[CNN Networks] 13. MobileNet v2
DeepLearning - CNN Networks

아래 내용은 개인적으로 공부한 내용을 정리하기 위해 작성하였습니다. 혹시 보완해야할 점이나 잘못된 내용있을 경우 메일이나 댓글로 알려주시면 감사하겠습니다.
MobileNet V2
Google은 2018년 MobileNet V2를 제안한 논문인 MobileNetV2: Inverted Residuals and Linear Bottlenecks를 발표했습니다.
MobileNet V2는 이전 모델인 MobileNet을 개선한 네트워크 입니다. 따라서 MobileNet과 동일하게 MobileNet V2는 임베디드 디바이스 또는 모바일 장치를 타겟으로 하는 단순한 구조의 경량화 네트워크를 설계하는데 초점이 맞춰져 있습니다.
MobileNet V2는 MobileNet V1을 기반으로 두고 몇가지 개선점을 추가했습니다. MobileNet V1에서 사용하던 Depthwise-Separable Convolution을 주로 사용하고 width/resolution multiplyer를 사용해 정확도와 모델 크기를 trade-off하는 등 유사한 점이 많습니다.
하지만 단순히 Depthwise-Separable Convolution을 쌓은 구조의 MobileNet과는 달리 MobileNet v2에서는 Inverted Residual block이라는 구조를 이용해 네트워크를 구성한 차이점이 있습니다.
설계 전략
Linear Bottlenecks
1) Manifold of interst
어떤 네트워크에 이미지가 입력된 모습을 생각해 봅시다. 이때 n번째 layer에서는 입력이미지의 특징들이 저차원의 특정 영역에서 활성화(mapping)됩니다. 이렇게 저차원에서 특징들이 mapping 되는 영역이 생기는 것을 manifold of interest을 구성한다고 합니다.
오래전부터 manifold of interest는 저차원 subspace로 embedding이 가능하다고 가정했습니다. 정리하면 고차원의 정보는 저차원에 표현 가능하다고 가정합니다.
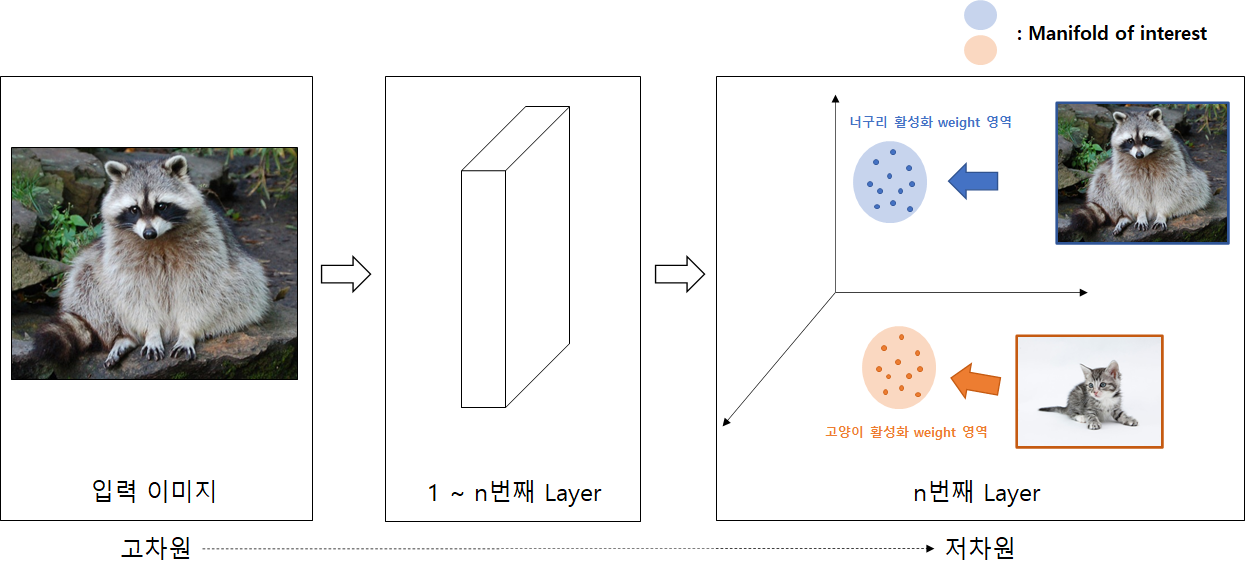
위 그림을 살펴보면, 고차원 데이터인 너구리 이미지에서 너구리의 특징에 해당하는 정보는 저차원의 일부분(subspace)에 맵핑되어 영역을 구성합니다. 즉, 저차원에서도 너구리라는 정보를 가지고 있음을 볼 수 있습니다.
