
요즘 아주 Hot한 강화학습을 리뷰하기 위해 가장 기본이 되는 논문을 읽어보았다.
Absctract
강화학습을 사용해 학습하는 최초의 모델 제시.
Q-Learning의 변형으로 만든 convolutional neural network Input은 Pixel이지만 output은 미래의 rewards를 추정하는 value function이다.
architecture 나 learning algorithm을 수정하지 않고 Atari game에 적용하여 결과를 보았을 때 6개 영역에서 이전 모든 접근방식을 능가하고 3개의 영역에서 인간 전문가를 능가한다.
Introduction
Vision과 NLP 영역에서 supervised, unsupervised 모두 성공을 이뤘다. 이 시점에서 필자는 RL이 유사 상황에서 성능의 궁금증 해결이 필요함을 말하고 있다.
RL의 중요 과제
sparse, noisy and delayed 환경에서 scalar reward signal에서 학습할 수 있어야 한다.
- SL은 Handed Labeled Data 사용
- RL의 action과 reward 사이의 연관성을 찾는 것은 SL의 input과 target의 연관성을 찾는것 보다 어렵다.
대부분 DL은 Data sample이 독립적이라 가정하지만 RL은 일반적으로 상관관계가 높은 상태의 sequence를 접한다.
또한 Data의 분포가 고정되어있는 DL에 반해 RL은 새로운 동작을 습득함에 따라 Data 분포가 변한다.
이 논문은 RL 환경에서 CNN 학습을 성공시킨다.
stochastic gradient descent 와 Q-Learning 알고리즘의 변형으로 학습된다.
High-dimensional input의 Atari game에 적용하였고 좋은 결과를 보였다.
(210 × 160 RGB video at 60Hz)
Background
논문 외 부분
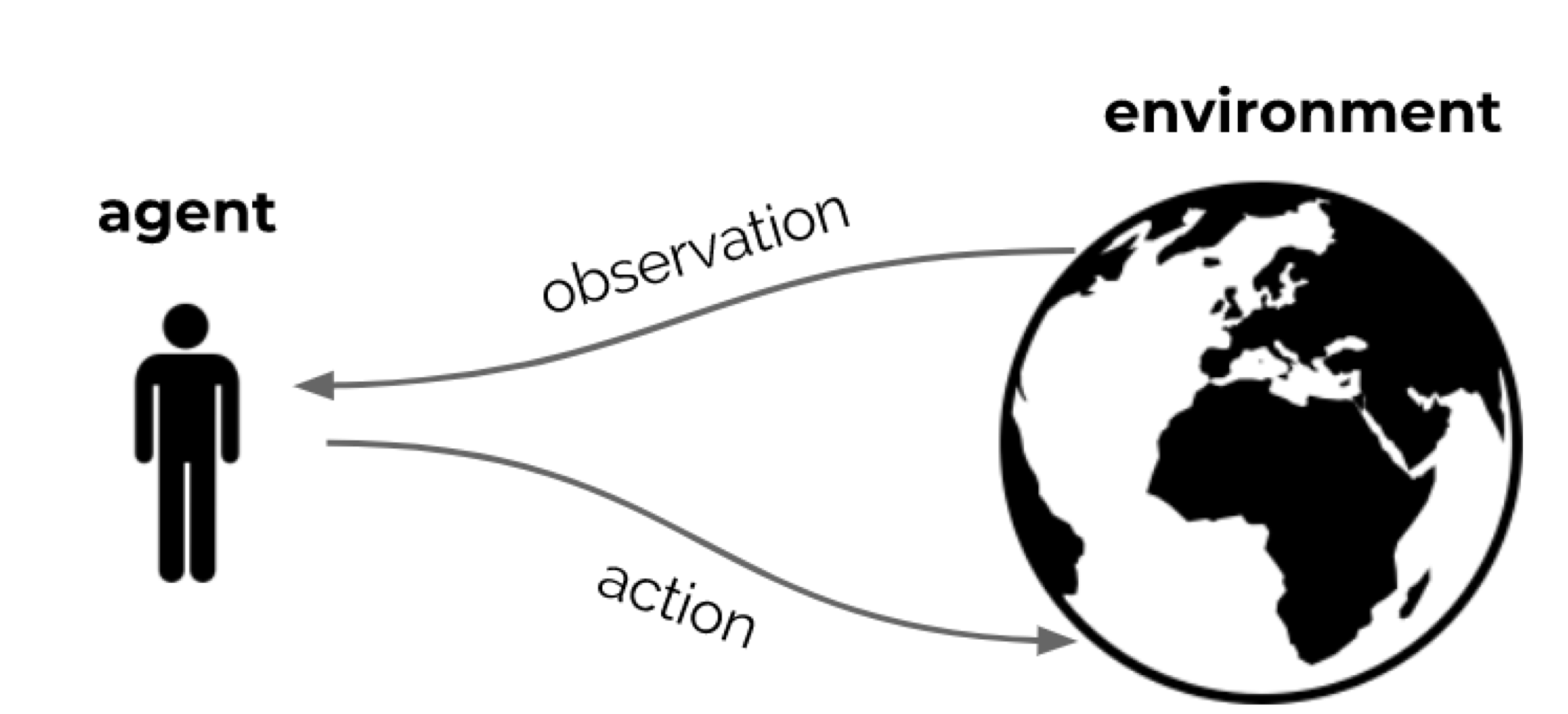
People and animals learn by interacting with our environment
Action -> Rewards
Interactions are often sequential -> we optimise some reward signal
Any goal can be formalized as the outcome of maximizing a cumulative reward
모든 목표는 누적 보상을 극대화한 결과로 공식화될 수 있습니다.
At each step t the agent:
- Receives observation Ot (and reward Rt )
- Executes action At
The environment:
- Receives action At
- Emits observation Ot+1 (and reward Rt+1)
Rewards
A reward Rt is a scalar feedback signal
Indicates how well agent is doing at step t — defines the goal
The agent’s job is to maximize cumulative reward
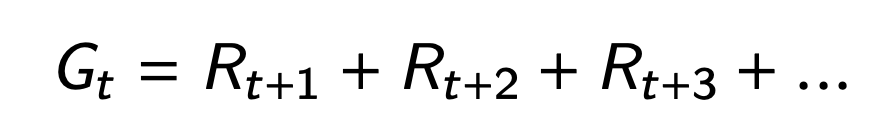
Value
cumulative reward, from a state s
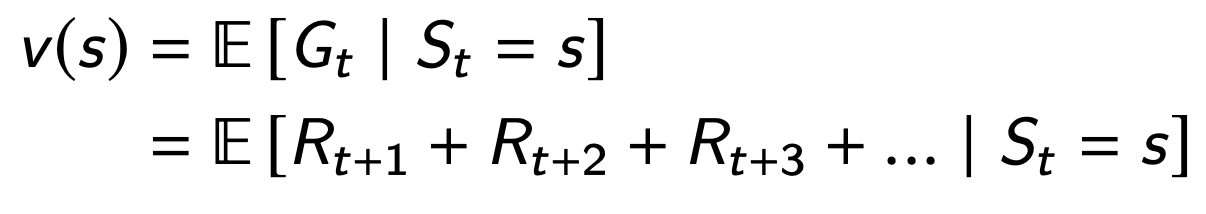
The value depends on the actions the agent takes
Goal is to maximize value, by picking suitable actions
Rewards and values define utility of states and action (no supervised feedback)
Returns and values can be defined recursively
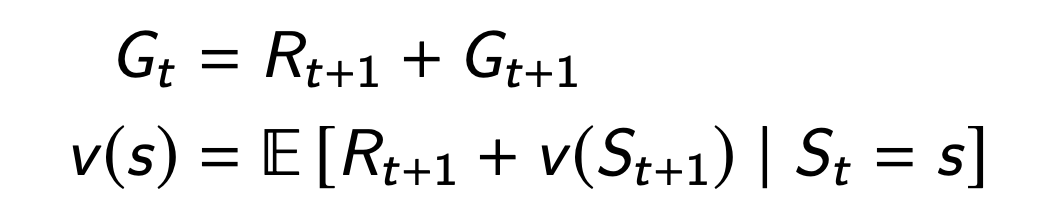
Goal: select actions to maximise value
