
원핫인코딩(One-hot encoding)
- 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식
- 단어의 개수가 늘어날 수록 벡터를 저장하기 위해 필요한 공간이 계속 늘어난다는 단점이 있음(벡터의 차원이 계속 늘어남)
Feature selection(특성선택)
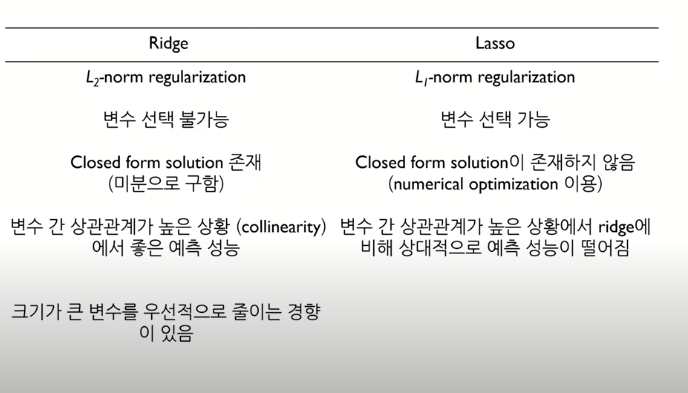
- Wrapper method : 모델링 돌리면서 변수 채택
- Filter Method : 전처리단에서 통계기법 사용하여 변수 채택
- Embedded method : 라쏘, 릿지, 엘라스틱넷 등 내장함수 사용하여 변수 채택
Ridge Regression 모델
- Ridge 회귀는 기존 다중회귀선을 훈련데이터에 덜 적합이 되도록 만든다는 것
- :
- n: 샘플수, p: 특성수, : 튜닝 파라미터(패널티)
참고: alpha, lambda, regularization parameter, penalty term 모두 같은 뜻
- Ridge 회귀는
과적합을 줄이기 위해서사용하는 것 - 과적합을 줄이는 간단한 방법 중 한 가지는 모델의 복잡도를 줄이는 방법
- 특성의 갯수를 줄이거나 모델을 단순한 모양으로 적합하는 것
Ridge 회귀는 이 편향을 조금 더하고, 분산을 줄이는 방법으로 정규화(Regularization)를 수행- 정규화의 강도를 조절해주는 패널티값인 람다의 성질
- → 0, →
- → ∞, → 0.
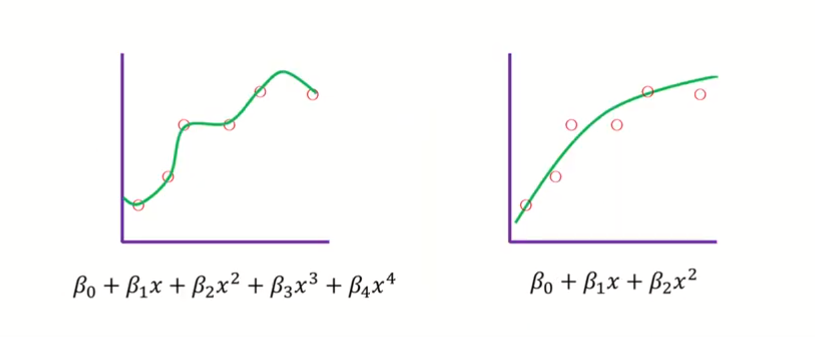
- 기존의 OLS(Ordinary Least Squares)가 아래에 보이는 제약조건까지 와야지 최적값이라고 할 수 있는 것
- OLS가 제약조건까지 오기 위해서는 RSS(RSS : residual sum of squares) 크기를 키워주게 됨
- bias가 약간의 희생은 하지만 variance를 줄이기 위해서 아래의 그림처럼 제약조건까지 오는 가장 작은 RSS를 고르면 됨
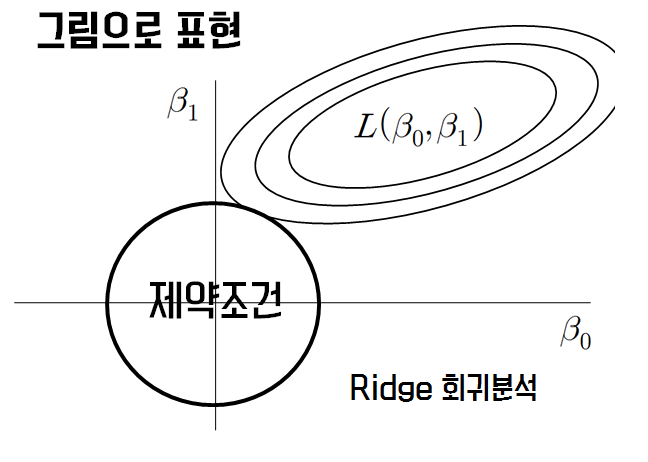
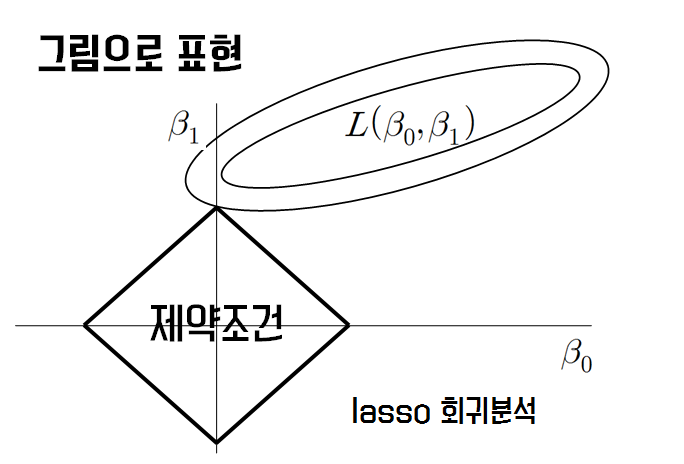
릿지회귀 참조 사이트

일단 저지르자! 그리고 해결하자!