ML프로젝트
시작에 앞서
기존에 알고있던 머신러닝 방법을 활용하여 현재 진행하고 있는 대회나 이미 진행이 완료된 대회를 통해 팀별 프로젝트를 진행하는 방식으로 운영되었다. 처음에 하고싶은 대회나 주제를 미리 선정해서 어느정도 후보가 존재하였고 나는 이전 프로젝트에서 진행하였던 Kaggle competition중에서 cirrhosis의 Stage를 맞춰야하는 이미 마무리 된 대회가 있길래 이 대회를 골랐다. 보기에 없었기 때문에 기타 항목에서 골랐는데 기존에 같이 하던 팀에서도 다들 비슷한 생각을 하였다. 따라서 이번 프로젝트에서도 같은 팀이 되었고 서로의 상의 끝에 총 세가지 프로젝트를 진행하기로 하였다.
지난 EDA 프로젝트
EDA프로젝트에서 우수 팀으로 선정되었다고 축하한다고 Slack에서 공지가 왔다. 지난번에 미왕빌딩에서 시달렸던 그때가 드디어 빛을 발휘한 것이다. 기존의 팀에서 연속으로 진행하게 되서 너무 신기하고 지난번보다 한결 편안하게 진행할 수 있어서 너무 좋았다. 상품은 기프티콘으로 맘스터치 싸이버거 세트가 한명당 하나씩 주어졌다. 생각지도 못한 우수팀이라니 앞으로의 프로젝트에서도 의지를 모아 이번에도 우수팀으로 거듭나자고 서로 화이팅하면서 시작했다. 사실 동혁님은 고민하다가 도망가려 했는데 붇잡혔다는 소문도 ...
프로젝트를 시작하면서
최종적인 목표를 KNHNES데이터를 활용하여 기존에 EDA 프로젝트에서 진행했던 cirrhosis를 예측하는 모델을 만들어 보고자 시작하였다. 그러나 다들 딥러닝이나 통계 분석쪽으로는 경험이 있지만 머신러닝에 대해 처음 접해보는 경우가 대다수였기 때문에 다른 대회를 통해 한번 익숙해지고 접근하자는 결론에 도달했다. 생각해보니 결과적으로는 중구난방이 되거나 용두사미가 되었던거 같기도 하지만.. 따라서 마침 일주일 남았던 대구 교통사고 피해 예측 AI 대회를 통해 머신러닝에 대해 감을 잡고 진행하자고 의논을 마무리 하였다. 그런데 진행하다보니 12월 5일자로 시작하게된 새로운 대회 Status를 맞추는 competition이 등장하면서 총 세가지를 진행하게 되었다. 이번에 언급하게 될 프로젝트는 대구 교통사고 프로젝트다.
주제
대구 교통사고 발생 케이스를 활용하여 사고의 피해 정도를 예측하는 대회였다. ECLO라고 해서 사망자수, 중상자수, 경상자수, 부상자수를 통해 계산하여 지수화 시킨 값이다. 사실 이런 지표 처음들어 보는데 생각해보니 그냥 피해자 조사해서 계산만 하면 되지 않나 라는 생각이 너무 들었다. 이 지수를 맞추는 대회로 계산 매트릭은 RMSLE(Root Mean Square log Error)이며 값이 음수로 나오게 되면 오류가 난다는 주의사항이 있었다. 머신러닝을 얼마전 학습한 사람들이 활용해보기 너무 좋은 대회였고, 데이터 개수 또한 딥러닝으로 적용하기엔 적은 데이터기 때문에 순전히 머신러닝을 활용하기 좋은 대회였다.
역할
우리가 진행해야 하는 내용을 다음과 같이 나누었다.
- EDA
- Make Baseline
- Modeling
- Submit predict value
- Feedback
여기서 나의 역할은 BaseLine코드를 생성하여 우리의 모델링 시작의 기반이 되는 기준점을 만들고 하나둘씩 확장해 나가는 방법을 선택하였다. 각 팀원들은 확보된 데이터를 EDA하고 모델링으로 진입하여 기존 Baseline 또는 가장 성능이 좋은 모델이랑 비슷한 valid score을 가져오거나 성능이 더 좋은 모델을 통해 제출하였고 제출한 모델의 public score가 얼마나 좋아졌는지 확인하면서 개선해 나가는 방식으로 진행하였다. 제출 기회가 하루에 3번씩이었기 때문에 신중하게 제출할 필요가 있었다. 이번에도 동혁은 그래프를 대량 생산하였는데 본인이 해석할줄 몰랐기 때문에 또 도연한테 혼났다... 따라서 회의를 반복적으로 진행하게 되었고 Feedback 이후에 필요한 EDA부터 predict value를 산출하기까지를 각자만의 방법으로 반복하였다.
