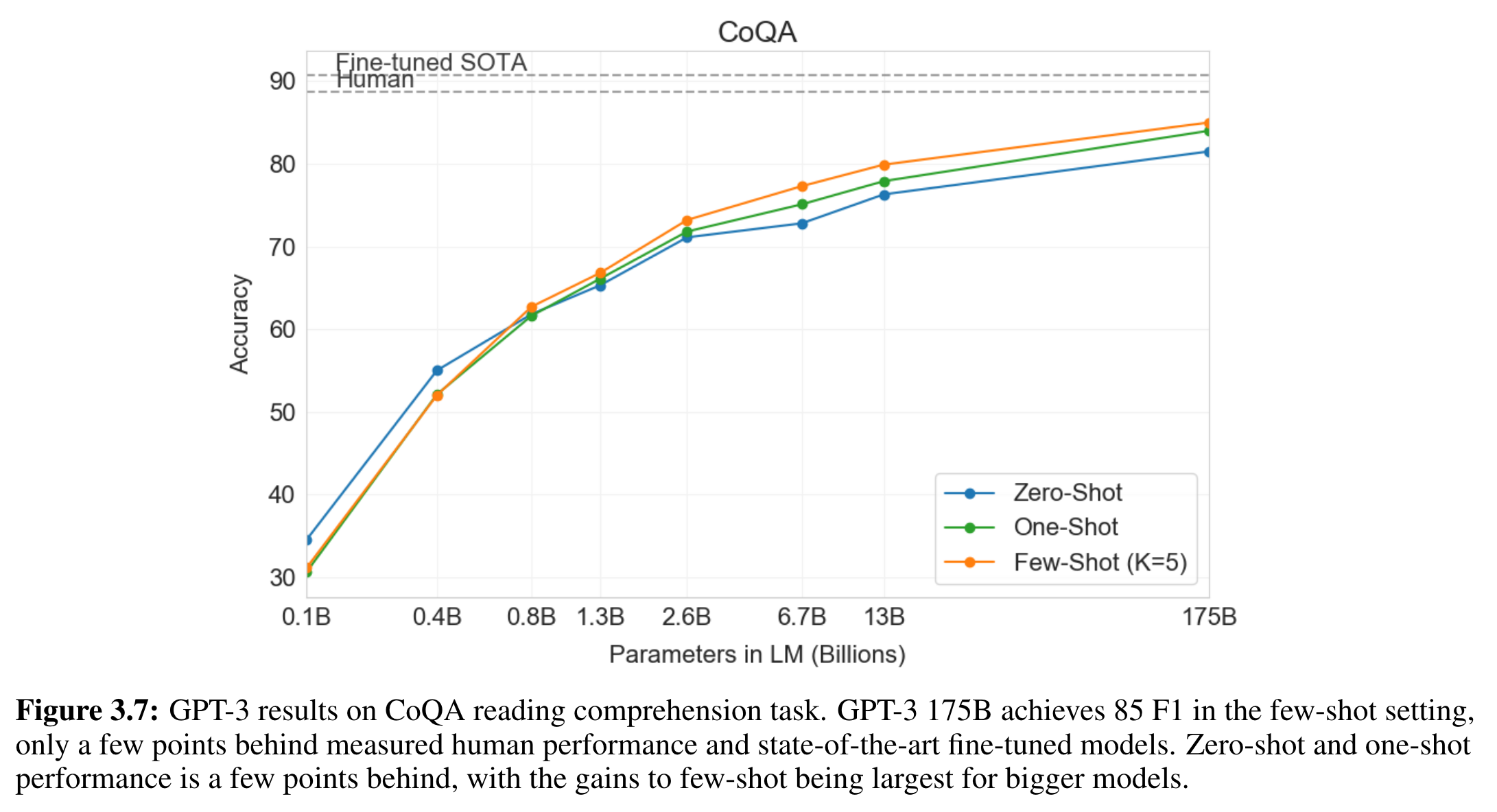
- 85 F1 Score 달성. 인간 수준의 성능, SOTA에 근접. - a free-form conversational dataset - zero-shot, one-shot은 몇 포인트 뒤쳐짐 -
QuAC에서 제일 별로였다.
Question Answering in Context is a dataset for modeling, understanding, and participating in information seeking dialog. Data instances consist of an interactive dialog between two crowd workers: (1) a student who poses a sequence of freeform questions to learn as much as possible about a hidden Wikipedia text, and (2) a teacher who answers the questions by providing short excerpts (spans) from the text. QuAC introduces challenges not found in existing machine comprehension datasets: its questions are often more open-ended, unanswerable, or only meaningful within the dialog context.
- 구조화된 대화 활동과 선생-학생 사이 상호작용의 answer 범위를 결정하는 문제
-
DROP
- discreate reasoning과 numberacy를 평가한다
- BERT baseline은 이겼다.
- 인간 수준과 symbolic systems을 사용한 NN에는 졌다.
-
SQuAD 2.0
- few-shot learning 능력을 잘 보여줌.
- zero-shot setting에 비해 10 F1이 증가함
- 기존 연구의 최고로 fine-tuned 모델을 이김
-
RACE
- 중고등 학교 영어 시험에서 다중 선택 문제.
- 상대적으로 약함. contextual representation을 사용하는 초기 연구 수준.
3.7 SuperGLUE
- NLP task의 결과들을 모으고 BERT, RoBERTa 같은 유명한 모델과 systematic하게 비교하기 위해서, GPT-3를 standarized collection of datasets에 대해 평가해 보았다.
- SuperGLUE benchmark
- GPT-3의 test-set 성능은 다음 표(3.8)와 같다.
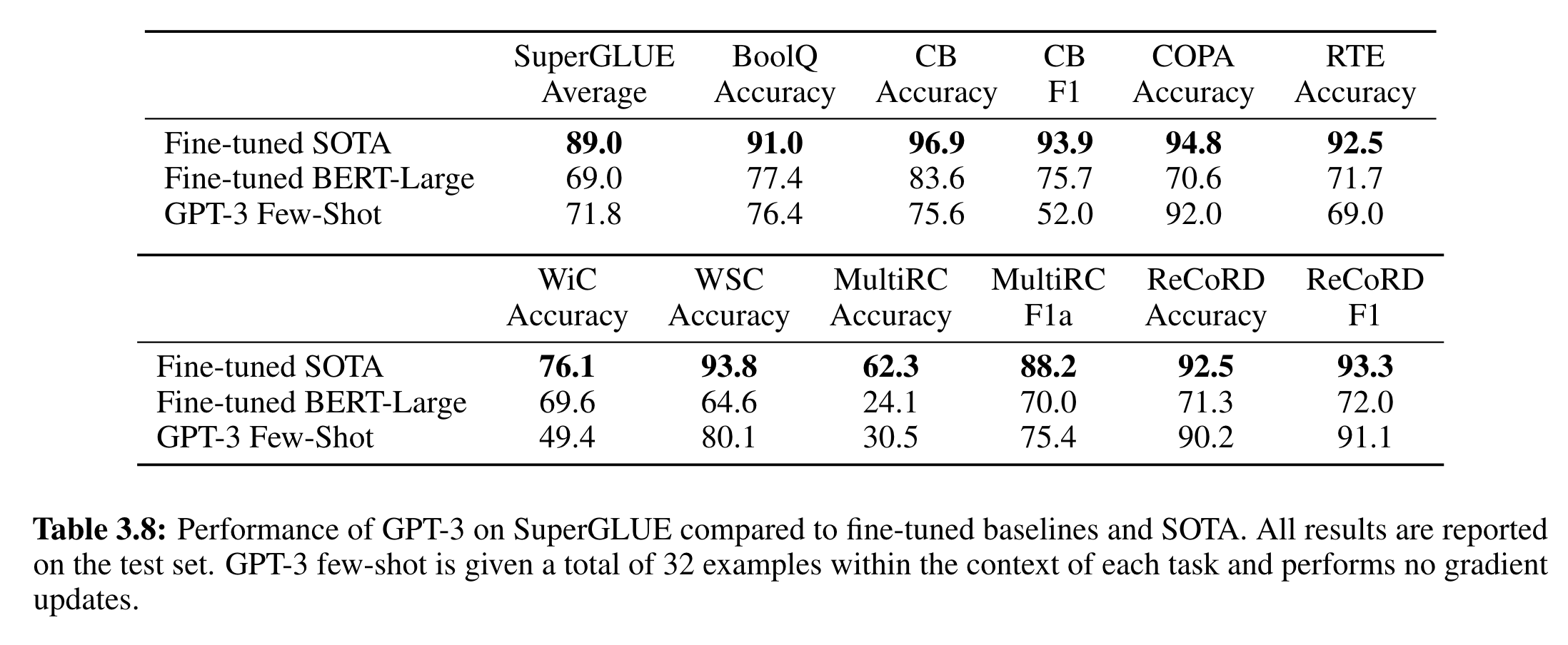
- GPT-3의 성능은 task에 따라 다양했다.