policy: A mapping from states to actions
Action Value
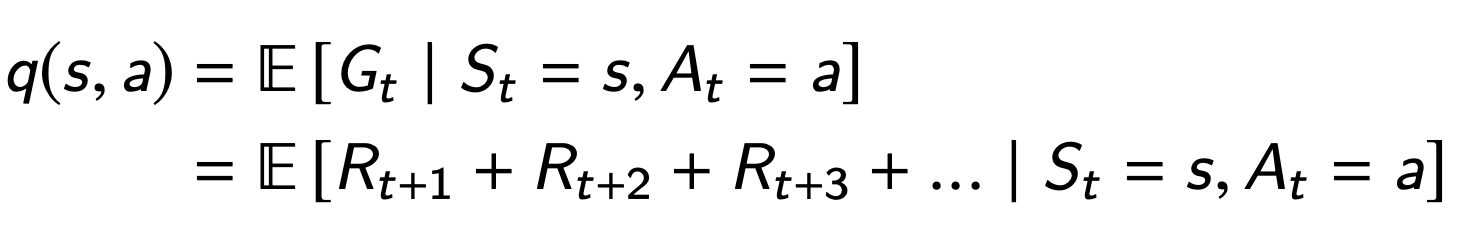
Agent Component
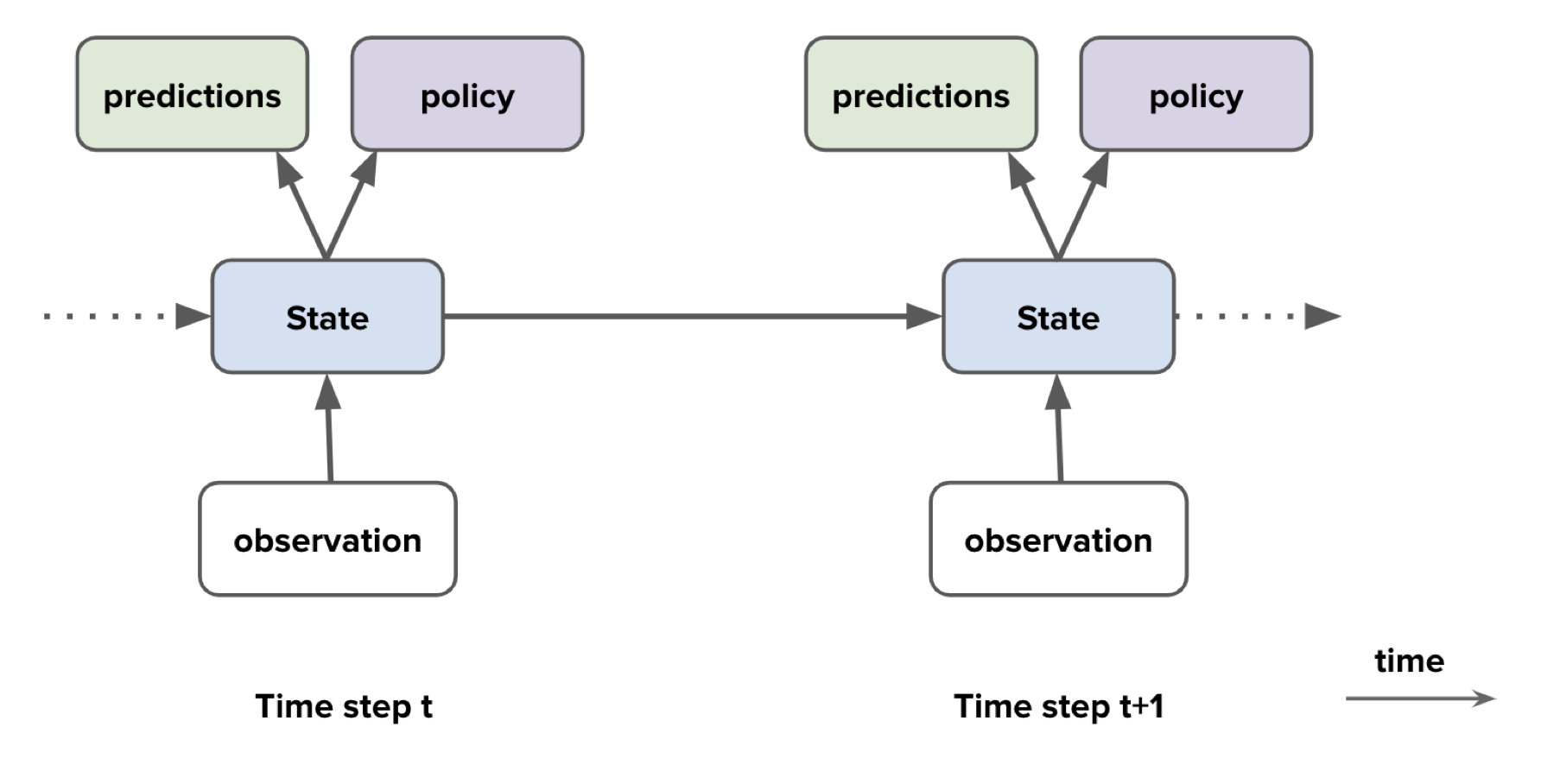
notice! environment state is usually invisible to the agent.
Agent State
The history is the full sequence of observations, actions, rewards
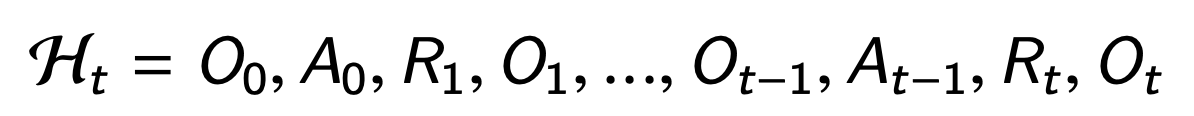
This history is used to construct the agent state St
State is a summary of history
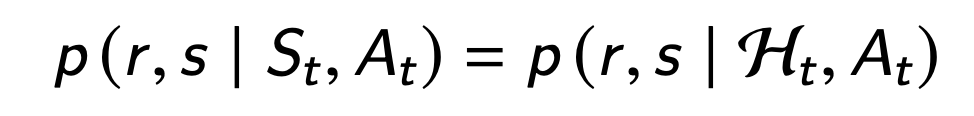
state contains all we need to know from the history
policy
policy: defines the agent’s behaviour
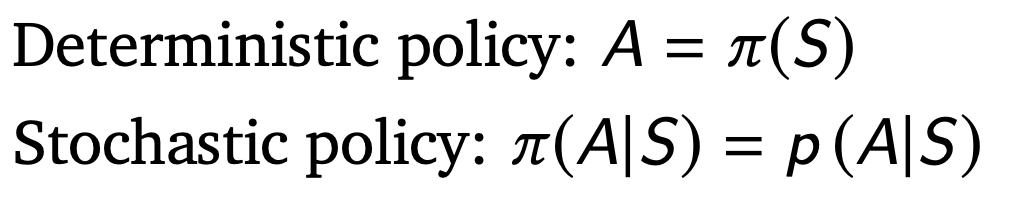
Value Function(Q-Value Function)
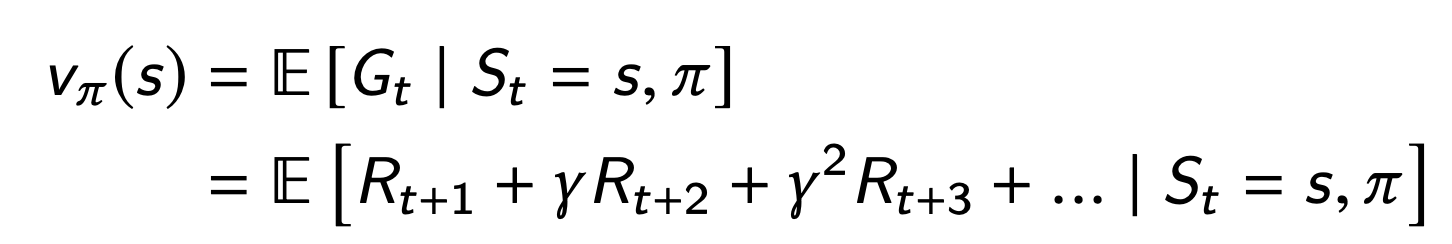