2) Linear Transformation
다음으로 어떠한 manifold of interest가 ReLU를 통과하는 경우를 생각해 보겠습니다.
ReLU는 음수영역은 0으로 만들지만, 양수 영역에서는 자기 자신을 반환하는 선형함수, linear transformation 입니다.
즉, Manifold of interest가 양수이면 ReLU는 linear transformation 연산과 동일하다고 볼 수 있으며, 이 때는 ReLU를 통과해도 정보가 보존된다고 생각할 수 있습니다.
ReLU를 사용하면 각 채널에서는 필연적으로 정보의 손실이 발생합니다. 하지만 논문에서는 많은 채널을 사용할 경우 정보 보존이 가능하다고 주장합니다.
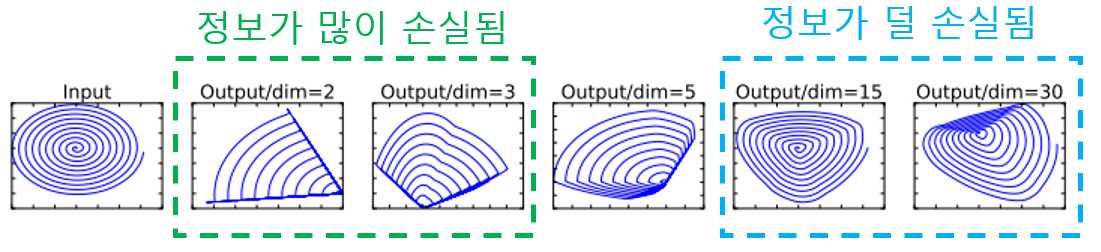
위 그림은 논문에서 제시한 예시로, 입력된 이미지를 낮은 차원으로 embedding한 뒤 다시 2차원 공간에 투영한 결과를 나타낸 것 입니다.
그림에서 낮은차원에 적은 수(2,3개)의 채널을 사용한 경우 복원했을 때 정보가 크게 손실된 것을 볼 수 있습니다. 하지만 15개 이상의 많은 채널을 사용하는 경우 원래 정보의 대부분이 보존되는것을 볼 수 있습니다.
논문에서는 낮은 차원으로 mapping할 때 하나의 채널에서 정보가 손실되더라도, 다른 채널에서는 손실된 정보가 살아있을 수 있기 때문에 정보가 보존되어 위 그림같은 결과가 나온다고 주장합니다.
3) Linear Bottlenecks
앞의 내용을 요약하면 입력에서 중요한 정보들인 manifold of interest는 Layer를 거쳐가며 저차원영역으로 전달될 수 있고, 이 때 Layer가 linear transformation이면 정보가 보존될 것이라고 가정할 수 있습니다.
MobileNet V2에서는 저차원으로 mapping하는 linear transformation을 만들 때 bottleneck 구조를 활용합니다.
논문의 저자들은 경험적으로 bottleneck 안에 있는 ReLU가 너무 많은 정보를 손실시킴을 알 고 있었으며, 실험을 해본 결과 non-linearity(비선형성, 여기서는 ReLU)를 제거한 linear bottleneck 구조가 기존 bottleneck 구조보다 cifar 데이터셋에서 더 좋은 성능을 보여주었다고 합니다.
종합하면 MobileNet v2는 linear transformation역할을 하는 linear bottleneck layer를 활용해서 차원은 줄이되 중요한 정보(manifold of interest)를 그대로 유지하여 네트워크 크기는 줄어들지만 정확도는 유지하는 전략을 취합니다.
Inverted Residuals
일반적인 Residual Bottleneck block의 구조는 아래 그림과 같은 구조를 가지고 있습니다.
