논문 분석: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
paper_review

Transformer는 NLP의 꽃이다. 나는 BERT나 ELECTRA, BigBird를 사용하면서 여러 NLP Task들을 수행했고 이들은 모두 Transformer 기반이다. NLP와 Vison은 철저하게 분리되어있다고 생각했는데 결과적으로 AI의 기본 원리 안에서 결과를 기대할 수 있다는 측면에서 참 놀랍다.
Abstract
Transformer는 NLP Task에서는 사실상 표준이지만 Vision에서는 여전히 제한적이다. attention convolutional networks과 함께 적용되거나 convolution network의 특정 부분을 대체하긴 한다. 하지만 이 논문에 따르면 더이상 CNN에 의존하지 않아도 되며 image patch가 잘 수행될 수 있다.
Introduction
Self-attention-based architectures인 Transformer 보통 large text corpus 단위로 pre-training 되어있으며 finetuning 작업으로 활용된다. transformer는 100B의 pararmeter로 학습되는 큰 크기의 학습이 가능하며 아직까지 포화가 없다.
Computer Vision 에서 영감으로 많은 연구가 이루어지고 있으며 CNN과 self-attention의 결합을 시도하거나 완전 대체 쪽으로 가고 있다. 후자의 경우는 아직 효과적이지는 않다. CNN 기반은 ResNet이 아직도 최신 기술이다.
Transformer에 적용하기 위해 image를 patch 단위로 나눈다. 이것은 단어를 token 단위로 나누는 것과 같다.
imageNet-21K나 JFT-300M으로 pretrained된 모델인 경우 SOTA모델에 접근 할 성적을 가진다.
RELATED WORK
Vison이 Transformer에 적용될 때 중요한 점은 각 pixel이 서로 다른 pixel에 집중해야 한다.
Cordonnier은 입력 Image에서 2x2 patch 를 적용하고 그 위에 full-self-attention 을 적용한다.
이 논문의 ViT와 유사하지만 CNN과 경쟁력 있음을 보여주기 위해 더 나아간다.
CNN을 self-attention 형태와 결합에 많은 관심이 있다.
다른 모델에는 iGPT가 있다.
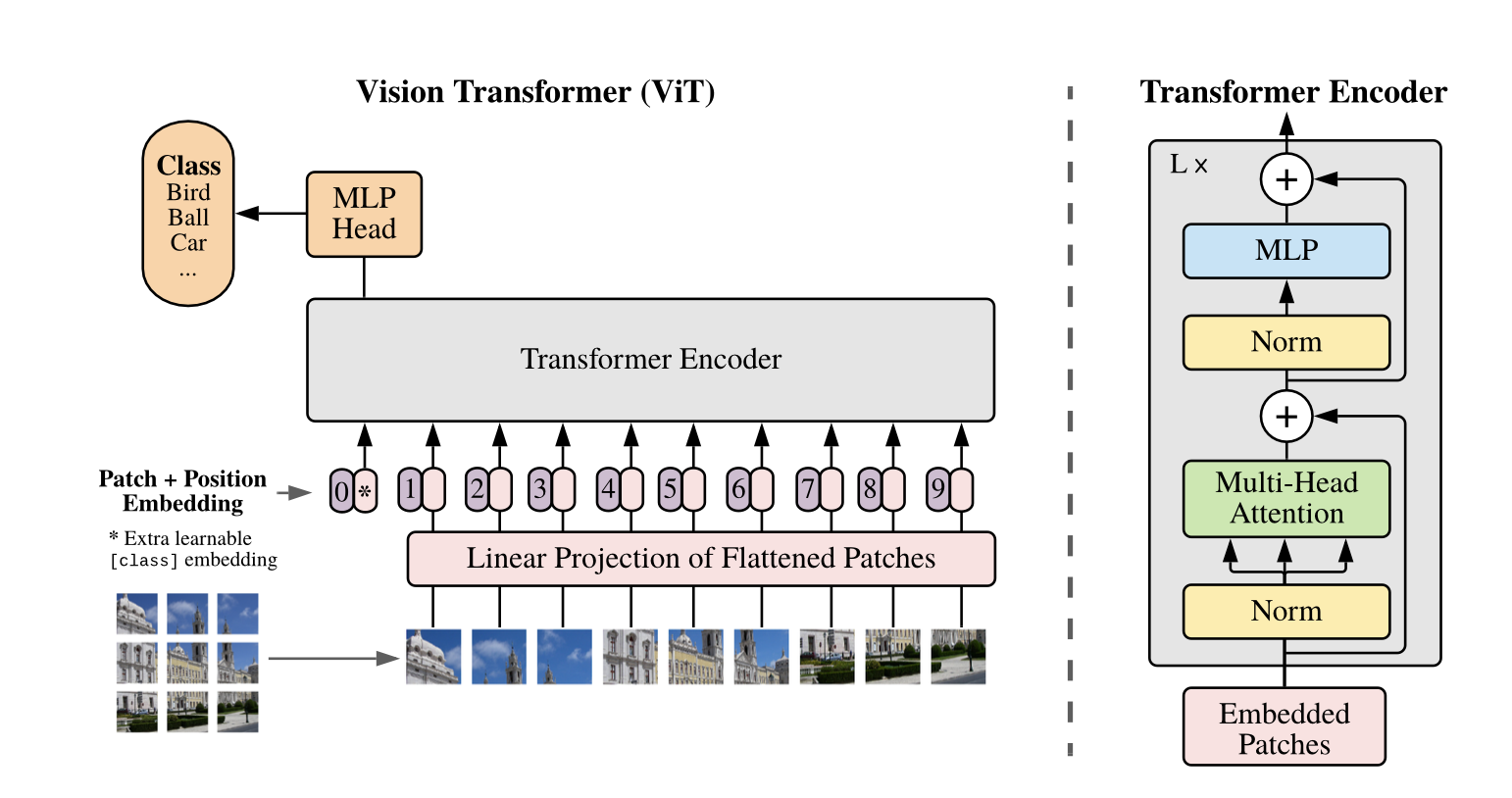
Method
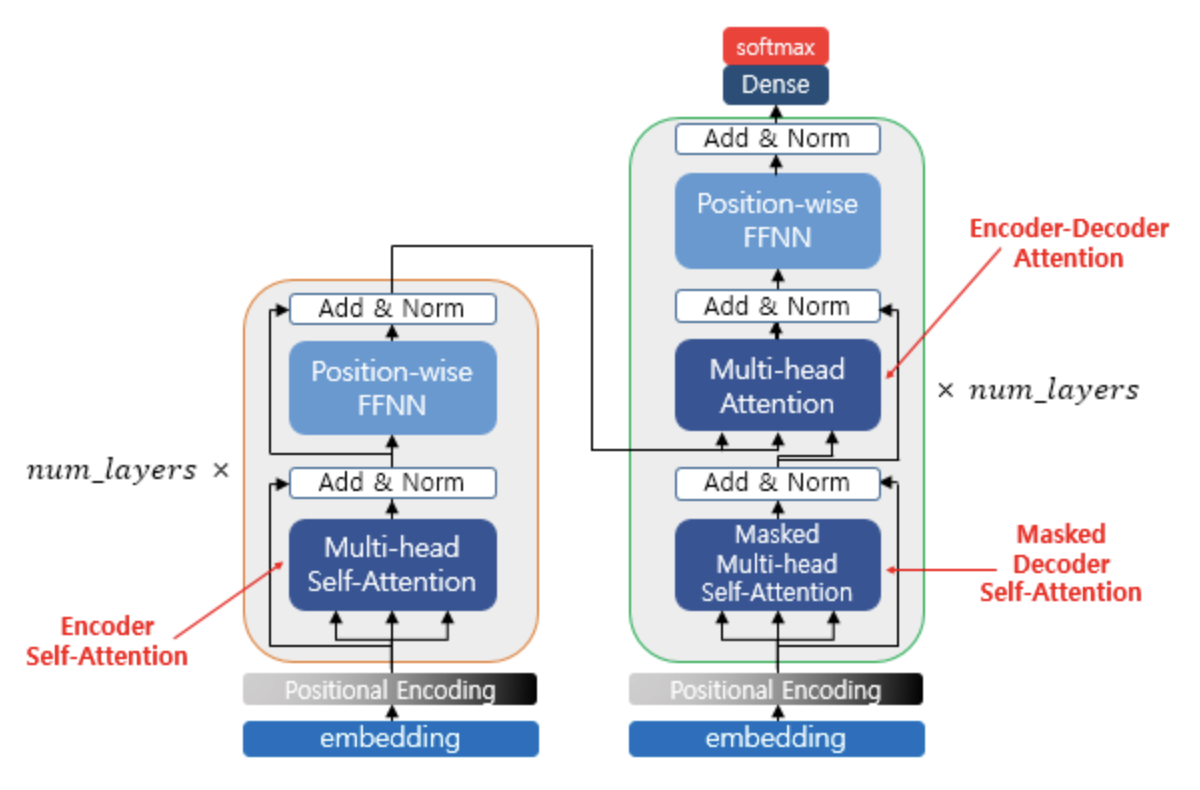
위의 설계대로 원래 Transformer의 형태를 유사하게 따른다.
