
로지스틱 회귀(Logistic Regression)란?
로지스틱 회귀(Logistic Regression)는 지금까지 설명드린 단순|다중 선형 회귀(Linear Regression)의 종속변수()가 연속형 이였던것에 반해, 종속변수()가 범주형이면서 결과가 이진수(0 OR 1)일때 사용합니다.
이를 이용해 어떤 사건(event)이 발생할지에 대한 직접적인 예측이아니라 그 사건(event)이 발생활 확률을 예측 하는것입니다.
예를 들어, 제가 AWS자격증에 합격될지, 불합격 될지 예측하려고할때 공부시간이 특징(독립변수 : ) 이고 목표 이진 변수 (종속변수: )는 합격(1), 불합격(0) 두가지 값이 있는것입니다.
로지스틱 회귀(Logistic Regression)의 종류
로지스틱 회귀((Logistic Regression)에는 크게 세가지 종류가 있습니다.
1.이진 로지스틱 회귀(Binary Logistic Regression)
범주형 데이터에 대한 응답에 가능한 결과는 이진(1,0 / 두가지)입니다.
위의 예시와같이 제가 자격증시험에 합격하거나 불합격한다는 형태의 종속변수()에 대해 사용합니다.
2.다중 로지스틱 회귀 (Multinomial Logistic Regression)
다중 로지스틱 회귀(Multinomial Logistic Regression)에는 순서가 없는 3개이상의 변수가 포함될 수 있습니다.
예를 들어 백반집에서 밥을 먹는사람들이 특정 종류의 메뉴(김치찌개, 된장찌개, 청국장)을 선호하는지 예측 하는 것이 있습니다.
3.순서 로지스틱 회귀 (Ordinal Logistic Regression)
다중 로지스틱 회귀(Multinomial Logistic Regression)와 같이 3개이상의 변수가 있을 수 있습니다.
거기에서 측정시에 순서를 추가하면 순서 로지스틱 회귀 (Ordinal Logistic Regression)가 됩니다.
별 1부터 5까지의 척도로 호텔이나 맛집을 평가하는 경우를 들 수 있습니다.
이진분류(Binary Classification) 만 다루는 이유
하지만 다중 로지스틱 회귀(Multinomial Logistic Regression) 인경우는
활성화 함수(Activaition Function)를 소프트맥스 분류(Softmax Classification)를 주로 사용하기때문에 본 게시글에선 시그모이드 함수(sigmoid Function)를 사용하는 분류만 소개하고자 합니다.
소프트 맥스 분류(Softmax Classification)에 대해서는 다음 게시글에서 소개해 드리도록 하겠습니다.
이번 게시글 부터는 데이터를 직접 만들어 사용하지않고, 예제 데이터들을 사용하여 설명드리겠습니다.
사용할 데이터셋은 깃허브의 "chinchu_data"로, 키(height)가 180 이상인 사람은 친구추가(cinchu)를 받을 수 있어 1, 180 미만일 경우에는 친구추가를 받지 못해 0 으로 분류하는 간단한 모델입니다.
#데이터 불러오기위해 사용
from tensorflow.keras.utils import get_file
#정규화를 위해 사용
from sklearn import preprocessing
#시각화를 위해 사용
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#------------------------------
#데이터 불러오기
fname = 'chinchu_data.csv'
origin = 'https://skettee.github.io/post/logistic_regression/chinchu_data.csv'
path = get_file(fname, origin)
#데이터를 데이터 프레임(Data Frame) 형태로 변환
df = pd.read_csv(path, index_col=0)
#상위10개 값 간단히 확인
df.head(10)keras의 get_file을 이용해 데이터 셋을 다운로드 받아 줍니다.
또 pandas module을 이용해 데이터프레임(Data Frame)으로 변환하고,
".head()"를 이용해 상위 10개 항목을 간단히 시각화 해봅니다.
