Data Augmentation
- 적은 데이터로 학습 시 과적합이 발생하기 쉽다. 훈련 데이터를 수집하기 어려울 때, 기존 데이터를 변형해서 훈련 데이터를 늘려줄 수 있다. 이것을 Data Augmentation이라고 한다.
- 사용하는 라이브러리/프레임워크에 따라 방법은 가지각색, 이미지 데이터인 경우 tensorflow에서는 keras의 preprocessing 모듈 중 ImageDataGenerator를 사용하는 방법이 일반적이다.
- Data Augmentation 으로 만들어진 데이터도 역시 과적합이 발생할 수 있으므로, Dropout을 활용해서 랜덤하게 일부 데이터를 학습에서 제외시킨다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255, horizontal_flip=True, width_shift_range=0.1, height_shift_range=0.1)-
rescale: 크기 조정
- 1./255: 모든 RGB 이미지는 색상이 0부터 255 사이 값. 학습에 걸리는 시간을 단축하고자 이 값을 0과 1 사이 값으로 조정
-
horizontal_flip: 좌우반전 (지정하지 않을 경우 디폴트값 False)
- cf. vertical_flip: 상하반전 (지정하지 않을 경우 디폴트값 False)
-
width_shift_range / height_shift_range: 가로/세로 변경 범위
-
이미지 변형 코드 예시
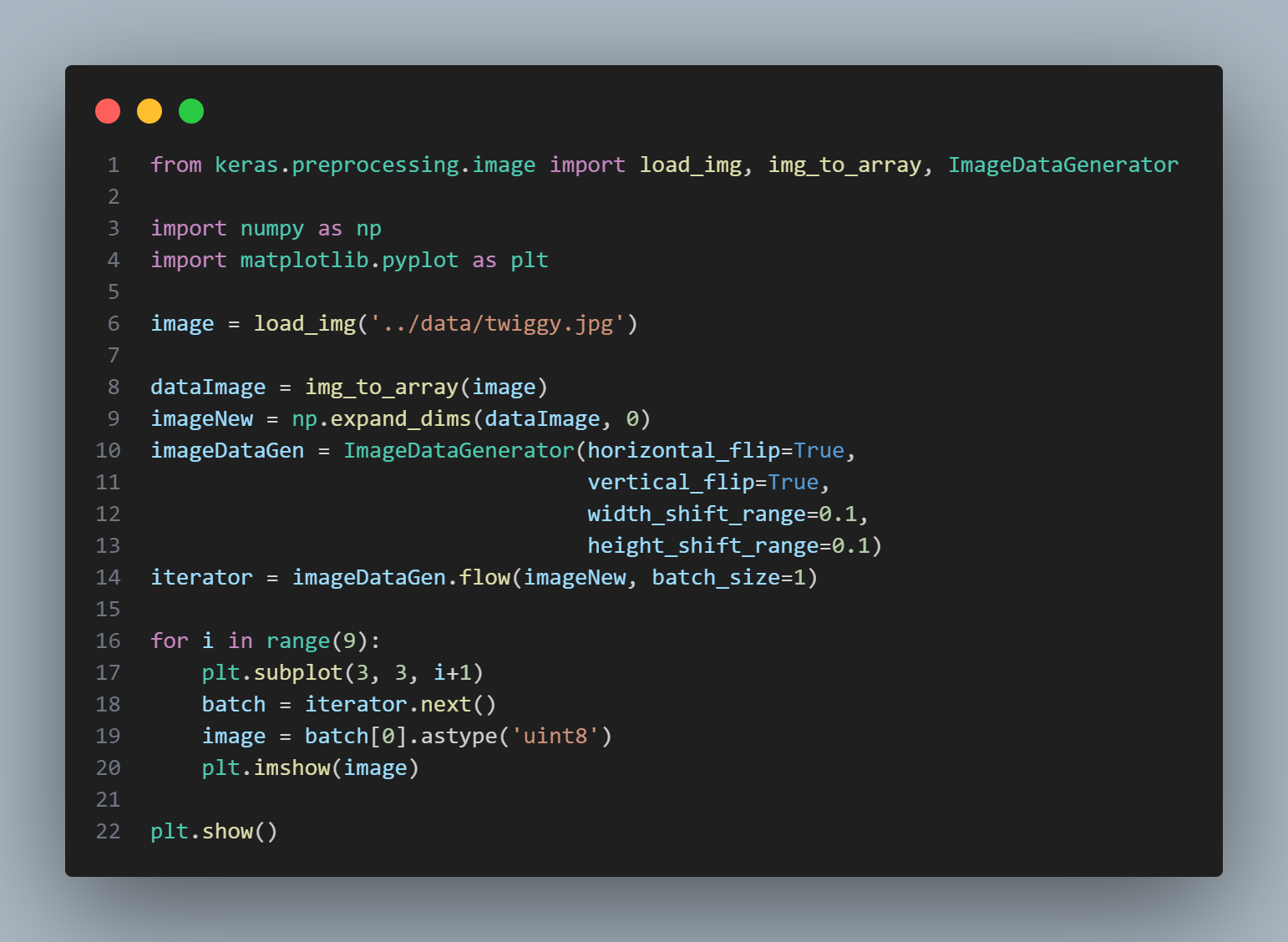
-
사용한 이미지 원본

-
결과 예시

- expand_dims는 왜 하는 걸까?
- ImageDataGenerator의 flow 함수가 numpy 4차원 행렬을 요구하므로 차원을 더해 줬다.