프로젝트 내용
이번에도 여지없이 50장의 PPT가 나왔다. 이 프로젝트는 내가 주로 담당했기 때문에 PPT를 혼자서 만들어야했다. 진짜 너무 고생했다 PPT하나가 뭐라고 이렇게 오래걸리는지.. 옆에있는 도연은 나보다 만드는 속도가 2배 이상 빠르던데 던지고 도망갈까 잠깐 생각하다가 동혁 혼나는걸 보면 또 묵묵하게 하게된다. 발표 제한시간은 15분이었지만 우리 프로젝트가 3개인 것을 감안하면 총 5분이라는 시간밖에 존재하지 않는다. 무슨 100m 달리기도 아니고 타임어택하듯이 진행하나 싶긴한데 이걸 또 해내는 상혁이 있다. 대단해
제목
제목은 간단하게 다음과 같이 지었다. 요즘 PPT도 chat gpt마냥 추천 잘해줘서 디자인도 진짜 잘해주는것 같다. 너무 고도화된거 아닌가 모르겠네

데이터 확인 및 EDA
모든 프로젝트는 EDA가 중요한 만큼 맨 처음 데이터를 통해 EDA를 진행해야한다. 따라서 다음과 같이 아주 간단하게 알아보고 진행하였다.
데이터 구성
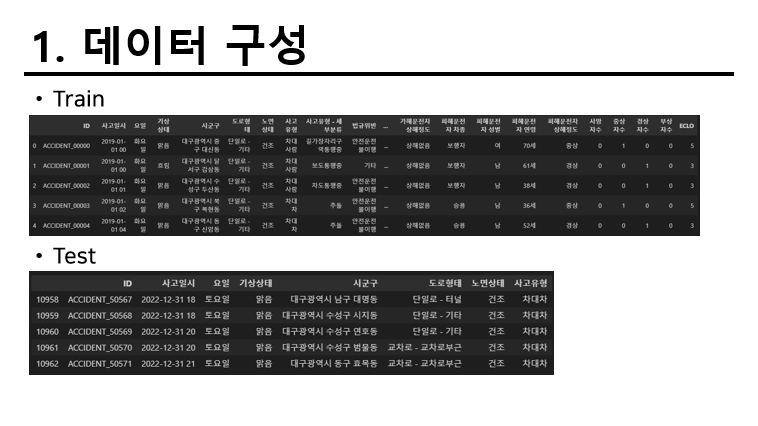
다음과 같이 Train에서 존재하는 데이터중 7가지 변수 이상이 Test에 없다. 따라서 기본적으로 데이터를 있는것만 사용해야 할지 아니면 존재하는 데이터를 요약이나 예측을 통해 만든다음 시작해야할지 고민이었다. 결과적으로는 Train에 없는 변수는 전부 제외하고 진행하게 되었다. 다른 이견은 크게 없었다.
간단한 EDA
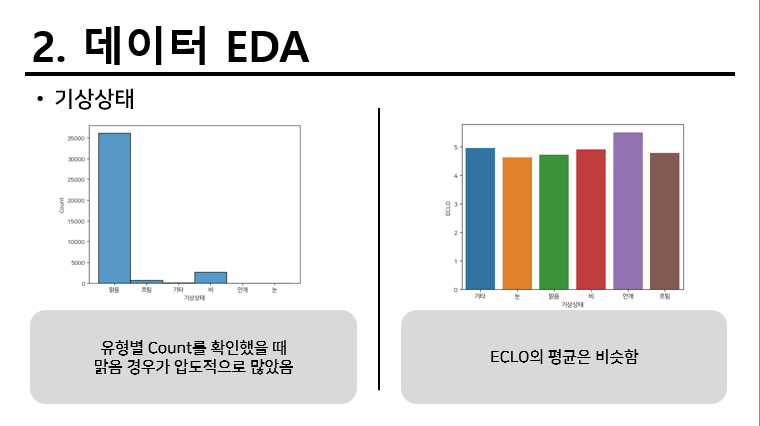
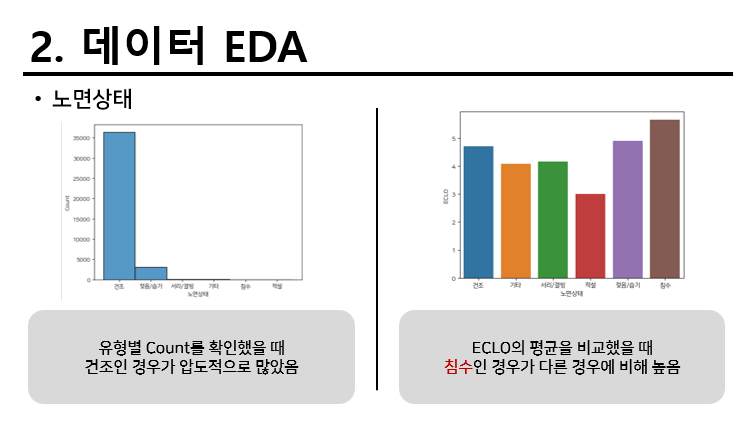
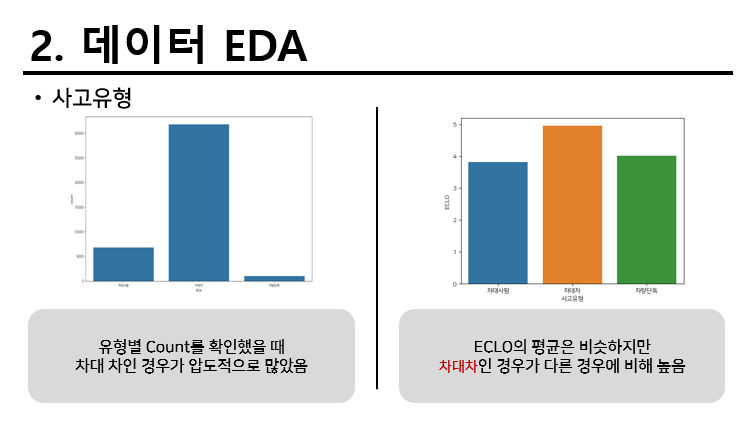
기본적으로 존재하는 데이터를 간단하게 EDA를 하였다. 내용은 다음과 같다.
