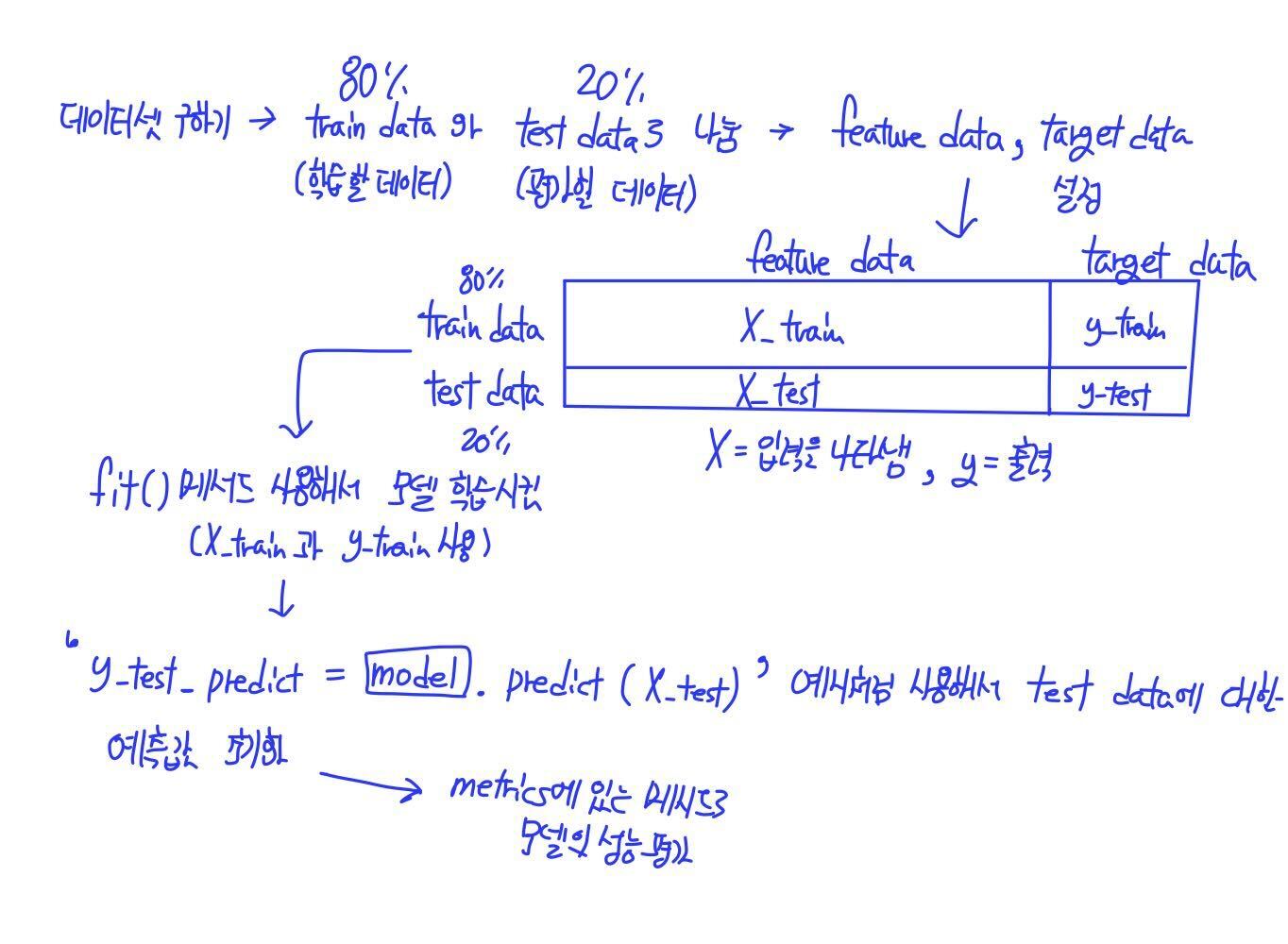
- 지도학습 모델에 학습시키기 위해서 데이터를 처리하는 과정을 포스팅하겠습니다
- 간단한 코드로 이론적인 내용으로 포스팅을 진행하겠습니다.
1. 필요한 데이터셋 읽어오기 (Train_Data / Test_Data)
df_train = pd.read_csv(r'[Dataset]Train.csv')
df_test = pd.read_csv(r'[Dataset]Test.csv')이처럼 필요한 데이터셋을 읽어옵니다. 지도학습은 정답을 알고 있는 상태에서 학습을 진행하여 모델을 만드는 방법이기 때문에 정답을 가지고 있는 train data와 test data가 필요합니다.
2. features data / target data 지정
features = ['setting1','setting2','setting3','s1','s2','s3','s4','s5','s6','s7','s8','s9','s10','s11','s12','s13','s14','s15','s16','s17','s18','s19','s20','s21']
X_train = df_train[features] #train 데이터의 feature data를 X_train으로
y_train = df_train['ttf'] #train data의 target data(ttf)를 y_train에 초기화
X_test = df_test[features] #test data의 특성데이터를 X_test에 초기화
y_test = df_test['ttf'] #test data의 target값을 y_test에 초기화
특성 데이터를 정하고, Train Data의 특성 데이터는 X_train이라는 변수에, Train Data의 target data(정답에 해당하는 데이터)는 y_train으로 초기화합니다.
똑같히 Test Data의 특성 데이터는 X_test이라는 변수에, Test Data의 target data(정답에 해당하는 데이터)는 y_test로 초기화합니다.

3. 필요한 모델에 학습
linreg = linear_model.LinearRegression()
linreg.fit(X_train, y_train) # 학습 데이터의 특성데이터 / 학습 데이터의 타겟 데이터
# 를 사용해서 fit() // 그래프 그림 => linear_model.LinearRegression()을 사용해서 모델에 학습.필요한 모델을 가지고 와서 fit() 함수를 사용하여 학습을 합니다.
지도학습은 정답을 알려주고 학습을 하는 것이니까 X_train(=문제에 해당하는 데이터)와 y_train(=정답에 해당하는 데이터)를 이용하여 학습을 시킵니다.
4. 학습시킨 모델을 사용해서 예측값 구하기
y_test_predict = linreg.predict(X_test) # X_test(=test data의 특성데이터)의 예측값으로 초기화
y_train_predict = linreg.predict(X_train) # X_train(=train data의 특성데이터)의 예측값으로 초기화위에서 fit() 함수를 사용하여 모델에 학습을 시키면 linreg에 학습된 모델이 있으니 predict() 함수를 사용하여 예측값을 알아낼 수 있습니다.
predict() 함수에 X_test(=평가를 위한 문제에 해당하는 데이터)를 사용하여 예측값을 알아냅니다.
5. 예측한 값을 사용하여 모델의 성능을 평가
linreg_metrics = get_regression_metrics('Linear Regression', y_test, y_test_predict)
linreg_metrics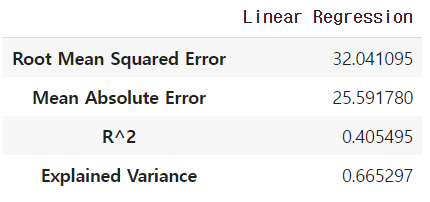
예측한 값을 사용하여 위의 그림처럼 해당 모델의 성능을 평가할 수 있습니다.
이상으로 지도학습에서의 데이터처리 과정에 대한 포스팅을 마치겠습니다!!
추가로 궁금한 점이나 포스팅 내용 중에 수정할 내용이 있다면 편하게 댓글 달아주시면 감사하겠습니다!!