-
COPA와 ReCoRD에서는 유사 SOTA (one-shot, few-shot 에서)
The Choice Of Plausible Alternatives (COPA) evaluation provides researchers with a tool for assessing progress in open-domain commonsense causal reasoning. COPA consists of 1000 questions, split equally into development and test sets of 500 questions each. Each question is composed of a premise and two alternatives, where the task is to select the alternative that more plausibly has a causal relation with the premise. The correct alternative is randomized so that the expected performance of randomly guessing is 50%. More details about the creation of the COPA evaluation are described in the following paper:
- 1등은 T5
-
WSC에서도 좋은 성능
The Winograd Schema Challenge was introduced both as an alternative to the Turing Test and as a test of a system’s ability to do commonsense reasoning. A Winograd schema is a pair of sentences differing in one or two words with a highly ambiguous pronoun, resolved differently in the two sentences, that appears to require commonsense knowledge to be resolved correctly. The examples were designed to be easily solvable by humans but difficult for machines, in principle requiring a deep understanding of the content of the text and the situation it describes.
-
나머지 BoolA, MultiRC, RTE에서도 성능이 좋았다.
- 대략 fine-tuned BERT-Large 정도
-
CB에서는 별로
-
- WiC는 특히 약한 부분
- 왜 그런지는 ANLI benchmark에서 토의할 것.
- 두 setences 또는 snippets을 비교하는 task에서 약한 모습을 보임.
- word가 다른 문장에서 같은 뜻으로 쓰이거나
- 하나가 paraphrase이거나
- 암묵적으로 표현하거나
- RTE, CB에서 성능이 낮은 설명도 된다.
- 이러한 약점에도 불구하고, GPT-3은 여전히 fine-tuned BERT-Large 보다 4가지 항목에서 강함.
- 2 항목은 T5 SOTA와 유사함
- model size와 context에 포함하는 예시의 수가 증가하면서 성능이 증가함 ⇒ in-context learning
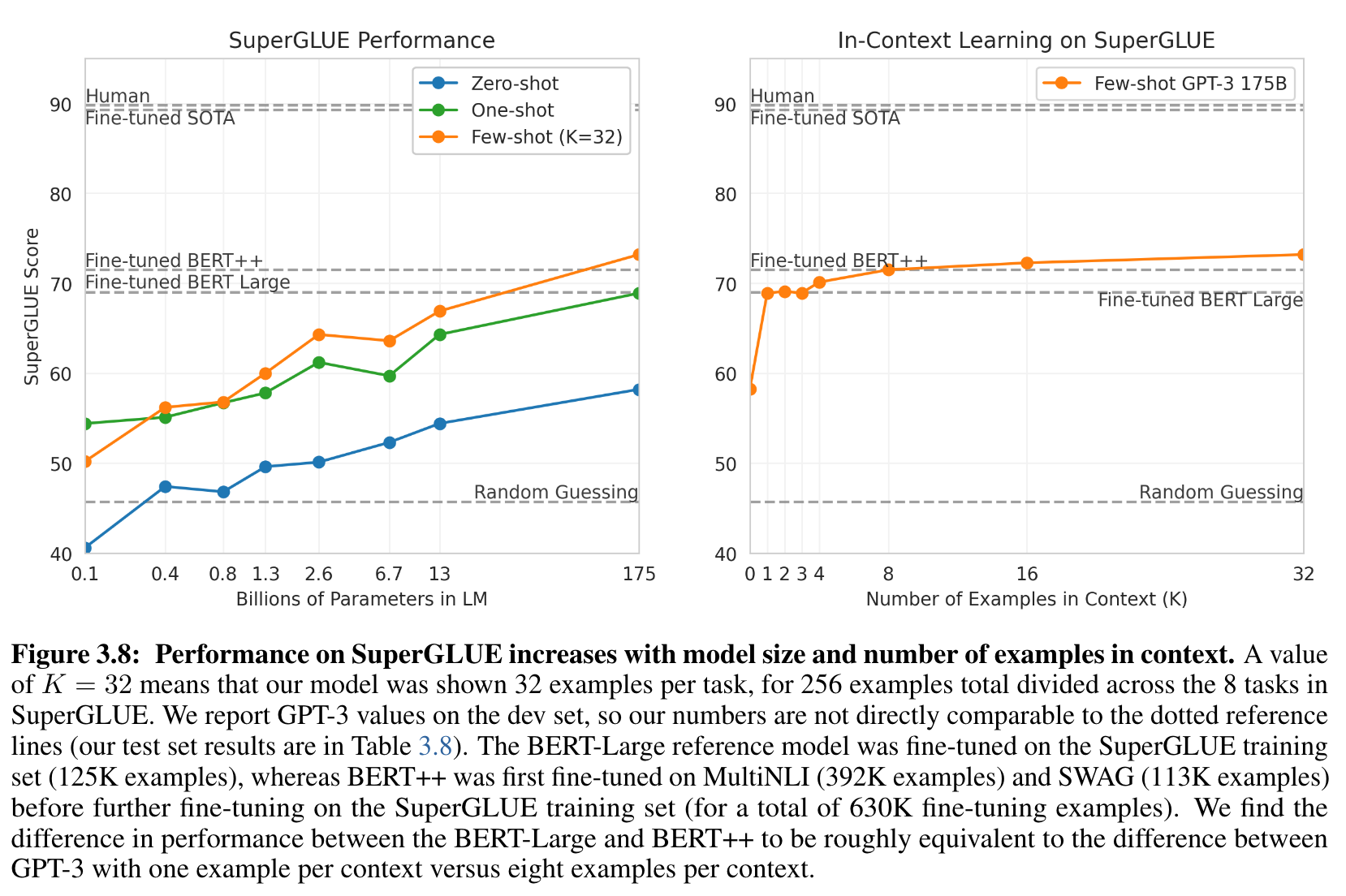
- K를 최대 32까지 늘림.
- 전반적으로 최소 8개의 예제가 있어야 잘 하더라.3.8 NLI
- Natural Language Inference ⇒ 두 sentence 사이의 관계 이해하는 능력
- 보통 두 문장이 있을 때 다음을 classification 한다.
- 논리적으로 유도 되는지
- 첫 문장과 모순되는지
- neutral 할 수 있는지
- SuperGLUE에 NLI, RTE가 이러한 task의 binary version이다. (neutral 빠짐)
- 보통 두 문장이 있을 때 다음을 classification 한다.
- RTE에서는 가장 큰 version이 56%, 랜덤으로 찍는 것보다 조금 더 나았다. 하지만 Few-Shot setting에서는 fine-tuned BERT-Large와 비슷했다.
A Textual Entailment Recognition (RTE) Task is an inference task of determining a inferential relationship between natural language hypothesis and premise.
- Adversarial Natural Language Inference dataset.
- 3 round의 일부러 어려운 자연어 추론 문제들 모음.
- RTE와 유사하게, GPT-3 보다 작은 모델들은 랜덤한 정도. few-shot setting 에서도.