모델 전략
우리의 전략은 기본적인 BaseLine을 확립하고 이 기반으로 계속 변형과 파생변수를 붙이는 활동 등 여러가지 전략을 통해 성능을 높히는 것을 선택하고 성능이 오히려 안좋아 지는 것을 제외하는 것이다.
BaseLine
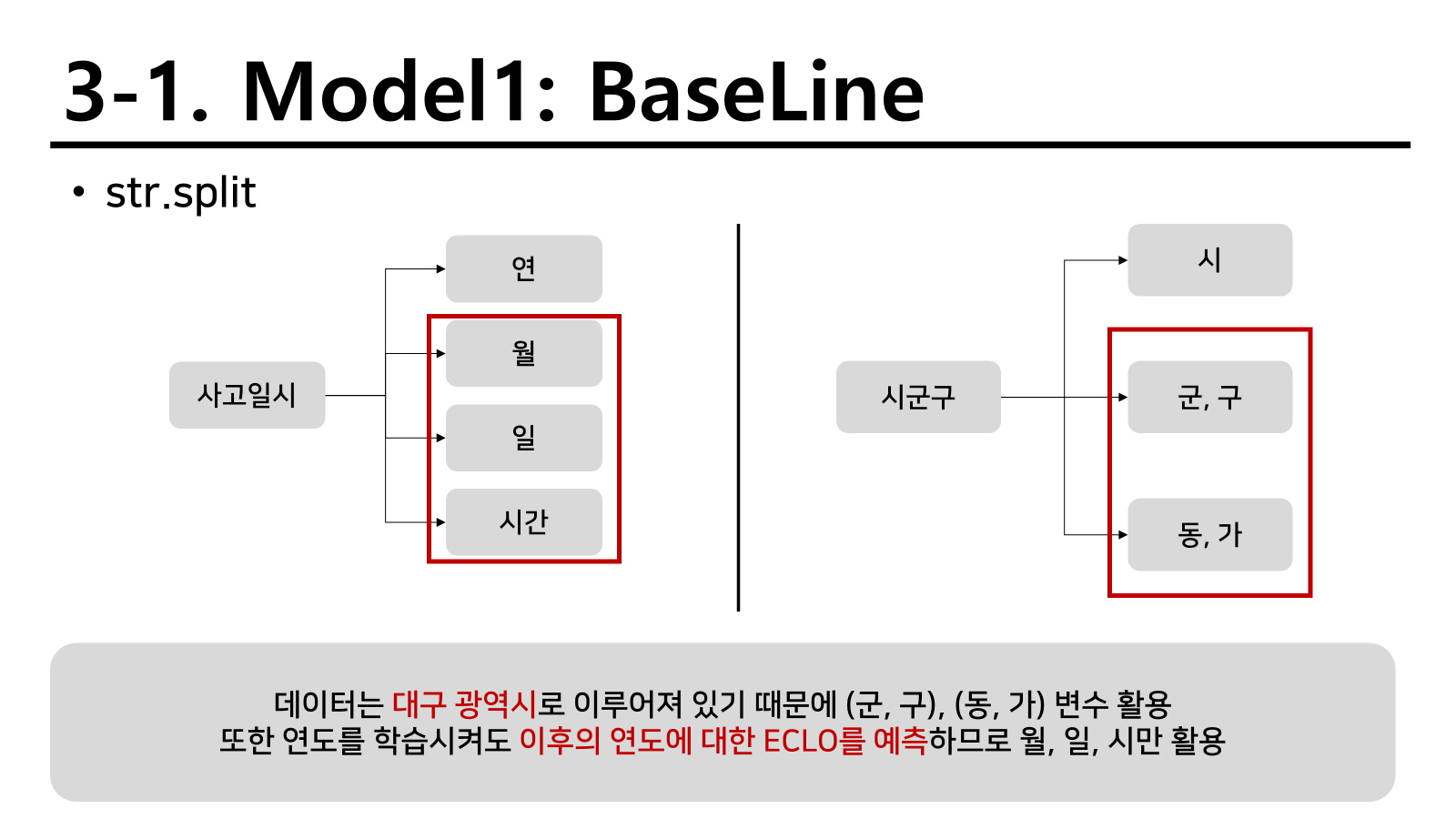
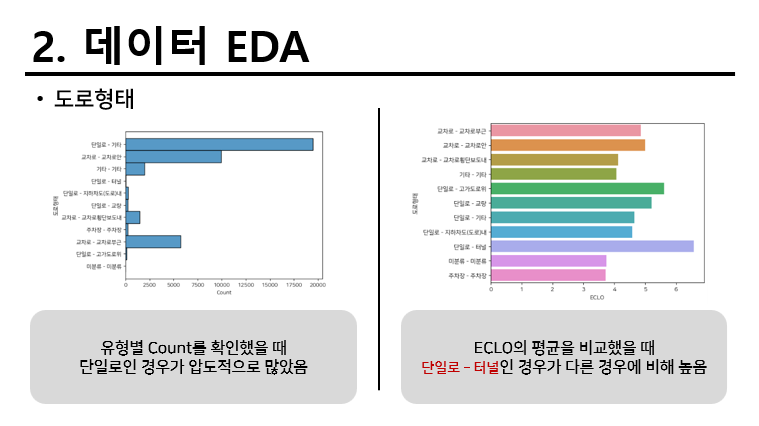
