- 저는 Kanggle에서 제공하는 항공기 센서 데이터셋을 사용하였습니다.
- 지도학습으로 선형회귀 모델을 사용하여 성능을 평가하는 방법을 포스팅하겠습니다.
- 저는 Anaconda/jupyter notebook을 사용하여 코드를 진행하였습니다.
- 지도학습에 대한 내용을 잘 모르신다면 이해하는데 조금 어려움이 있을 수 있습니다.
데이터셋을 다루는 것이 조금 어려운 분들은 앞에서 포스팅했던 내용을 조금 읽고 오시면 좋을 것 같습니다!
진행하는데 필요한 라이브러리
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use('ggplot') #그래프 스타일 지정
%matplotlib inline #notebook을 실행한 브라우저에서 바로 그림을 볼 수 있게 해주는 코드
from sklearn import linear_model
from sklearn import model_selection
from sklearn import metrics #metrics : 평가지표
from sklearn.feature_selection import SelectFromModel, RFECV #특성데이터 지정하는 역할사용할 데이터셋 읽어오기(Read)
Train Data 읽어오기
df_train = pd.read_csv(r'[Dataset]Train.csv')Test Data 읽어오기
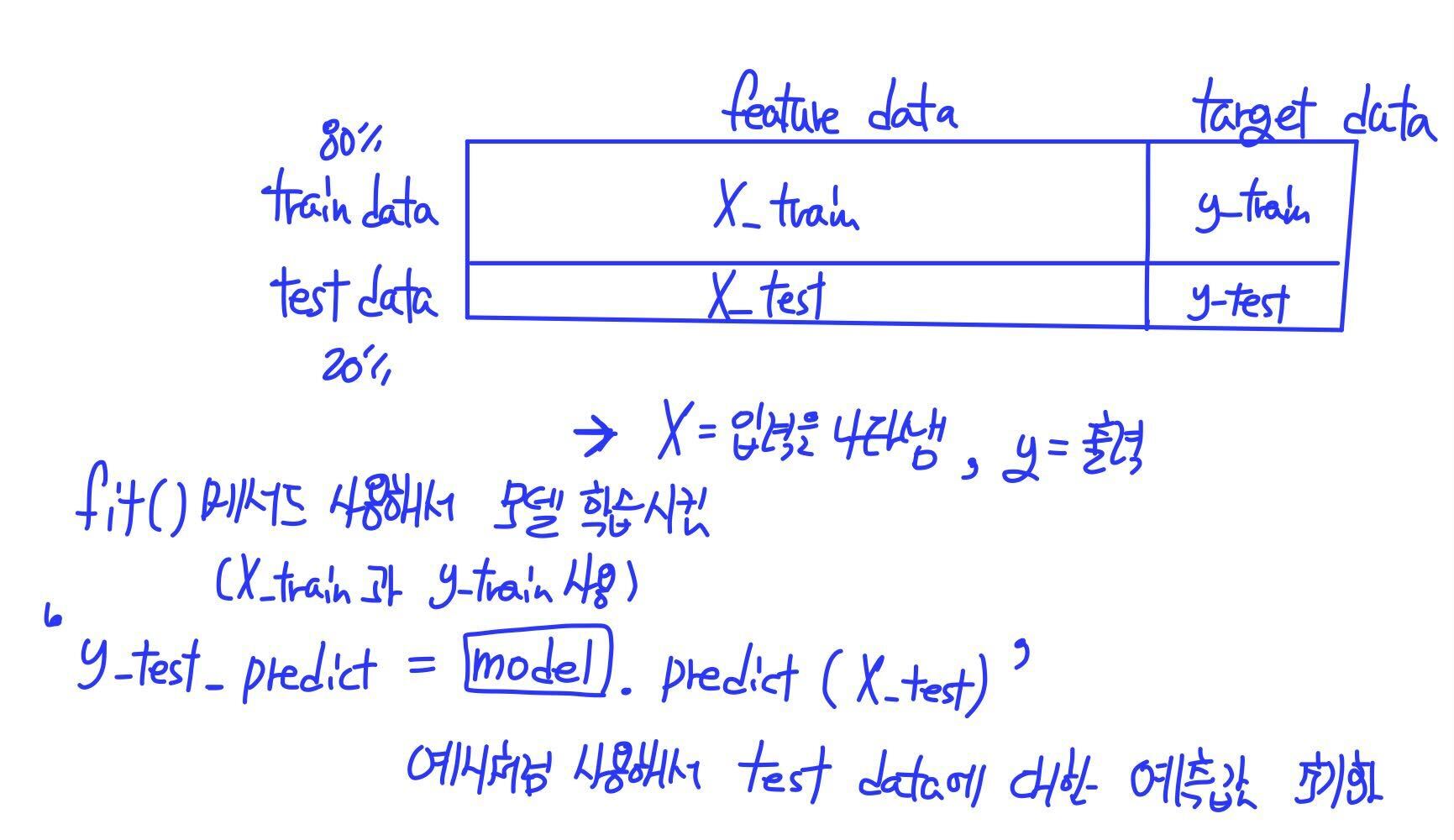
df_test = pd.read_csv(r'[Dataset]Test.csv.csv')Train Data와 Test Data는 하나의 파일에 있던 데이터셋을 80%와 20%로 나눈 파일을 읽어온 데이터셋입니다.