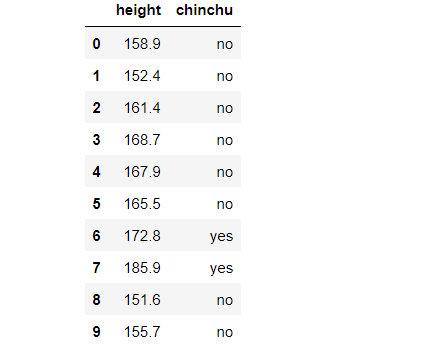
위와 같은 데이터를 확인 할 수 있습니다.
데이터의 결측치(NULL, None)를 확인하고, 결측치(NULL, None)가 존재한다면 제거합니다.
df.isnull().any()다음과 같은 코드를 실행하면 데이터프레임(Data Frame)의 칼럼(column)별 결측치의 존재유무를 쉽게 확인할 수 있습니다.
height True
chinchu True
dtype: bool
결측치가 존재 하기때문에,(True) 제거한후 다시 확인 해보도록 하겠습니다.
df = df.dropna(axis=0)
df.isnull().any()height False
chinchu False
dtype: bool
확인하면 결측치가 잘 제거된것을 확인 할 수 있습니다.
라벨링(Labeling)과 정규화(Nomalization)
#yes일 경우 1을 return
#no일 경우 0을 return
def labeling_y(y):
if y == 'yes':
return 1
else:
return 0
#x와 y값을 지정하여 reshape
x = np.array(df.height).reshape(len(df.height), 1)
y = np.array([labeling_y(i) for i in df.chinchu ]).reshape(len(df.chinchu), 1)
#라벨링된 데이터를 시각화
plt.scatter(x, y)
plt.xlabel('height (cm)')
plt.ylabel('chinchu')
plt.show()이진 분류(binary Classification)를 하기 위해서는 손실함수(Loss Function)을 계산하여야 합니다.
그래서 위와 같이 각 범주형인 yes =1, no=0 으로 라벨링하는 작업이 필요합니다.
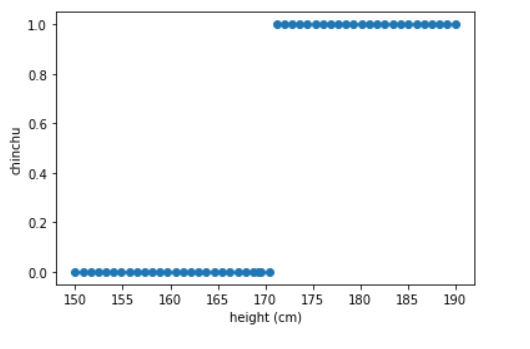
다음과 같이 'yes','no'의 범주형 데이터에서 0,1의 계산가능한 정수형 데이터로 변환된걸 확인 하실 수 있습니다.
데이터의 정규화(Nomalization)
정규화(Nomalization)는 관계형 데이터베이스의 설계에서 중복을 최소화 하기위하여, 데이터를 구조화 하는 과정입니다.
중복된 데이터를 제거해 이상(anomaly)을 제거하는것이 정규화(Nomalization)의 목적입니다.
머신러닝(machine learning)을 위해 사용하는 sklearn. preporcessing의 MinMaxScaler를 이용해 데이터를 정규화 해보도록 하겠습니다.
사실 데이터의 질 향상을 위해, 정규화(Nomalization)는 선택이 아닌, 필수라고 생각됩니다.
mm_scaler = preprocessing.MinMaxScaler() #편한 사용을 위해 선언
x = mm_scaler.fit_transform(x) #독립변수(x) 스케일링위와 같은 코드를 작성하면,
MinmaxScaler는
정규값 = (현재값 - 최소값) / (최대값-최소값)
위와 같은 방법을 통해 데이터를 정규화(Nomaluzation)합니다.
훈련과(train) 검증(validation)
딥러닝(DeepLearning) 모델을 설계할때, 모델의 데이터 손실율(Loss)과
정확도(accuracy)는 중요한 이슈입니다.