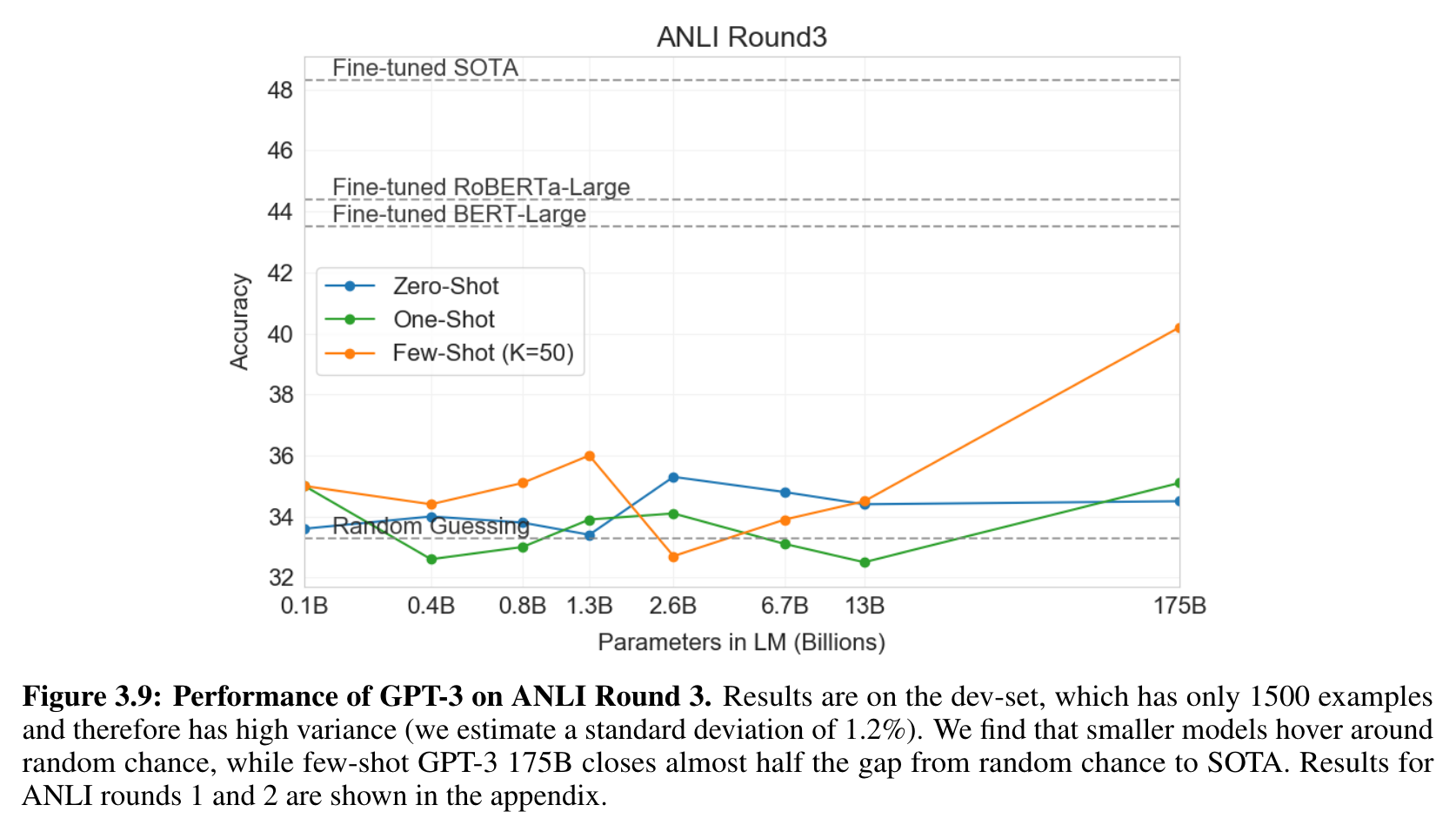
- 1500개의 예시 밖에 없어서 variance가 크다. 모델이 작으면 거의 random. 하지만 175B GPT-3는 SOTA의 절반 정도 따라감.
- 하지만 GPT-3는 Round3에서 잘 하게 됨.
- 거대 Language Model에게도 여전히 어려운 일이다!
3.9 Synthetic and Qualitative Tasks
- GPT-3의 성능을 증명하는 방식은 단순한 즉석 computational reasoning을 요구하는 task를 해 보는 것. training에서는 발생하지 않는 새로운 pattern을 인식하고, 일반적이지 않은 task에 빠르게 적응함.
- arithmetic
- rearranging 또는 unscrambling을 포함하는 task
- SAT 스타일의 유추 문제
- qualitative tasks
- sentence에서 새로운 words 쓰기
- English Grammar 교정하기
- news article 만들기
3.9.1 Arithmetic
- GPT-3에게 단순한 사칙 연산을 자연어로 물어보는 test를 만들었다.
- 2 digit addition (2D+) ⇒ “Q: What is 48 plus 76? A: 124.”
- 2 digit subtraction (2D-) ⇒ “Q: What is 34 minus 53? A: -19”
- 3,4,5 digit addition / subtraction
- 2 digit multiplication (2Dx)
- One-digit composited (1DC) ⇒ 6+(4*8) : 괄호 풀기
- 10개의 task에서 대체로 잘 대답했다.
- 숫자가 작으면 매우 잘 했다. digit이 커질 수록 성능은 감소함.
- 곱하기는 잘 못함.
- 괄호 묶는 것도 잘 못함.
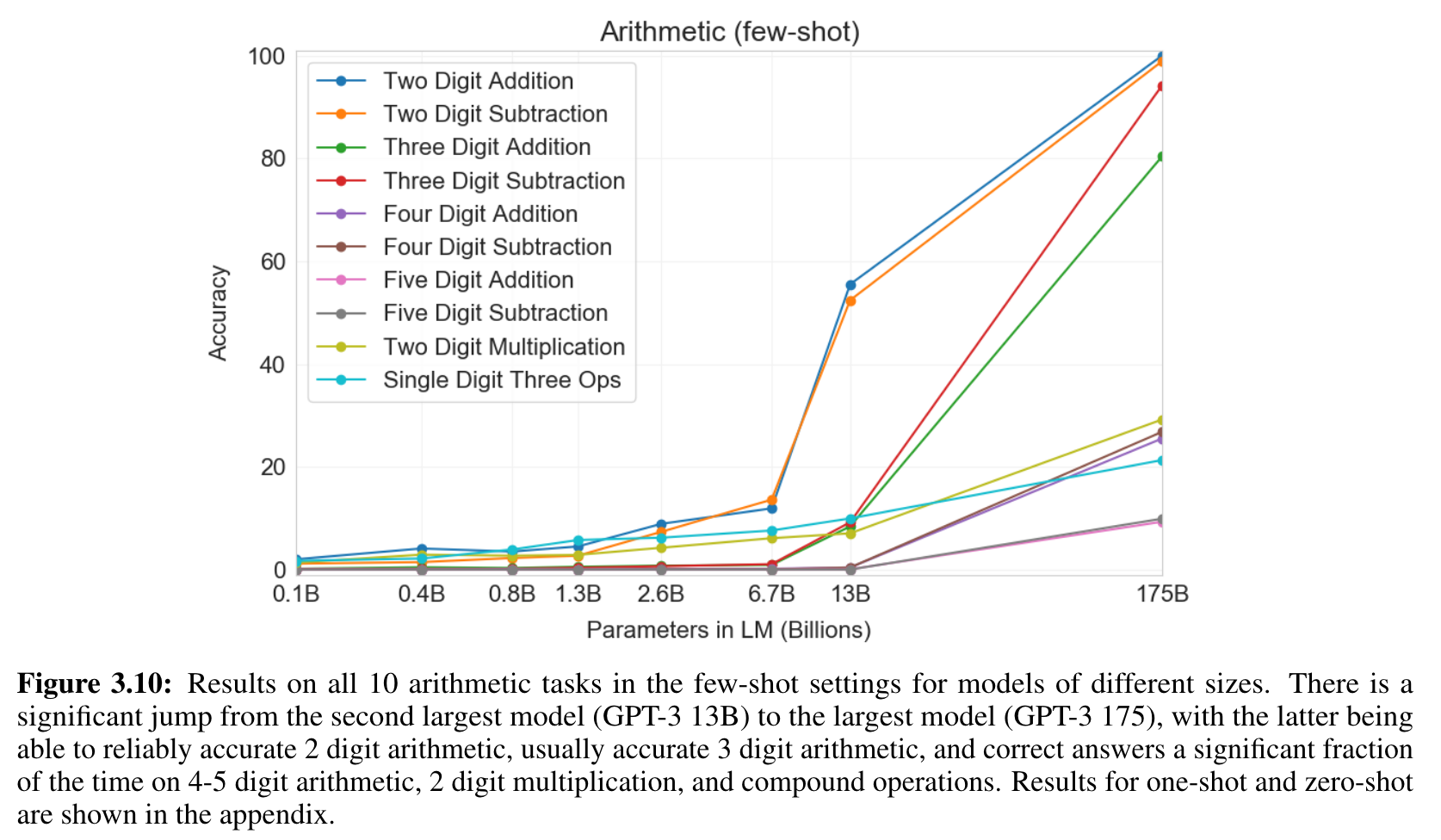
- 13B → 175B에서 급격한 점프가 있었다.
