Hyperparametres to tune in order of importance
- Learning rate(alpha)
- Momentum(Beta) - recomm: 0.9
- Number of Hidden Units
- Mini-batch size
- Number of Layers
- Learning rate decay
- B1, B2, Epsilon - 0.9, 0.999, 10^(-8) fixed!
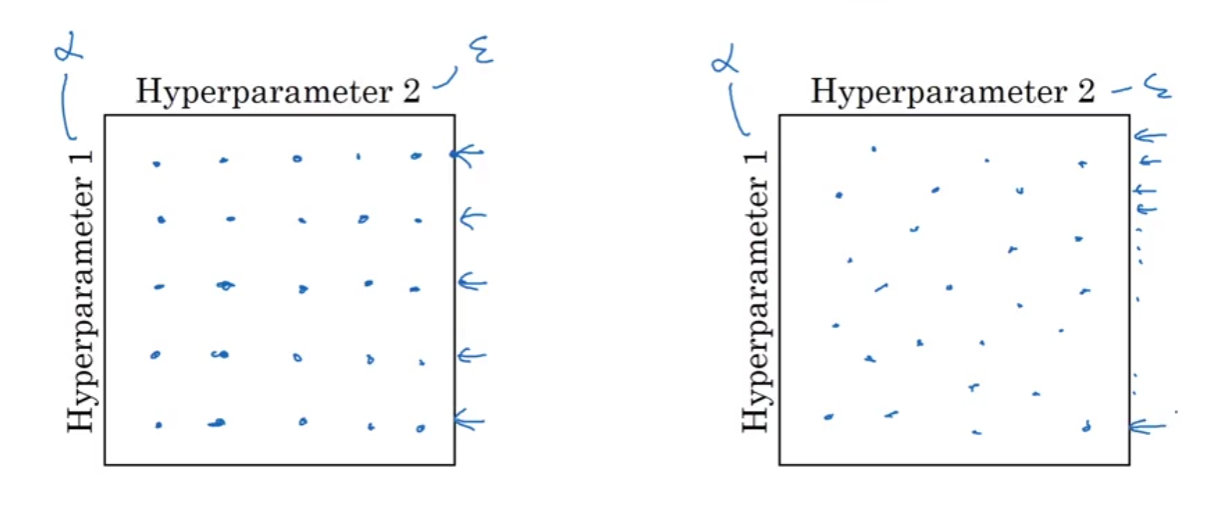
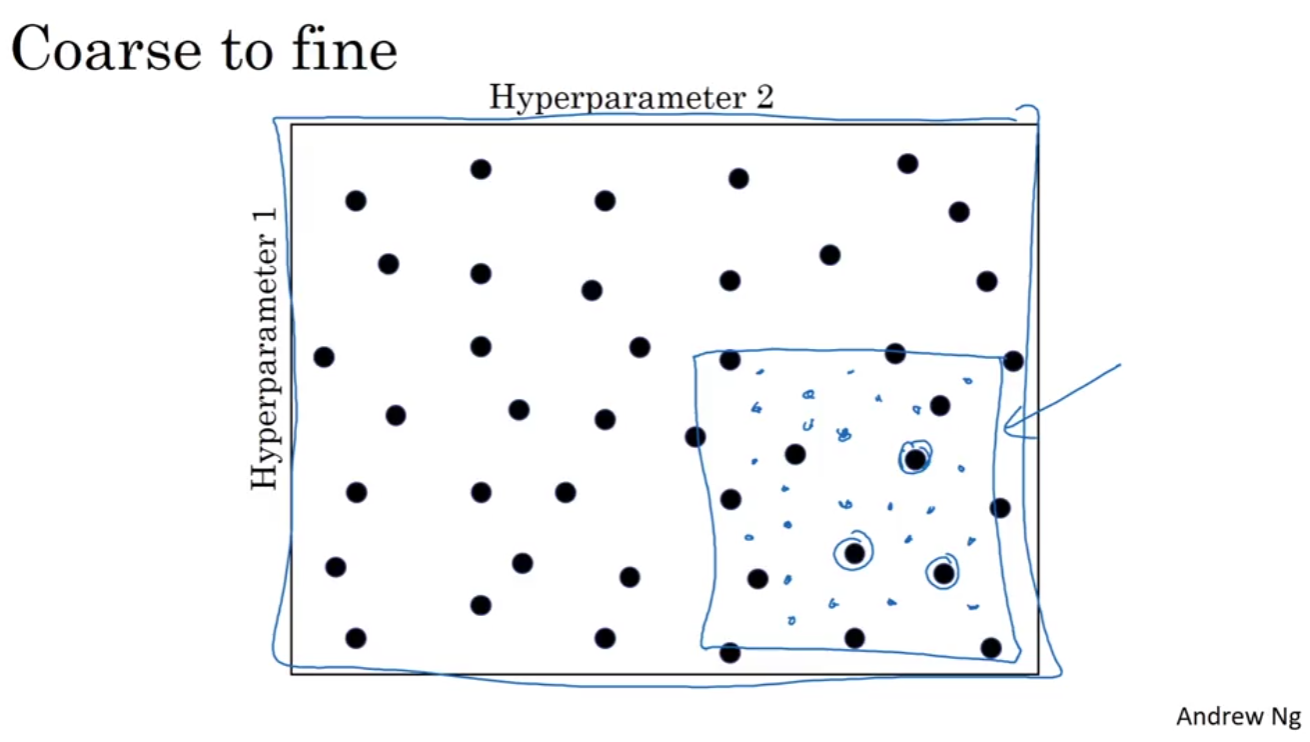
Random Search is more efficient than Grid Search

yozzum