사고일시나 시군구와 같은 변수는 여러 정보가 혼합되어있는 형태로 존재했다. 따라서 이를 분리하기 위해 다음과 같이 split를 적용하였다.
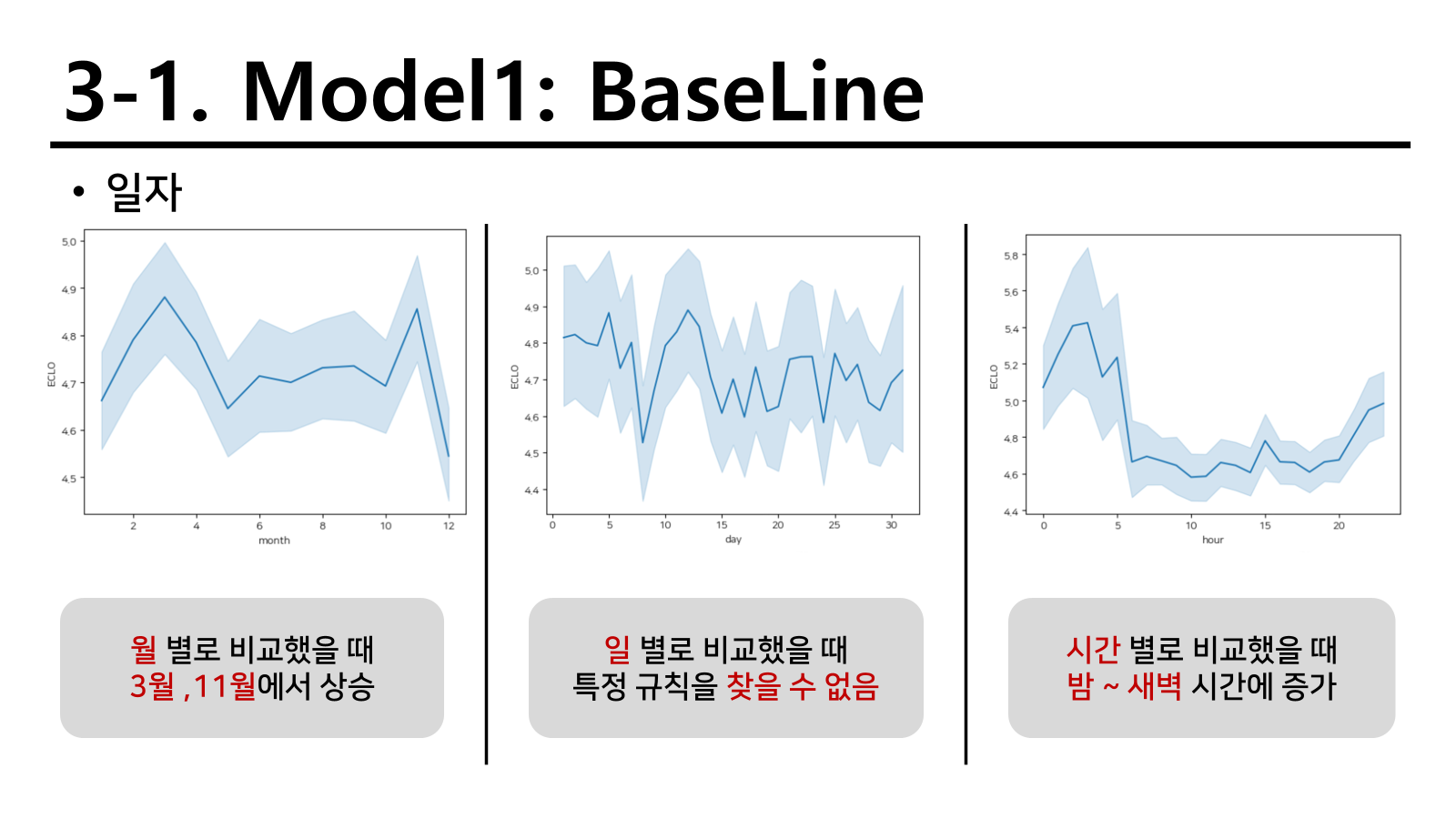
연도는 앞으로의 기간밖에 존재하지 않기 때문에 제외하고 월, 일, 시를 확인하였을 때 다음과 같이 경향성을 확인할 수 있었다. 