The value depends on a policy
Can be used to evaluate the desirability of states
Can be used to select between actions
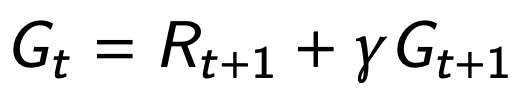
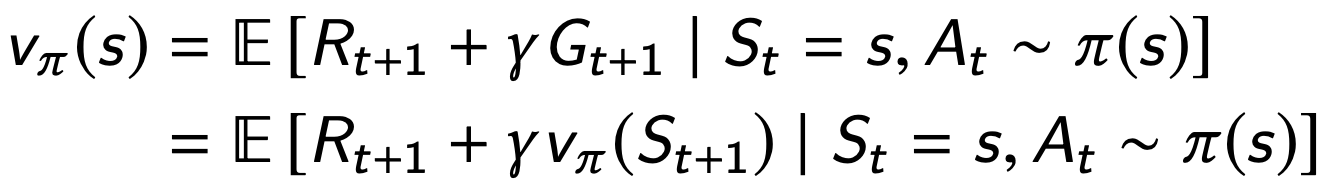
Here a ∼ π(s) means a is chosen by policy π in state s (even if π is deterministic)
Bellman equation (Bellman 1957)
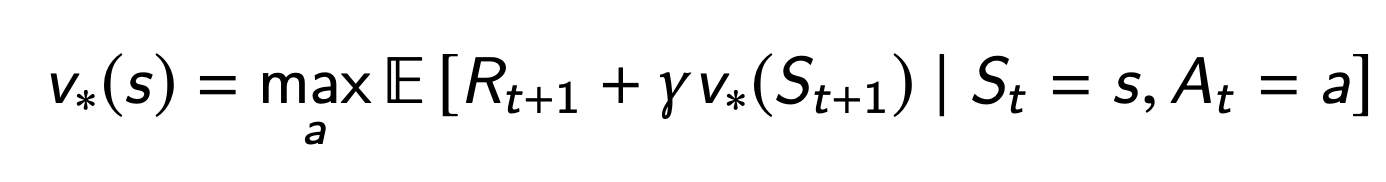
In Paper
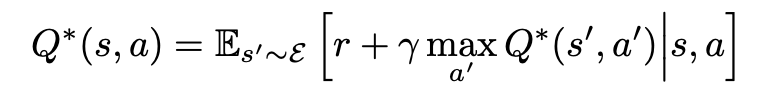
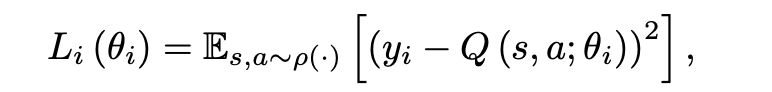
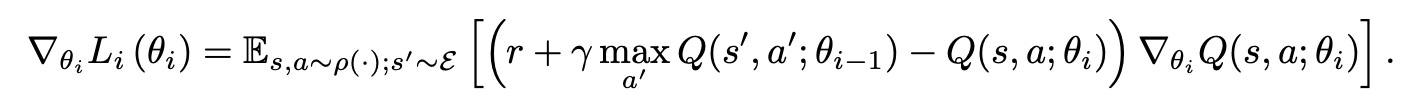
Related Work
TD-gammon -> Q-learning과 유사한 방법 및FCN 연결
Q-learning의 발산 문제를 gradient temporal difference로 해결
NFQ: Q-learning update를 위해 RPROP사용, 저차원에서는 Auto-Encoder 사용.