표준 Transformer의 input은 token embbeding sequence
2D이미지를 처리하기 위해
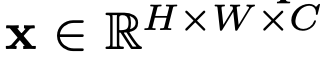
H: height, W: width, C: channels
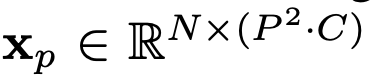
N: HW/P^2(number of patch) P: image patch size, C: channels
flatten 작업 후 D차원에 mapping(linear projection) -> patch embedding
BERT와 유사한 Token 보유.
Classification head는 pretrained 시 MLP에 의해 구현, Finetuning 시 single layer에 의해 구현.
위치 정보를 위해 position embeddingdl patch embedding에 추가.
Encoder는 MSA와 MLP로 구성
Layer norm이 residual connection 이후 구성.
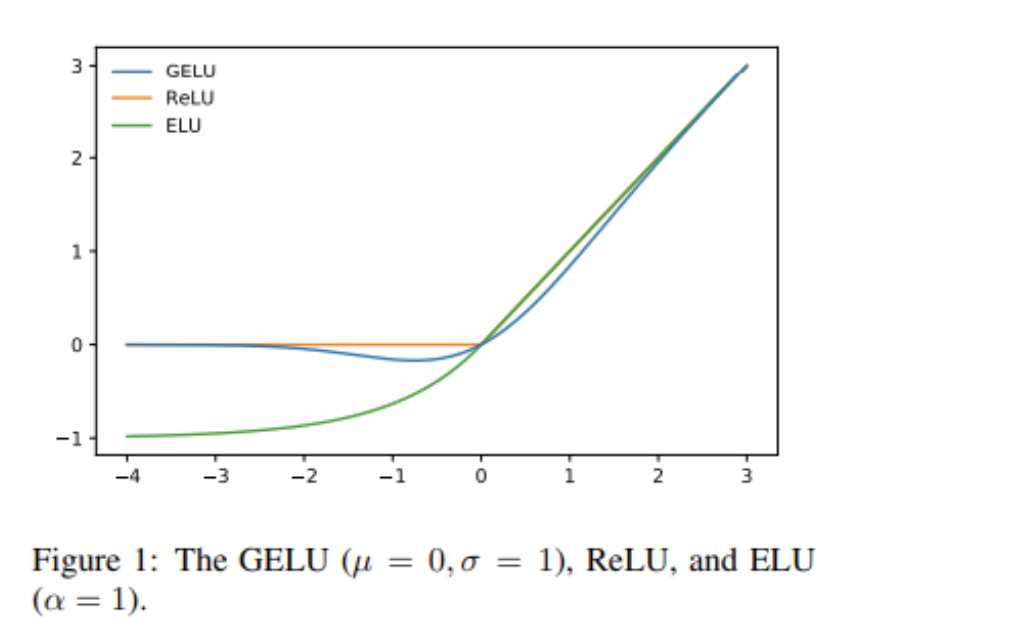
MLP는 2layer 이며 Activation Function은 GELU이다.