여기서 3월과 11월이 왜 이런지 궁금하긴 했지만 예상상 대입 시기와 수능 종료 시기라 추측을 하고 넘어갔다.
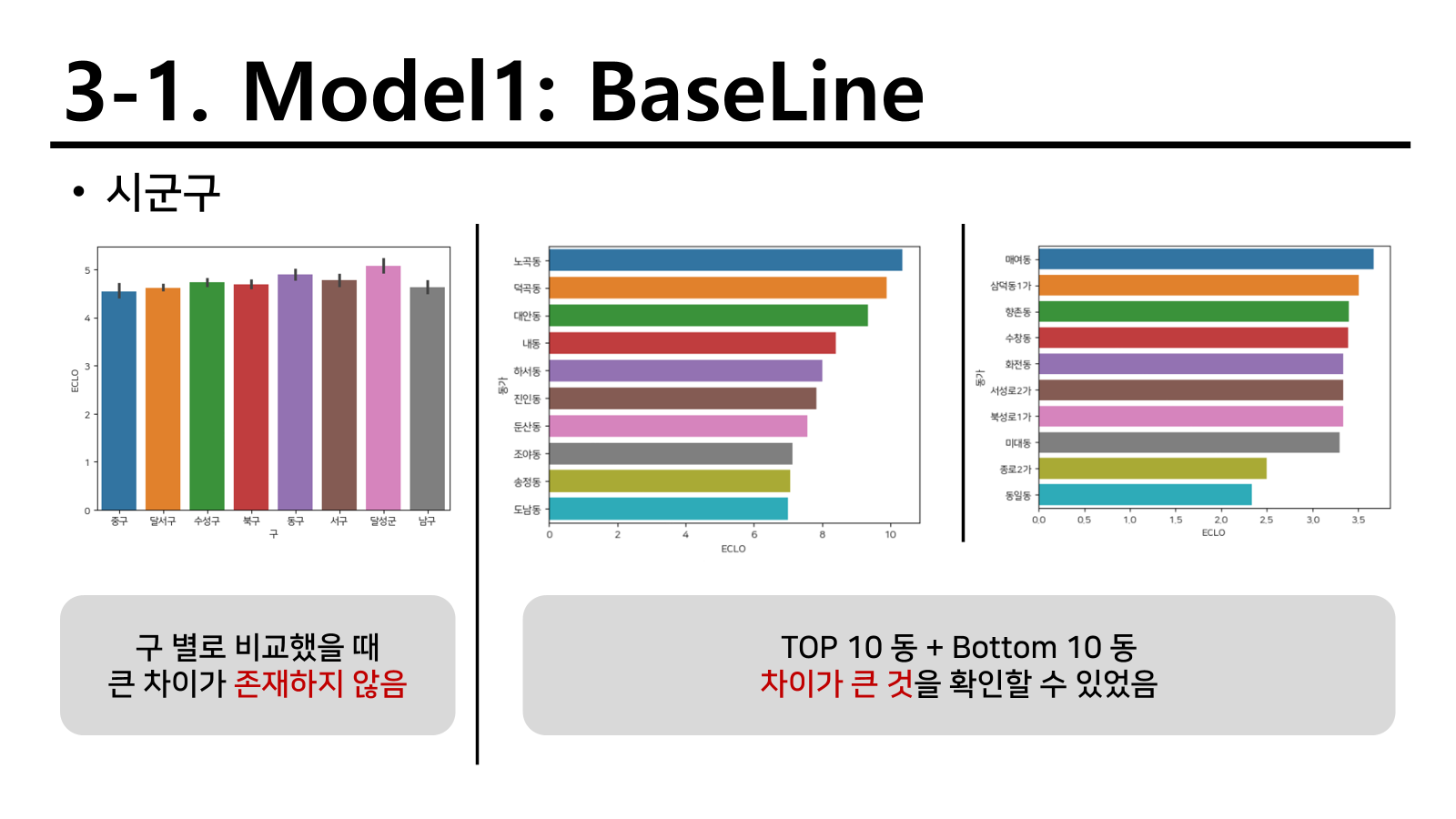
구 단위로 비교하였을 때 차이가 크게 없어보였고, 동 단위로 비교했을때는 오히려 차이가 존재했다. 세부적으로 ~~동 ~~1동과 같이 나뉘어져있는 행정동명도 있었지만 번호마다 다른 지역을 가리킬 수도 있어서 그대로 활용하기로 하였다.