Deep Reinforcement Learning
RL을 SGD에 연결하여 RGB에서 이미지에 직접 작동 및 Stochastic하게 기울기 업데이트 하도록 DL과 연결
경험의 영역인 st, at, rt, st+1, at+1 에서 value function값 얻기.

DQN 장점
1. 경험의 각 단계는 잠재적으로 많은 가중치 업데이트에 사용되어 데이터 효율성을 높일 수 있다.
2. 연속 샘플링은 샘플들 간의 강한 상호작용으로 비효율적
3. policy에 따라 학습될 때 현재 parameters는 다음 Data를 결정
Preprocessing and Model Architecture
210 × 160 pixel images with a 128 color palette
Gray-scale and down-sampling it to a 110×84 image.
Cropping an 84 × 84 region of the image
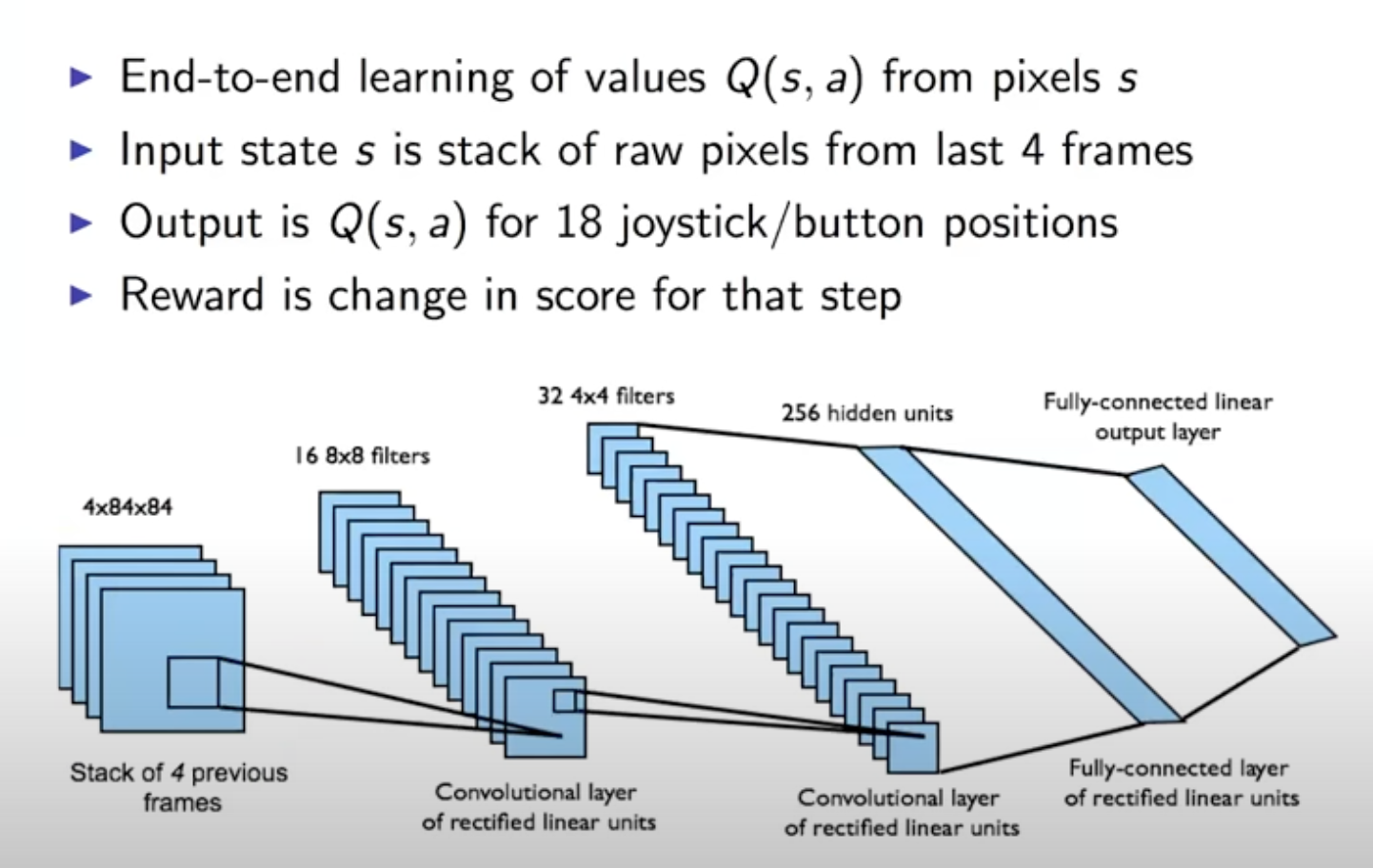
Experiments
ATARI games – Beam Rider, Breakout, Enduro, Pong, Q* bert, Seaquest, Space Invaders.
