탐색적 자료분석 방안 < Lift Score >
1) Lift score 정의
- Psi(아이템k) = 그룹 si에서 아이템 k를 구매할 확률
- Xsi(아이템k) = 그룹 si에서 아이템 k를 구매할 확률 / 각 그룹마다 아이템 k를 구매할 확률의 평균 : 그룹 si에서 아이템 k에 대한 Score
- 각 그룹에서 아이템 k를 구매할 확률이 비슷하다면, 즉
Psi(아이템k) ~ .. ~ Psn(아이템 k) => Xsi(아이템k) = 1 - If Xi(아이템k) > 1 : 다른 그룹 보다 그룹 Si에 아이템 k가 상대적으로 더 많이 포함
- If Xi(아이템k) ↗ : 그룹 Si가 아이템 k를 많이 산다.
- 즉, lift score를 기준으로 해당 그룹이 아이템k를 다른 그룹에 많이 포함되어 있거나 적게 포함되어 있다고 판단할 수 있다.
2) Lift를 이용한 데이터 분석
- 데이터를 연령대별로 나눔 10대, 20대초반, 20대후반, 30대 초, 30대 후반, 40대
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import plotly.express as px
data=pd.read_excel('data.xlsx')
age=[]
for i in range(0,len(data)) :
if data.iloc[i,1] < 20 :
age.append('10')
elif data.iloc[i,1] <25 and data.iloc[i,1] >= 20 :
age.append('20-25')
elif data.iloc[i,1] < 30 and data.iloc[i,1] >= 25 :
age.append('25-30')
elif data.iloc[i,1] <35 and data.iloc[i,1] >=30 :
age.append('30-35')
elif data.iloc[i,1] <40 and data.iloc[i,1] >=35 :
age.append('35-40')
elif data.iloc[i,1] <45 and data.iloc[i,1] >=40 :
age.append('40-45')
data_new=pd.concat([data,pd.DataFrame(age)],axis=1)
1. 10대
data_10=data_new.loc[data_new.iloc[:,5] == '10']
data_10.iloc[:,0].value_counts()
m 5
f 4
Name: 성별, dtype: int64
data_10.iloc[:,3].value_counts()
경기 5
부산 2
강원 1
전주 1
Name: 지역, dtype: int64
data_10.iloc[:,4].value_counts()
핸드폰케이스 3
화장품 3
마스크 2
자동차용품 1
Name: 구매제품, dtype: int64
2. 20대 초반
data_20_1=data_new.loc[data_new.iloc[:,5] == '20-25']
data_20_1.iloc[:,0].value_counts()
m 39
f 28
Name: 성별, dtype: int64
data_20_1.iloc[:,3].value_counts()
서울 30
경기 21
부산 9
강원 3
제주 2
세종 2
Name: 지역, dtype: int64
data_20_1.iloc[:,4].value_counts()
노트북 18
마스크 14
핸드폰케이스 12
화장품 12
자동차용품 11
Name: 구매제품, dtype: int64