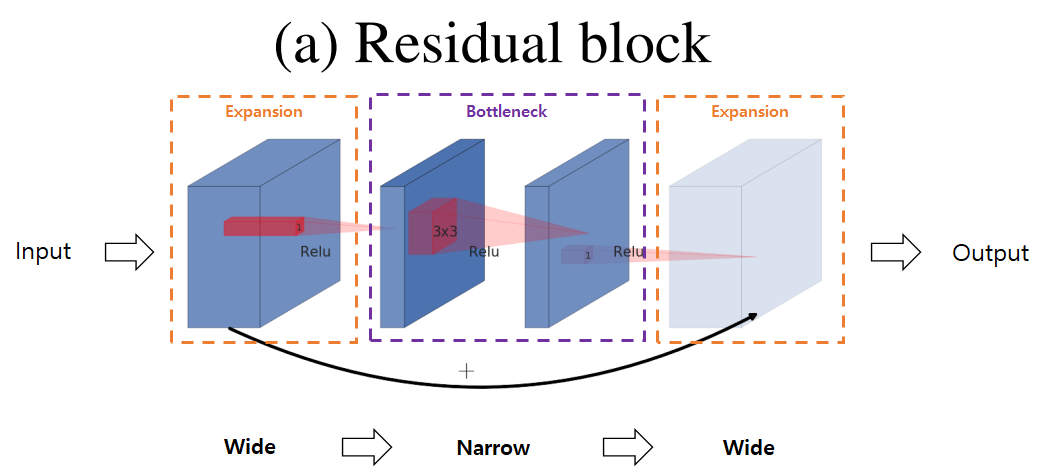
먼저 1x1 Conv layer로 적은 수의 채널을 갖는 bottleneck block을 생성합니다. Bottleneck block에서 3x3 Conv layer를 통과한 뒤 Residual connection을 연결하기 위해 다시 1x1 Conv layer를 활용해 채널 수가 많은 expansion block을 생성합니다.
하지만 앞의 Linear bottleneck 구조에 대한 설명에서 고차원의 정보는 저차원에 표현 가능하다고 가정 했습니다. 바꿔말하면 저차원에 해당하는 bottleneck block에 이미 manifold of interest가 보존되어 있다고 생각할 수 있습니다.
따라서 MobileNet v2에서는 Shortcut connection을 bottleneck block끼리 연결하여 Narrow Wide Narrow의 순으로 된 형태의 Inverted Residual block을 사용합니다.
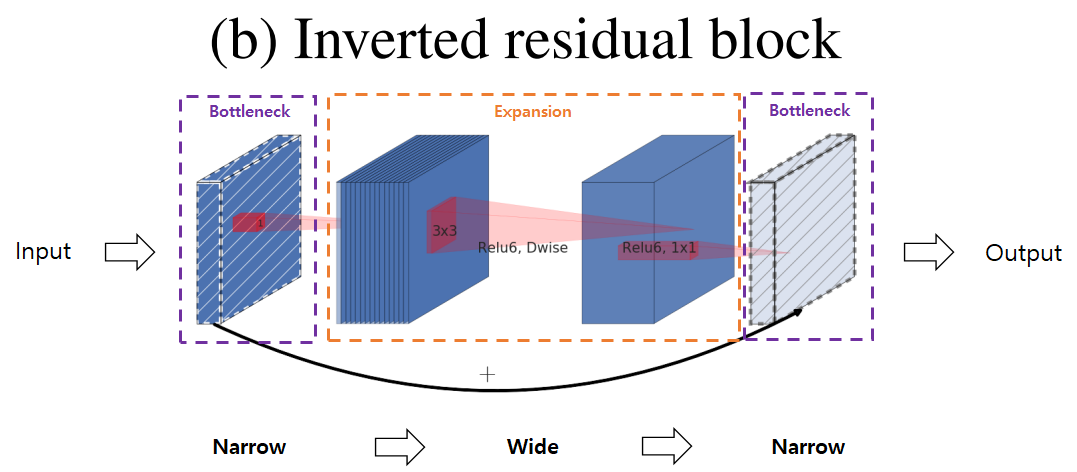
(그림에서 빗금이 쳐진 block은 ReLU와 같은 비선형 함수를 사용하지 않은 block입니다.)
Inverted Residual Block은 입력과 출력의 채널수가 낮기 때문에 Residual block보다 메모리 효율이 좋은 장점이 있습니다.
Residual Block과 Inverted Residual Block의 연산량을 비교하면 다음과 같습니다.
Residual Block :
Inverted Residual Block :
수식에서만 보면 Inverted residual block이 1x1 Conv layer부분이 더 붙어있기 때분에 더 많은 연산량이 필요해 보입니다. 하지만 inverted residual block의 입력과 출력의 채널 수가 더 적기 때문에 inverted residual block의 연산량이 더 적다고 합니다.
네트워크 구조
특징
1) Bottleneck Residual Block의 구조
MobileNet V2을 구성하는 Bottleneck residual block은 아래 표와 같이 3개의 Convolution layer로 구성되어 있습니다.

이전의 Bottleneck 구조와 차이점은 입력된 feature map의 채널 수를 늘리는 expansion ratio라는 변수(위 표에서 t)가 사용되는 점 입니다. 이 expansion ratio를 활용해 입력 채널의 수를 조절합니다.
실험을 해보니 expansion ratio는 5~10의 값일 때 좋은 성능을 보여주었다고 하며, 논문에서는 최종적으로 6을 사용합니다.