** 논문 외 부분
Transformer는 Attention is all you need에서 소개된 모델.
seq2seq에 Attention mechanism이 적용.
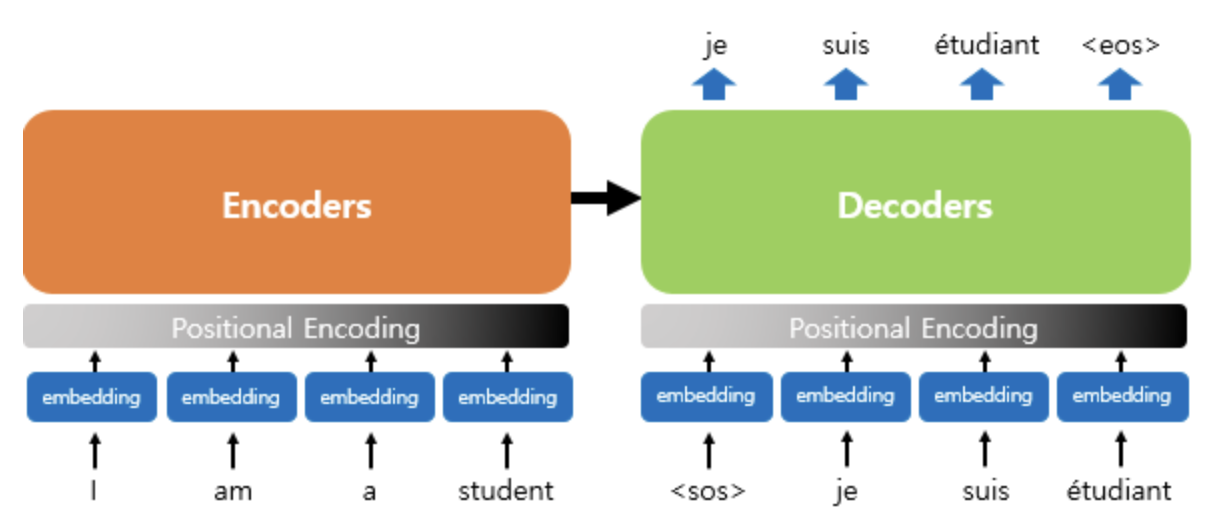
트랜스포머는 단어의 위치 정보를 얻기 위해서 각 단어의 embedding vector에 위치 정보들을 더하여 모델의 입력으로 사용하는데, 이를 positional encoding 이라고 한다.

Attention.
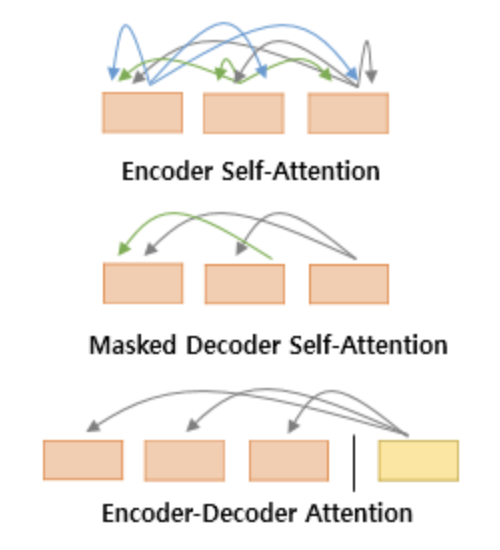
Query, Key, Value
Attention 함수는 주어진 Query 에 대해서 모든 Key와의 유사도를 각각 구합니다. 그리고 구해낸 이 유사도를 가중치로 하여 Key와 맵핑되어있는 각각의 Value에 반영해줍니다. 그리고 유사도가 반영된 Value을 모두 가중합하여 return합니다.