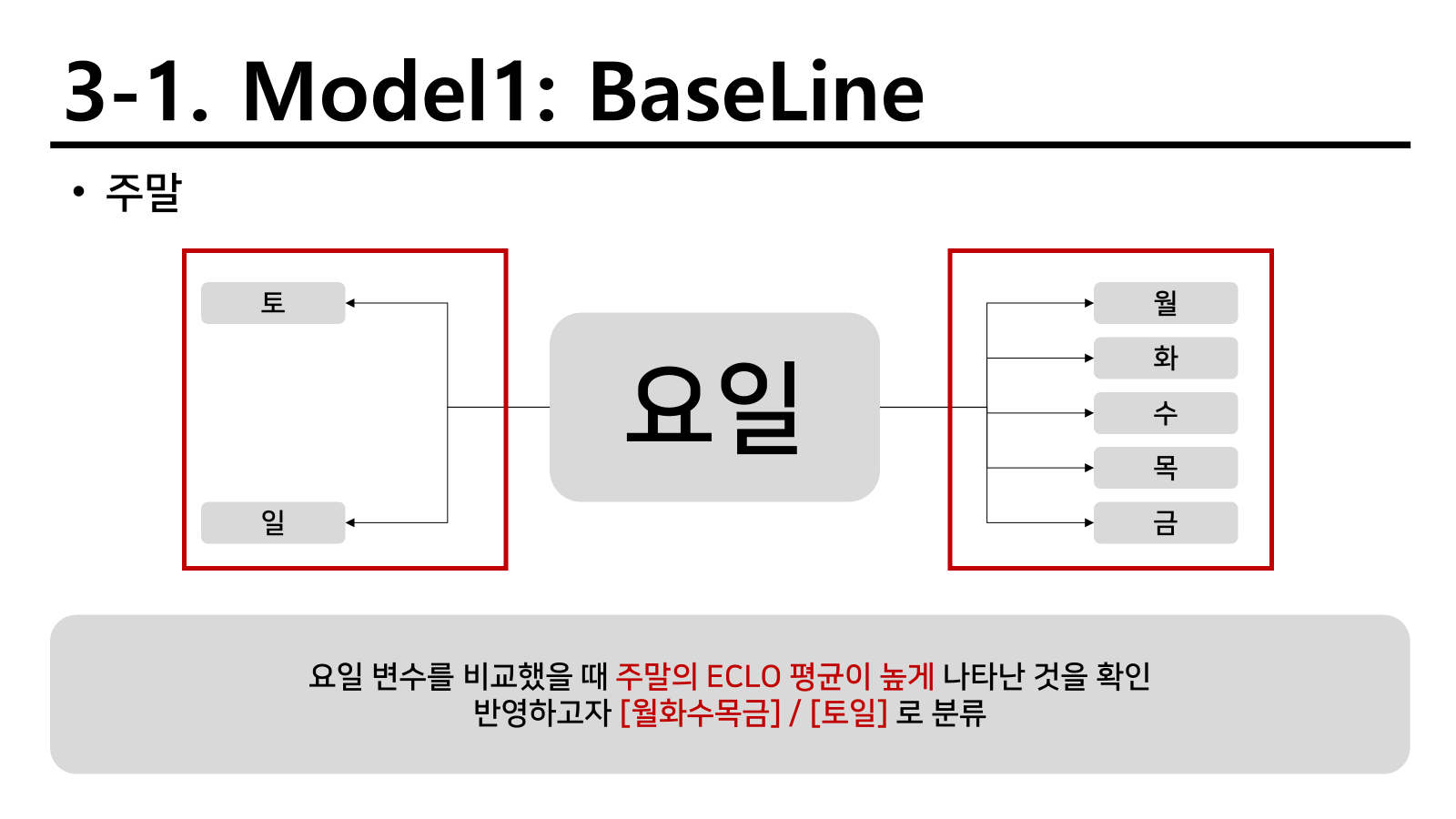
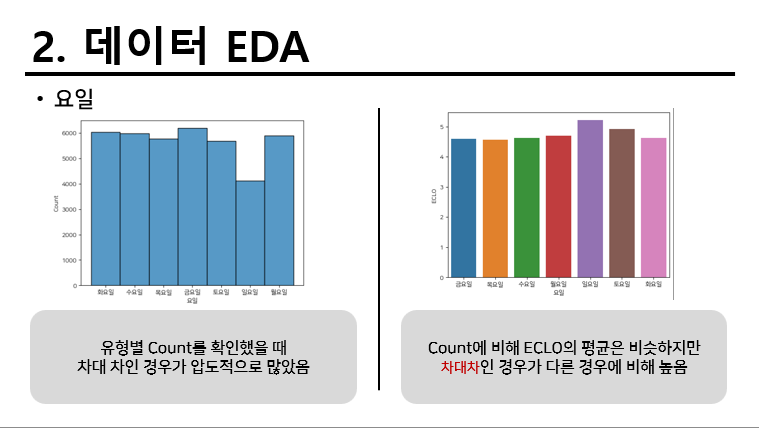