- ex. 원본 shape: (479, 500, 3) -> 차원확장 후 shape: (1, 479, 500, 3)
실습: O와 X 구분
- 훈련/테스트에 사용된 이미지
- 그림판(Ubuntu Kolourpaint)
- 아이폰 메모 그림
- 우분투 시스템 폰트
- 종이에 펜으로 그린 후 사진
- 종이에 매직으로 그린 후 사진
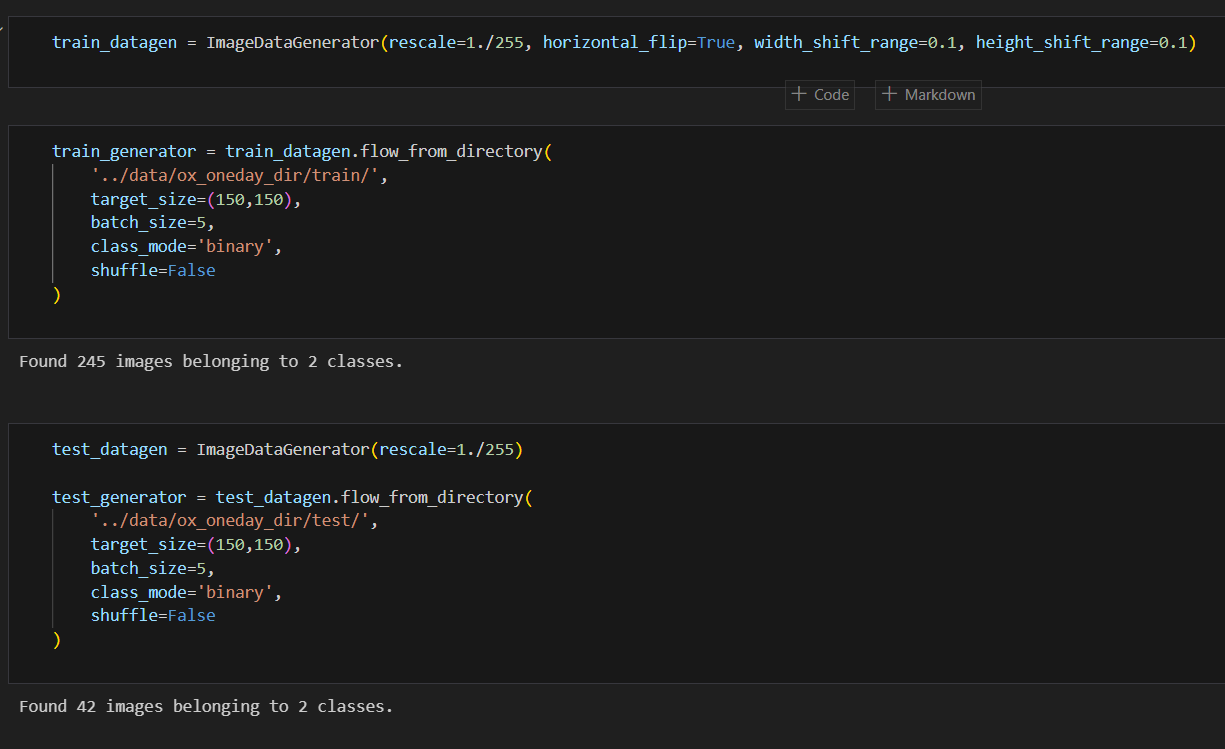
flow_from_directory
- 라벨링을 디렉토리로 한 경우 사용하기 좋다.
- O와 X를 구분하기 위한 이미지를 binary class로 가져온다.
CNN LeNet
-
1998년에 발표된 모델로, 최신 모델에 비하면 정확도가 낮은 편
