Overview
- An Emsemble model based on multiple Decision(or Regression) Trees.
Characteristics
- When the number of trees is sufficiently large, the Strong Law of Large Numbers(SLLN) ensures that the model does not overfit, and its error converges to a limiting value.
- The main two concepts; Bagging and the Random Subspace method maximize the independence, generalization, and randomness of individual models, thereby reducing the correlation between them.
- The performance of a Random Forest improves as the accuracy and independence of individual trees increase.
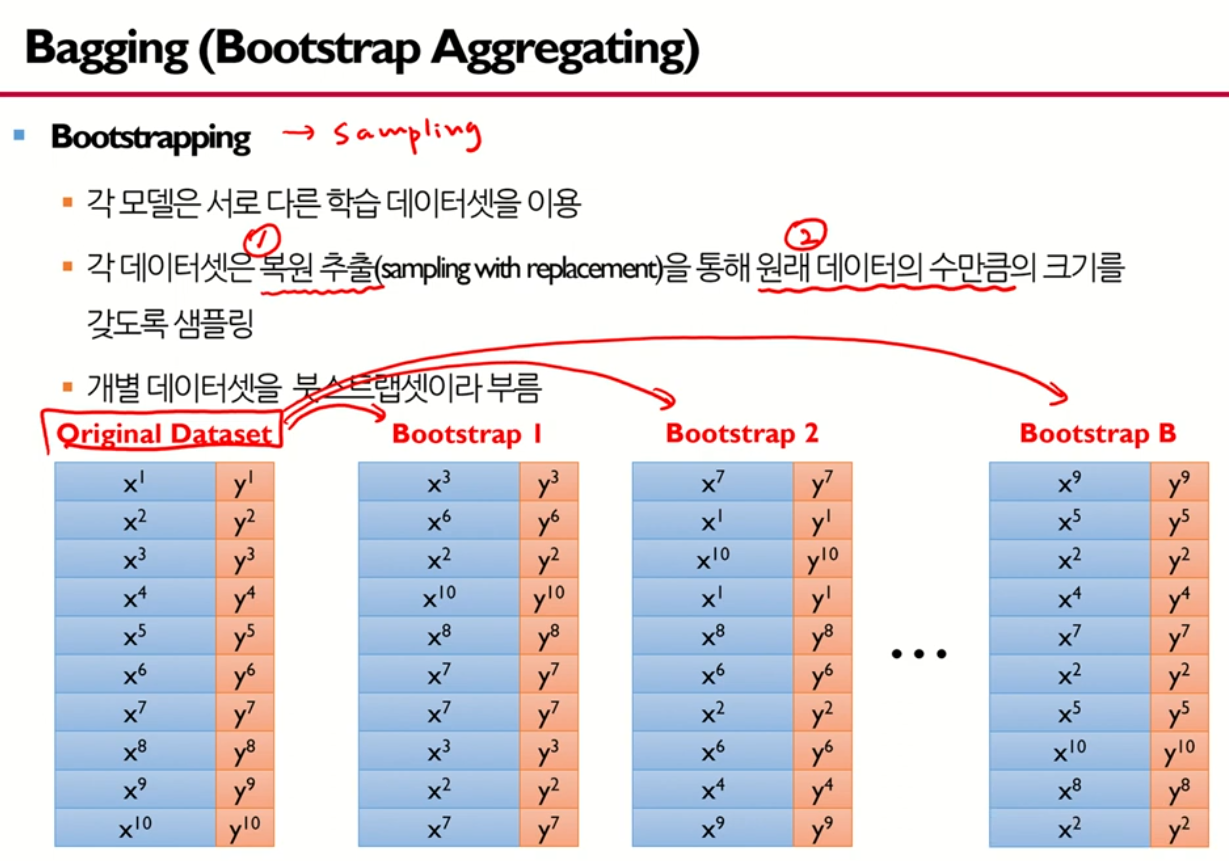
1. Bagging(Bootstrap Aggregating) → Diversity
- Generate multiple training datasets(bootstrap sets), build individual decision tree models for each, and aggregate results through voting.