- 작은 model은 이러한 tasks를 잘 하지 못한다.
- one-shot, zero-shot은 성능이 떨어진다.
- adaptation이 중요하기 때문에
- 그럼에도, 작은 모델들의 few-shot보다 성능이 높다.
3.9.2 Word Scrambling and Manipulation Tasks
- 5개의 “글자 조정” tasks를 만들었다.
- Cycle letters in word (CL) : “lyinevitab” ⇒ “inevitably”
- Anagrams of all but first and last characters : “criroptuon” ⇒ “corruption”
- Anagrams of all but first and last 2 characters : “opoepnnt” ⇒ “opponent”
- Random insertion in word : “s.u!c/c!e.s s i/o/n” ⇒ “succession”
- Reversed words : “stcejbo” ⇒ “objects”
- 각각 10,000개 정도의 예시를 만듦.
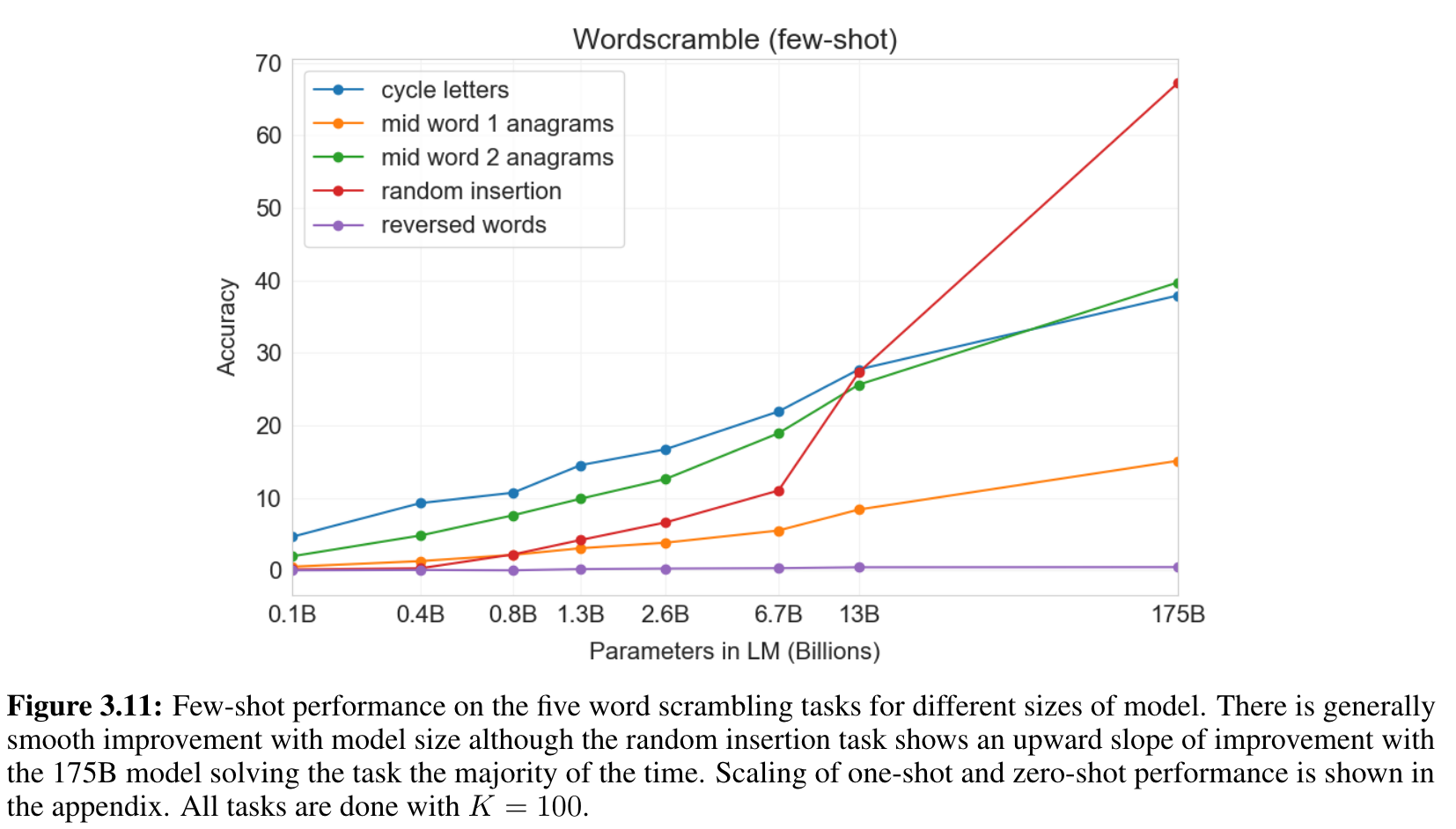
- 일반적으로 부드러운 성능 증가. K=100개 넣어줌.
- 역시 모델이 커져야 잘 하더라.
- one-shot, zero-shot 일때는 잘 하지 못함 ⇒ test time에 이러한 task를 배운다.
- pre-training data에는 이런 데이터가 적으니까 (하지만 우리도 확신은 못 함)
- in-context learning curves를 그려서 성능을 평가할 수 있을 것.
- in-context 예시를 몇 개를 넣냐에 따라서.