-
Convolutional Neural Network에 대해 이해하기 위해 사용해 봅니다.
-
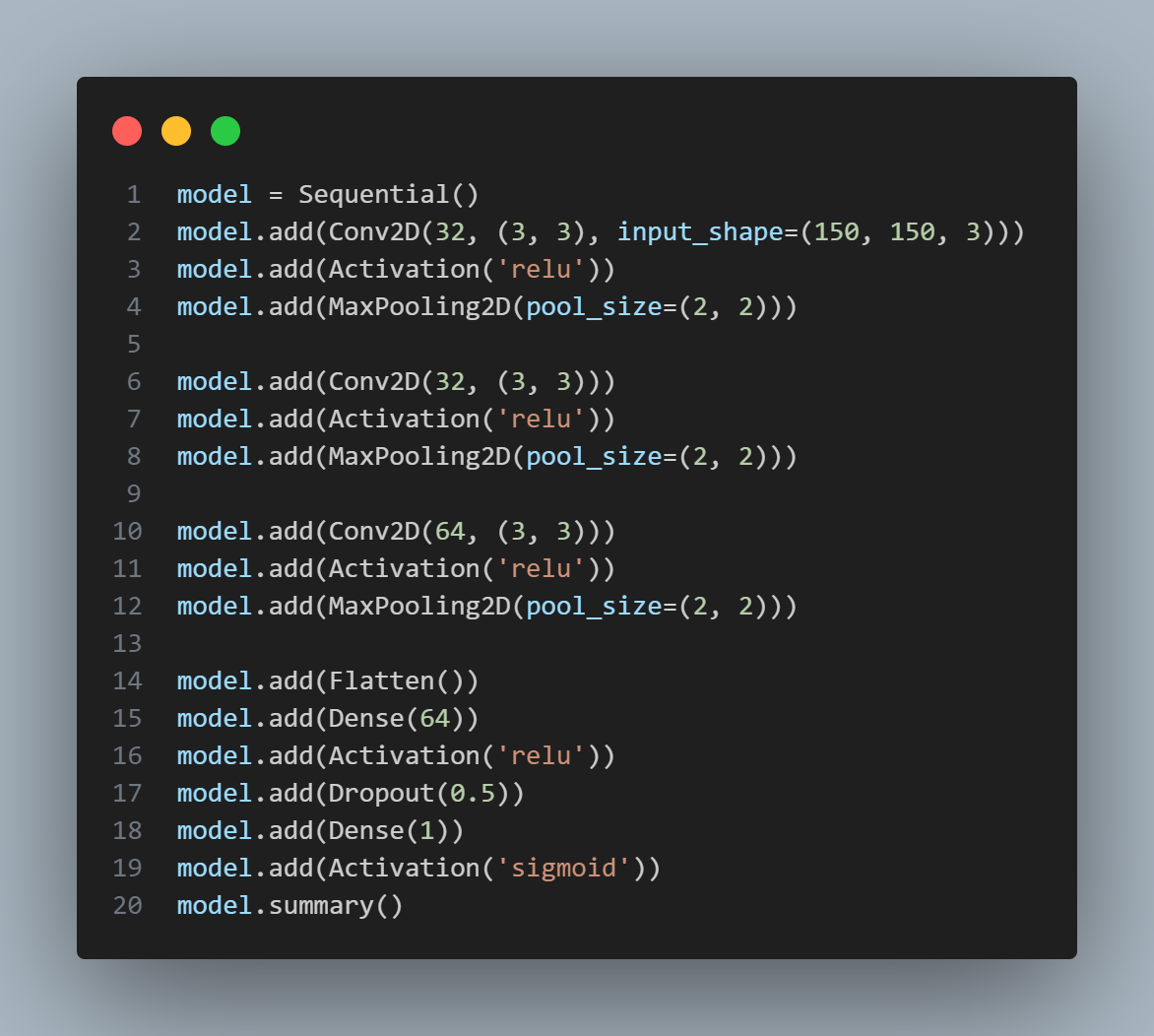
Convolution으로 이미지의 특징을 추출
- 위 코드에서는 32개의 채널(특징)을 찾아내고, 2x2 행렬 크기로 화면 전역에 적용해서 추상화
- maxPooling: 화면의 하얀 부분에 집중(mnist 데이터 또는 MRI처럼 배경이 까맣고 숫자/이미지는 하얀색인 경우)
- averagePooling: 이미지를 smooth하게 함
- minPooling: 배경이 하얗고 집중해야 하는 이미지가 까만색
-
활성화 함수로 relu를 사용하여 sigmoid에 비해 학습 효율이 좋다