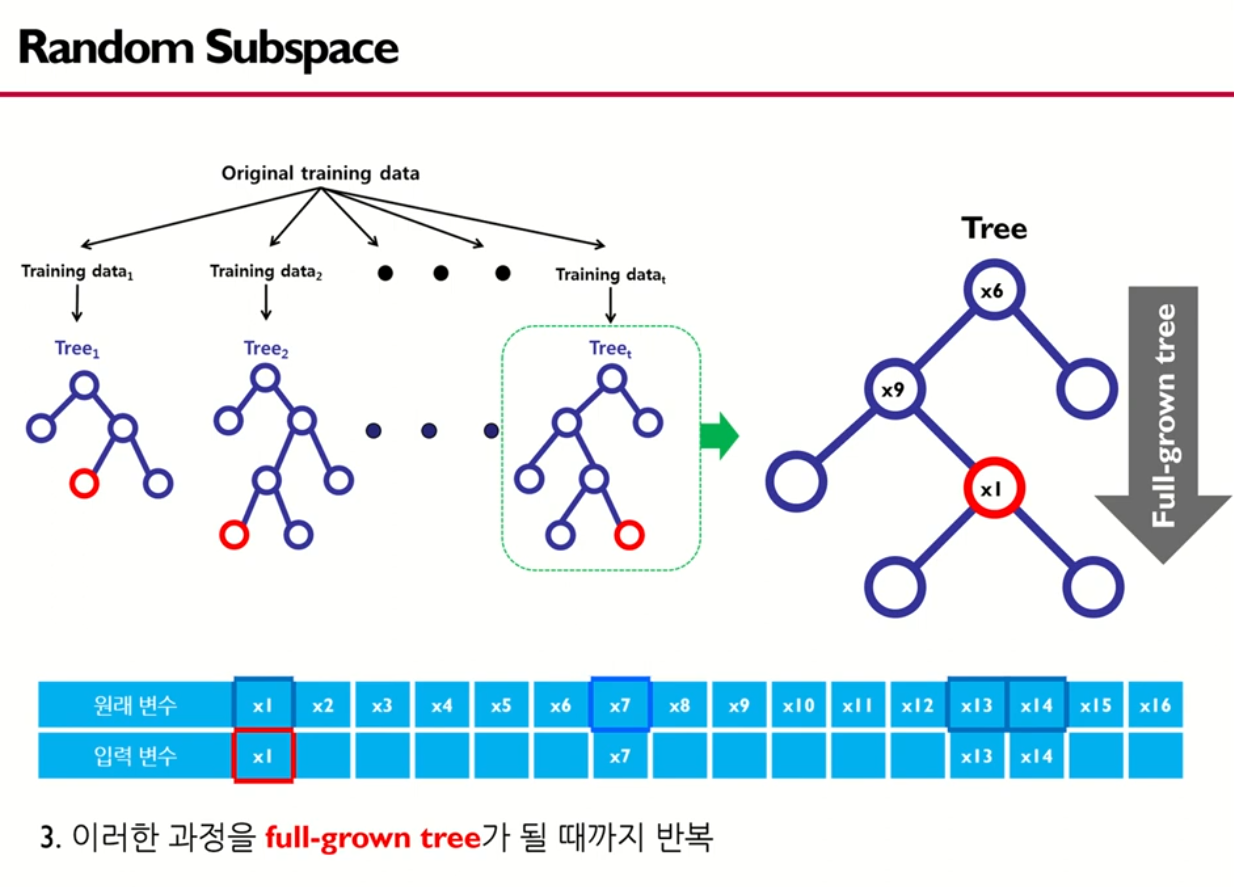
2. Random Subspace → Randomness
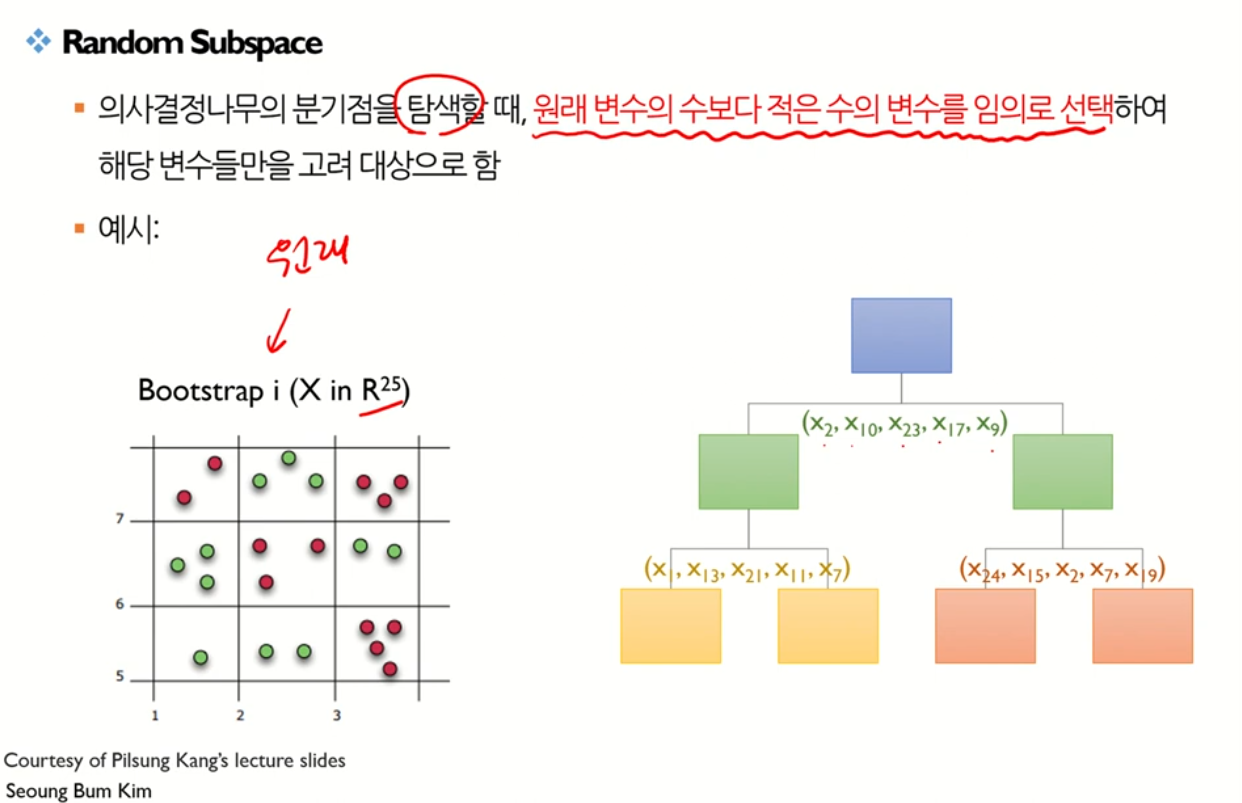
- Randomly select variables when spliting and constructing a decision tree model.
