[제로베이스] 데이터 사이언스 15기 - (06-02 EDA 스터디노트)
0

오늘 수강한 강의 - EDA 웹 데이터 분석 (01 ~ 13)
01 ~ 04 Beautiful Soup
Beautiful Soup 기초와 웹데이터
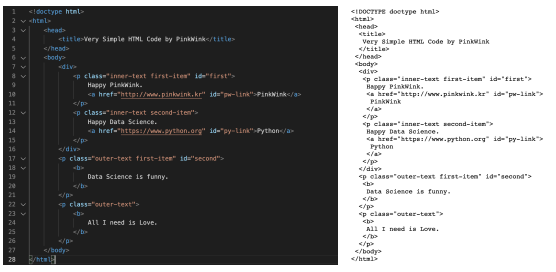
- 03.test_first.html 파일을 실행
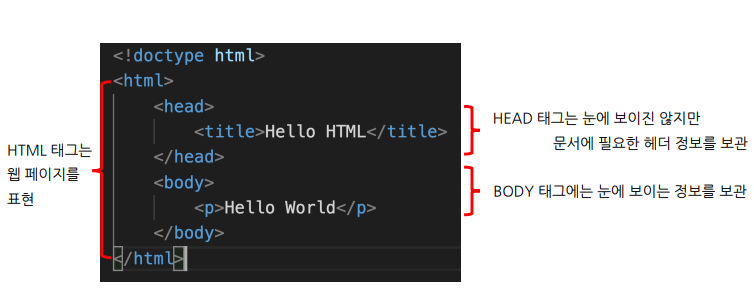
- test_first.html 내용
- 파일로 저장된 html 파일을 읽을 때
- open: 파일명을 함께 읽기(r) / 쓰기(w) 속성을 지정
- html.parser: Beautiful Soup의 html을 읽는 엔진 중 하나(lxml도 많이 사용)
- prettify(): html 출력을 이쁘게 만들어 주는 기능
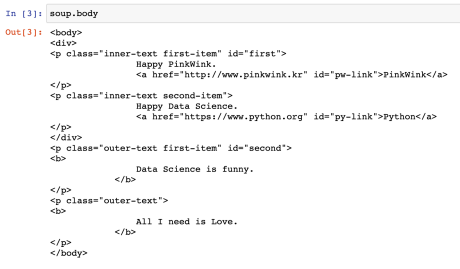
- soup.body: soup에서 body 태그만 보고싶을때
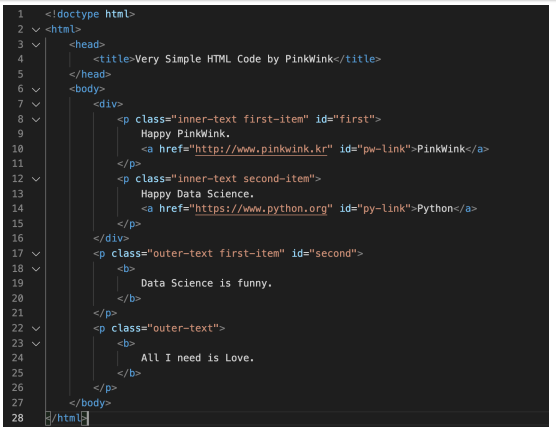
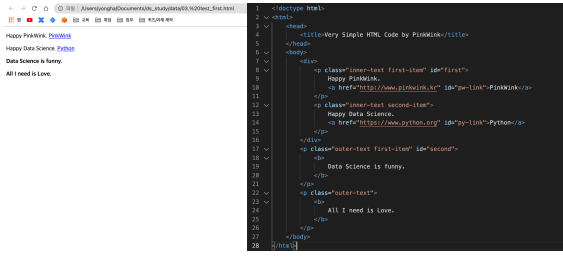
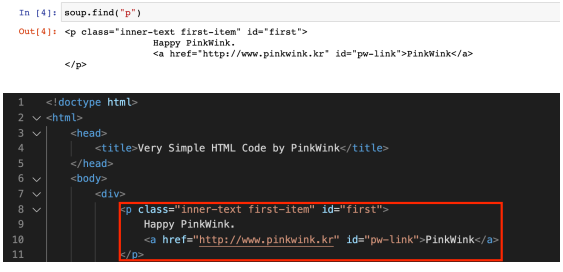
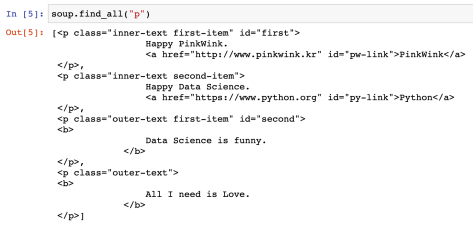
- soup.find("p"): soup에서 p 태그 찾기
- 그러나 하나만 찾아줌