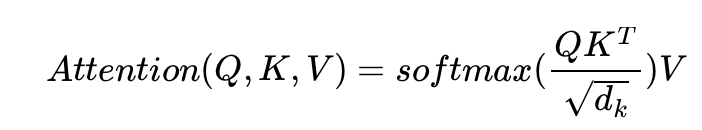
GELU
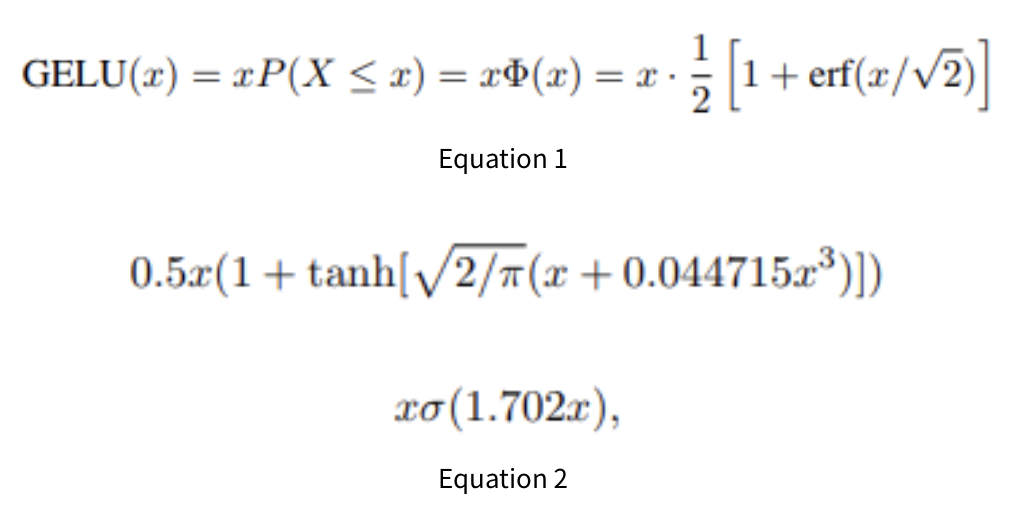
Experiments
Representation learning capabilities
:ResNet, Vision Transformer (ViT), and the hybrid.
ViT는 낮은 교육 비용으로 좋은 성적 보유
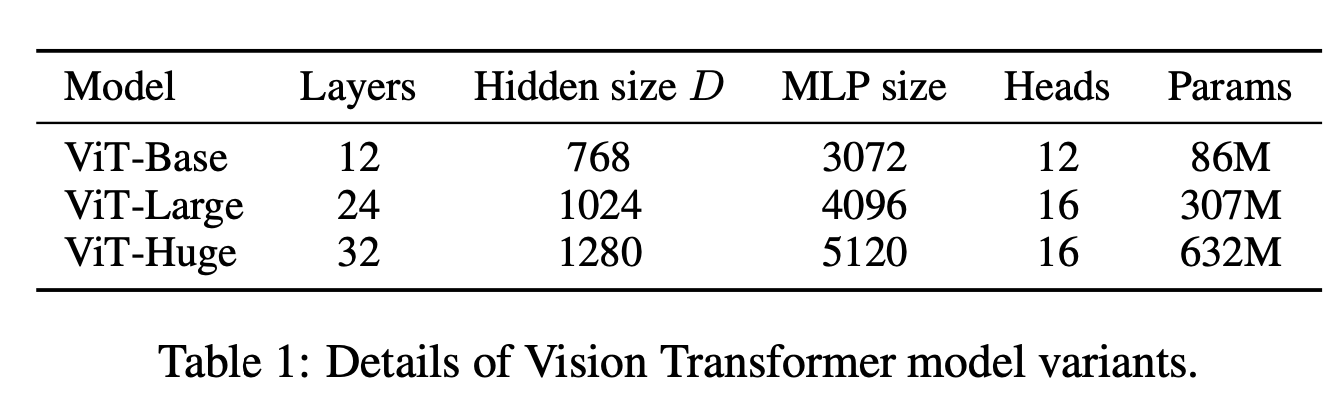
여기서 ViT-Large는 16x16의 patch size 보유.
Transformer의 sequnce 길이는 patch size에 반비례, 작은 size일수록 더 높은 계산비용이 든다.