훈련(train)뿐만아니라, 실제 데이터를 모델에 적용했을때에(test) 손실율(Loss)을 낮추고, 정확도(accuracy)를 높이는 것이, 설계한 모델의 실전이라고 할 수 있겠습니다.
sklearn에는 훈련(train)과 동시에 검증하기(validation)위해 훈련(train)과 검증 데이터를 나눌 수 있는 기능을 제공하는데,
from sklearn.model_selection import train_test_split
#8:2 비율로 훈련(Train), 검증(validation) 데이터 나누기
x_train, x_valid, y_train, y_valid = train_test_split(x, y,
test_size=0.2, #비율지정 test의 사이즈는 20%
random_state=1, #랜덤 상태를 지정, 나눌데이터 고정
stratify=y)
#각각 Train), 검증(validation) 데이터의 모양 확인
print(x_train.shape, y_train.shape, x_valid.shape, y_valid.shape)(40, 1) (40, 1) (10, 1) (10, 1)
결측치(NULL, None) 제거후 총 50개의 데이터가 8:2의 비율로 나누어 진걸 확인 하실 수 있습니다.
모델에 사용하기위한 데이터 전처리는 모두 끝났습니다.
이제부터 본격적으로 모델을 구현 해보도록 하겠습니다.
tensorflow.Keras의 Dense Layer 이용하여 구현하기
Tensor flow 에는 keras라는 오픈소스 신경망 라이브러리가 존재합니다.
그중 Dense 클래스는 다층 퍼셉트론(Multi Layer Perceptron : MLP)의 입력과 출력을 연결해주는 역할을 합니다.
예를 들어 입력 노드(Input node)가 6개, 출력 노드(Output node)가 10개라고 가정 할 때 총 연결선은
개가 됩니다.
각 연결선은 가중치(weight)를 포함하고 있는데, 여기서 가중치(weight)는 연결강도를 나타낸다고 할수있습니다.
위의 예시에서의 연결선이 60개 존재함으로, 가중치(weight)의 갯수는 60개라고 할수 있습니다. 또 가중치가 높을수록 입력 노드(Input node)가
출력 노드(Output node)에 미치는 영향이 크고, 낮을수록 미치는 영향이 적습니다.
지금까지의 게시글에서는 가중치(weight)와 편향(bais)의 중요성을
강조하기위해 그것들을 직접 선언하며 구현하였지만,
본문부터는 keras를 십분 활용하여 ,
더욱쉽게 구현하는 방법에대해 설명 드리겠습니다.
Tensorflow를 사용하여 구현하기
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Activation
# 모델 선언
model = Sequential()
# Dense층 구현
model.add(Dense(1, input_dim=1, activation='sigmoid'))
# 손실함수(Loss funtion)와 옵티마이저(Optimizer)를 엮습니다.(compile)
#측정항목(metric)을 정확도(accuracy)로 지정해주어 실시간으로 정확도정확도(accuracy)를 모니터링합니다.
model.compile(loss='binary_crossentropy', optimizer='rmsprop',metrics = ['accuracy'])
# epochs(10000)만큼 반복해서 손실값이 최저가 되도록 모델을 훈련한다.
hist = model.fit(x_train, y_train, epochs=10000, batch_size=10,validation_data=(x_valid, y_valid))
입력 노드(Input node)의 개수를 1, 출력 노드(Output node)의 갯수를 1로하고, 활성화 함수를(Activation Function) 시그모이드함수(sigmoid Function)로 하는 Dense 층을 구현합니다.
또 이 모델의 손실함수(Loss Function)는 이진 교차 엔트로피(Binary Cross Entropy)를 사용하고, 옵티마이저(Optimizer)는 RMSProp를 사용하여 Dense Layer에 엮었습니다.(Compile)
이렇듯 tensorflow의 keras를 잘활용하면 단 네줄의 코드로 딥러닝 모델을 만들수 있습니다.
