
Very Deep Convolutional Networks for Large-Scale Image Recognition, ICLR (2015)
link: https://arxiv.org/abs/1409.1556
public model: https://www.robots.ox.ac.uk/~vgg/research/very_deep/
Introduction
VGGNet은 ILSVRC14(ImageNet Large Scale Visual Recognition Competetion 2014)에서 2등을 한 model의 architecture이다. 당시 1등을 했던 GooLeNet보다 높은 accuracy를 기록하지는 못했지만 복잡한 구성 없이 conv layer, pooling layer, fully connected layer만을 이용하여 간단한 구조로 우수한 성능을 얻었다는 점에서 주목 받았다. 이번 포스트는 VGGNet이 등장하게 된 배경과 자세한 아키텍처, 학습과 테스트 환경에 집중하여 논문을 리뷰한다.
Background
VGGNet을 소개한 논문이 출간 되었을 당시 ImageNet과 같은 거대 데이터셋의 등장과 GPU의 활용으로 convolutional neural network를 이용한 image recognition solution이 각광 받았다. VGGNet 이전에도 convolutional network를 적절히 활용하여 visual recognition 분야에서 높은 성능을 얻고자 하는 시도가 있었으며, 실제로 AlexNet (Krizhevsky et al.)은 deep convolutional neural network를 이용해 ILSVRC12에서 우승하기도 했다.
conv network의 performance를 향상하기 위해서는 feature map의 dimension, receptive field의 크기, conv layer의 stride 등이 있는데, 본 논문에서는 conv network를 쌓는 depth에 집중했다. 크기의 작은 kernel을 이용하여 conv layer를 깊게 쌓음으로써 높은 성능을 기대했다.
👀 Receptive Field (수용 영역)
시각 인지 관련 생물학적 용어로, 컴퓨터 비전에서는 output feature map의 픽셀 하나를 연산할 때 사용되는 input 픽셀의 개수이다. receptive field가 넓을수록 더 넓은 정보를 수용하여 영상을 이애할 수 있다는 이점이 있다.