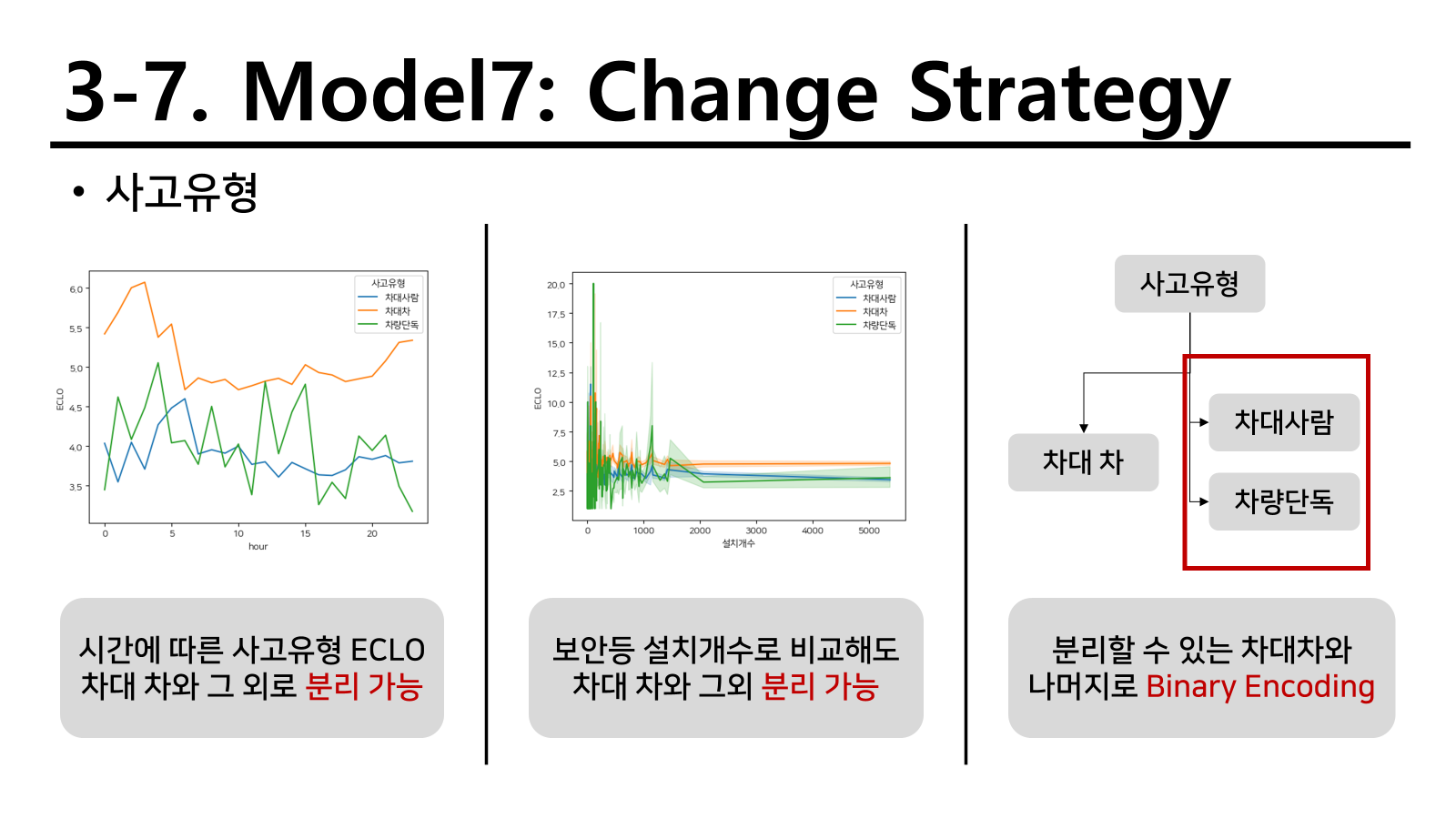
요일별로 확인하였을 때 주말에 해당하는 요일이 평일에 해당하는 요일보다 높게 나왔다. 따라서 평일과 주말로 비교해서 적용하기로 진행하였다.