이처럼 사용할 데이터셋을 Train Data와 Test Data 나누는 이유는 전체 데이터셋의 80%에 해당하는 데이터셋을 모델에 학습을 시키는 용도(Train)로 사용하고 나머지 20%를 학습시킨 모델을 평가(Test) 하는 용도로 사용하기 위해서입니다.
칼럼별 결측값 확인하기
df_train.isnull().sum() # 칼럼별 결측값 개수 구하기
데이터프레임 칼럼을 features 배열에 추가(시각화하기 위한 코드)
features = []
for col in df_train.columns:
features.append(col)df_train 칼럼의 표준편차 출력(시각화하기 위한 코드)
df_train[features].std().plot(kind='bar', figsize=(10,6), title="Features Standard Deviation")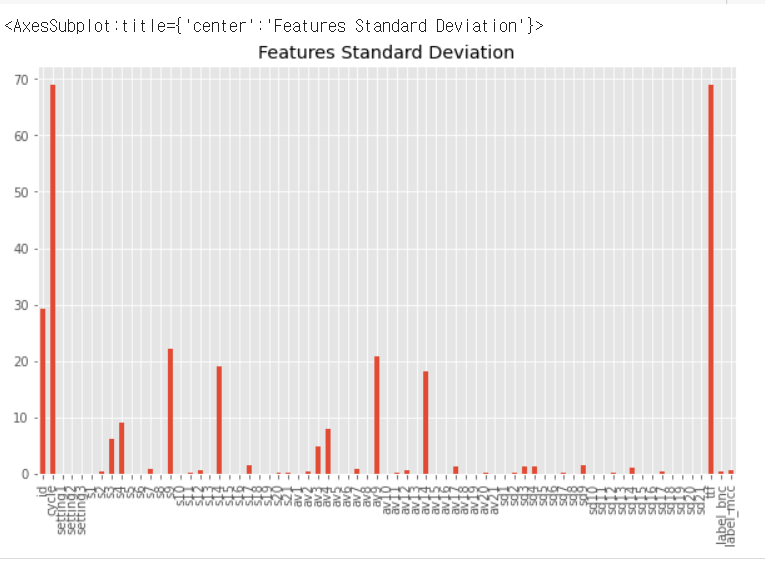
이처럼 plot() 함수를 사용하여 데이터를 시각화 할 수 있습니다.
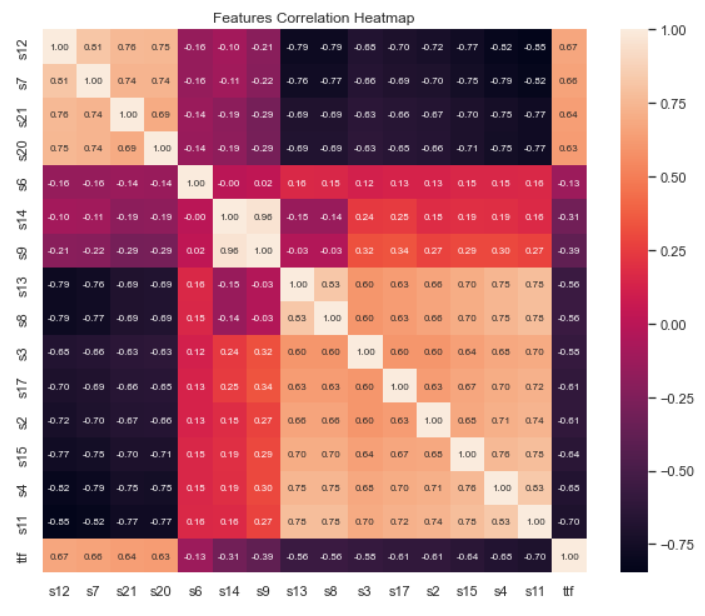
특성데이터들 간의 상관관계를 히트맵으로 출력
feat= ['s12','s7','s21','s20','s6','s14','s9','s13','s8','s3','s17,
's2','s15','s4','s11','ttf']
cm = np.corrcoef(df_train[feat].values.T)
# 피어슨 상관관계를 나타내줌 (관련있는거는 밝은 색 / 관련이 적은 것은 어두운 색으로)
print(cm)
sns.set(font_scale=1.0) #title, x, y축 글자(font)들의 크기
fig = plt.figure(figsize=(10,8)) # 나타내려고 하는 표의 size
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 8}, yticklabels=feat, xticklabels=feat)
plt.title('Features Correlation Heatmap') #annot : 숫자로 표시
plt.show() #fmt : .2f = 소수점 2자리 /코드를 작성하면 아래처럼 특성 데이터 간의 상관관계를 나타내주는 히트맵이라고 하는 표가 나타납니다.