> 20대 후반 , 30대 초반, .. , 40대까지 동일
> 이렇게 보면 다른 연령대에 비해 특이한 점 발견하기가 어려움
4. 각 연령대 특징 파악 10대 - 성별
* 10대 그룹에서 남자와 여자에 대한 Lift Score를 계산해보자
gender_data=[]
gender=['f','m']
for i in range(0,2):
g=gender[i]
a10= len( data_10[data_10.iloc[:,0] == g ] ) / len(data_10)
a20_1= len( data_20_1[data_20_1.iloc[:,0] == g ] ) / len(data_20_1)
a20_2= len( data_20_2[data_20_2.iloc[:,0] == g ] ) / len(data_20_2)
a30_1= len( data_30_1[data_30_1.iloc[:,0] == g ] ) / len(data_30_1)
a30_2= len( data_30_2[data_30_2.iloc[:,0] == g ] ) / len(data_30_2)
a40= len( data_40[data_40.iloc[:,0] == g ] ) / len(data_40)
T= a10/(a10+a20_1+a20_2+a30_1+a30_2+a40)
T=T*6
gender_data.append(T)
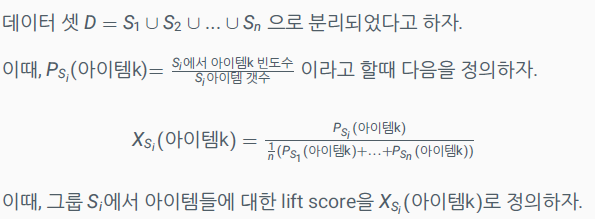
px.bar( x=gender , y=gender_data) 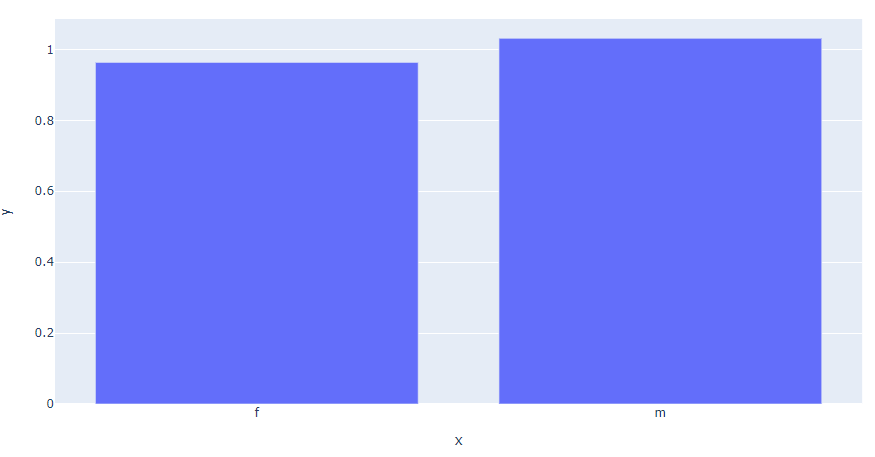
👉 m > 1 : 남자의 lift score가 1 이상이므로 다른 그룹에 비하여 10대 고객 그룹에 남자가 더 많이 포함되어있다고 해석
4-1) 각 연령대 특징 파악 10대 - 지역
* 데이터 전체에 대한 각 지역별 고객 빈도수
data.iloc[:,3].value_counts()
서울 90
경기 63
부산 26
제주 6
강원 5
세종 4
울산 3
전주 2
Name: 지역, dtype: int64
* 위 함수 계산
def cal_prob(data,name):
if len(data.loc[data.iloc[:,3] == name]) !=0 :
a= len(data.loc[data.iloc[:,3] == name])/ len(data)
else:
a=0
return a
* 각 지역에 대한 Lift Score를 계산해보자.
X{10대}[서울],X{10대}[경기],...,X{10대}[전주]
state_name=['서울','경기','부산','제주','강원','세종','울산','전주']
state_data=[]
for i in range(0,8):
name=state_name[i]
b10= cal_prob(data_10,name)
b20_1=cal_prob(data_20_1,name)
b20_2=cal_prob(data_20_2,name)
b30_1=cal_prob(data_30_1,name)
b30_2=cal_prob(data_30_2,name)
b40=cal_prob(data_40,name)
T=b10/(b10+b20_1+b20_2+b30_1+b30_2+b40)
T=T*6
state_data.append(T)
px.bar( x=state_name, y=state_data)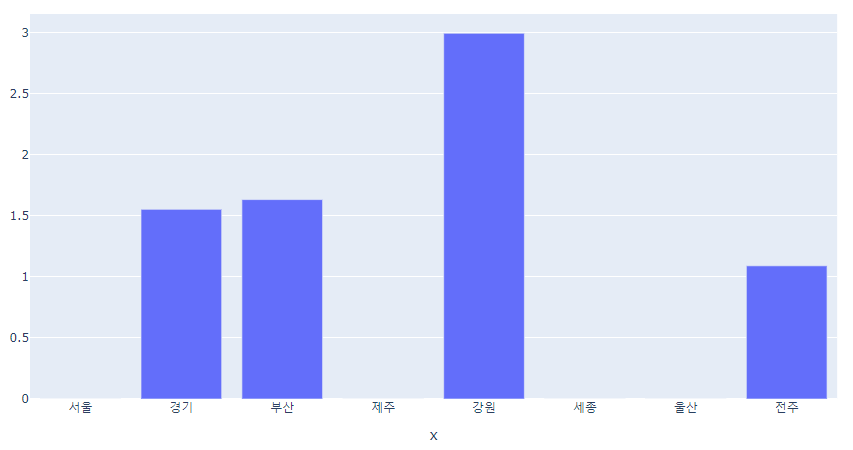
👉 10대 그룹은 강원도 거주 비율이 상대적으로 높다.