-
stride는 설정하지 않음: 디폴트값 1 (데이터를 줄일 경우 2 이상으로 설정)
-
Flatten: 2차원 데이터를 1차원 데이터로
-
Dense: fully connected layer 생성
- 마지막 Conv2D가 64개 채널을 가지고 있었으므로, 첫 번째 Dense도 64개 채널을 가져옴
- 두 번째/마지막 Dense는 출력 뉴런은 하나, sigmoid probability를 구하기 위한 것
-
Dropout으로 일부 데이터를 버림
model summary
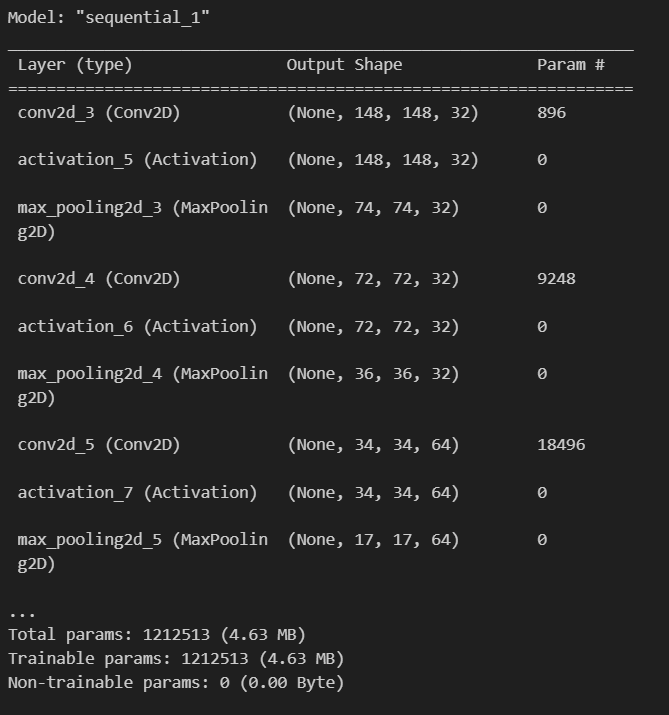
- 훈련가능한 파라미터 121만 2513개
model compile