실행하면 다음과같은 모델의 history가 같이 나오게 되는데, 여기서 손실값(Loss value)를 확인 하실 수 있습니다.
Epoch 1/10000
4/4 [==============================] - 0s 38ms/step - loss: 0.8544 - accuracy: 0.5250 - val_loss: 0.8647 - val_accuracy: 0.5000
Epoch 2/10000
4/4 [==============================] - 0s 9ms/step - loss: 0.8528 - accuracy: 0.5000 - val_loss: 0.8633 - val_accuracy: 0.5000
Epoch 3/10000
4/4 [==============================] - 0s 8ms/step - loss: 0.8515 - accuracy: 0.5000 - val_loss: 0.8621 - val_accuracy: 0.5000
Epoch 4/10000
4/4 [==============================] - 0s 8ms/step - loss: 0.8505 - accuracy: 0.5000 - val_loss: 0.8609 - val_accuracy: 0.5000
.
.
.
Epoch 9997/10000
4/4 [==============================] - 0s 8ms/step - loss: 0.1007 - accuracy: 1.0000 - val_loss: 0.1236 - val_accuracy: 0.9000
Epoch 9998/10000
4/4 [==============================] - 0s 7ms/step - loss: 0.1007 - accuracy: 1.0000 - val_loss: 0.1235 - val_accuracy: 0.9000
Epoch 9999/10000
4/4 [==============================] - 0s 8ms/step - loss: 0.1007 - accuracy: 1.0000 - val_loss: 0.1235 - val_accuracy: 0.9000
Epoch 10000/10000
4/4 [==============================] - 0s 8ms/step - loss: 0.1007 - accuracy: 1.0000 - val_loss: 0.1235 - val_accuracy: 0.9000
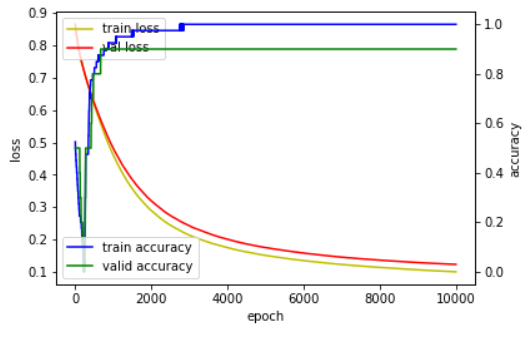
훈련이 반복될수록 위의 결과처럼 훈련(train)과 검증(validation)의 손실(Loss)이 점점 내려가고 정확도(accuracy)는 오르는것을 확인 하실 수 있습니다.
더욱 편하게 보기위해 시각화 해보도록 해보겠습니다.
모델학습 시각화
fig, loss_ax = plt.subplots()
acc_ax = loss_ax.twinx()
loss_ax.plot(hist.history['loss'], 'y', label = 'train loss')
loss_ax.plot(hist.history['val_loss'], 'r', label = 'val loss')
acc_ax.plot(hist.history['accuracy'], 'b', label = 'train accuracy')
acc_ax.plot(hist.history['val_accuracy'], 'g', label = 'valid accuracy')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuracy')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
plt.show()위의 소스코드는 복사하셔서 텍스트 파일로 가지고 계시는 것도 좋습니다.
각각의 history를 matplotlib을 통해 시각화 한 코드입니다.
다음과 같은 차트를 확인 하실 수 있습니다.
마무리
오늘은 tensorflow.keras의 Dense Layer를 활용하여 손쉽게 모델을 만들고 평가하는 방법까지 알아보았습니다.
다음 게시물은 활성화함수(Activation Function) 소프트맥스(softmax)를 사용하는 다중 로지스틱 회귀(Multinomial Logistic Regression)에 대해 적어 보도록 하겠습니다.
오늘은 특히 글이 길었는데 끝까지 읽어주셔서 감사합니다.
