
아래 내용은 개인적으로 공부한 내용을 정리하기 위해 작성하였습니다. 혹시 보완해야할 점이나 잘못된 내용있을 경우 메일이나 댓글로 알려주시면 감사하겠습니다.
Pruning이란?
가지치기로 해석할 수 있는 Pruning은 Model의 weight들 중 중요도가 낮은 weight의 연결을 제거하여 모델의 파라미터를 줄이는 방법입니다.
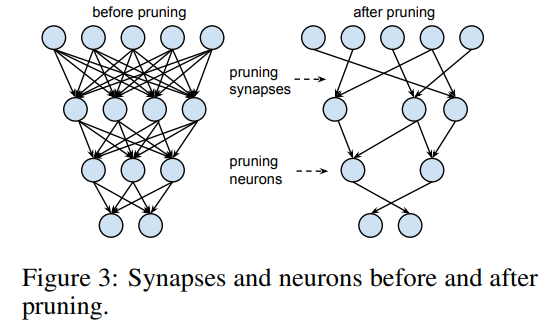
만약 각 weight 값이 결과에 주는 영향이 다르다면, 상대적으로 영향력이 작은 weight는 삭제하여도 결과에 주는 영향이 작을 것입니다.
따라서 최종 결과에 영향력이 적은 weight를 제거한다면 적은 파라미터를 가졌지만 유사한 성능을 보여주는 모델을 만들 수 있을 것 입니다.
Pruning은 네트워크의 성능이 크게 저하되지 않는 선에서 weight들을 최대한 sparse(희소하게 : 대부분의 값이 0이도록) 하게 만드는 방법으로 정의할 수 있습니다.
딥러닝 Network의 각 layer는 weight(가중치)와 bias(편향)로 이루어져 있습니다. 파라미터는 각 weight값과 bias값 모두를 의미합니다.
일반적으로 bias는 상대적으로 파라미터에서 차지하는 비율이 적기 때문에 pruning 해봐야 큰 차이가 안나기 때문에 가치가 없습니다. 따라서 일반적으로 pruning하지 않습니다.
Sparsity(희소성)의 정의
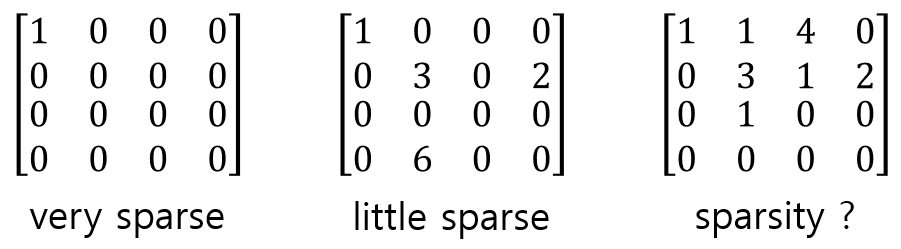
위에 있는 세개의 16x16 행렬 중 제일 왼쪽은 한개의 요소를 제외하고는 전부 0이기 때문에 희소행렬(sparse한 행렬)로 판단됩니다. 가운데 행렬도 0이 대다수를 차지하기 때문에 희소행렬로 보입니다.
그렇다면 오른쪽은 행렬은 희소행렬일까요? 분명 0이 반이상 차지하지만 희소행렬로는 보이지 않습니다.
만약 대부분의 weight가 0이면, sparse(희소)한 것을 간주할 수 있습니다. 그렇다면 대부분이라는 기준은 정확히 어떻게 설정할 수 있을까요?
대부분을 구체적인 수치로 확인하기 위해 사용하는 개념이 Sparsity입니다. Sparsity란 전체 네트워크에서 얼마나 많은 weight가 (작은 수가 아닌)정확하게 0인지를 나타내는 척도입니다.
sparsity를 측정할 수 있는 가장 간단한 방법은 norm 을 활용하는 것 입니다.
위 수식에서 각 요소가 1 또는 0으로 되며, norm은 요소의 값이 0이 아닌 값들의 개수가 됩니다.
이제 전체 weight 개수 대비 norm의 값을 확인하면 sparsity를 알 수 있습니다.
Pruning 에서 설정해야 할 내용들
1) Pruning granularity
Pruning할 때 각 요소를 pruning하는 것을 element-wise pruning 또는 fine-grained pruning이라고 합니다.
어떠한 요소들을 그룹으로 묶고 그 그룹 전체에 대해 pruning 하는것은 Coarse-grained pruning, structed pruning, group pruning 또는 block pruning 이라 부릅니다.