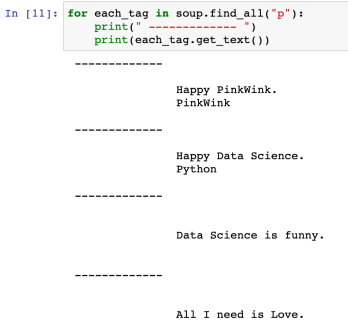
- 전부 다 찾고 싶다면 soup.find_all("p")
- find_all()은 지정된 태그를 모두 찾아준다
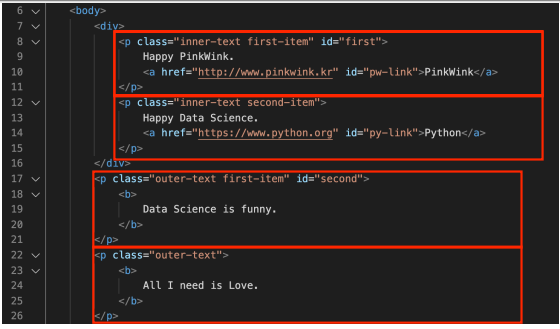
- p 태그 안에 특정 클래스만 찾을 수 있다
- soup.find_all(class_="outer-text"): 클래스 이름이 outer-text인 클래스를 모두 찾아준다
- soup.find_all(id="first"): 이름이 first인 아이디를 하나만 찾아준다
- HTML 내에서 속성 id는 딱 한 번만 나타난다
- 그래서 find_all() 함수는 의미가 없다
- 단, 검색결과를 list로 받고 싶다면 id라도 find_all() 함수를 사용한다
- get_text(): 태그 안의 글자를 가져오는 함수
- soup.find_all("a"): 외부로 연결되는 링크의 주소를 알아내는 방법






05 ~ 09 크롬 개발자 도구 이용하기
Beautiful Soup 예제 1 - 네이버 금융
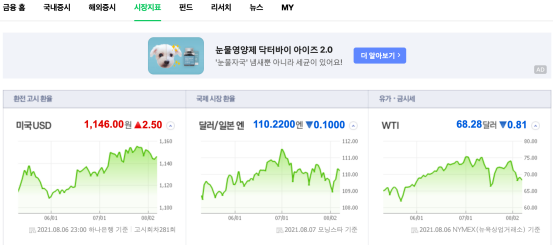
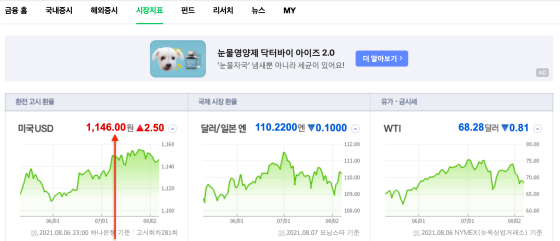
- 시장지표 탭으로 이동
- USD 환율 체크
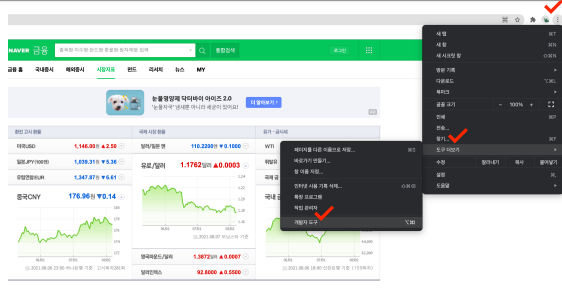