예를 들어, 크기의 kernel을 사용하면 output feature map의 픽셀 하나는 input image에서 크기의 영역을 수용하여 계산된다.
Architecture
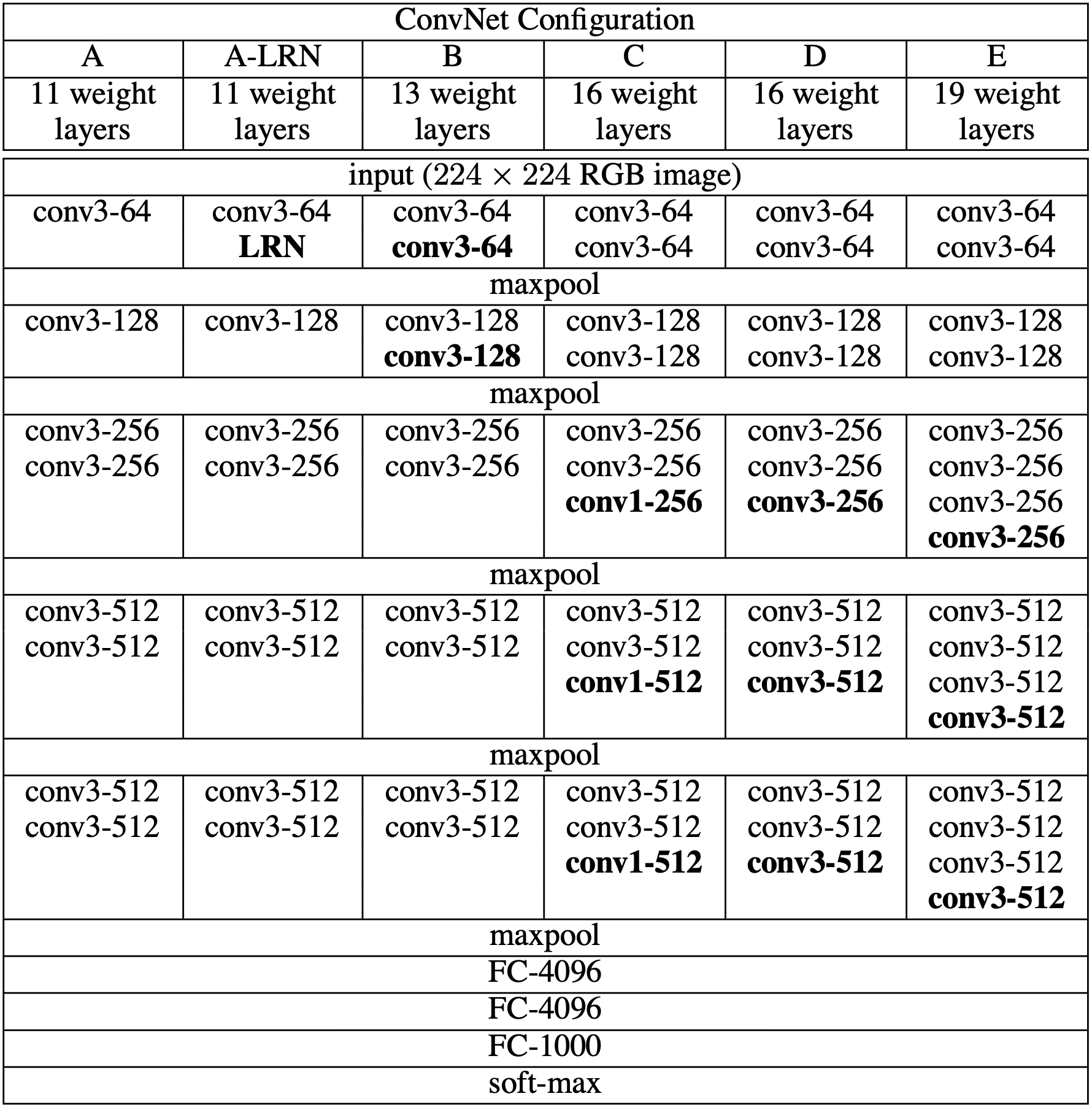
VGGNet은 기본적으로 conv layer와 pooling layer를 깊게 쌓는 구조로 이루어진다. 위 사진에서 볼 수 있듯 깊이에 따라 VGGNet은 A~E로 나뉘는데, 이들은 모두 공통된 방식으로 디자인 되었다. (LRN이 사용된 A-LRN과 kernel이 사용된 C는 뒤에서 논하겠다.)
| component | description |
|---|---|
| kernel size | (상하좌우의 개념이 존재하는 가장 작은 크기) |
| stride | |
| padding | image의 resolution이 변하지 않도록 하는 값으로 적절히 설정 (e.g., 에 대해서는 으로 설정) |
| pooling | kernel size: stride: |
추가적인 디테일은 아래와 같다.
- input image의 크기는 로 고정한다.
- input image의 모든 pixel을 normalize한다. (유일한 preprocessing)
- 총 5개의 pooling layer가 존재하며, pooling layer를 거친 후에는 feature map의 dimension이 2배씩 커진다.
- 앞선 두 개의 fully connected layer는 4096개의 feature를, 마지막 fully connected layer는 1000차원의 output을 출력한다.
- 마지막 fc layer는 softmax에, 나머지 conv / fc layer는 ReLU(rectified linear unit)에 연결된다.
convolution
VGGNet의 선행연구는 대부분 최대한 큰 크기의 kernel을 사용해 넓은 receptive field를 추구했다. 그러나, 본 논문에서는 convolution을 두 번 수행하면 크기의 receptive field를 얻을 수 있으며, 세 번 수행하면 크기의 receptive field를 얻을 수 있다고 설명한다. 또한, 단순히 큰 크기의 kernel을 한번에 적용하는 것보다 convolution을 여러 번 적용하는 것은 아래와 같은 이점이 있다고 논문에서 언급한다.