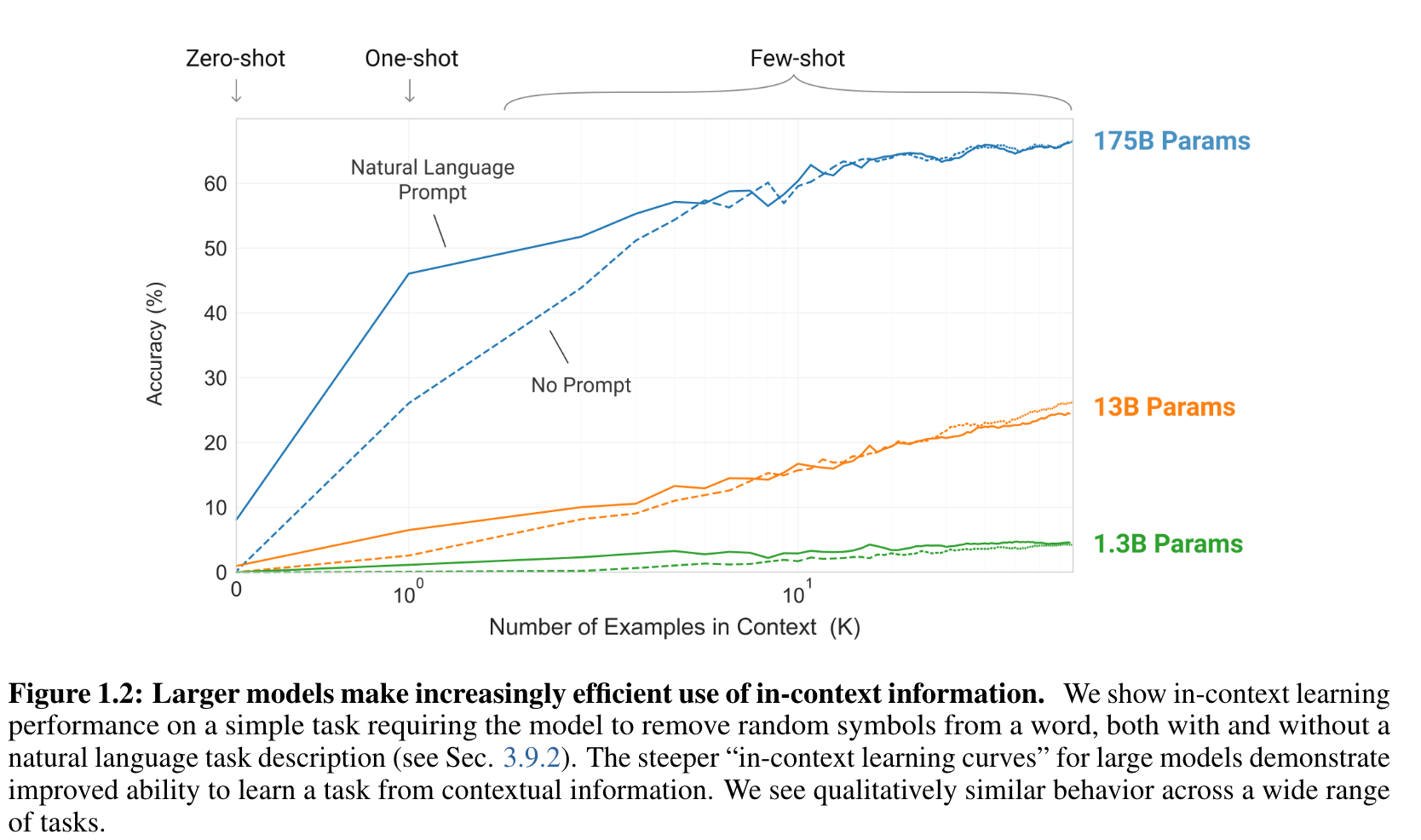
- 이 그림처럼. K개를 몇개를 주냐에 따라서 성능이 어떻게 변화하는가.- BPE encoding에 대해서 많이 작동됨. 그리고 bijective 하지 않은 task임. 하여튼 정말 non-trivial 한 pattern-matching and computation을 요구한다.
3.9.3 SAT Analogies
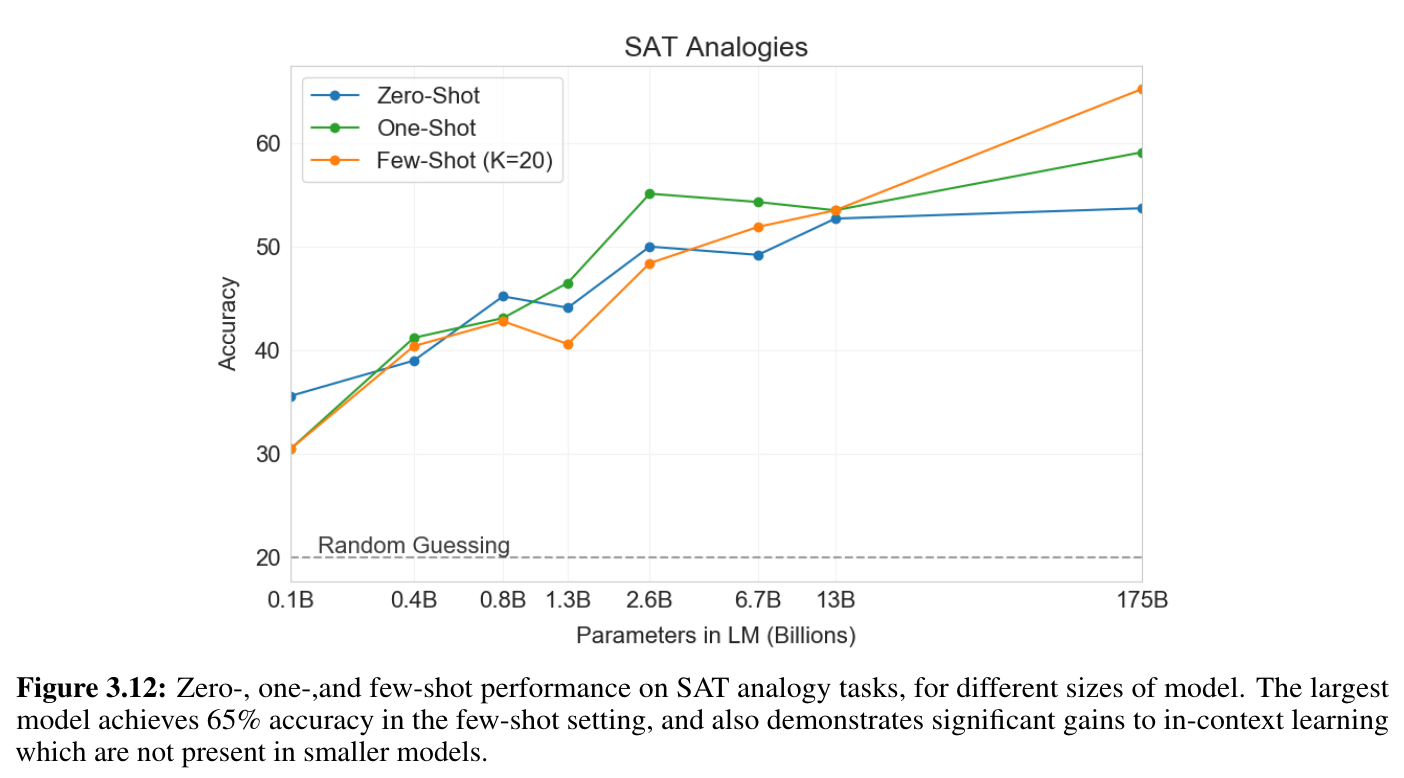
- model이 크면 in-context learning도 잘함
- zero < one < few shot 순으로 성능 향상
- 평균적으로 사람은 57% (random guess 20%)
- 모델이 커질 수록 성능 향상. (13B 보다 175B가 10% 성능 향상)
3.9.4 News Article Generation
- 학습이 news article에 대해 되어 있지 않다.
- tweets 형식을 더 잘 만듦
- in-context로 넣어서 3개의 few-shot learning을 넣어줌
- 사람이 진짜 기사와 구별하는 것을 measure함
- Model이 커질수록 50% (random guess)에 가까워졌다.
3.9.5 Learning and Using Novel Words
- 처음 보는 단어를 던져주고 문장을 만들어 보기
- 상당히 잘 한다!
3.9.6 Corrrecting English Grammar

Prompt : "Poor English Input: \n Good English Output: ".
4 Measuring and Preventing Memorization Of Benchmarks
- 우리 Data들이 인터넷에서 왔음. benchmark test set에 학습되었을 수도 있다.
- 인터넷 규모의 데이터셋에서 test 오염원을 찾아내는건 새로운 연구의 지평이다.
- 점점 더 많은 데이터에 대해서 학습하다 보면 이러한 고려가 더 중요해 질 것.
- 그냥 가설이 아니다. 이전에도 그래서 삭제한 적이 있었음. GPT-2에서도.
- 작은 부분만 차지하고 전체 성능 보고에 크게 영향을 안 준다 해도 중요하다.
- GPT-3는 조금 다른 영역에서 작동한다. 반면, GPT-2에서 사용된 것 보다 dataset과 model size가 크다.
- 잠재적인 오염과 기억의 가능성이 더 높다.
- 반면, 대용량의 data 덕분에, 175B나 되는 model이 overfit 하지 않는다.