상관관계가 높은 특성 데이터는 연한 색으로 상관관계가 적은 특성 데이터는 어두운색으로 표현하고 있습니다!
가운데 대각선은 모두 자기 자신과의 상관관계를 비교하는 것이므로 가장 상관관계가 높게 나오는 것을 알 수 있습니다.
특성데이터 지정
# 회귀 모델을 위한 데이터를 준비합시다.
# 원본 feature 리스트 입니다.
features_orig = ['setting1','setting2','setting3','s1','s2','s3','s4','s5','s6','s7','s8','s9','s10','s11','s12','s13','s14','s15','s16','s17','s18','s19','s20','s21']
# 회귀 레이블과 상관 관계가 낮거나 없는 feature 리스트 입니다.
features_lowcr = ['setting3', 's1', 's10', 's18','s19','s16','s5', 'setting1', 'setting2']
# 회귀 레이블과 상관 관계가 있는 feature 리스트 입니다.
features_corrl = ['s2', 's3', 's4', 's6', 's7', 's8', 's9', 's11', 's12', 's13', 's14', 's15', 's17', 's20','s21']
# features는 실험할 feature 집합을 보유하는 변수이다.
features = features_orig
print(features)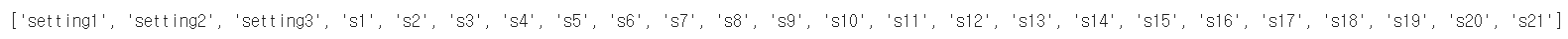
특성데이터(features), 타겟데이터(target) 지정
X_train = df_train[features] #train 데이터의 feature data를 X_train으로
y_train = df_train['ttf'] #train data의 target data(ttf)를 y_train에 초기화
X_test = df_test[features] #test data의 특성데이터를 X_test에 초기화
y_test = df_test['ttf'] #test data의 target값을 y_test에 초기화linear_model에 학습 (선형회귀모델)
- fit() 함수를 사용해서 모델에 학습을 시킵니다
linreg = linear_model.LinearRegression()
linreg.fit(X_train, y_train) # 학습 데이터의 특성데이터 / 학습 데이터의 타겟 데이터
# 를 사용해서 fit() // 그래프 그림 => linear_model.LinearRegression()을 사용해서 모델에 학습.- 학습된 모델에 predict() 함수를 사용하여 X_test(=test data의 input값)을 사용하여 결과를 예측합니다.
y_test_predict = linreg.predict(X_test) # X_test(=test data의 특성데이터)의 예측값으로 초기화
y_train_predict = linreg.predict(X_train) # X_train(=train data의 특성데이터)의 예측값으로 초기화
- 예측을 바탕으로 성능평가를 합니다.
print('R^2 training: %.3f, R^2 test: %.3f' % (
(metrics.r2_score(y_train, y_train_predict)),
(metrics.r2_score(y_test, y_test_predict)))) #성능평가
linreg_metrics = get_regression_metrics('Linear Regression', y_test, y_test_predict)
linreg_metrics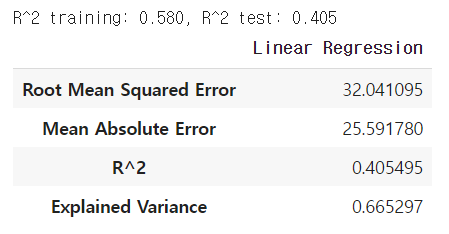
이상으로 선형회귀 모델에 학습을 하는 방법에 대한 포스팅을 마치겠습니다!!
추가로 궁금한 점이나 포스팅 내용 중에 수정할 내용이 있다면 편하게 댓글 달아주시면 감사하겠습니다!!