그룹은 여러 모양과 크기가 될 수 있습니다.
위와 같이 Pruning할 요소를 정하는것이 필요합니다.
2) Prunning criteria
Pruning은 weight들 중 어떤 요소를 어떻게 prune할지 정하기 위한 기준이 필요합니다. 이 기준을 pruning criteria라고 합니다.
한가지 예로 가장 흔하게 사용되는 pruning criteria를 예시로 들자면, weight 값에 대해 어떠한 threshold를 기준으로 할지 (0으로 바꿀지, 그대로 놔둘지) 판단하는 것입니다.
Weight들 중 절댓값이 작은 weight는 결과에 미치는 영향이 작을 것이기 때문에 앞의 예시는 실제로 활용될 수 있는 pruning criteria 중 하나입니다.
pruning criteria을 설정할 때 고려해야할 요소들 중 다른 한가지는 dense-model(pruning 전 원래 모델)과 비교했을 때 어느정도의 정확도 하락을 허용할지 입니다.
3) Pruning schedule
가장 직설적인 pruning방법은 학습 후 pruning 하는 것 입니다. 이렇게 학습 완료 후 한번 pruning하는 것을 one-shot pruning이라고 합니다.
학습과 pruning과정을 거친 후 sparse한 네트워크를 다시 학습하는 것을 iterative pruning이라고 합니다.
pruning한 네트워크를 재 학습 하는 경우 성능이 더 상승한다고 알려져 있습니다.
이 때, one-shot pruning을 할지 iterative pruning을 할지, iterative pruning이라면 얼마나 많이 반복할지, 매 iteration 마다 Prunning criteria을 어떻게 설정 할지, 어떤 weight를 prune할지, 언제 멈출지와 같은 정보를 총칭하여 Pruning schedule이라고 합니다.
pruning을 멈추는 타이밍 또한 schedule로 표현할 수 있습니다. 예를들어 어떠한 sparsity level에 도달하면 멈추거나 목표로 하는 연산량에 도달하면 멈추도록 설정하는 것오 schedule로 볼 수 있습니다.
Sensitivity analysis
Pruning을 할 때 가장 어려운 부분은 weight을 prune할지 결정하는 threshold 값을 정하는 것과 목표로 하는 sparsity level을 정하는 것 입니다.
Sensitivity 분석은 어떤 weight 또는 layer가 pruning할 때 영향 많이 받는지 분석할 수 있는 방법으로 threshold나 sparsity level을 설정할 때 유용합니다.
Sensitivity 분석하는 한가지 예시는 다음과 같습니다.
① 먼저 특정 weight 또는 group의 pruning level(sparsity를 몇 까지 할지)을 설정하고, pruning 진행 후 성능을 평가합니다.
② 1번 과정을 모든 weight 또는 group에 대해 수행합니다.
이 과정을 통해 나온 결과로부터 우리는 어떤 weight 또는 group이 얼마나 민감한지, 즉 결과에 얼마나 영향을 주는지 알 수 있습니다.
많은 구조를 prune할 수록 model 구조에 대한 sensitivity 분석이 가능해집니다.
요약하면 각 weight가 결과에 주는 sensitivity를 이해하기 위해 각각의 weight를 prune한 뒤 평가하고, 정확도가 어떻게 변하는지 살펴봄으로 써 그 weight가 어느정도 중요한지 알 수 있다는 것 입니다.
한 가지 예시로 AlexNet의 pruning sensitivity를 살펴보면 아래 표와 같습니다.

Pruning 방법
1) Magnitude Pruner
Maginiture Pruning은 가장 기본적인 방법으로, 어떠한 값을 기준으로 weight를 thresholding 하는 방법입니다.
만약 weight값이 기준값 이하 라면 0으로 만들고, 기준값 보다 크다면 그대로 두는 것 입니다.
2) Sensitivity Pruner
각 layer마다 threshold값을 찾는 것을 쉽지 않습니다.
Sensitivity Pruning 방법은 Convolution layer 그리고 Fully connected layer가 가우시안 분포를 갖고있다는 것을 활용합니다.
예를들어 pre-trained된 AlexNet의 첫번째 Convolution layer와 Fully-connected layer의 weight 분포를 보면 가우시안 분포와 유사함을 알 수 있습니다.