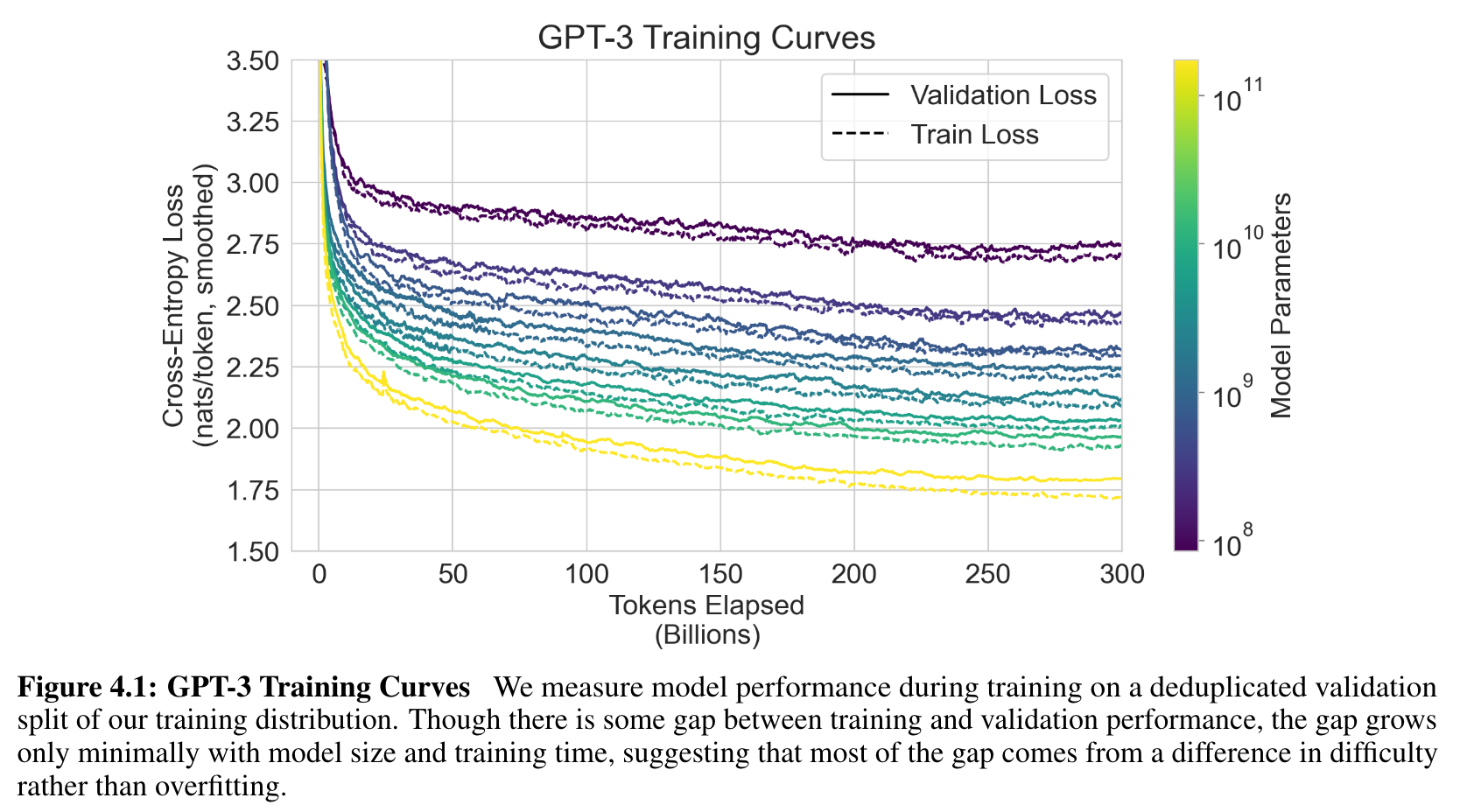
- 대부분의 성능 향상이 model size, training time에 비례함. overfitting이 아니라 문제의 난이도 차이에 의해 gap이 생긴다.
- 중복이 제거된 validation set과의 비교를 해 봤을 때 성능 차이는 있지만 크지는 않다.
- 중복이 빈번하게 일어나지만, 그렇게 크게 두려워 할 필요는 없다.- 처음에는 적극적으로 중복을 제거하려고 했음. 하지만 bug 발생. training cost의 관점에서 불가능 했다.
- 각각의 benchmark에서 ‘clean version’을 만들었다.
- 그리고 원래 점수랑 비교해봄.
- 큰 차이가 없다.
- 오염이 정말 존재하더라도, 큰 영향을 주진 않는다.
- 만약 낮았다면 오염이 정말 존재 했을 것.
- 잠재적인 오염이 높더라도, 오염과 성능 사이의 연관 관계를 찾지 못했다.
- 오염의 위험을 너무 과대 평가한 건 아닌가.
- 이제 두 가지 경우를 고려해 볼 것.
- cleaned version보다 상당히 성능이 안 좋은 경우
- 잠재적 오염이 매우 높아, 성능 차이를 측정하기 어려운 경우.
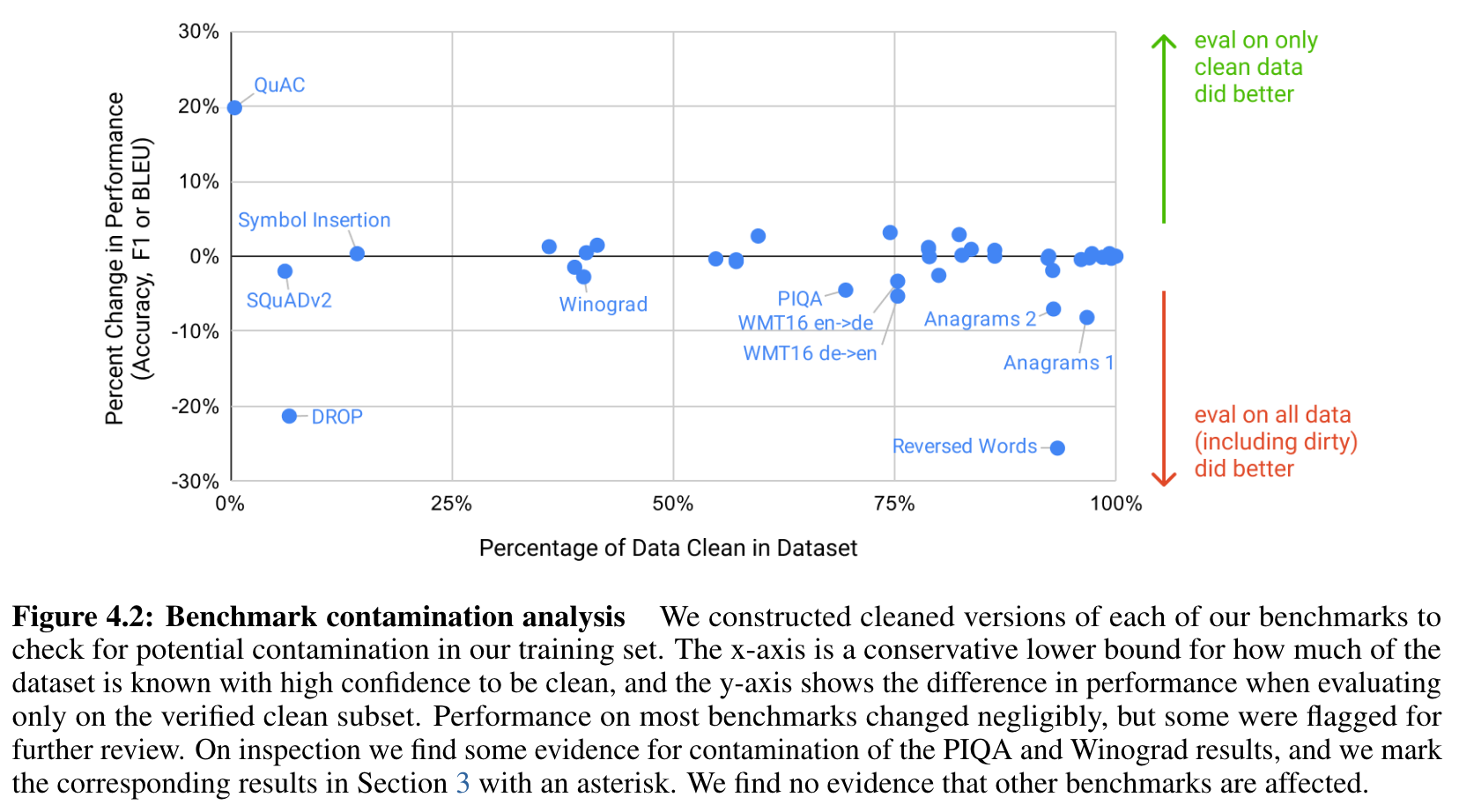
- x축 : 데이터가 얼마나 오염됨? y축 : 밑으로 가면 clean set에서 성능이 감소함.