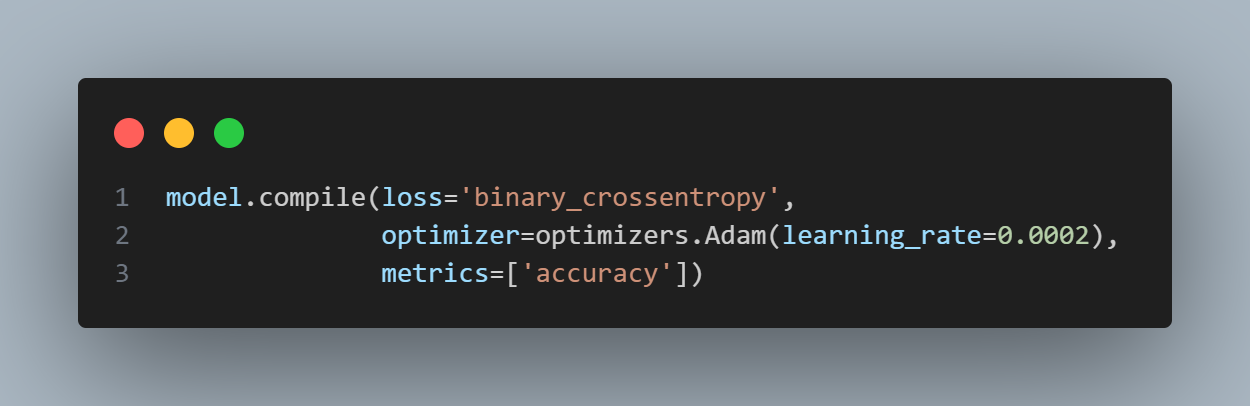
- optimizer는 adam 사용
model fit (학습)
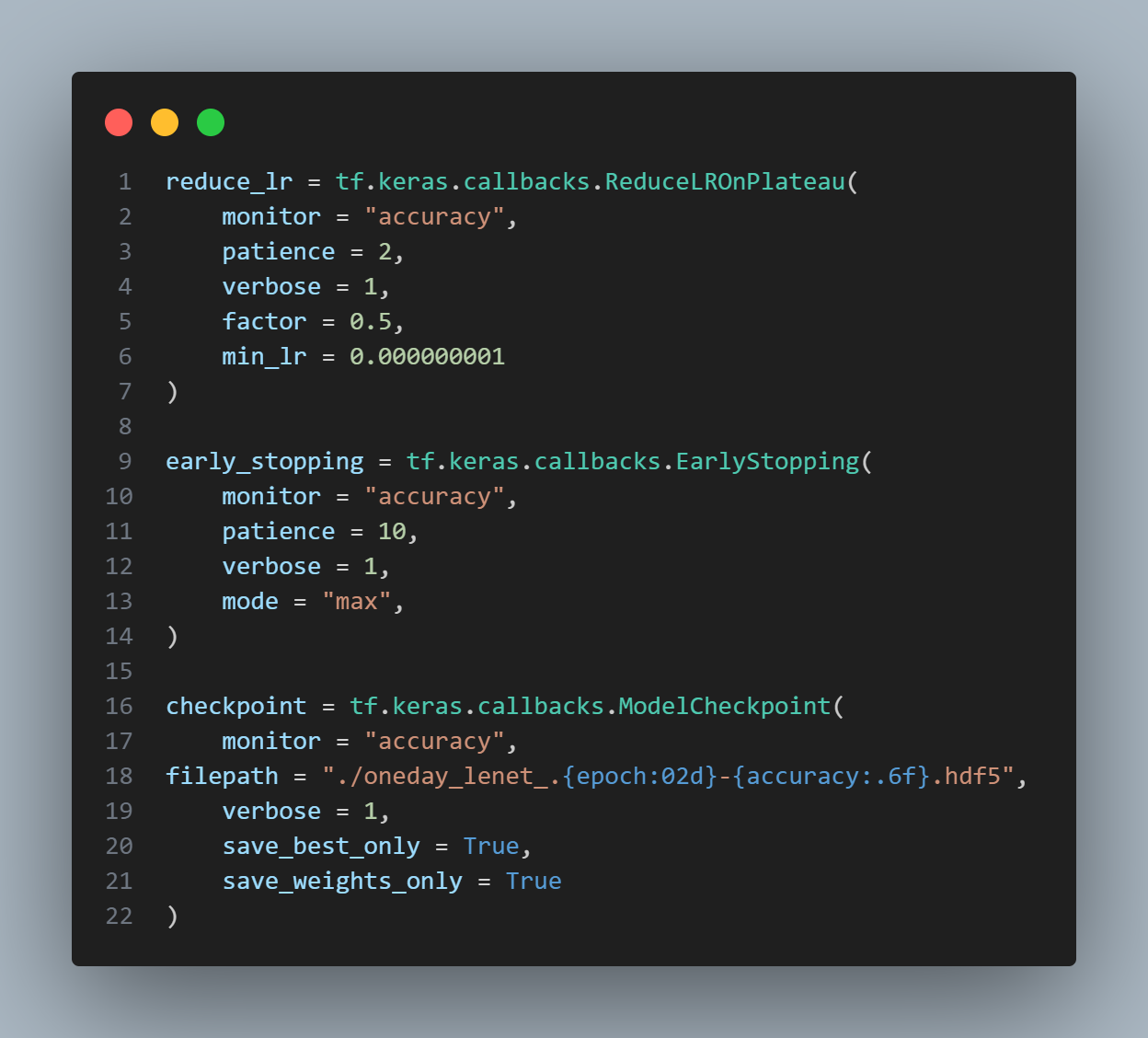
- ReduceLROnPlateau: 정확도가 2에포크 동안 높아지지 않으면 learning rate 조절
- learning rate: 너무 높으면 불안정하고 너무 낮으면 학습이 안됨
- EarlyStopping: 정확도가 10에포크 동안 높아지지 않으면 지정한 epoch를 마치지 않고 학습을 종료
- ModelCheckpoint: 이전 에포크보다 정확도가 높아졌을 때 모델을 저장
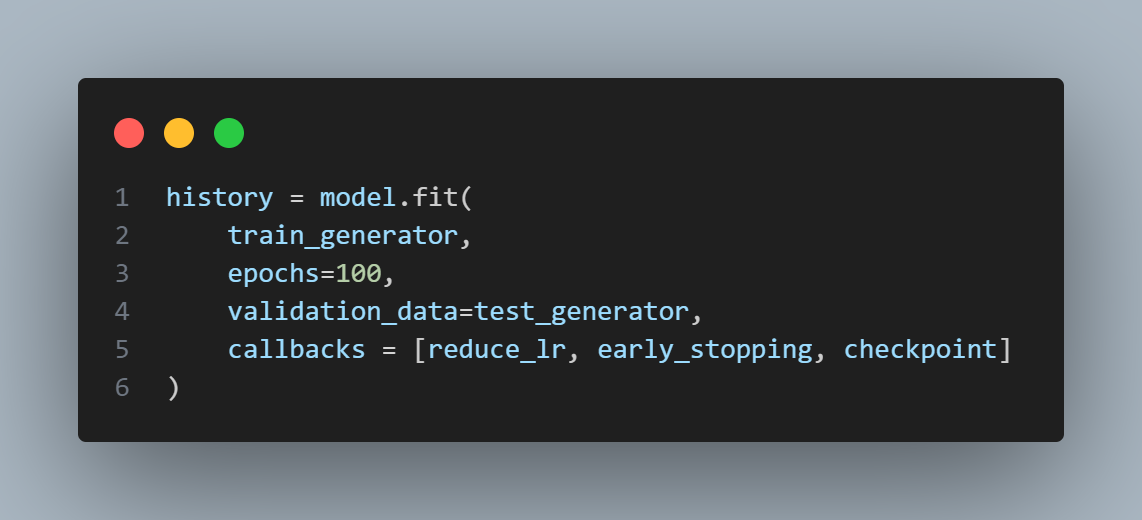
