
Prologue
벌써 프로젝트의 네번째 시리즈가 끝이 났다. 두번째 프로젝트부터 이어지는 팀원으로 4번째 프로젝트까지 이어서 진행하게 되었다. 진행하면서 호흡도 잘맞았고 각자의 장단점을 서로 보완하여 발표가 끝날때 쯤이면 칭찬을 주로 들었다. EDA장인이라는 강사님의 말이 가장 임펙트 있었다.
이번 프로젝트는 AI Stages 플랫폼을 활용해 지금까지 배워왔던 머신러닝 및 관련 내용에 대해 스스로 적합해보고 질문해보는 시간을 갖도록 해주는 좋은 대회였다. 비록 시스템간의 이슈는 존재했지만 관리측의 대응으로 최종 결과 및 우리가 지금까지 진행했던 결과에 대한 오류는 수정하고 있다고 공지를 받았다.
개요
1. 프로젝트 개요
A. 개요
지속적으로 변하는 서울시의 아파트 가격을 예측한다. 이로 인해 부정거래 및 허위매물에 대해 파악하고 앞으로 아파트 가격이 어떻게 형성되는지 머신러닝 모델링을 통해 값을 예측하는 프로젝트이다. 데이터 셋은 2007년부터 2023년 06월까지 train 데이터로 제공되고, 2023년 7월 ~ 9월 까지의 데이터를 테스트 셋으로 주어졌다. 추가 데이터로 버스 및 지하철 좌표를 추가로 주어졌으며 외부 데이터를 가져올 수 있도록 허용했던 대회였다.
B. 환경
팀구성 : 5인 1팀, 인당 3090ti서버를 VSCode와 SSH로 연결해서 사용
협업 환경 : Notion, Github
의사 소통 : Slack, Zoom, Offline Meeting
2. 프로젝트 팀 구성 및 역할
전체 목록
- 외부 데이터 수집
- 데이터 EDA
- 전처리 및 train/test data 생성
- 머신러닝 모델링
- 파라미터 튜닝
- 앙상블
팀 구성
배정 받은 팀은 5인이었다. 그러나 자신만의 사정으로 인해 대회 참여가 어려워졌던 한 분을 제외한 네명이서 팀을 이끌어 나갔으며 전체 목록에 있는 역할은 전부 참여하였지만 각자 파트별로 비중을 둔 선택을 진행하여 주된 역할을 담당하였다.
