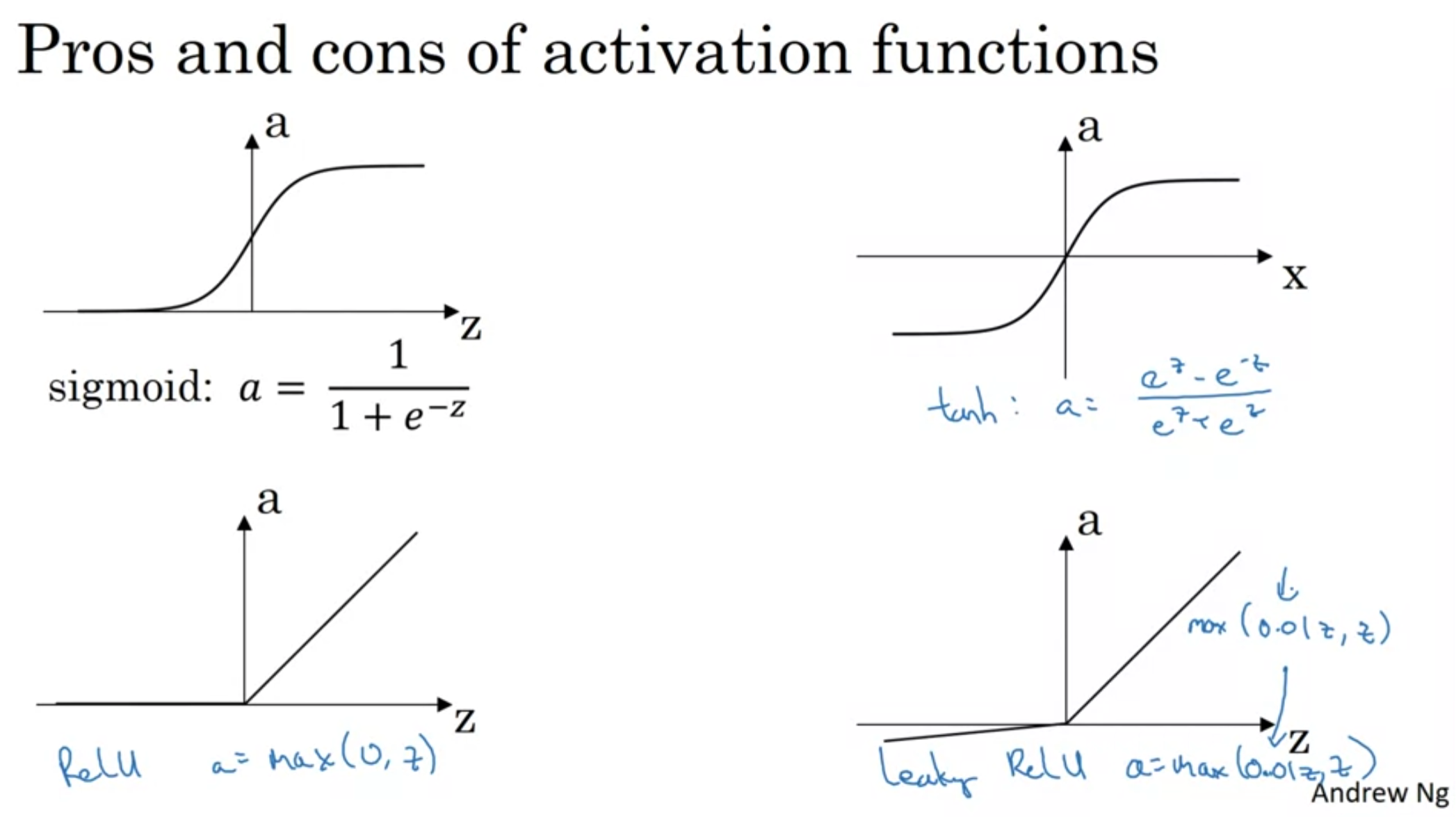
-
There is no point setting linear functions for activation since the result would be a giant linear throughout the layers. That is why non-linear functions should be used in hidden layers.