- PIQA, Winograd는 의심스럽다.
- Reading Comprehension (QuAC, SQuADv2, DROP)
- 90% 이상이 오염되고, DROP은 contaminated 되었을 수도 있다 의심.
- 일일히 감시해 봤는데, source text는 training data에 있었지만, question/answer pairs는 그러지 않았다. 즉, 모델이 오직 배경 정보만 습득했지 특정한 질문에 대해서는 배우지 않았다.
- 너무 많은 데이터가 오염되어서 평가가 힘들지 않나?
- PIQA
- 29%가 오염, 약 3% 성능 감소
- 인터넷에 정답이 올라가 있어서
- 25x 작은 model에서 비슷한 감소가 발생함 (memorization을 잘 못함)
- 이거 memorization이 아니라 statistical bias 아님?
- 그러나 가설일 뿐 의심스러운 결과이다.
- 29%가 오염, 약 3% 성능 감소
- Winograd
- 45% 오염, 2.6% 감소
- 132 Winograd가 training set에서 나타남.
- 성능 감소는 적지만 의심스러운 결과로 기록함
- 오염이 높다고 생각했지만, 성능 영향은 0에 가까움.
- 실제 성능에 얼마나 영향을 미치는지 검사해서 알 수 있음
- LAMBADA에 대해서는 정말 오염이 있는 듯.
- 작긴 함
- 0.5% 감소?
- 엄밀히 말하면 빈칸 채우기는 외우기 제일 쉽다.
- 그럼에도 불구하고 LAMBADA 성능이 많이 늘어서, 의심되는 오염이 있으리라 기록함
- 오염 분석의 한계
- clean subset은 원래 dataset과 같은 distribution에서 생성됨.
- memorization 하는게 결과를 부풀릴 수도 있다.
- 하지만 clean subset을 만드는 과정이 task를 더 쉽게 만드는 statistical bias에 의해 정확하게 대응된다.
- 하지만 성능에 따른 큰 영향이 없다는 것을 보였다.
- 최선을 다 해 보긴 했습니다…
- 이러한 이슈는 앞으로도 중요할 것입니다!
5 Limitations
- GPT-3는 여전히 많은 NLP tasks에서 약점을 가지고 있다.
- text synthesis 등에서 그렇다.
- 특히 “common sense physics”에 약하다.
- benchmark에 따라 GPT-3의 in-context learning 성능이 다르다.
- GPT-3에는 이러한 문제를 설명할 수 있는 구조 및 알고리즘의 한계가 있다.
- autoregressive model. in-context 학습에 중점을 주었다.
- autoregressive : 자기 자신의 token을 예측하는 방식의 학습
- bidirectional : 왼쪽 오른쪽의 context를 모두 이용하는 방식
- bidirectional로부터 얻는 이익을 포기하게 된다.
- 빈칸 채우기 등
- bidirectional model이 GPT-3보다 fine-tuning에 더 강할 것이다.
- GPT-3 규모의 bidirection model을 만들거나, few / zero-shot으로 bidirectional model을 만드는 것이 유망한 연구가 될 것.
- autoregressive model. in-context 학습에 중점을 주었다.
- 조금 더 근본적인 한계. pre-training의 한계에 부딪힐 수 있다.
- 모든 token에 동등한 가중치를 부여. 무엇이 가장 중요하고 아닌지를 모른다.
- 궁극적인 LM은 단순히 예측하는 것보다 목표 지향적인 행동을 취하는 것이 더 필요하다.
- Video, 실제 물리적 상호 작용 같은 다른 경험 영역에 기반하지 않아 세계에 대한 Context가 부족하다.
- pure slelf-supervised prediction은 한계에 부딪힐 가능성이 있고, 다른 방식이 필요할 수 있다.
- object function from humans
- fine-tuning with reinforcement learning
- 세계에 대한 grounding을 제공하기 위한 이미지 등 다른 modality와 결합
- Language Model의 공통적인 한계는 sample efficiency가 낮다.
- GPT-3는 인간이 평생 동안 보는 것보다 더 많은 data를 pre-training 한다.
- GPT-3가 few-shot learning을 할 때 정말로 새로운 tasks를 inference time에 “처음부터” 새롭게 배우는가, training 중에 학습한 것으로 인식하는가? 불확실하다.
- 여라 spectrum이 있을 수 있다.
- synthesis 잡업은 새로운 것으로 인식될 수 있고
- 번역 등은 pre-training 동안 학습되었을 것이다.
- 궁극적으로, 인간이 처음부터 배우는 것과 이전 시연에서 배우는 것이 무엇인지조차 명확하지 않다.
- pre-training 때 다양한 시연을 구성하고, test 할 때 식별하는 것도 language model의 발전이지만, 그럼에도 불구하고 few-shot learning이 어떻게 작동하는지 정확하게 이해하는 것은 미래 연구를 위한 중요한 미개척 방향이다.
- 여라 spectrum이 있을 수 있다.
- GPT-3 같이 대형 model은 비용이 많이 들고 불편하다.
- distillation이 해법이 될 수 있다.
- GPT-3는 다양한 task에 최적화 되어 있으니, 특정 작업에만 distiliation 하는 것이 가능할 것이다.
- 아직 수천억 parameter 단위의 distiliation은 시도되지 않았다.
- GPT-3는 Deep Learning systems들의 공통적인 한계를 포함한다.
- 결정이 쉽게 해석되지 않고,
- 새로운 입력에 대한 예측에 대해 잘 계산되지 않고
- train data의 bias를 가진다
- 이 issue는 사회적인 관점에서 많이 논의된다.
GPT-3와 우리의 분석은 많은 한계를 가진다. 밑은 이러한 것의 일부를 묘사하고 미래 작업에 대한 방향을 제시한다.
첫째로, GPT-3의 양적, 질적인 향상에도 불구하고, 직계 조상인 GPT-2와 비교해 봤을 때, 이것은 여전히 text 합성과 여러 NLP tasks에서 주목할만한 약점을 가지고 있다. text synthesis에서, 전반적인 질은 높지만, GPT-3 samples은 여전히 때때로 document level에서 의미론적으로 자기 자신이 반복되고, 충분히 긴 passage에서 일관성을 잃고, 자기 스스로 모순되고, 그리고 때때로 따르지 않는 문장 또는 단락을 포함한다. GPT-3의 한계와 text synthesis의 강점을 제공하는데 도움을 주기 위해 우리는 500개의 무조건 적인 sample을 수집하여 공개할 것이다. discrete language task의 영역에서, 비공식적으로 GPT-3가 “common sense physics”에 특별히 약하다는 것을 봤다, 비록 일부 dataset에서 잘 함에도 불구하고. 특히 GPT-3는 “내가 냉장고에 치즈를 넣으면, 녹을까?” 같은 질문에 약하다. 질적으로, GPT-3의 in-context learning 성능은 일련의 벤치마크에서 상당한 차이가 있다, Section 3에서 설명했듯, 그리고 특히 reading comprehension task의 일부분 뿐만 아니라 두 단어가 문장에서 같은 방식으로 사용되었다던가, 한 단어가 다른 하나를 imply 한다던가 하는 유형의 질문에서 on-shot 또는 일부 few-shot을 평가할 때 기회보다 조금 낮다. 이것은 특히 GPT-3의 다양한 task에서 강력한 few-shot performance를 고려할 때 두드러진다.