여기에서 나는 주로 외부 데이터 수집 파트와 전처리, EDA를 담당하였고 모델링 및 이하 파트에서는 진행 방향에 대해 상의하고 적용하고자 하는 방법에 대해 검토하고 토론하는 역할을 주로 담당하였다.
3. 프로젝트 수행 절차 및 방법
A. 팀 목표 설정
1주차 : 사전에 진행되었던 캐글, 데이콘 대회를 참조하여 미리 연습해보거나 업스테이지에서 준비해준 강의를 보고 적용해 볼 방법에 대해 정리하는 시간 갖기
2주차 : 데이터 확인 및 EDA와 외부 데이터중 가져올 수 있는 요인에 대해 검색 및 가져오기
3주차 : 모델링과 외부 데이터에 대한 EDA를 진행하여 최종 모델 완성, 마지막 Ensemble 전략
B. 프로젝트 사전기획
(1) Time-line 수립
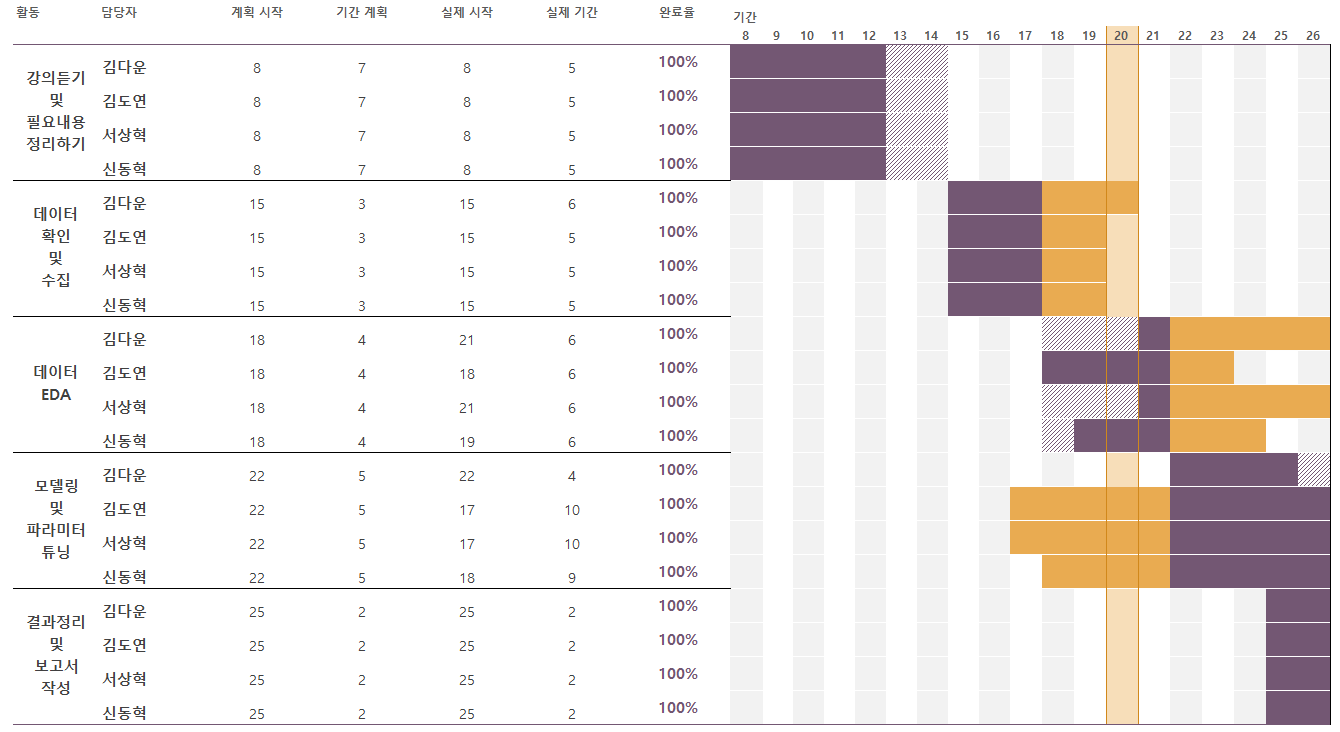
(2) 협업 문화
- 대회의 마무리 시기에는 같이 모여서 마무리 할 것(offline meeting)
- 각자의 일을 하다가 어느정도 결과가 나오면 같이 보면서 상의할 것
- 코드를 작성하고 진행할때 꼭 주석처리 및 마크다운 언어로 작성해둘 것
- 각자의 아이디어 및 사전 조사 자료는 노션에 공유해둘 것
- 특별한 사정이 없는 한 회의할 때 빠지지 말기
- 혼자서 계속 진행하지 말고 중간중간 상황에 대해 알려주기
4. 수행 결과

최종 전략
기존 변수에 대한 내용이 없었기 때문에 외부에서 데이터를 가져와서 결측치가 많은 변수를 대신 하거나 보완하여 활용할 수 있는 데이터를 많이 채우고자 함
금융관련 요인 : 금리, GDP, 전세가율
거리 요인 : 역세권, 한강조망권, 숲이나 도시공원같은 자연 조경과 관련된 시설물
교육 요인 : 학군, 학급 개수
제재(制裁) 요인 : 부동산 제도 변화
아파트 구성 요인 : 방 개수, 화장실 개수, 주차장 면적, 세대수, 세대당 주차장 대수
이중 나의 역할은 주로 거리요인, 교육요인과 아파트 구성요인을 담당하였다. 또한 서브로 금융 관련 요인을 담당하였다.