- 모든 convolution의 output은 ReLU에 feed되므로 convolution을 여러 개로 나누는 것은 decision boundary에 nonlinearity를 부여하는데 효과적이다. nonlinearity가 연결되는 횟수가 1회에서 3회로 늘어나기 때문이다.
- learnable parameter의 수가 줄어든다. 논문에 따르면 conv가 아닌 conv를 이용함으로써 parameter의 수를 약 81% 줄일 수 있다고 한다.
convolution
convolution은 사실상 동일한 차원 사이의 linear projection과 동일하다. 본 논문에서는 차원을 유지하면서 nonlinearity를 부여하기 위해 convolution를 이용했다.
LRN (Local Response Normalization)
측면 억제(lateral inhibition)를 막기 위해 사용되는 normalization으로, ILSVRC12의 승자인 AlexNet (Krizhevsky et al.)이 사용했다. 측면 억제란 신경생물학 용어로, 하나의 뉴런이 주변 뉴런의 활성화를 억제하는 것을 뜻한다.
Aqeel Anwar의 포스트에 따르면 DNN에서의 측면 억제는 local한 활성화가 다음 layer에 잘 전달되기 위해 발생한다. 본 논문의 저자는 LRN이 ILSVRC dataset에 효과적으로 작동하지 않는다고 주장하며 LRN을 적용하지 않았다.
Experiment
Training Configuration
environment setup
| hyperparameter | value | hyperparameter | value |
|---|---|---|---|
| optimizer | SGD | learning rate | |
| momentum | learning rate decay | ||
| epoch | 74 | dropout ratio | |
| batch size | 256 | L2 regularization |
learning rate decay는 validation accuracy가 증가하지 않을 때 발생한다. 전체 학습 과정 중 총 3회 이루어진다.
dropout은 첫 두 개의 fc layer에 적용된다.
weight initialization
VGGNet은 깊은 network를 효과적으로 학습시키기 위해 pretraining 전략을 이용한다. 이는 아래와 같다.
- 가장 간단한 A를 random weight로부터 학습시킨다.
- 이후 깊은 network를 학습시킬 때는 앞 4개, 뒤 3개 conv layer의 weight는 A와 동일하게, 나머지는 random하게 초기화한 뒤 학습시킨다. (pre-trained)
이를 통해 VGGNet은 다른 연구에 비해 더 적은 epoch으로 빠르게 수렴하는 것을 볼 수 있다고 저자는 언급한다.
random weight는 를 따른다.
bias는 으로 초기화된다.
data augmentation
- random crop:
- random horizontal flip
- RGB color shift
input image scaling
본 논문의 저자는 VGGNet을 여러 가지 image scale에 대해 학습시키기 위해 두 가지 전략을 사용했다. 표기의 편의성을 위해 입력 이미지의 짧은 변 길이를 라고 하겠다.
-
single-scale training: 를 고정하여 학습한다. 본 논문의 실험에서는 과 에 대해 실험을 진행했다. 를 학습시키기 위해서는 에 대해 pre-training한 뒤에 의 learning rate로 학습한다.
-
multi-scale training: 각 이미지에 대해 를 특정 범위에서 무작위로 설정한다. 본 논문의 실험에서는 가 sample되는 범위를 로 제한했다. 위 전략과 유사하게 로 pre-train한 뒤에 multi-scale로 학습을 진행한다.
가 sample되는 범위는 로 표기한다.
💡 위 전략을 이용하여 비율은 유지한 채로 이미지를 rescale한 뒤 random crop이 적용된다.
Test Configuration
classification
training과 유사하게 우선 입력 이미지의 짧은 변의 길이가 가 되도록 비율을 유지한 채로 rescale한다. 이후, fc layers를 conv layer로 변환한다. fully-convolutional network를 이용하므로 입력 이미지는 임의의 크기를 가질 수 있다. 따라서 이미지의 crop없이 network에 feed한다.