RMSProp algorithm with minibatches of size 32.
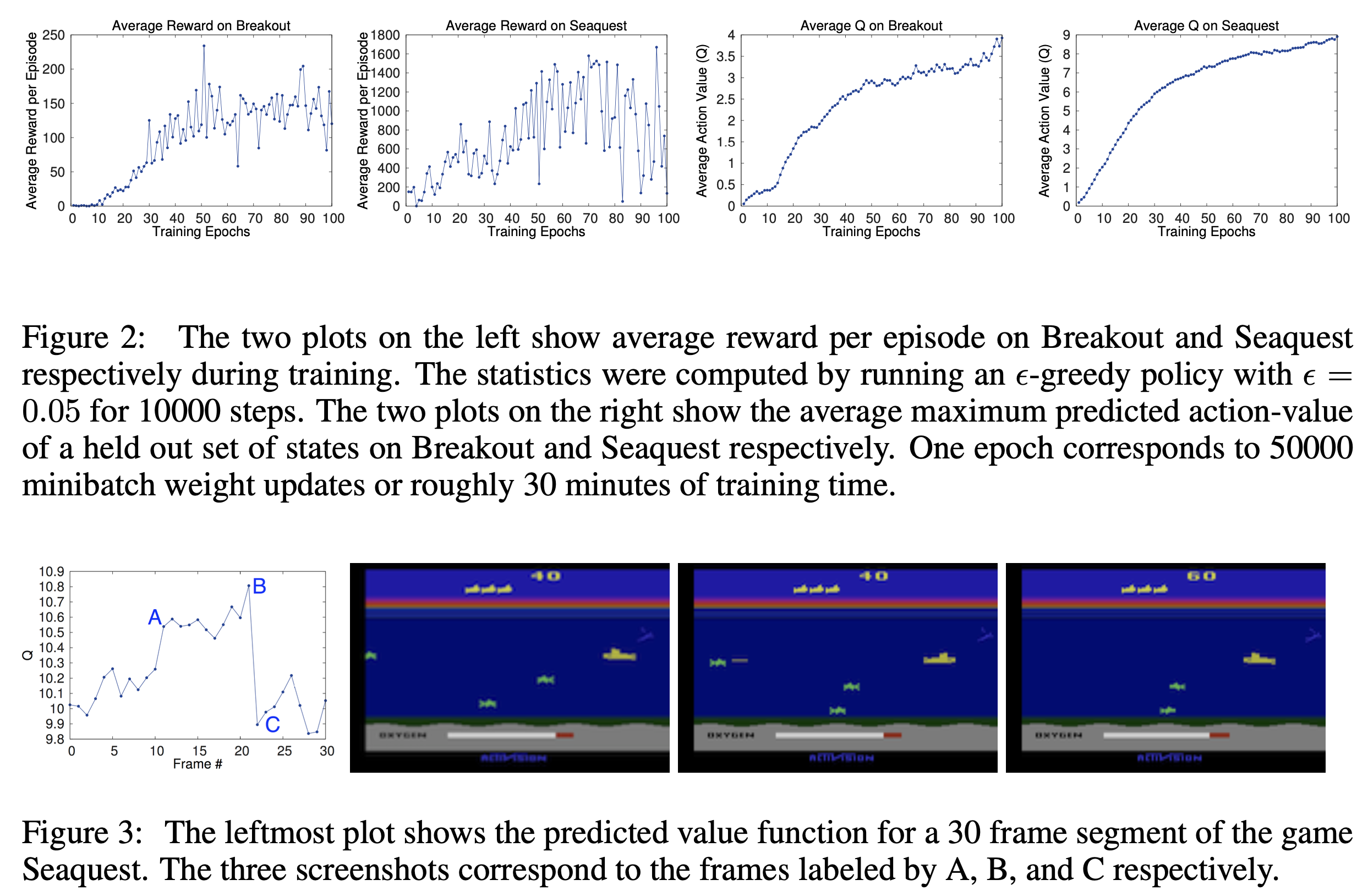
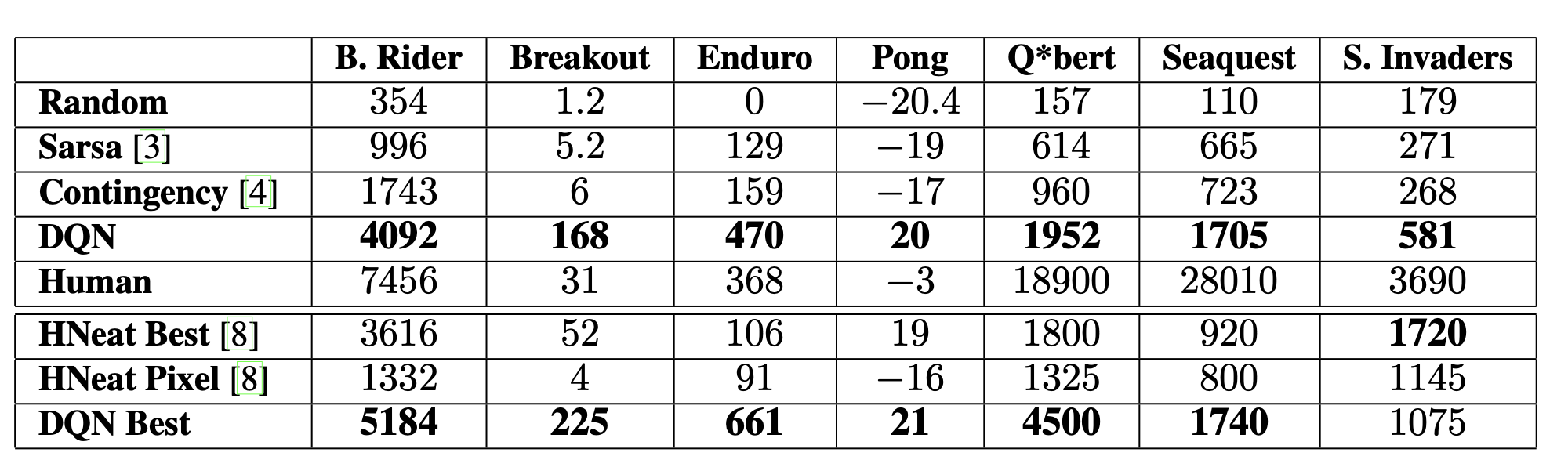
Conculusion
RL을 DL에 적용하여 좋은 결과를 내보임. 앞으로 RL의 발전 가능 여부 무한.
나의 결론
강화학습을 공부해보고 싶어서 가장 유명한 논문을 보았다. 문제는 굉장히 어려웠고 특히 기본적인 개념들은 모두 뛰어 넘기고 설명을 한다는 점이다. 그렇지만 알아보면서 더 배울 수 있어서 즐거웠고 논문을 읽을 수록 학습의 아이디어가 얼마나 중요한지를 배우게 되는 것 같다.