-
By experience, Relu or Leaky Relu give better performance. You can use them in hidden layers but the activation function of the output layer should be a binary such as Sigmoid function.
Building blocks of DNN
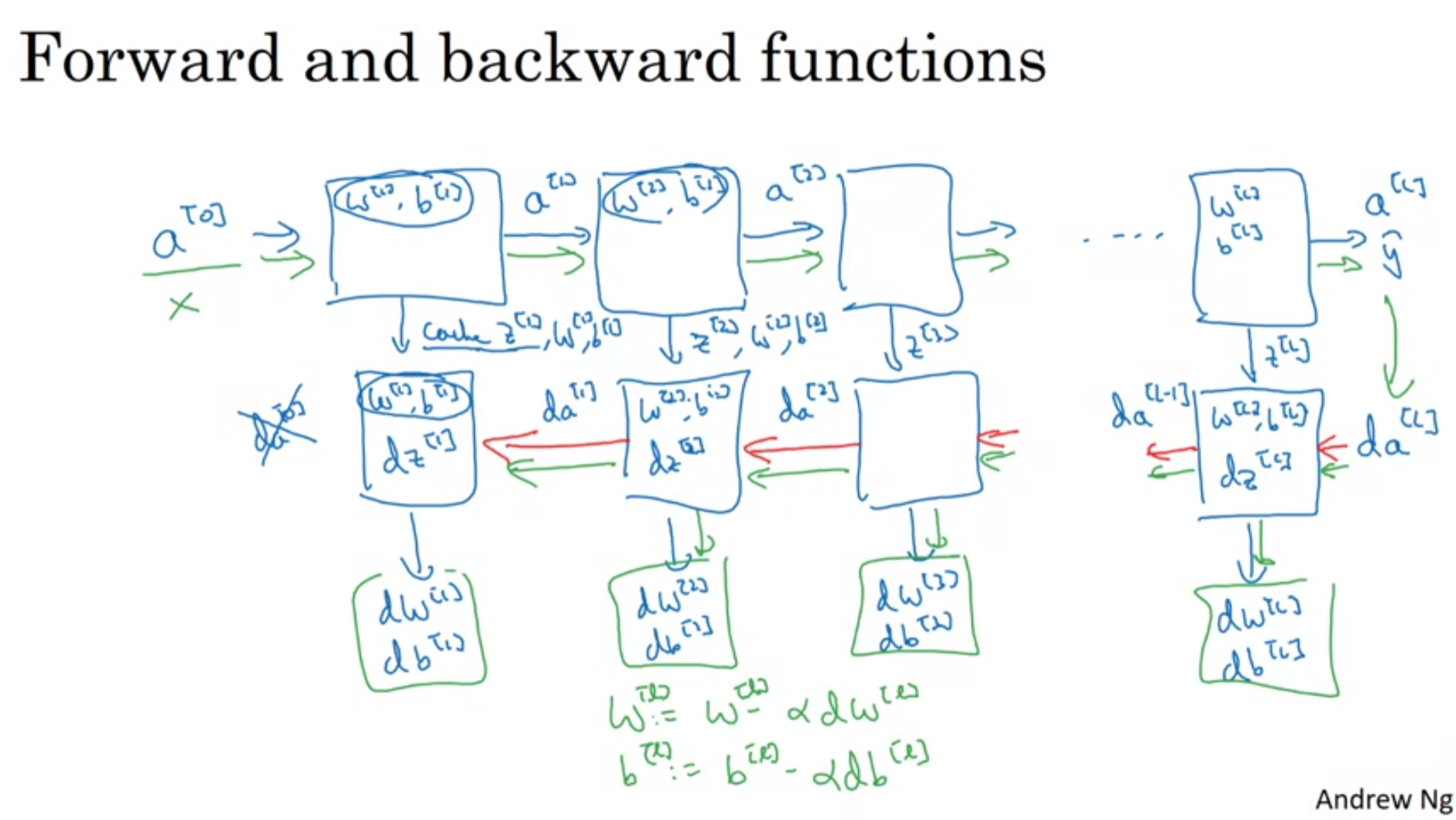
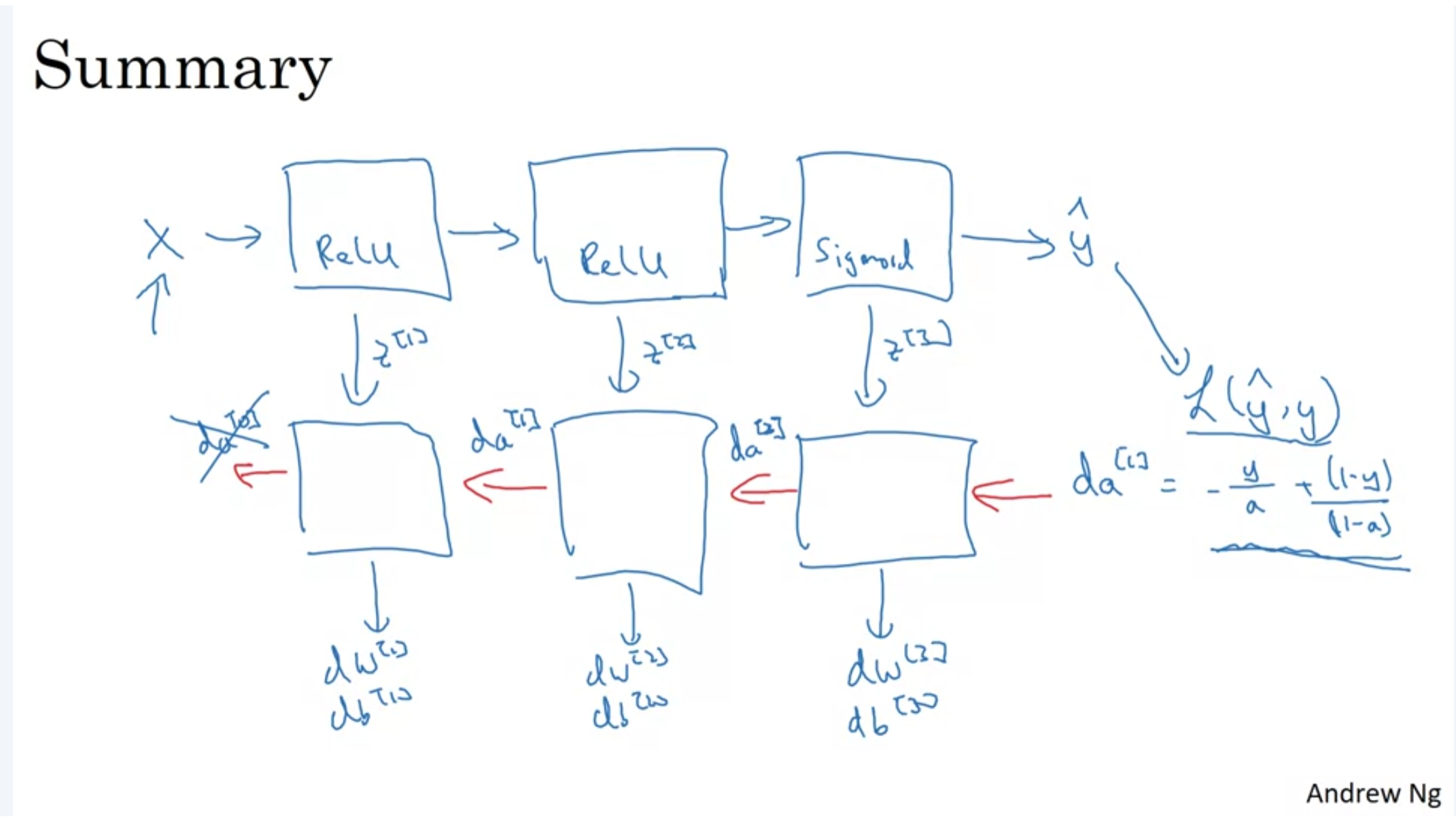

yozzum