2) ReLU6 사용
또 다른 차이점은 ReLU대신 ReLU6를 사용하는 점 입니다.
ReLU는 입력값이 양수일 때 입력된 값을 그대로 반환하지만, ReLU6는 6보다 큰 값을 6으로 고정하여 반환합니다. 그래프로 나타내면 아래와 같습니다.

ReLU6는 INT8이나 FP16연산과 같은 low-precision 연산에서 강건한(robustness) 특징을 갖기 때문에 사용되었다고 합니다.
3) Trade-off hyper parameters
MobileNet V1과 마찬가지로 MobileNet V2에서는 width multiplier와 해상도(resolution) 조정을 사용해 성능과 네트워크 크기를 trade-off 합니다.
Mobilenet과의 차이점은 width multiplier를 마지막 layer를 제외한 모든 layer에 적용한 점 입니다. 그 결과 작은 모델에서 약간의 성능 향상이 있었다고 합니다.
네트워크 구조

위의 표는 MobileNet V2의 구조를 설명한 표 입니다.
구조를 살펴보면 Convolution layer로만 구성되어 있으며, 첫 번째와 마지막 Convolution layer를 제외하고는 모두 bottleneck block을 사용합니다. 각 block은 표의 n회 만큼 반복해서 쌓습니다.
Bottleneck 구조에서 Stride가 2인 경우는 첫 번째 layer만 stride를 2로 두고 뒤에 이어지는 layer의 stride는 1로 설정합니다.
평가
메모리 사용량 비교
MobileNet V2가 얼마나 가벼운 네트워크인지 확인하기 위해 먼저 다른 네트워크와 메모리 사용량을 비교했습니다.
MobileNet, ShuffleNet과 비교했으며, 각 feature size에 대해 채널 수, 최대 메모리 사용량을 비교했습니다.
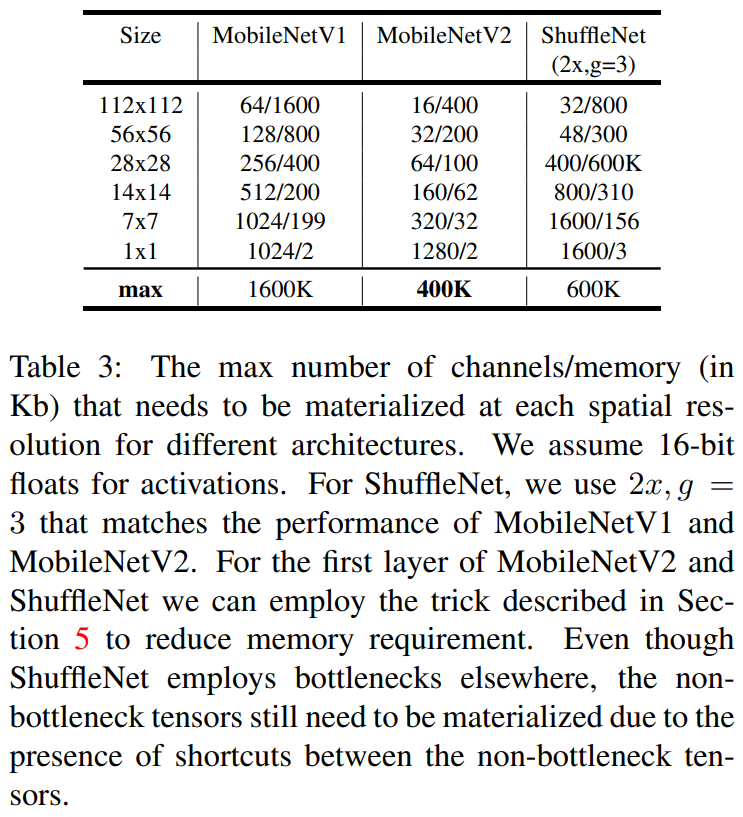
표에서 가운데 위치한 MobileNet V2가 400K로 최대로 사용하는 메모리의 크기가 가장 작은것을 볼 수 있습니다.
성능 평가
1) ImageNet Classification
MobileNet V2는 가장 기본인 Classification 성능을 ImageNet 데이터셋에서 확인했습니다. 성능은 MobileNet V1, ShuffleNet, NASNet-A와 비교했고, MobileNet V2는 기본형과 높은 성능을 내기 위해 multiplier를 1.4로 설정한 모델을 사용했습니다.