Feature Importance
- RF는 비모수적 모델로, 선형 회귀모델/로지스틱 회귀모델과 달리 개별 변수가 통계적으로 얼마나 유의한지에 대한 정보를 제공하지 않음(확률 분포를 가정하지 않음)
- 대신 간접적으로 변수의 중요도를 결정함
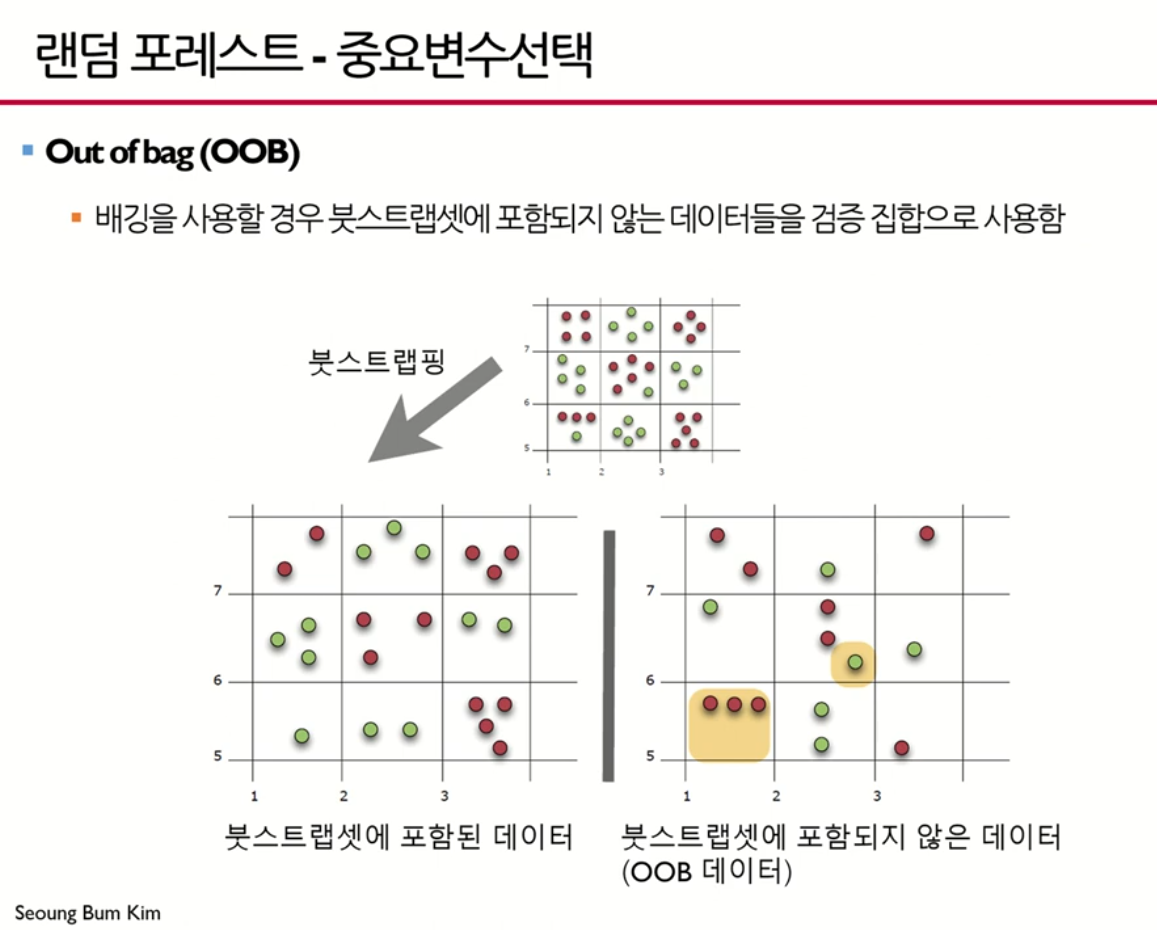