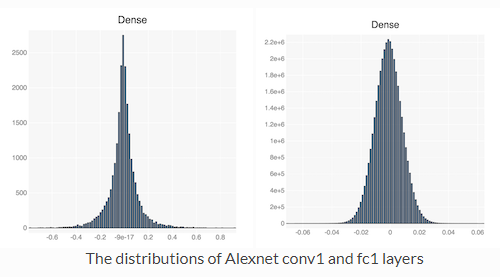
따라서 Sensitivity Pruner에서 thresholding하는 pruning 기준은 아래와 같이 설정합니다.
where is std of layer as measured on the dense model
만약 어떤 layer의 68% weight들의 값이 표준편차 보다 작을 때, 기준이 되는 는 % 가 됩니다.
그렇다면 는 어떻게 구할 수 있을까요?
Song Han 교수님의 논문인 Learning both Weights and Connections for Efficient Neural Networks에서는 앞장에서 살펴본 sensitivity를 활용합니다.
논문에서는 iterative pruning을 사용했고, 매 pruning 마다 sentitivity parameter인 값을 수정하였습니다.
따라서 Sensitivity Pruner의 동작은 아래와 같습니다.
- 모델에 대해 Sensitivity 분석을 수행한다.
- 분석을 통해 나온 Sensitivity parameter에 weight들 분포의 표준편차를 곱하여 threshold로 사용한다.
3) Level Pruner
Level Pruner는 특정 값 기준으로 thresholding하는 것이 아닌 특정 layer의 sparsity level로 pruning합니다. 즉, 각 weight의 값을 보고 판단하는 것이 아닌 layer의 sparsity가 특정 값이 되게 끔 pruning합니다.
예를들어 어떠한 layer의 sparsity level을 0.5(50%의 값이 0이게)로 pruning 한다고 가정하면, layer에 있는 weight값들 중 상위 50%는 그대로 놔두고 하위 50%는 0으로 prune합니다.
Level Pruner의 동작은 아래와 같습니다.
- pruning하려는 layer의 절대값을 기준으로 정렬
- 정렬된 결과에서 가장 작은것부터 sparsity level이 목표로 하는 값이 되는 수 만큼의 weight를 0으로 변환
4) 그 외 prunning 방법
설명한 Pruning 기법 이외에도 Splicing Pruner, Automated Gradual Pruner (AGP), RNN Pruner, Structure Pruners, Hybrid Pruning 등 다양한 pruning 방법이 있습니다.
여기서 정리하지 않은 pruning 알고리즘 내용들은 network compression을 위한 open-source인 Neural Network Distiller의 Document에 잘 정리되어 있습니다.
Sparse Matrix의 활용
Pruning을 거쳐 Sparsity가 높은 layer가 만들어집니다. 하지만 0으로 pruning된 weight에 대한 정보를 여전히 가지고 있기 때문에 모델의 용량을 줄이기 위해서는 0에 대한 정보를 제거할 필요가 있습니다.
실제로 weight layer를 하나의 행렬로 보았을 때 pruning된 결과는 Sparse matrix(희소행렬)의 형태로 나타날 것 입니다.
이러한 희소행렬을 효율적으로 저장하는 방법으로는 COO(Coordinate Format)과 CSR(Compressed Sparse Row)가 있습니다.
COO는 0이 아닌 값의 값, 행, 열을 별도의 메모리에 저장하는 방법입니다. Sparse matrix에서 0이 아닌 값의 개수가 개일 때 COO의 경우 개의 메모리 공간만이 필요합니다.
CSR은 COO처럼 값과 행의 정보를 가지고 있되 열에 대한 정보를 포인터(주소값) 형태로 가지고 있는 형태를 의미합니다.
아래와 같은 예시에서, 데이터와 열의 인덱스는 COO와 마찬가지로 저장됩니다.
행은 각 행에 몇개의 데이터가 있는지를 확인 후 그만큼 더하는 과정을 거칩니다. 예를들어 첫 번째 행은 2개의 데이터가 있습니다. 따라서 열 포인터는 +2를 합니다.

Matrix의 행의 길이가 개일 때 CSR에서 필요로하는 메모리공간의 개수는 개 입니다. 항상 그런것은 아니지만 CSR이 COO보다 더 적은 데이터를 사용한다고 알려져 있습니다.
행에 대해 정리한 CSR과 반대로 열에 대해 정리한 것을 CSC라고 합니다. 저장방법은 CSR과 동일합니다.
이렇게 Sparse Matrix를 저장하는 방법을 사용하면 Pruning된 weight layer를 효율적으로 저장할 수 있으며 저장할 때 필요한 메모리 수도 줄일 수 있습니다.
참고자료
딥 러닝 모델의 경량화 기술 동향
Learning both Weights and Connections for Efficient Neural Networks
Neural Network Distiller Document
동빈나님 유튜브 영상
위키피디아 - 희소행렬