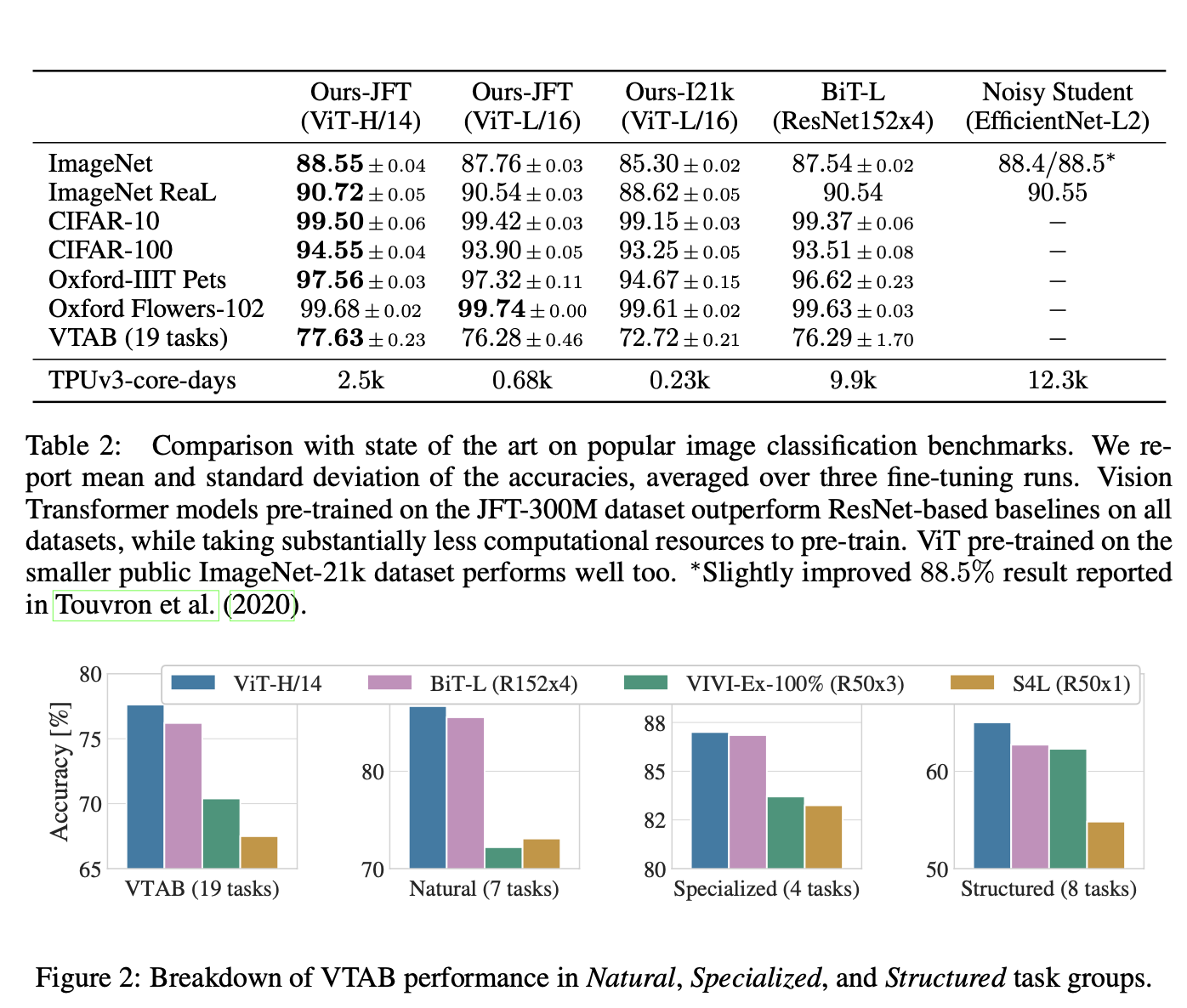
ViT는 image task의 특정 bias를 적용하지 않아 ResNet보다 inductive bias가 적기 때문에 Dataset 크기가 중요하다.