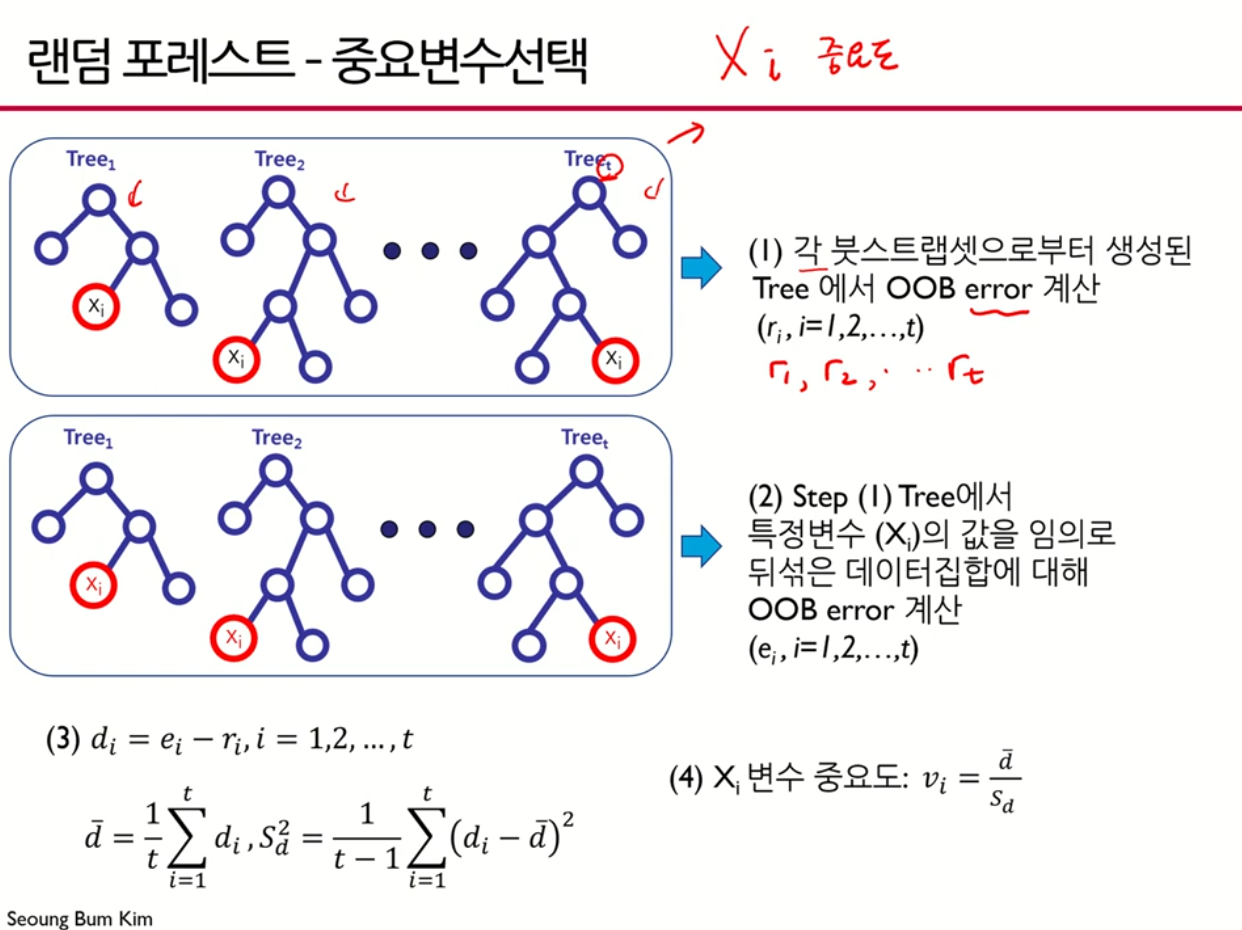
1단계) 원래 데이터 집합에 대해서 Out Of Bag(OOB) Error를 구함
2단계) 특정 변수의 값을 임의로 뒤섞은 데이터 집합에 대해서 OOB Error를 구함
3단계) 개별 변수의 중요도는 2단계와 1단계 OOB Error 차이의 평균과 분산을 고려하여 결정함.

yozzum