
from sklearn.tree import DecisionTreeClassifier
feature_names = ['pclass', 'sex', 'fare', 'Embarked_C', 'Embarked_Q', 'Embarked_S']
label_name = 'survived'
X = titanic_data[feature_names]
y = titanic_data[label_name]
model = DecisionTreeClassifier(max_depth=3, random_state=13)
model.fit(X_train, y_train)결정트리를 만들기 위해 타이타닉 데이터를 이용하여 모델을 학습시키는데
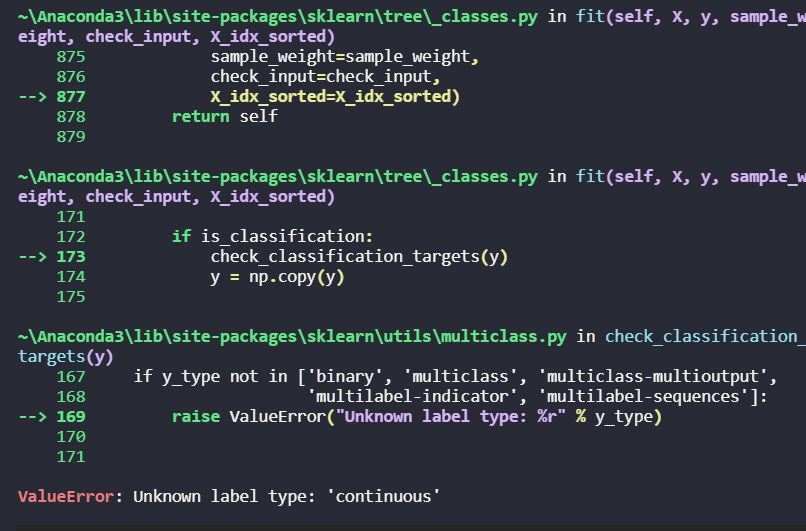
위의 사진과 같은 에러가 발생했다.
검색결과 타입의 문제라는 결론이 생겼다.
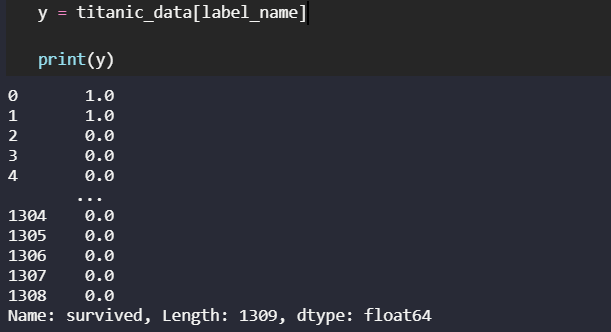
현재 사진과 같이 y 데이터의 타입은 float로 되어있는데, 이진분류를 위한 0과 1의 값은 int형이어야한다는 것이다...
feature_names = ['pclass', 'sex', 'fare', 'Embarked_C', 'Embarked_Q', 'Embarked_S']
label_name = 'survived'
X = titanic_data[feature_names]
titanic_data = titanic_data.astype({'survived': 'int'})
y = titanic_data[label_name]따라서 데이터프레임의 y데이터를 형변환 시켜주었다.
문제해결!
이로인해 배운 데이터 프레임일 경우 데이터 타입 변경하는 방법!
df = df.astype('float')데이터 프레임의 모든 열의 데이터 타입을 변환해주는 방법이다.

원래의 데이터는 object와 float64였는데 이를 모두 int형으로 바꿔주었다.
만약 단일 열만 데이터 타입을 변경하고 싶다면
df = df.astypes({'sex':'int'})
sex열의 데이터타입만 int형으로 바뀌게 된다.

안녕하세요 ㅎㅎ