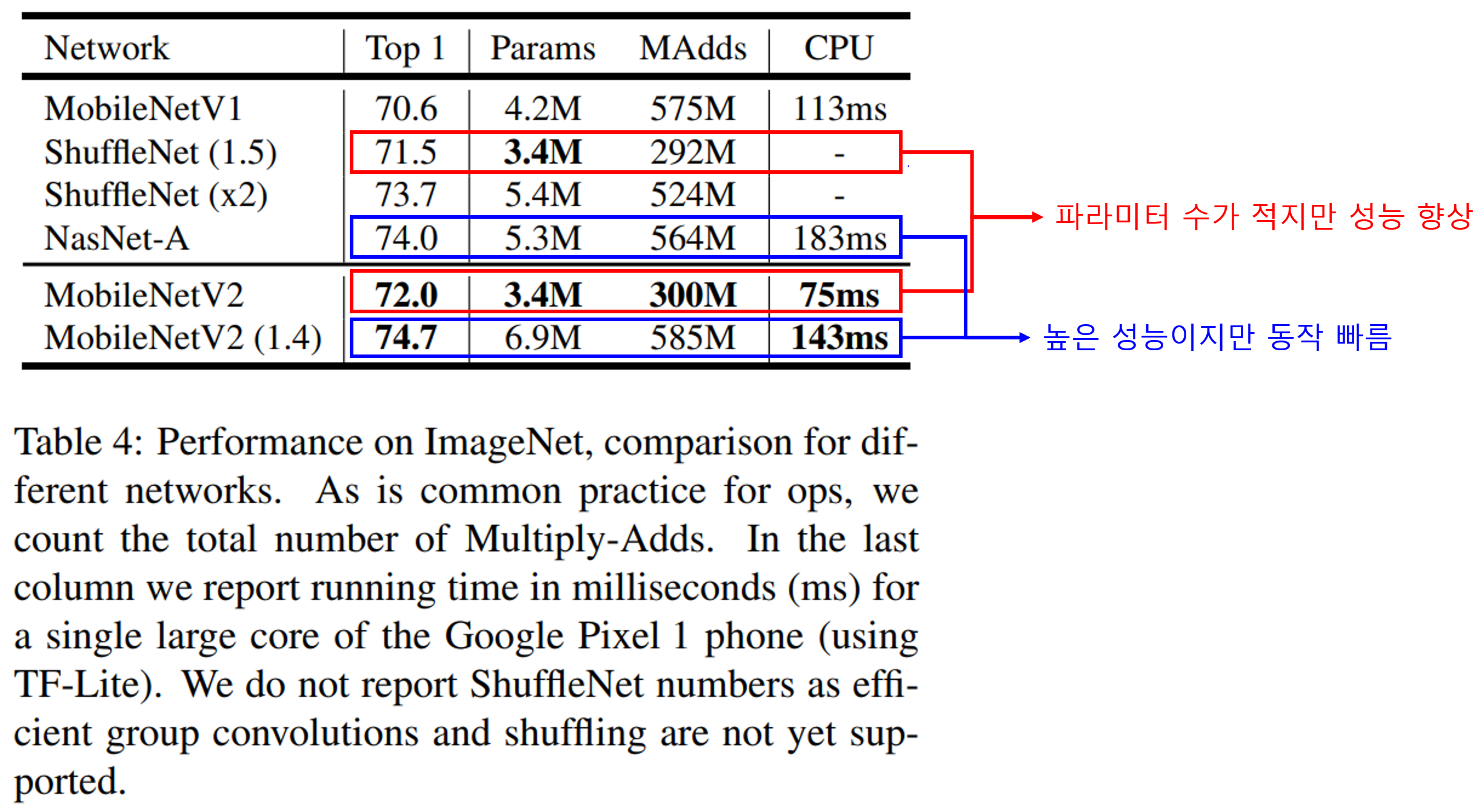
실험결과 MobileNet V2는 기본형은 ShuffleNet(1.5)수준의 가장 적은 수의 파라미터를 가지지만 성능은 살짝 향상된 결과를 보여줍니다.
대조군 중 가장 성능이 좋은 NasNet-A와 비교했을 때 더 높은 성능을 보여주지만 동작시간이 더 짧은것을 볼 수 있습니다.
