In logistic regression, normalizing INPUT FEATURES speeds up learning.
In deep learning, for any hidden layer, can we normalize the activation functions so as to train W, b faster?
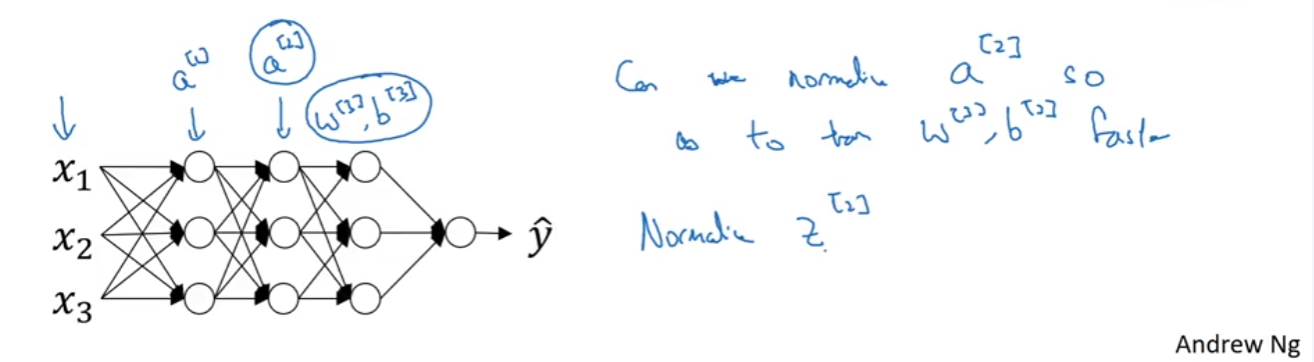
-
There are some debates whether you should apply normalizing before or after activation function.
-
But in practice it is known that normalizing the values before activation is better.

- You let the model learn gamma and beta to reshape the distribution of Z.
- Note that you don't want your values in hidden layers to have a mean of 0 and variance of 1 since you want the advantage of non-linearity.
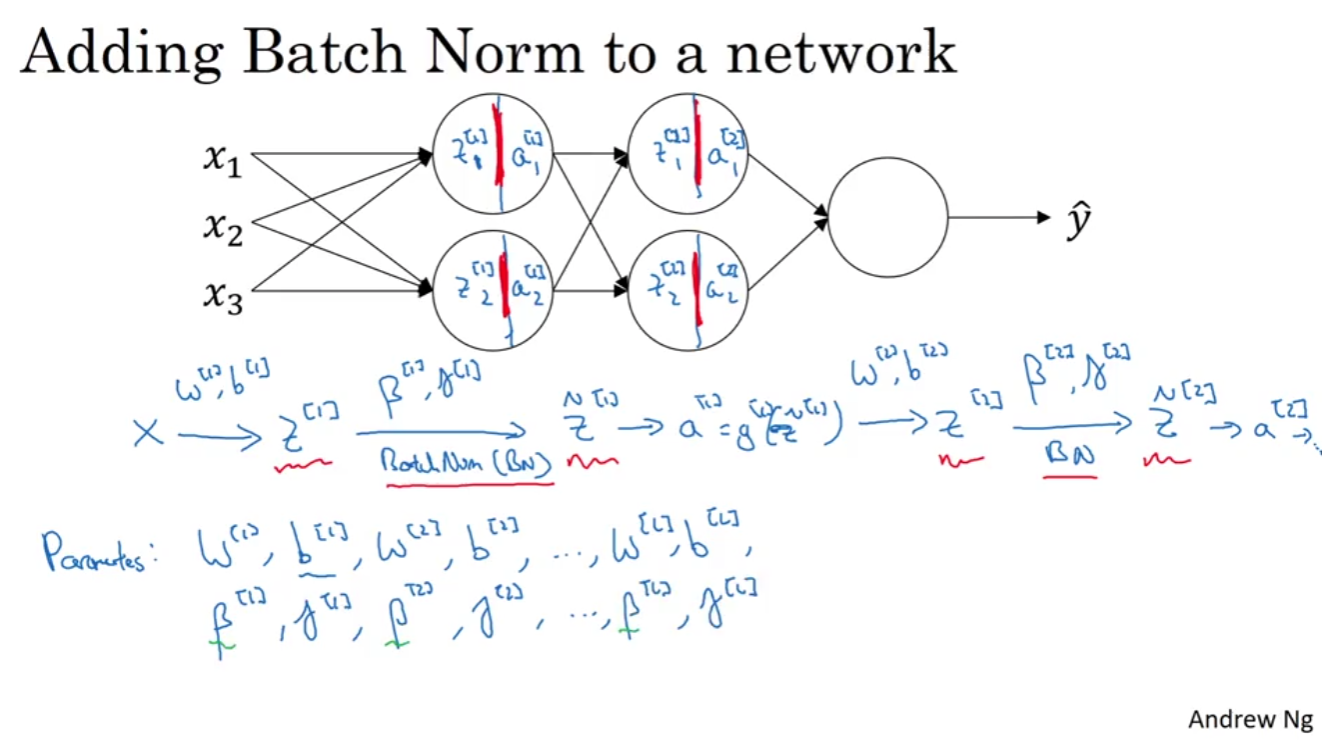
- Batch Norm is carried out between z and a.
※ This beta is different from the beta of momentum.



3개의 댓글

Nutrisystem offers prepackaged meals and structured eating plans. This convenience reduces decision fatigue and portion errors, semaglutide naples fl guiding individuals through consistent calorie control and helping them stay on track toward fitness-related transformations.
Travel-friendly features make them vacation-ready. Easy to fold, lightweight, and quick to dry, these lanyards work great for sightseeing, theme parks, or ski phone leash tours where you want to avoid carrying extra bags.
Software licenses can add up quickly, especially for businesses requiring multiple tools. Opting for subscription-based software models or hosted desktops open-source alternatives helps reduce costs while ensuring businesses have access to necessary applications without large initial investments.