- 데이터 전처리(Data Preprocessing) 란?
데이터에서 결측치(NA) 및 이상치를 확인하여 제거하는 과정
혹은, 데이터를 분석하기전에 데이터를 변형하는 작업(형태 변형 등,,)
따라서 탐색적 자료 분석이 선행되어야 한다.
한국 20대 남성의 연봉 조사한다고 해보자.
data_new
성별 나이 연봉 지역 구매제품 0
0 m 21 3300 서울 핸드폰케이스 20-25
1 f 22 5000 경기 마스크 20-25
2 f 25 5200 경기 마스크 25-30
3 f 32 2000 서울 핸드폰케이스 30-35
4 m 27 1800 부산 마스크 25-30
... ... ... ... ... ... ...
194 m 28 3400 경기 노트북 25-30
195 f 28 2800 서울 화장품 25-30
196 m 27 3500 경기 화장품 25-30
197 f 23 1900 경기 노트북 20-25
198 m 29 2800 서울 핸드폰케이스 25-30
199 rows × 6 columns
data_new.iloc[:,3].value_counts()
서울 90
경기 63
부산 26
제주 6
강원 5
세종 4
울산 3
전주 2
Name: 지역, dtype: int64
👉 이 데이터에서 울산, 전주 데이터는 분석하기에 너무 적은 수로 판단된다. 따라서 이를 제거해보자
state_select=['서울','경기','부산','제주','강원','세종']
data_state_select=data_new[data_new.iloc[:,3].isin(state_select)]
data_state_select
성별 나이 연봉 지역 구매제품 0
0 m 21 3300 서울 핸드폰케이스 20-25
1 f 22 5000 경기 마스크 20-25
2 f 25 5200 경기 마스크 25-30
3 f 32 2000 서울 핸드폰케이스 30-35
4 m 27 1800 부산 마스크 25-30
... ... ... ... ... ... ...
194 m 28 3400 경기 노트북 25-30
195 f 28 2800 서울 화장품 25-30
196 m 27 3500 경기 화장품 25-30
197 f 23 1900 경기 노트북 20-25
198 m 29 2800 서울 핸드폰케이스 25-30
194 rows × 6 columns
> *참고* isin 구문
Python에서 테이블 형식의 데이터를 읽고 처리할 때 가장 많이 쓰이는 pandas 라이브러리에서는 다양한 데이터 처리 기능을 구현하고 있다.
이 중에 isin 구문은 열이 list의 값들을 포함하고 있는 모든 행들을 골라낼 때 주로 쓰인다.
EX)
df = DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'f']})
df.isin([1, 3, 12, 'a'])
* 연령대를 살펴보자
data_new.iloc[:,-1].value_counts()
25-30 72
20-25 67
30-35 34
35-40 15
10 9
40-45 2
Name: 0, dtype: int64
👉 연령대에 대한 빈도수 데이터를 살펴보게되면 40-45 고객 데이터수가 2개 이므로 제거한다.
age_select=['10','20-25','25-30','30-35','35-40']
data_as_select=data_state_select[data_state_select.iloc[:,-1].isin(age_select)]
data_as_select
성별 나이 연봉 지역 구매제품 0
0 m 21 3300 서울 핸드폰케이스 20-25
1 f 22 5000 경기 마스크 20-25
2 f 25 5200 경기 마스크 25-30
3 f 32 2000 서울 핸드폰케이스 30-35
4 m 27 1800 부산 마스크 25-30
... ... ... ... ... ... ...
194 m 28 3400 경기 노트북 25-30
195 f 28 2800 서울 화장품 25-30
196 m 27 3500 경기 화장품 25-30
197 f 23 1900 경기 노트북 20-25
198 m 29 2800 서울 핸드폰케이스 25-30
193 rows × 6 columns👉 이런식으로 데이터 전처리 진행
마크스 상품 A,B,C,D에 대하여 년도별 판매개수 데이터를 아래와 같이 가지고있다고 할 때, 인기있는 마스크 상품을 찾아보자.
data2=pd.read_excel('data2.xlsx')
data2.index=data2.iloc[:,0]
data2=data2.iloc[:,1:]
data2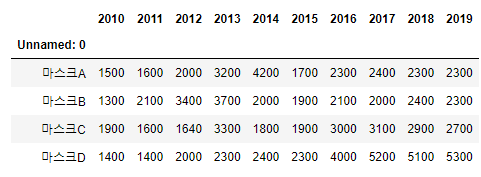
- 각 년도별 마스크 총 판매수를 나눔으로써, 각 마스크 상품에 대한 관심도를 알 수 있다.
- 2010년도에 마스크 A가 구매되는 비율 = 2010년도의 마스크 A의 관심도
sum_data=data2.sum().values
for i in range(0,10):
data2.iloc[:,i] = data2.iloc[:,i] /sum_data[i] 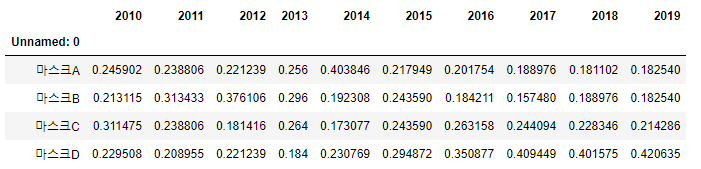
마스크 A
plt.plot(data2.iloc[0,:] )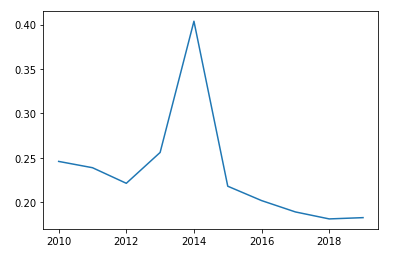
👉 인기가 갑자기 많아졌다 급격하게 감소
마스크 B
plt.plot(data2.iloc[1,:] )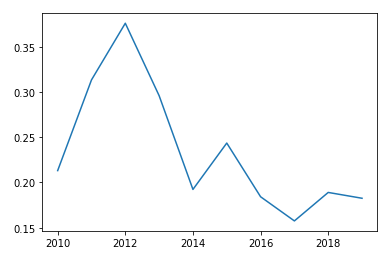
👉 인기가 조금씩 사그라 드는 제품
마스크 C
plt.plot(data2.iloc[2,:] )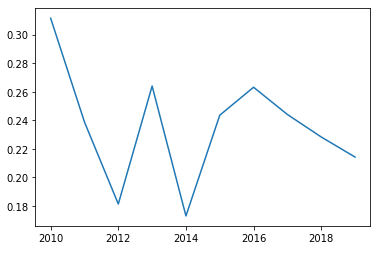
👉 인기가 매년 급격하게 바뀌는 것으로 보임. 생긴지 얼마 안된 생산 업체 추측 가능
또한 트렌드에 민감한 제품
마스크 D
plt.plot(data2.iloc[3,:] )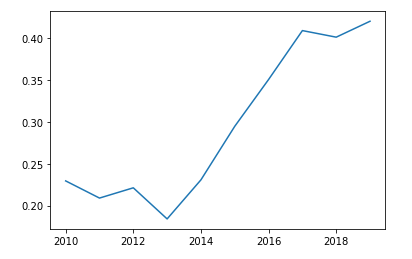
👉 다른 제품들에 비하여 인가 고속 성장,
D마크스가 가장 인기가 많은 제품임을 알 수 있음

안녕하세요 공부한 내용을 기록하기 위해서 시작했습니다.