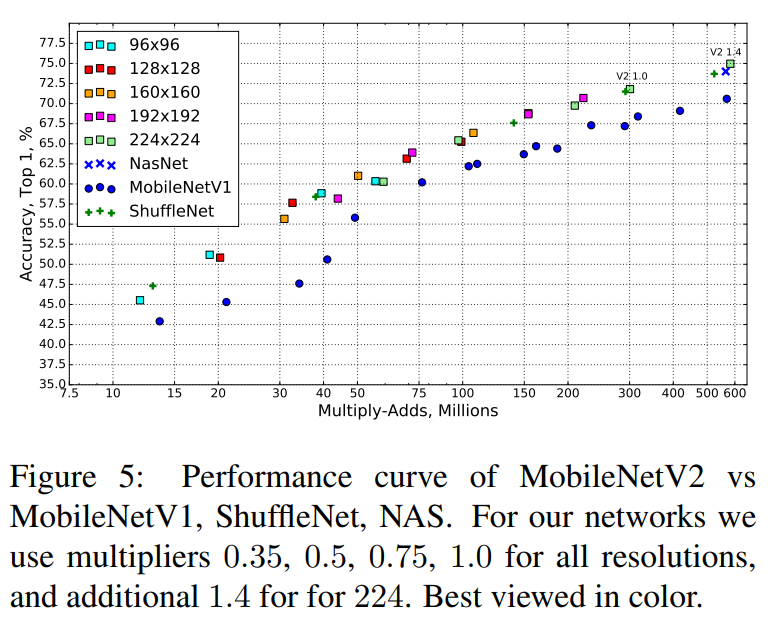
다음으로 width multiplier와 입력 해상도를 조절하며 각 연산량에서 성능이 어떻게 되는지 확인했습니다.
실험결과에서 네모 모양의 MobileNet V2의 성능이 주로 그래프 위쪽에 위치함을 볼 수 있습니다. 이로부터 hyper-parameter에 의한 성능-연산량 사이의 trade-off가 잘 이뤄지면서 유사한 연산량을 가진 다른 네트워크 보다 높은 성능을 보여줌을 볼 수 있습니다.
2) Object Detection
다음으로 Object Detection에서 MobileNet V2가 어느정도 효과가 있는지 평가했습니다.
평가를 위해 SSD 객체검출 네트워크의 Convolution layer를 모두 MobileNet V1에서 사용한 separable convolution으로 교체한 뒤 SSDLite라고 명명했습니다.
평가는 위해 SSDLite의 Backbone을 MobileNet V2으로 교체한 네트워크를 SSD300, SSD512, Yolo v2, MobileNet V1 SSDLite를 비교했습니다.
성능평가는 Tensorflow Object Detection API를 사용했으며, COCO dataset에서 평가했다고 합니다.
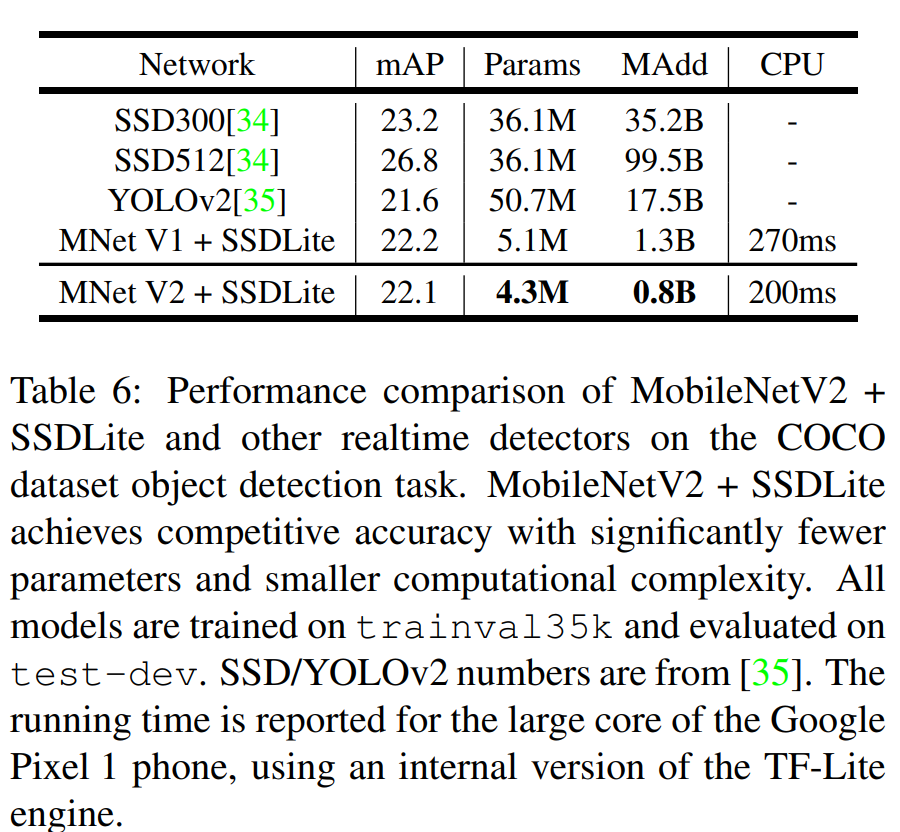
결과를 살펴보면 파라미터 수와 연산량이 가장 작으면서 yolo v2보다 높은 성능을 보여주었습니다. 결과로부터 비교한 네트워크들 중 MobileNet V2를 사용한 SSDLite가 가장 효율적인 네트워크임을 알 수 있습니다. (최고 성능은 아닙니다)
3) Semantic Segmentation
마지막으로 Segmantic segmentation에서 mobileNet V2의 성능을 비교했습니다.