💡 fc layer를 conv layer로 변환하는 것에 대한 디테일은 Stanford CS231n를 참고한다.
network의 최종 출력이 vector가 아닌 tensor (class 개수 만큼의 깊이를 갖는) 이므로, global average pooling을 적용하여 class score vector로 변환한다.
data augmentation으로 horizontal flip을 적용했을 때의 class score vector와 원본 이미지의 class score vector를 평균낸 뒤 softmax를 적용하여 이미지의 최종 class score를 계산한다.
input image sampling
AlexNet (Krizhevsky et al.)은 multi-crop 전략을 이용하여 정확도를 높였다.
🔥 multi-crop은 하나의 이미지를 여러 가지로 crop한 뒤, 각각을 classification하여 평균값을 취하는 것을 말한다.
그러나, VGGNet은 test-time에서 fully convolutional network의 구조를 가지므로 multi-crop 없이도 작동하며, 오히려 이는 추가적인 리소스를 요구한다.
이렇게 fully convolutional network를 이용하여 이미지 전체에 대한 evaluation을 진행하는 것을 dense evaluation이라고 칭한다. 본 논문에서는 dense evaluation을 이용함으로써 전반적으로 더 넓은 receptive field를 가질 수 있다고 설명한다.
Results
Evaluation Metrics
-
top-1 error: network가 틀리게 판단한 image의 비율
-
top-5 error: network가 판단한 5개의 상위 class에 ground truth가 속하지 않는 image의 비율 (ILSVRC에서 채택한 평가 기준)
Single Scale Evaluation
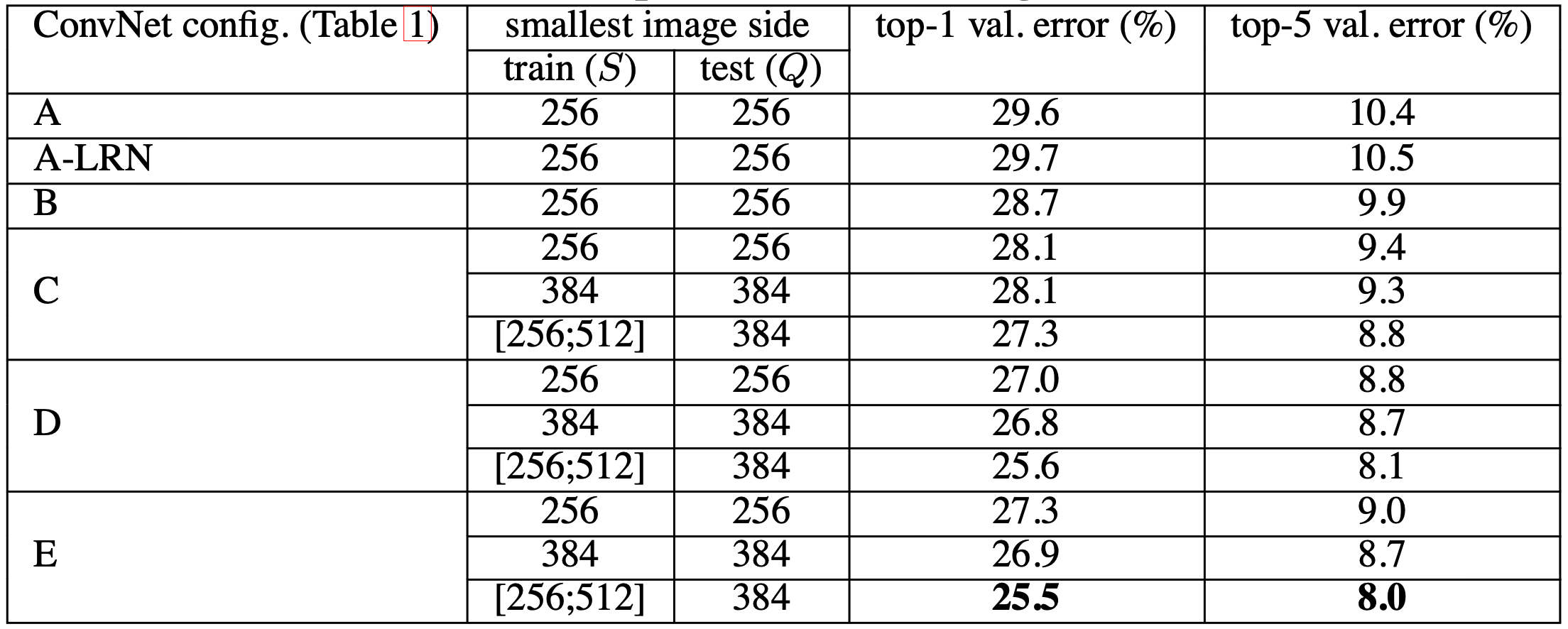
- LRN normalization으로 인한 성능 향상은 거의 발생하지 않았다. (A와 A-LRN 비교)
- network의 구조가 깊어질수록 error가 감소했다.
- B의 한 쌍의 conv layer를 하나의 conv layer로 바꿨을 때 top-1 error가 7% 더 증가했다.
- training 과정에서 scale jittering을 사용했을 때 가시적인 성능 향상이 발생했다. 즉, scale jittering은 다양한 크기의 이미지 특징을 이해하는데 도움을 준다.
Multi Scale Evaluation
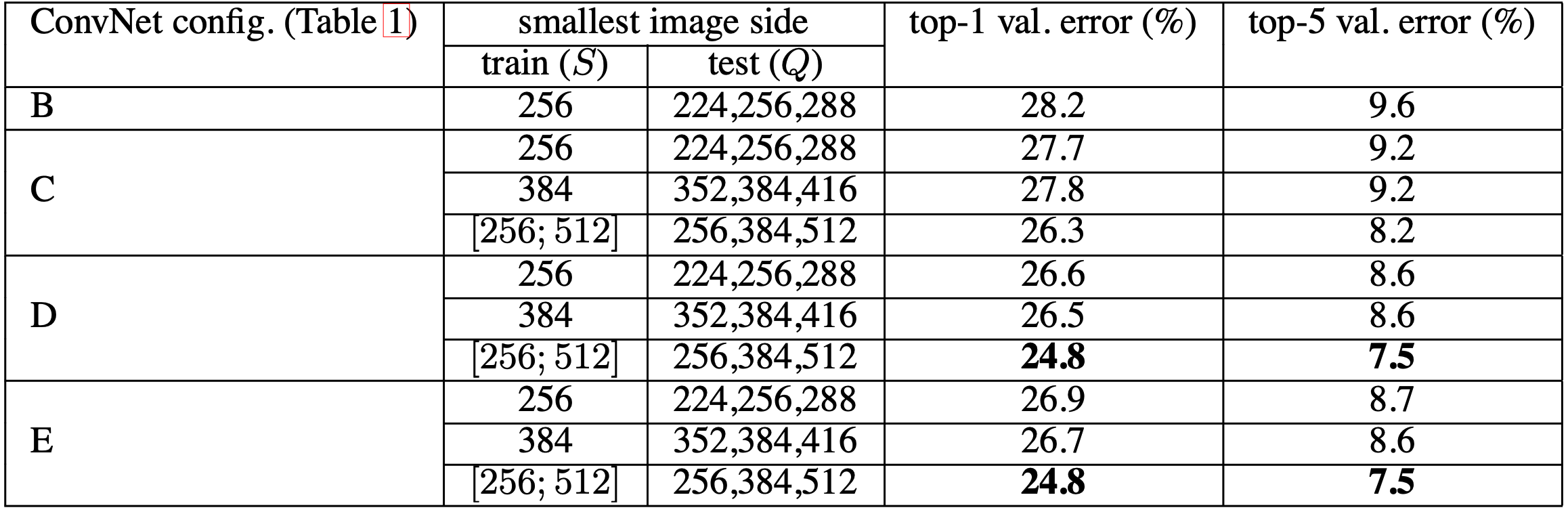
이번 실험은 여러 가지 크기로 rescale된 test image에 대해 classification을 진행한 뒤 얻은 평균값으로 평가한다. training scale과 test scale이 크게 다른 경우 성능 하락이 발생할 수 있기 때문에 는 으로 설정되었다.
