머신러닝 알고리즘
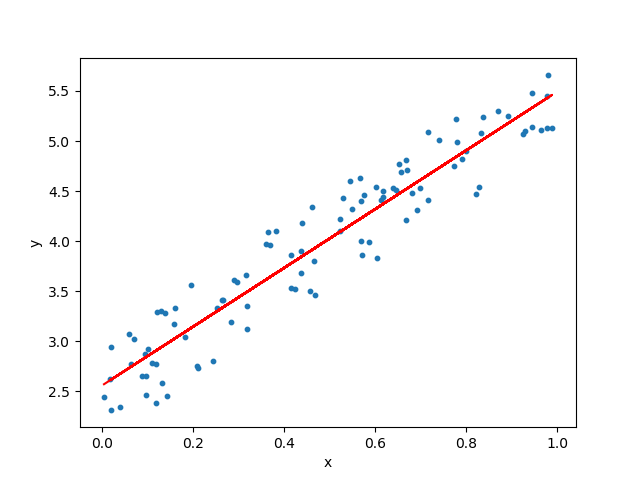
Linear Regression
- 회귀
- y = ax + b 꼴의 직선으로 최적화된 w값 구하는 알고리즘

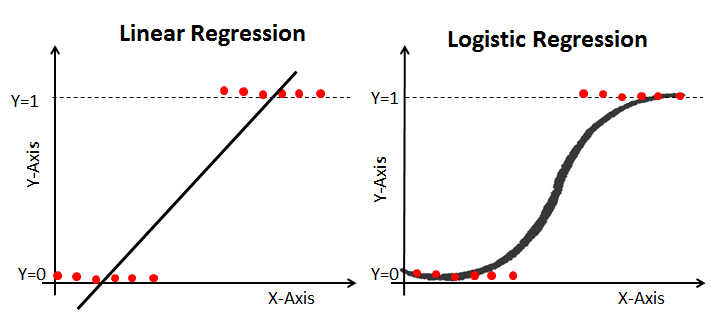
Logistic Regression
- 분류
- 이진 분류 모델.
- 로지스틱 함수(=시그모이드 함수)를 사용하여 로지스틱 회귀 곡선을 만들고, 이진분류
K-Nearest Neighbor
- 새 데이터 입력 시, 기존 데이터에서 새 데이터와의 거리가 가장 가까운 K개 이웃의 정보로 데이터를 예측하는 모델
- 해당 모델에서의 하이퍼파라미터: 가장 가까운 거리에 있는 이웃의 갯수

Decision Tree
- 지도학습 알고리즘
- 데이터를 기반으로 의사 결정 규칙을 학습하고, 이 규칙을 사용하여 새로운 데이터를 예측하거나 분류
Random Forest
-
앙상블: 트리 한 개보다 여러 개의 트리로 예측을 수집하면 모델 성능이 올라감
-
랜덤 포레스트: 결정 트리에 앙상블을 적용한 것

-
각 트리 별 예측 값을 생성하고, 그 중 다수결 원칙에 따라 나온 결과값을 결과로 예측
-
하이퍼파라미터 n_estimators => 트리의 갯수
Ensemble
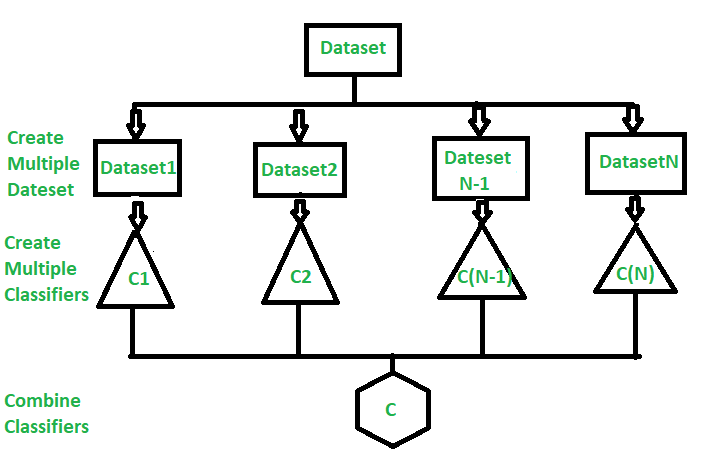 - 여러 개의 분류기(트리) 생성하고, 이를 결합하면서 예측의 정확도를 높이는 것
- 하이퍼파라미터가 중요함
- 여러 개의 분류기(트리) 생성하고, 이를 결합하면서 예측의 정확도를 높이는 것
- 하이퍼파라미터가 중요함
- bagging: parallel (트리가 병렬로 학습됨) (RandomForest) (여러 개의 bootstrap이 서로 영향을 주지 않는 병렬학습)
- boosting: sequential (학습한 데이터의 결과값을 다음 가중치에 반영) (XGBoost, RightGBM) (+ 여러 모델을 순차적으로 학습해서 이전 모델의 결과를 바탕으로 다음 모델을 학습하는 기법)
앙상블의 종류
- Stacking: 개별 모델이 예측한 데이터를 기반으로 final_estimator 종합하여 예측을 수행
- Weighted Blending: 각 모델의 예측값에 대하여 weight를 곱하여 최종 output 계산

💻귀찮으니 필요할 때만 쓰는 Computer Vision 일지 ㅇㅇ💻