GPT-3에는 위의 문제 중 일부를 설명할 수 있는 몇 가지 구조적 및 알고리즘적 한계가 있습니다. 이 모델 클래스를 사용하면 sample 및 computation likelihoods 모두에 간단하기 때문에 autoregressive language model에서 in-context 학습 행동을 탐색하는 데 중점을 두었습니다. 결과적으로 우리의 실험은 양방향 아키텍처 또는 노이즈 제거와 같은 다른 훈련 목표를 포함하지 않습니다. 이는 표준 언어 모델[RSR+19]에 비해 이러한 접근 방식을 사용할 때 향상된 미세 조정 성능을 문서화한 최근 문헌의 대부분과 현저한 차이입니다. 따라서 우리의 설계 결정은 양방향성으로부터 경험적으로 이익을 얻는 작업에서 잠재적으로 더 나쁜 성능을 희생하게 됩니다. 여기에는 빈칸 채우기 작업, 두 개의 내용을 되돌아보고 비교하는 작업 또는 긴 지문을 다시 읽거나 신중하게 고려한 다음 매우 짧은 답변을 생성해야 하는 작업이 포함될 수 있습니다. 이것은 WIC(두 문장의 단어 사용을 비교하는 것), ANLI(한 문장이 다른 문장을 의미하는지 확인하기 위해 두 문장을 비교하는 것) 및 여러 읽기 이해 과제(예: QuAC 및 RACE)와 같은 몇 가지 작업에서 GPT-3의 지연된 퓨샷 성능에 대한 가능한 설명이 될 수 있습니다. 우리는 또한 과거 문헌을 바탕으로 큰 양방향 모델이 GPT-3보다 미세 조정에 더 강할 것으로 추측합니다. GPT-3의 규모로 양방향 모델을 만들거나, 또는 소수 또는 제로샷 학습으로 양방향 모델이 작동하도록 노력하는 것은 향후 연구의 유망한 방향입니다, "양쪽의 장점"을 달성하는 데 도움이 될 수 있습니다.
이 논문에서 설명한 일반적인 접근법의 더 근본적인 한계는, 즉, 자동 회귀 또는 양방향이든 LM과 같은 모델을 확장하는 것은 결국 사전 훈련 목표의 한계에 부딪힐 수 있다는 것이다(또는 이미 부딪힌 것일 수도) 있다는 것이다. 우리의 현재 목표는 모든 토큰에 동등하게 가중치를 부여하고 무엇이 가장 중요하고 무엇이 덜 중요한지에 대한 개념이 부족하다. [RRS20]에서는 interest한 entity를 위해 customizing prediction을 만드는 것의 이점을 보여준다. 또한 self-supervised 목표에서 작업 사양은 원하는 작업을 예측 문제로 강제하는 데 의존하는 반면, 궁극적으로 유용한 언어 시스템(예: 가상 보조자)은 단순히 예측을 하는 것보다 목표 지향적인 행동을 취하는 것으로 더 잘 생각될 수 있다. 마지막으로, 사전 훈련된 대규모 언어 모델은 비디오 또는 실제 물리적 상호 작용과 같은 다른 경험 영역에 기반하지 않으므로 세계에 대한 많은 컨텍스트가 부족하다[B]HT+20] 이러한 모든 이유로 순수 자기 감독 예측을 확장하는 것은 한계에 부딪힐 가능성이 있으며, 다른 접근 방식을 사용한 증강이 필요할 가능성이 높다. 이러한 맥락에서 유망한 미래 방향에는 인간[ZSW+19a]으로부터 목적 기능을 학습하거나, 강화 학습으로 미세 조정하거나, 이미지와 같은 추가 양식을 추가하여 세계의 기초와 더 나은 모델을 제공하는 것이 포함될 수 있다[CLY+19].
언어 모델이 널리 공유하는 또 다른 한계는 사전 훈련 중 샘플 효율성이 낮다는 것이다. GPT-3는 인간(원샷 또는 제로샷)에 더 가까운 테스트 시간 샘플 효율성을 향해 한 걸음 내딛지만, 여전히 인간이 평생 동안 보는 것보다 사전 훈련 중에 훨씬 더 많은 텍스트를 본다[Lin20]. 훈련 전 샘플 효율성을 개선하는 것은 향후 작업을 위한 중요한 방향이며, 추가 정보를 제공하기 위한 물리적 세계의 접지 또는 알고리듬 개선에서 나올 수 있다.
GPT-3의 퓨샷 학습과 관련된 한계 또는 적어도 불확실성은 퓨샷 학습이 실제로 추론 시간에 "처음부터" 새로운 과제를 학습하는지 또는 단순히 훈련 중에 학습한 과제를 인식하고 식별하는지에 대한 모호성이다. 이러한 가능성은 테스트 시점의 것과 정확히 동일한 분포에서 도출된 훈련 세트의 시연에서부터 동일한 작업을 인식하지만 다른 형식으로 수행되는 것, QA와 같은 일반 작업의 특정 스타일에 적응하는 것, 완전히 새로운 기술을 배우는 것에 이르기까지 스펙트럼에 존재한다. GPT-3가 이 스펙트럼에 있는 경우 과제마다 다를 수 있다. 단어를 뒤적거리거나 넌센스 단어를 정의하는 것과 같은 합성 작업은 특히 새로운 것으로 학습될 가능성이 높은 반면, 번역은 시험 데이터와 조직과 스타일이 매우 다른 데이터에서 가능하지만 사전 훈련 동안 분명히 학습되어야 한다. 궁극적으로, 인간이 처음부터 배우는 것과 이전의 시연에서 배우는 것이 무엇인지조차 명확하지 않다. 사전 훈련 중에 다양한 데모를 구성하고 테스트 시간에 식별하는 것도 언어 모델의 발전이지만 그럼에도 불구하고 퓨샷 학습이 어떻게 작동하는지 정확하게 이해하는 것은 향후 연구를 위한 중요한 미개척 방향이다.
객관적 기능이나 알고리듬에 관계없이 GPT-3 규모의 모델과 관련된 한계는 추론을 수행하는 데 비용이 많이 들고 불편하다는 것이며, 이는 현재 형태의 모델의 실제 적용 가능성에 대한 과제를 제시할 수 있다. 이 문제를 해결할 수 있는 가능한 미래 방향 중 하나는 특정 작업에 대해 관리 가능한 크기로 대형 모델을 distillation하는 [HVD15]이다. GPT-3와 같은 대형 모델은 특정 작업에 필요하지 않은 매우 광범위한 기술을 포함하고 있어 원칙적으로 공격적인 증류가 가능할 수 있음을 시사한다. 증류는 일반적으로 [LHCG19a]에서 잘 탐구되었지만 수천억 매개 변수의 규모로 시도되지 않았다. 이 크기의 모델에 증류를 적용하는 것과 관련하여 새로운 도전과 기회가 있을 수 있다.
마지막으로, GPT-3은 대부분의 딥 러닝 시스템에 공통적인 몇 가지 한계를 공유한다. 결정은 쉽게 해석할 수 없고, 표준 벤치마크에서 인간보다 훨씬 높은 성능 차이로 관찰되는 새로운 입력에 대한 예측에서 반드시 잘 보정되지는 않으며, 훈련된 데이터의 편향을 유지한다. 이 마지막 문제(모델이 정형화되거나 편견을 가진 콘텐츠를 생성하도록 유도할 수 있는 데이터의 편향)는 사회적 관점에서 특별한 관심사이며, 더 광범위한 영향에 대한 다음 섹션에서 다른 문제와 함께 논의될 것이다(섹션 6).
6 Broader Impacts
- Misuse of Language Models
- Potential Misuse Application
- Threat Actor Analysis
- External Incentive Structures
- Fairness, Bias, and Representation
- Gender
- Race
- Religion
- Future Bias and Fairness Challenges
- Energy Usage
7 Related Work
8 Conclusion
- 많은 NLP tasks와 benchmark에 강력한 성능을 보이는 175B parameter의 Language Model을 만들었다.
- zero-, one-, few-shot setting이 가능하다.
- 일부 경우에는 fine-tuned 된 SOTA에 필적하는 성능을 냈다.
- 또한 즉석에서 정의된 task에 대해서도 좋은 성능을 냈다.
- fine-tuning을 사용하지 않는 scaling이라는 trend를 예상해 보았다.
- model의 사회적 효과에 대해 토의 했다.
- 많은 한계와 약점이 있음에도, 이러한 결과는 초거대 언어 모델이 적용 가능하고 일반적인 언어 시스템을 만드는데 중요한 요소가 될 것이다.