scale jittering이 적용된 경우 는 으로 설정된다. 실험 결과는 아래와 같다.
- test-time에서 적용된 scale jittering이 성능 향상에 도움이 되었다. (single scale evaluation의 동일 모델과 비교)
- 깊이가 깊을수록 우수한 성능을 보였다.
- training 과정에서 scale jittering을 사용했을 때 성능 향상이 있었다.
Multi Crop Evaluation
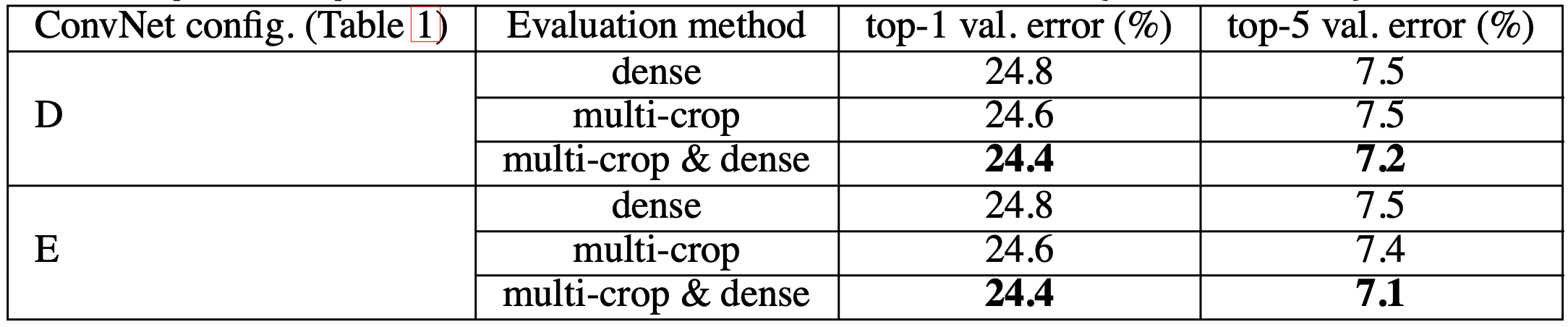
- dense evaluation에 비해 multi-crop evaluation이 약간 더 우수한 성능을 보인다.
- 두 가지를 모두 사용했을 때 가장 좋은 결과를 얻을 수 있다.
Network Fusion

여러 개의 network의 softmax output의 평균값을 취할 때 더 우수한 성능을 얻을 수 있다. 특히, network D와 E의 평균값을 취한 뒤 multi-crop과 dense evaluation을 모두 적용했을 때 가장 낮은 error를 얻었다.