- 매 에포크에 callback 함수로 위에서 지정한 함수 실행
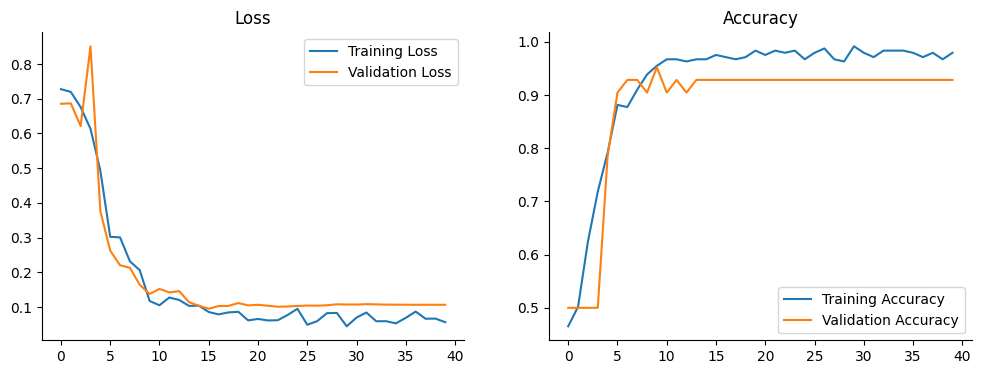
학습 결과
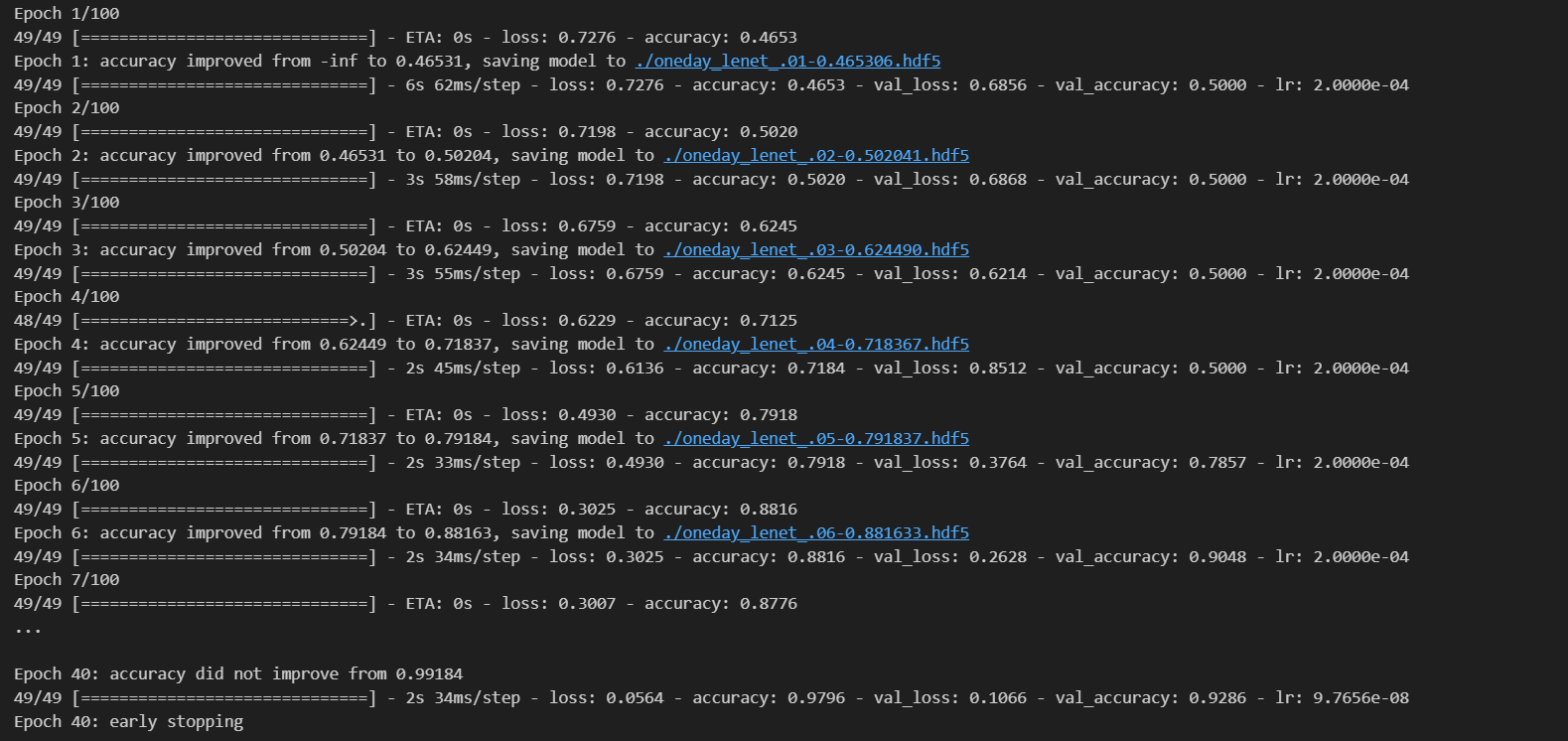
- 훈련 데이터 약 98%, 테스트 데이터 약 93% 정확도로 학습 종료
학습 history로 그래프 그리기
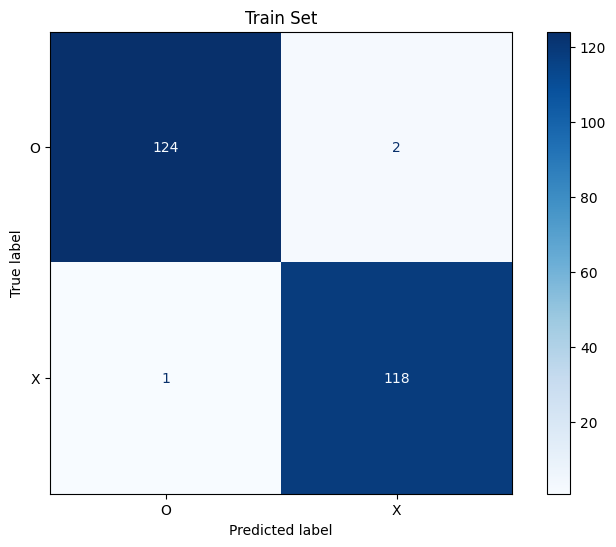
confusion matrix 그리기
틀린 이미지는 어떻게 생겼나?
- 훈련 데이터에서
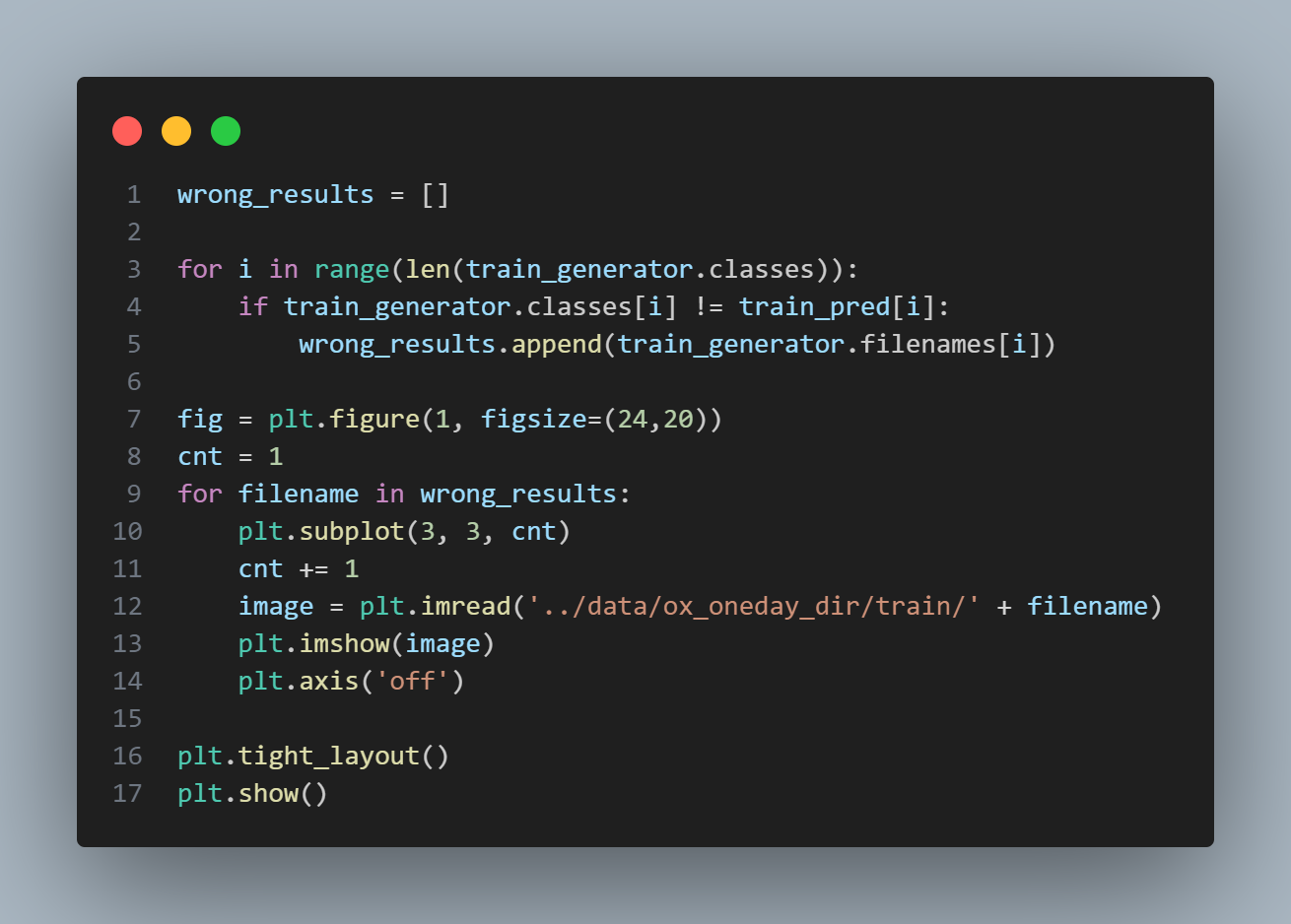

- 누가 봐도 O와 X인데 왜 틀렸을까..?