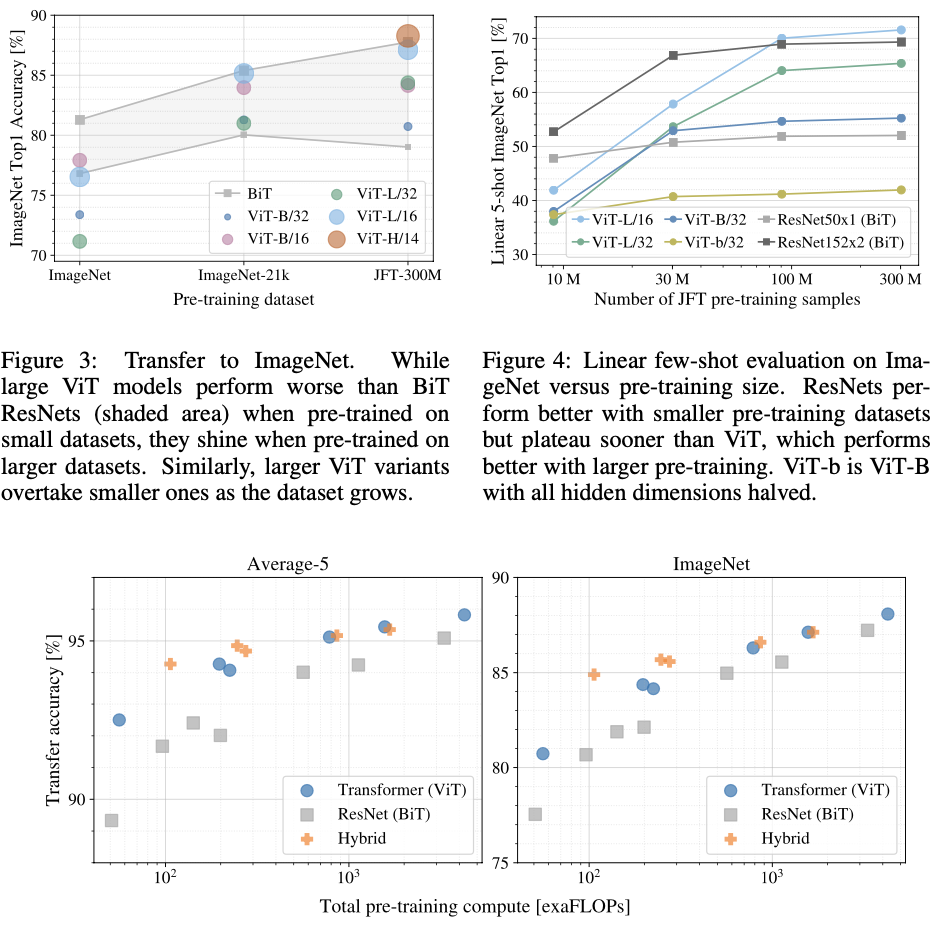
Transforemer의 NLP의 쪽에서 뛰어난 성능과 확장성 뿐만 아니라 self-supervised pre-training이 가능하단 부분에서 중요하다.
이부분을 실험했으나 아직 연구해야할 부분이다.
Conclusion
Vision에 Transformer을 적용하는데 성공했고 원래 Transforemr의 방식을 그대로 따르며 image task의 inductive bias를 생각하지 않고 수행했다.
image를 patch화 시켜 self-attention 방식의 encoder에 적용해 좋은 결과를 얻었다.
ViT는 데이터 측면에서도 효율적이다. 다음 과제는 self-supervised pre-training 부분을 연구하는 것이다.
나의 결론
Transformer의 작동 원리를 다시금 기억하며 vision과 어떻게 적용될 수 있는지 볼 수 있어서 재밌었다. vision도 생각해보면 각 pixel과 그 상하좌우로 연관성을 찾을 수 있고 전체적으로 서로 유사도를 평가하는 것은 중요한 작업인것 같다. 좋은 아이디어로 재밌는 작업을 배워 볼 수 있어서 정말 재미있었다.