Comparison with SOTA
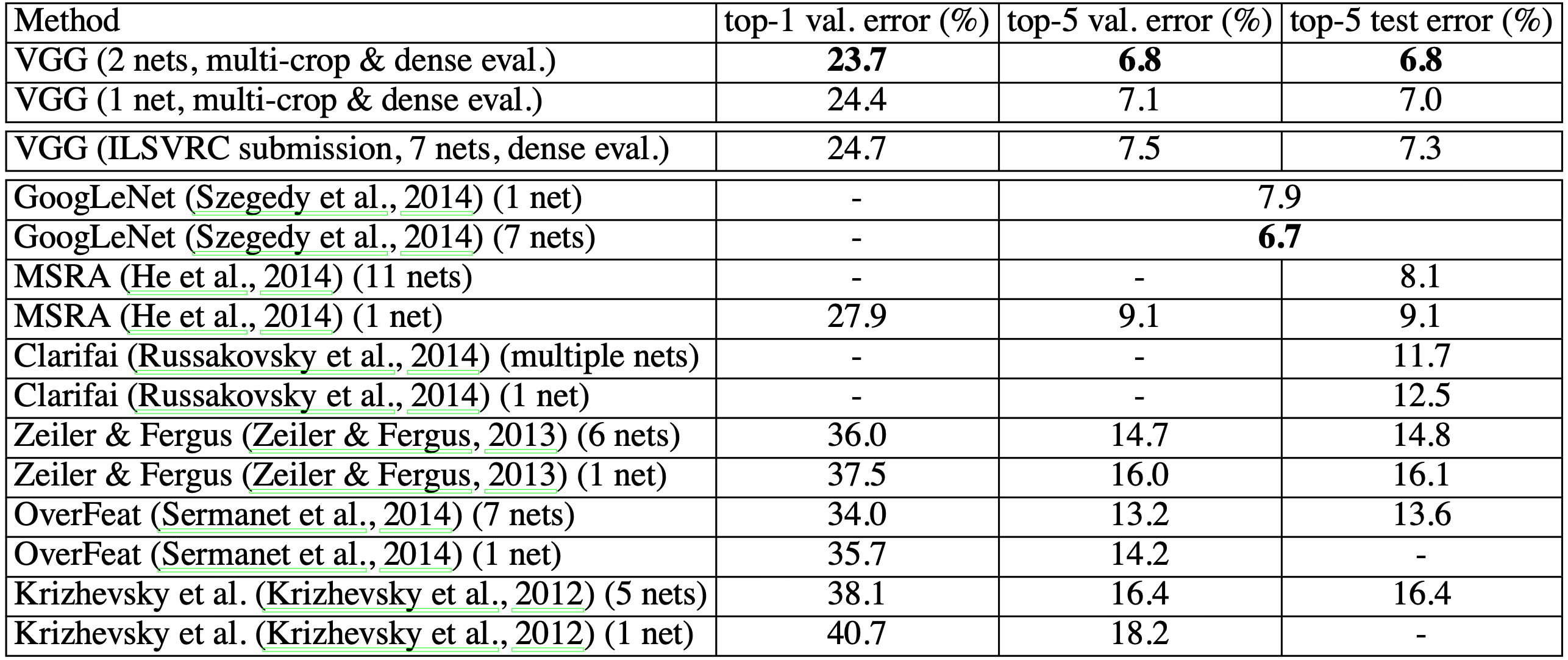
state-of-the-art network와 비교했을 때 VGGNet의 성능은 매우 우수한 것을 볼 수 있다. 단일 network에 대해서는 ILSVRC12의 winner인 GoogLeNet을 능가했으며, 두 개의 network만을 혼합함으로써 최고의 결과를 얻어내는 network configuration을 만들 수 있었다.
뿐만 아니라, 고전적인 convolutional neural network의 구조를 유지한 채로 깊은 network를 구성함으로써 우수한 성능을 얻었다는 점에서 인상적인 연구 결과이다.
Conclusion
본 논문은 network를 깊게 구성함으로써 높은 정확도에 도달할 수 있음을 실험적으로 확인한 논문이다. 또한, 앞서 언급했듯 간단히 고전적인 convolutional neural network의 구조에 기반을 두면서 ILSVRC의 state-of-the-art 수준의 performance를 얻을 수 있었다.
본 연구에서 제안한 아키텍처는 ImageNet에 대한 image classification task뿐만 아니라 다른 dataset에도 잘 generalize되며, action classification, object detection, object localization 등의 task에 또한 적용할 수 있다는 점에서 의의가 있다.