- 누가 봐도 O와 X인데 왜 틀렸을까..?
- 비슷한 코드로 검증 데이터도 확인

- 중간에 '오'는 틀리라고 넣은 데이터
- 그래도 양옆 이미지는 맞췄어야 할 것 같다
왜 틀렸는지 더 궁금해하지 않고 적중률 높은 모델을 찾아 떠납니다..
VGG16 전이학습
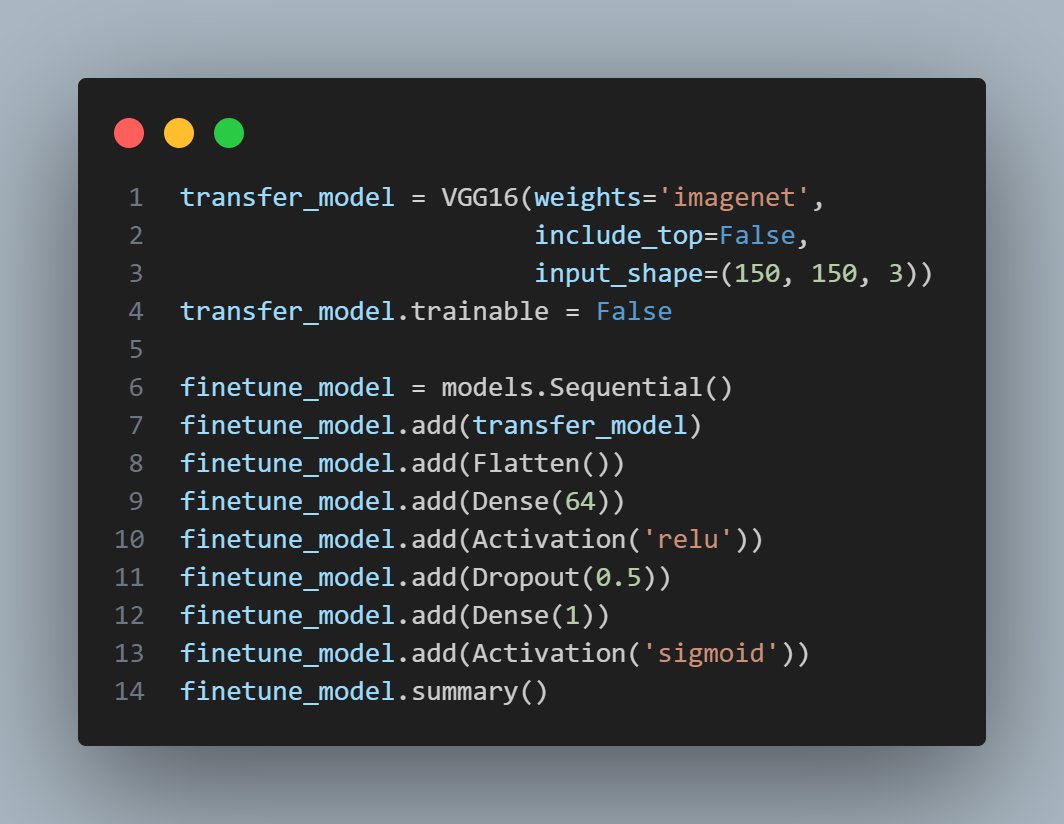
- VGG16이라는 성능 좋은 모델을 가져와서 일부를 Dropout
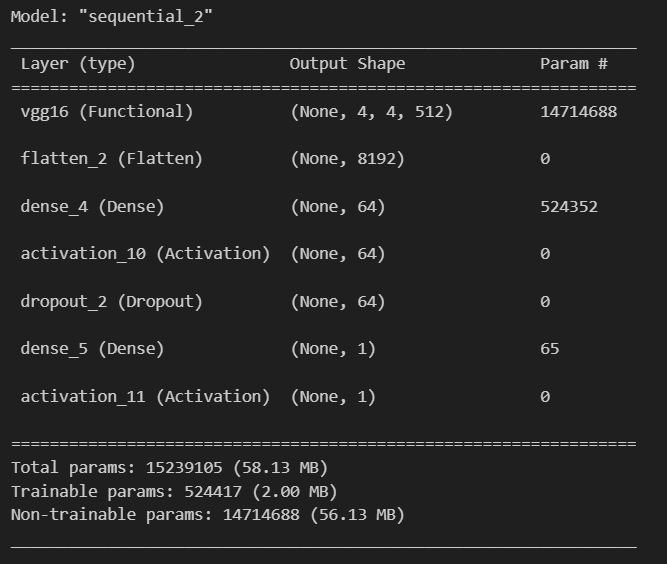
- 5만 개 정도 학습할 수 있는 param이 생겼습니다
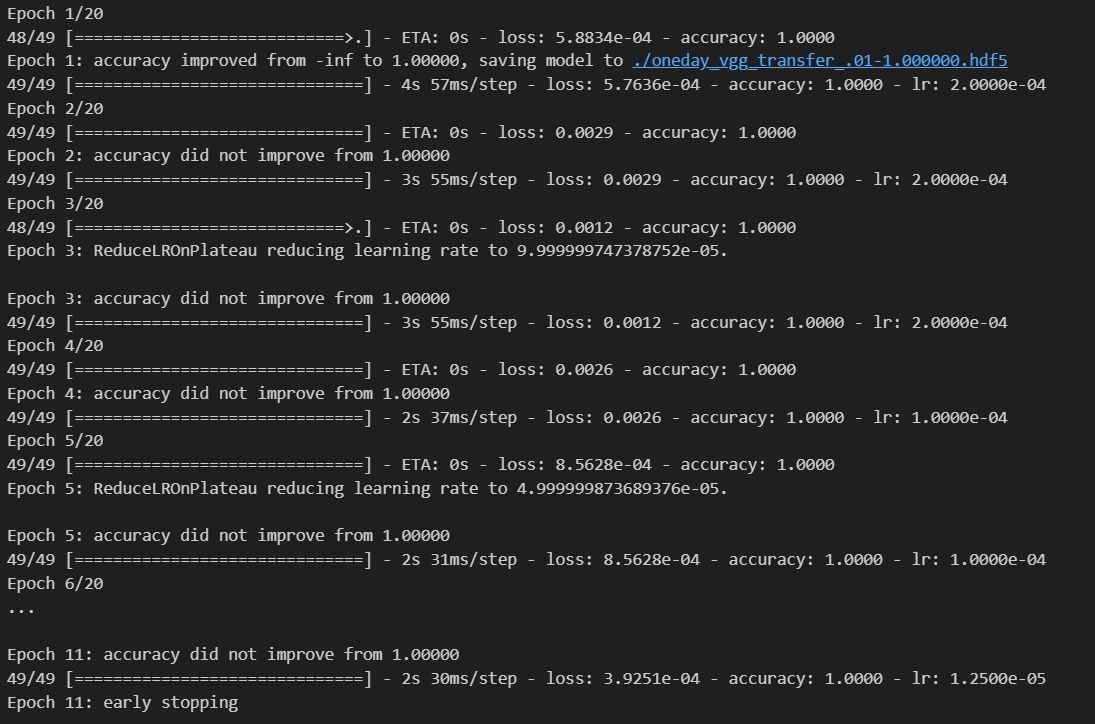
- 더 적은 학습으로 더 좋은 성능을 가지게 되었어요
- 무려 정확도가 100% (훈련 데이터 한정이지만)
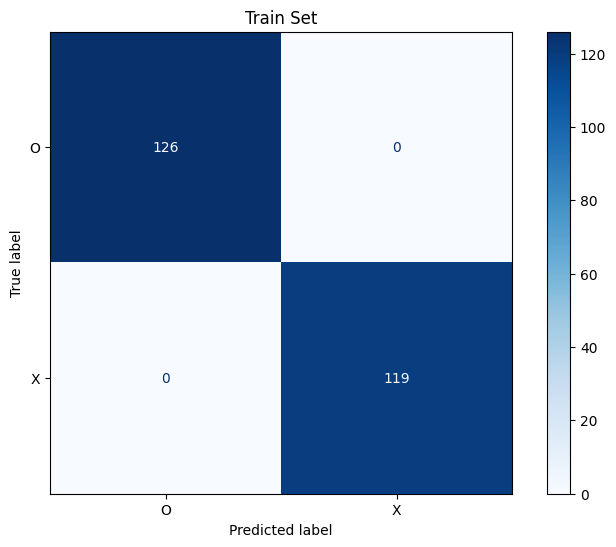
- 아름답다
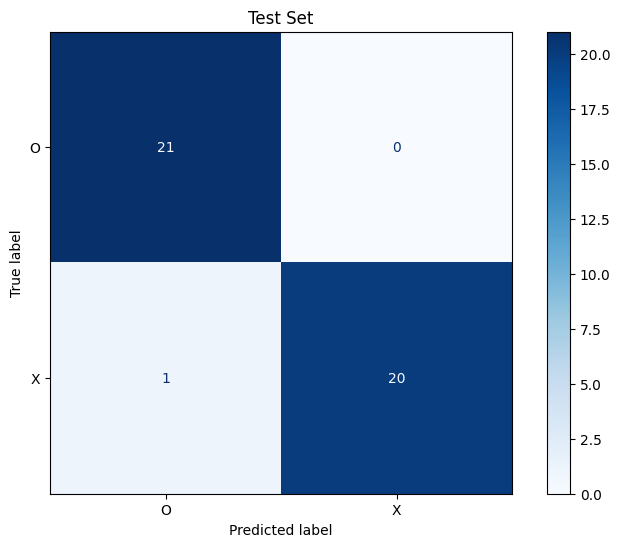
- 테스트 데이터에서도 하나 빼고 다 맞췄습니다.
- 참고자료
- https://github.com/Arsey/keras-transfer-learning-for-oxford102/issues/1
- https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html
- https://www.studytonight.com/post/horizontal-and-vertical-flip-data-augmentation
- https://stackoverflow.com/questions/64947335/model-fit-validation-accuracy-different-than-model-predict
- http://vision.stanford.edu/cs598_spring07/papers/Lecun98.pdf
- https://medium.com/@bdhuma/which-pooling-method-is-better-maxpooling-vs-minpooling-vs-average-pooling-95fb03f45a9
- https://stackoverflow.com/questions/47029417/how-to-choose-the-window-size-of-cnn-in-deep-learning