평가는 PASCAL VOC 2012 dataset에서 이뤄졌으며, DeepLab v3 네트워크에서 feature extractor 부분을 교체해 가며 성능을 비교했습니다.
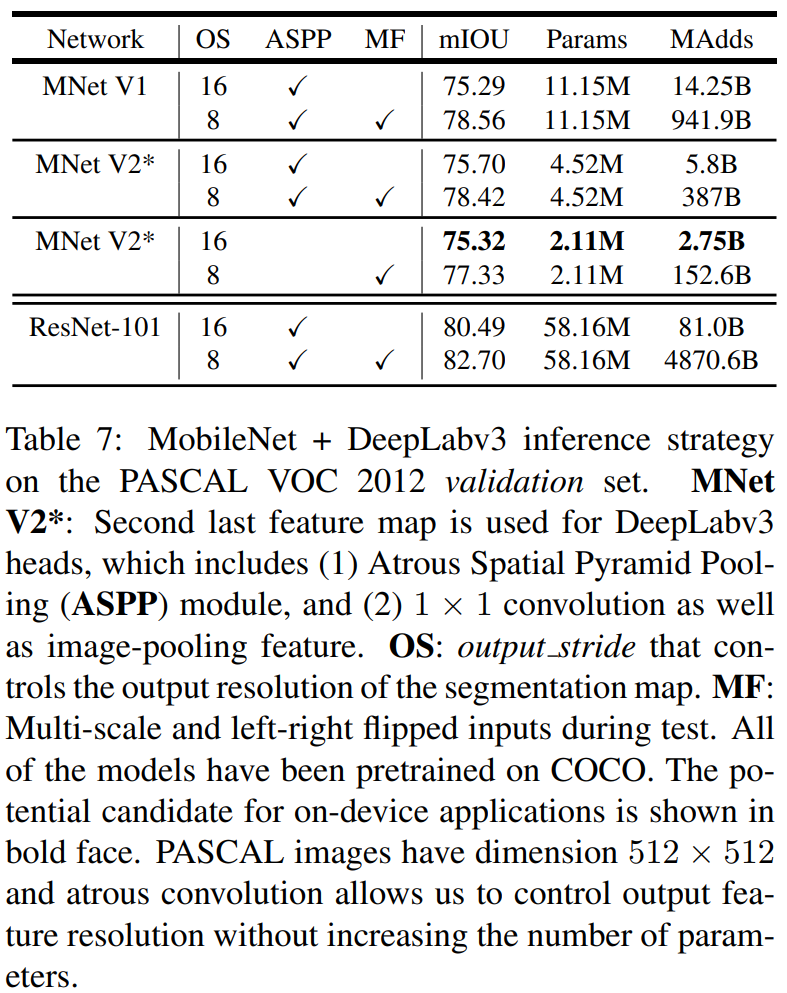
결과를 살펴보면 MobileNet V2를 사용한 네트워크가 가장 적은 파라미터와 연산량을 가지면서 어느정도 준수한 성능을 보여주는것을 볼 수 있습니다.
Ablation study
마지막으로 Bottleneck layer에서 non-linearity 유무에 따른 성능변화와 Shortcut의 위치에 따른 성능변화를 살펴봤습니다.