- HTML을 잘 모를때 사용할 수 있는 것이 크롬 개발자 도구
- 크롬 개발자 도구 활용
- 크롬 설정 - 도구 더보기 - 개발자 도구(화면 오른쪽부터 선택)
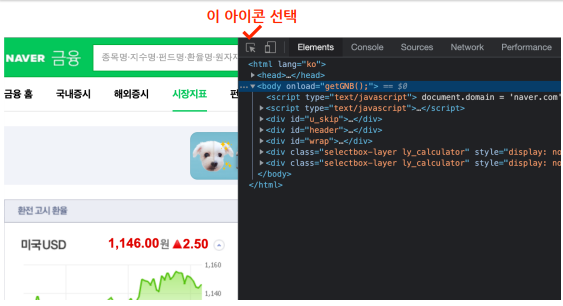
- element select 버튼 누르기
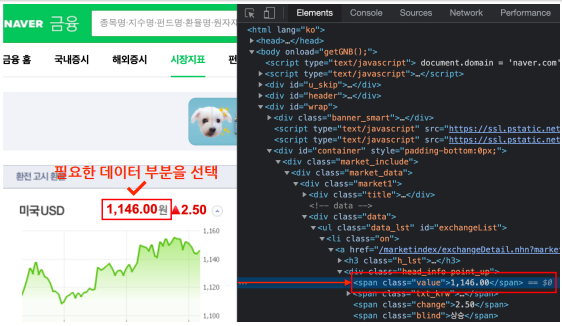
- 필요한 데이터 부분을 선택
- 내가 원하는 HTML 태그가 위치한 곳을 찾아 갈 수 있다
- URL 주소 복사
- https://finance.naver.com/marketindex/
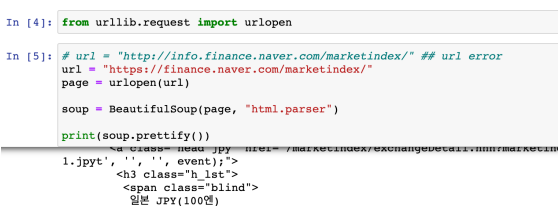
- 웹주소(URL)에 접근할 때는 urllib의 request 모듈이 필요하다
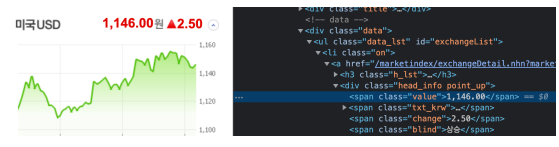
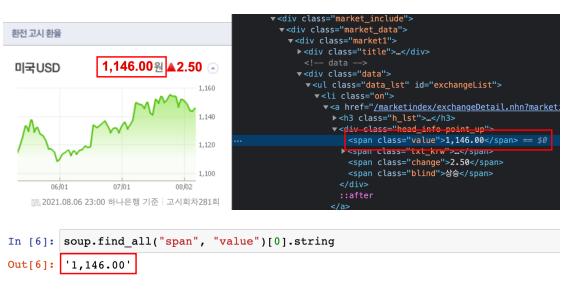
- find_all 명령으로 span의 value를 찾기
- 그중 첫번째 string
10 ~ 11 위키백과 문서 정보 가져오기
Beautiful Soup 예제 2 - 여명의 눈동자
- 여명의 눈동자 위키백과 페이지로 이동
- 메모장이나 Jupyter Notebook 셀에 붙여 넣어 보자
- 이상하게 바뀜
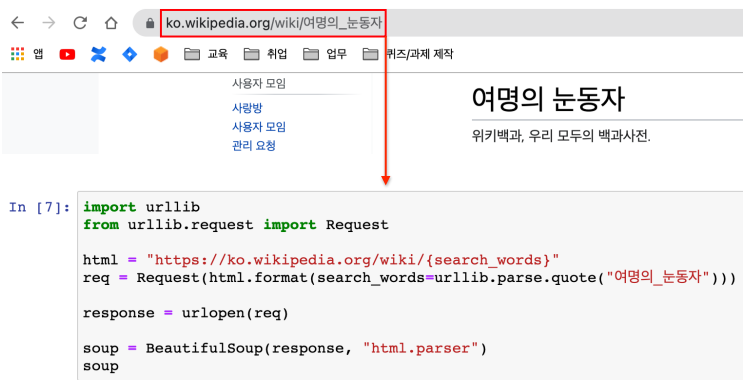
- 웹주소는 UTF-8로 인코딩 되어야 한다
