머신러닝 프로세스
- 데이터 수집
- 데이터 전처리 (특성 추출 등)
- 모델 선택
- 모델 학습
- 모델 평가
- 하이퍼파라미터 튜닝: 모델의 성능을 최적화 함
- 모델 배포
- 모델 유지보수
머신러닝 학습 과정
Linear Regression (선형 회귀)
y = ax + b (함수) (= 데이터를 가장 잘 표현할 수 있는 직선 모델)
즉, y = wx + b (최적화된 모델을 구할 수 있는 w를 구하는 것이 목표)
- 위 모델을 구하기 위해, Cost function을 사용
Cost function
- Error(Cost): 예측값 - 실제값
- MSE(Cost function): (실제값 - 예측값)^2/N (N은 평균값을 의미)
(* MSE의 결과값은 오차(= 숫자)를 의미하고, 해당 값이 작을수록 모델의 예측이 정확함을 의미) - 해당 값이 작을수록 더 최적화된 w값을 구할 수 있음
Stochastic Gradient Descent (확률적 경사 하강법)

- y값(cost)을 줄여가며, 비용이 가장 작게 되는 w값을 구하는 게 목표
- (MSE와의 연관성) SGD는, 모델이 MSE를 최소화하도록 학습될 때 사용(w값을 최적화함으로서, MSE 시 계산되는 오차들의 값을 줄이는 게 목표)
확률적 경사 하강법 공식

-
gamma는 이동할 거리를 조정하는 매개변수(=학습률, Learning Rate)
-
Learning Rate를 작게 설정하는 것을 권장함

-
-
f(x_i)(= Cost Function)를 미분한 값을 구하고,
-
기존의 W값(= x_i)에서 해당 미분 값을 빼고
-
W를 업데이트하며 최적화된 W값을 구하는 것이 최종 목표
직선별 손실함수를 구하고 => 손실함수의 최솟값을 구하고 => 최적의 직선을 구한다.
머신러닝 종류
지도학습
- 분류(Classification): 이산적으로 나눠지는 데이터(ex 이진분류(긍/부정 대답)) 시 사용
- 예측(Regression): 레이블 값들이 연속적인 경우, 특정 column의 값을 예측하기 위해 사용
- 열: 특징(Feature) (+ 컬럼 중 하나 선택해서 레이블(정답)로 사용)
- 행: 예제(Example)
비지도학습
- 정답(레이블) 없이 데이터를 학습
Confusion matrix (분류모델 시 오차 구하기 위해 사용)
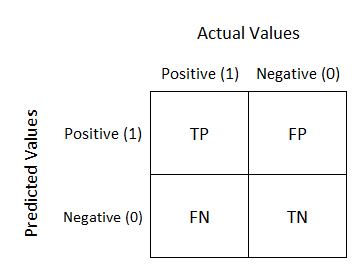
- Accuracy(정확도): (TP + TN) / (TP + FP + FN + TN)
- Recall(재현율): (TP) / (TP + FN)
- Procision(정밀도): (TP) / (TP + FP)
- F1 Score: (2PrecisionRecall) / (Precision+Recall)

💻귀찮으니 필요할 때만 쓰는 Computer Vision 일지 ㅇㅇ💻