코드 및 설명은 github에 자세히 나와있다. 전략은 총 2가지 방법으로 이뤄졌는데 I전략은 외부 데이터를 의미가 존재하는 변수들로 최대로 채우고 부스팅 모델을 적용하는 방법으로 진행하였고, II전략은 아파트 가격이나 가장 상관성이 높은 전용면적에 대해 각자 구간을 만들어서 클러스터링을 진행하여 기본 베이스 모델과 앙상블하는 전략을 선택하였다.
결과적으로 리더보드의 전산 오류 요인이 대회가 끝나고 밝혀졌지만 리더보드에서 방향은 클러스터링 방향으로 가는 것이 성능이 좋았지만 프라이빗 스코어를 확인했을 때 추가한 변수들이 많은 모델이 성능이 더 좋은것을 확인할 수 있었다.
처음에 생각하던 상식선에서 이해가 되지 않는 흐름으로 가고 있어서 생각의 한계를 맞이한줄 알았으나 실제 전산 오류로 데이터 셋의 오류임이 밝혀저 배경지식을 도입해 생각했던 예상과 맞아서 한결 다행스러웠다.
5. 자체 평가
새로운 시도
- 기본적인 Baseline 구축을 위해 EDA와 데이터 수집을 다같이 진행한 후 완성된 데이터셋을 활용하여 Modeling을 진행
- 각자의 경험치를 위해 AutoML을 사용하지 않고 직접 GridSearch, Optuna 등 여러 도구를 직접 사용해 보는 과정을 진행
- 앙상블 방법 중 weight mean 방법 또한 적용해보기
- 없는 데이터를 직접 크롤링해서 결측치를 채워보기
좋은 변화
- 같이 의논하게 되면서 목적에 맞지 않게 하는 일이 줄어들게 되었다.
- 다양한 모델을 구현해봤으며 앙상블 방법에 맞게 적용해봤다.
- 부스팅 모델에 대해 적용하는 방법에 대해 익숙해졌다.
- 다양한 관점에서 보는 EDA 방법을 적합할 수 있었다.
잘 되지 않은 것
- 마지막 크롤링 데이터를 가공하는데 시간이 너무 오래 소요 되었다.
- 여러개를 동시에 진행하였기 때문에 하나의 작업에 집중할 수 없었다.
- 각자 하는일이 많았기 때문에 서로 어떠한 일을 하는지 알 수 없었기 때문에 서로간의 오해가 존재했다.
아쉬운 점
- 중간중간에 시스템 이슈가 있어서 대회의 몰입도가 저해되는 사례가 있었다.
- 짧은 시간동안 대회가 진행되었기 때문에 미처 사용해보지 못했던 피처가 존재했다. 시간 안배를 효율적으로 개선하는 방안을 마련해야겠다.
배운점 및 시사점
- EDA 관점에 대해 확실시 할 수 있게 되었다.
- 앙상블 방법에 대해 무엇인지 예시를 들어 설명할 수 있게 되었다.
프로젝트를 마치며
지금까지 머신러닝 프로젝트까지 진행하면서 내가 가장 잘 할 수 있었던 프로젝트가 마무리 되었다. 이를 발판삼아 앞으로의 딥러닝 프로젝트 2개와 실전 파이널 프로젝트까지 같은 팀으로 좋은 시너지를 발휘해서 승승장구하여 팀원 전원이 원하는 결과물에 도달할 수 있게 최선을 다하고 싶다.
앞으로는 딥러닝의 영역이니만큼 내가 배울것이 많을 것이라 생각이 든다. 이 과정을 통해 가져갈 수 있는 요인은 모조리 가져갔으면 좋겠다.