👉 max Lift Score = 8
4-2) 각 연령대 특징 파악 10대 - 구매품목
data.iloc[:,4].value_counts()
마스크 50
노트북 49
화장품 38
자동차용품 31
핸드폰케이스 31
Name: 구매제품, dtype: int64
* 구매품목에 대한 확률을 구하는 함수
def cal_prob_product(data,name):
if len(data.loc[data.iloc[:,4] == name]) !=0 :
a= len(data.loc[data.iloc[:,4] == name])/ len(data)
else:
a=0
return a
* 각 구매 품목에 대한 Lift Score를 계산해보자.
X{10대}[마스크],X{10대}[노트북],...,X{10대}[자동차용품]
product_name=['마스크','노트북','화장품','핸드폰케이스','자동차용품']
product_data=[]
for i in range(0,5):
name=product_name[i]
b10= cal_prob_product(data_10,name)
b20_1=cal_prob_product(data_20_1,name)
b20_2=cal_prob_product(data_20_2,name)
b30_1=cal_prob_product(data_30_1,name)
b30_2=cal_prob_product(data_30_2,name)
b40=cal_prob_product(data_40,name)
T=b10/(b10+b20_1+b20_2+b30_1+b30_2+b40)
T=T*6
product_data.append(T)
px.bar( x=product_name, y=product_data)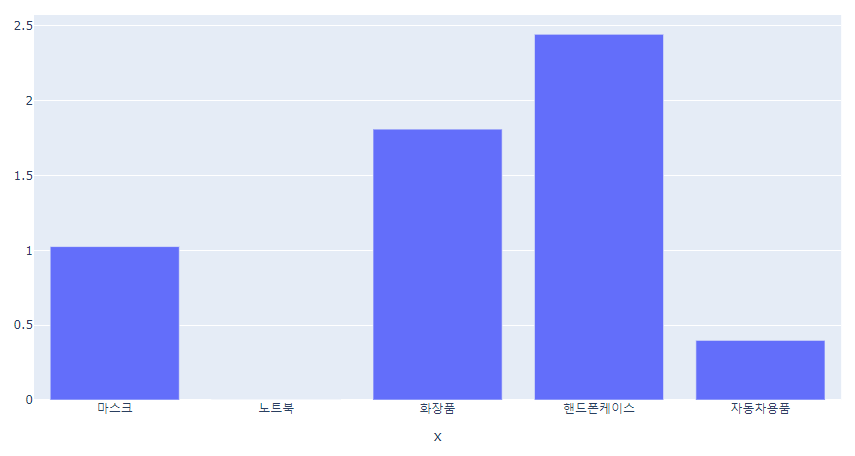
👉 10대들은 핸드폰케이스와 화장품을 다른 그룹에 비해 많이 구매하는 것을 알 수 있다.
👉 이와 동일하게 다른 연령대도 분석 할 수 있음
👉 Lift Score를 이용하게 되면 "다른 그룹"에 비하여, 얼만큼 더 많이 포함되어 있는지와 각 그룹에서의 선호도(관심도)를 쉽게 알 수 있다.
👉 그룹안에서의 비교 가능 & 다른 그룹간의 비교도 가능

안녕하세요 공부한 내용을 기록하기 위해서 시작했습니다.