- {}는 string에서 변수가 됨
- html.format
- urllib.parse.quote() -> UTF-8로 변환해줌
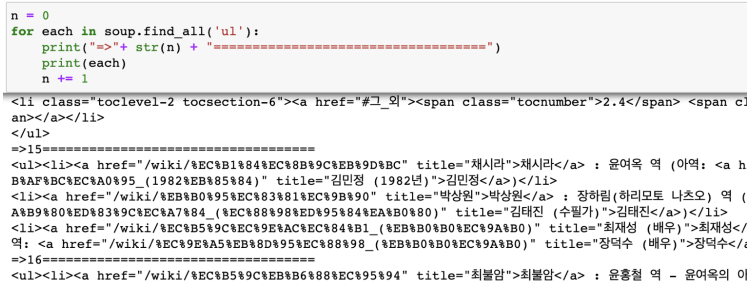
- soup.find_all("ul")[15]

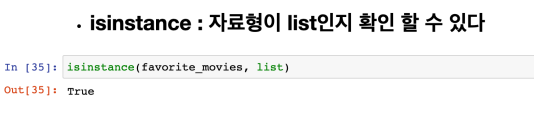
12 ~ 13 list 데이터형
List 자료형과 반복문에 대한 짧은 정리
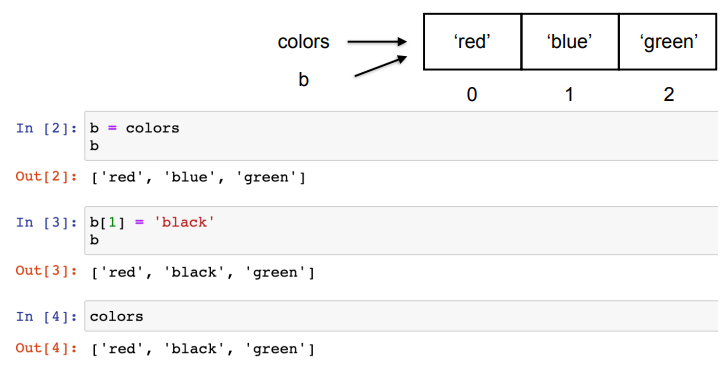
- 메모리 공간이 같으므로 colors도 바뀜
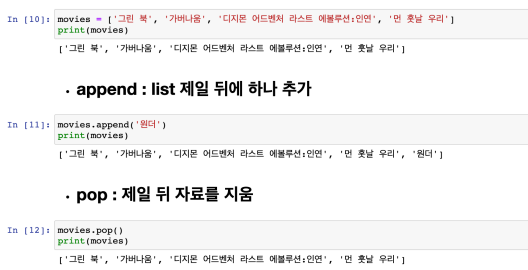
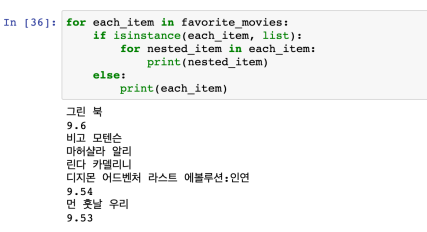
- append를 사용하면 리스트 안에 또다른 리스트를 집어넣게됨
- 리스트안에 리스트가 있더라도 전체적으로 다 풀어서 출력해라






재미있었던 부분
작년에 프론트엔드 독학중이었을때 HTML과 CSS를 공부한 적이있었는데 그때 배웠던 부분이 나와서 반갑고 재미있었다
어려웠던 부분
예전에 배울때는 기본적인 것을 배웠던 것에 반해 오늘은 더 깊게 들어간 느낌이어서 하는 중간중간 멈춰서 따로 찾아보고 이해하는 데에 시간이 많이 들었다
느낀점 및 내일 학습 계획
항상 느끼는 것이지만 첫 부분 이외에 쉬운 부분이 없다
계속해서 모르는 부분은 반복해서 봐야겠다

데이터 부트캠프 참여중