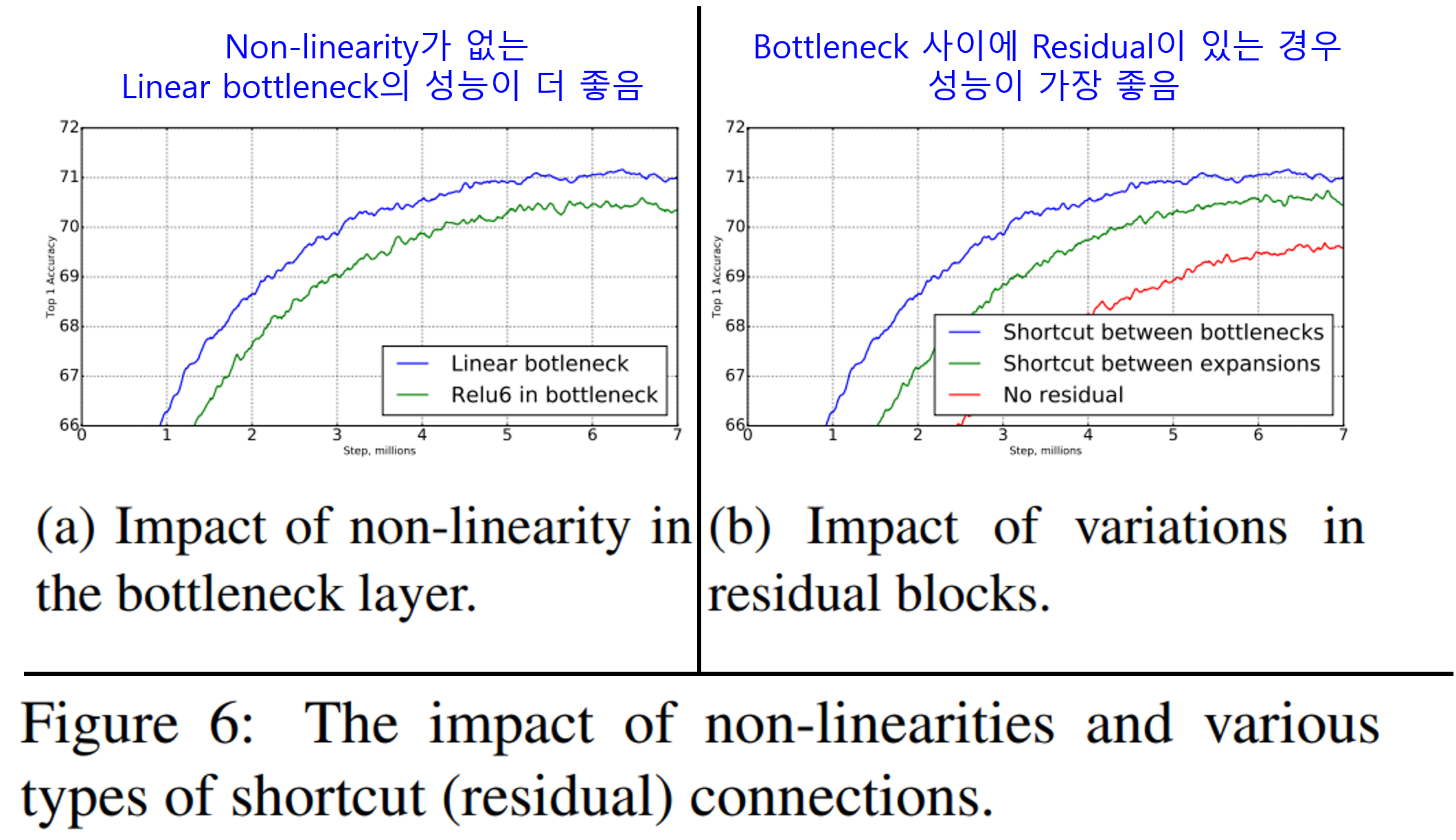
처음 설계 전략에서 설명했던 바와 같이 non-linearity(ReLU)가 없는 bottleneck layer가 더 좋은 성능을 보여주며, 이로부터 manifold of interest가 bottleneck에서 더 잘 보존됨을 알 수 있습니다.
다음으로 Shortcut connection의 위치에 따른 성능변화를 살펴봤습니다. 그 결과 Bottleneck block사이에 shortcut connection을 연결하는 경우가 성능이 가장 좋았습니다.
결론
MobileNet V2에서는 고차원에 있는 정보를 손실없이 저차원에 저장하는 아이디어를 바탕으로 Inverted Residual BottleNeck 구조를 사용한 네트워크를 설계하여 효율적이면서 성능을 최대한 보존하는 결과를 보여주었습니다.
네트워크 자체가 Inverted Residual Block을 단순히 쌓아올려 구성했기 때문에 구현이 쉬우면서 필요에 따라 block수를 조절하며 네트워크 크기를 조절하며 사용할 수도 있습니다.
또 이 글에서는 설명하지 않았지만, 논문에서는 이러한 단순한 구조 덕분에 Tensorflow나 Caffe같은 Framework에서 최적화하기 쉬운 장점도 있다고 강조하고 있습니다.
결론적으로 MobileNet V1과 마찬가지로 어느정도 성능이 보장되면서 가벼운 네트워크로 모바일 환경을 타겟으로 할 때 유용한 네트워크라고 생각됩니다.
참고자료
MobileNetV2: Inverted Residuals and Linear Bottlenecks
진솔님 블로그
전차둥이님 블로그
딥런이 공부방 블로그