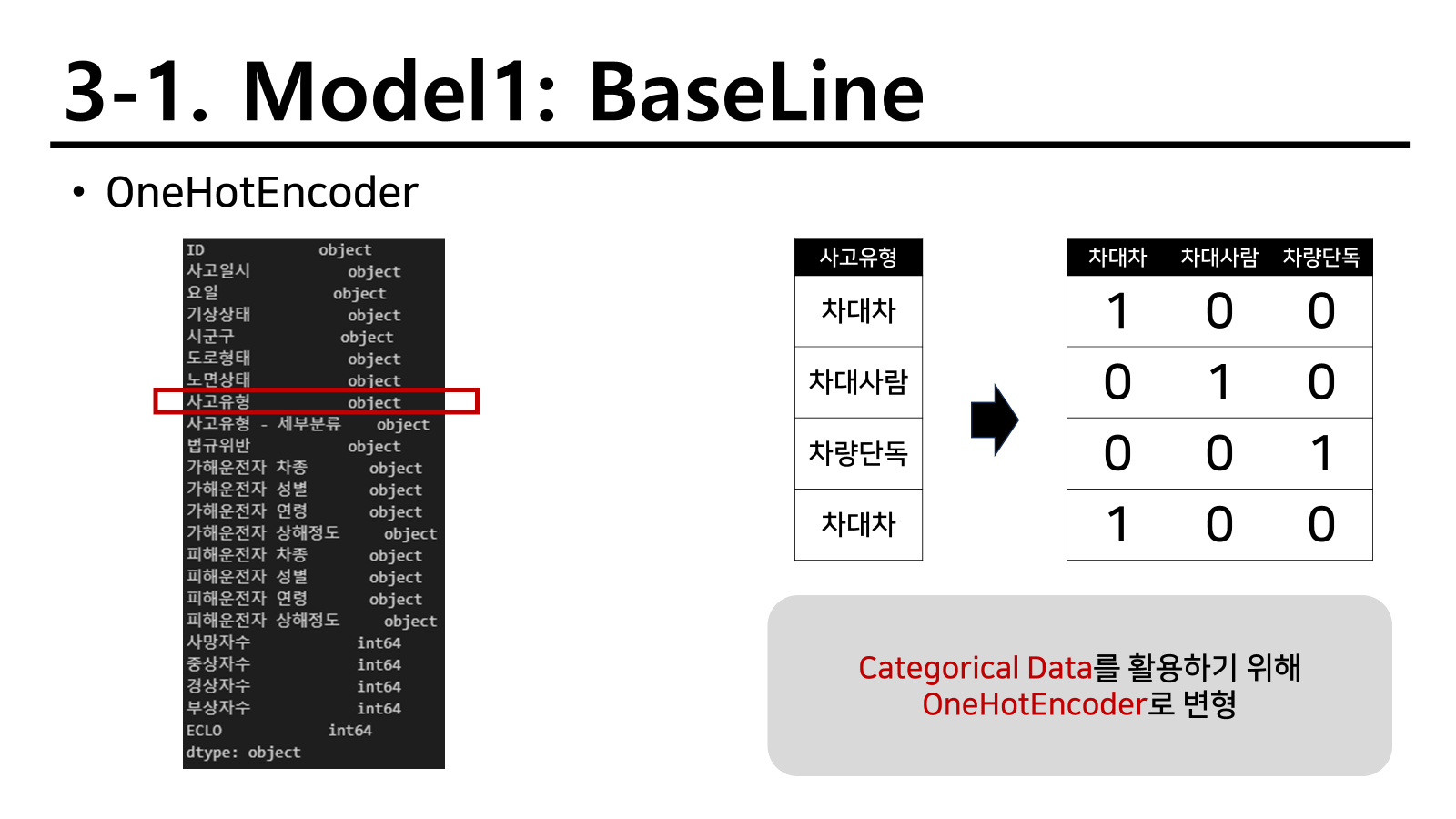
예시로 사고유형을 들었지만 다음과 같이 보이는 object변수형태로 되어 있는 것은 대부분 OnehotEncoder을 활용하였다. 여러 label보다 이 attribute를 해당하는지 하지 않는지를 구분짓는 변수 유형이 트리 모델과 오히려 잘맞았기 때문인것 같다. 앞으로의 전략에서도 이 전략을 생각보다 많이 진행한다.
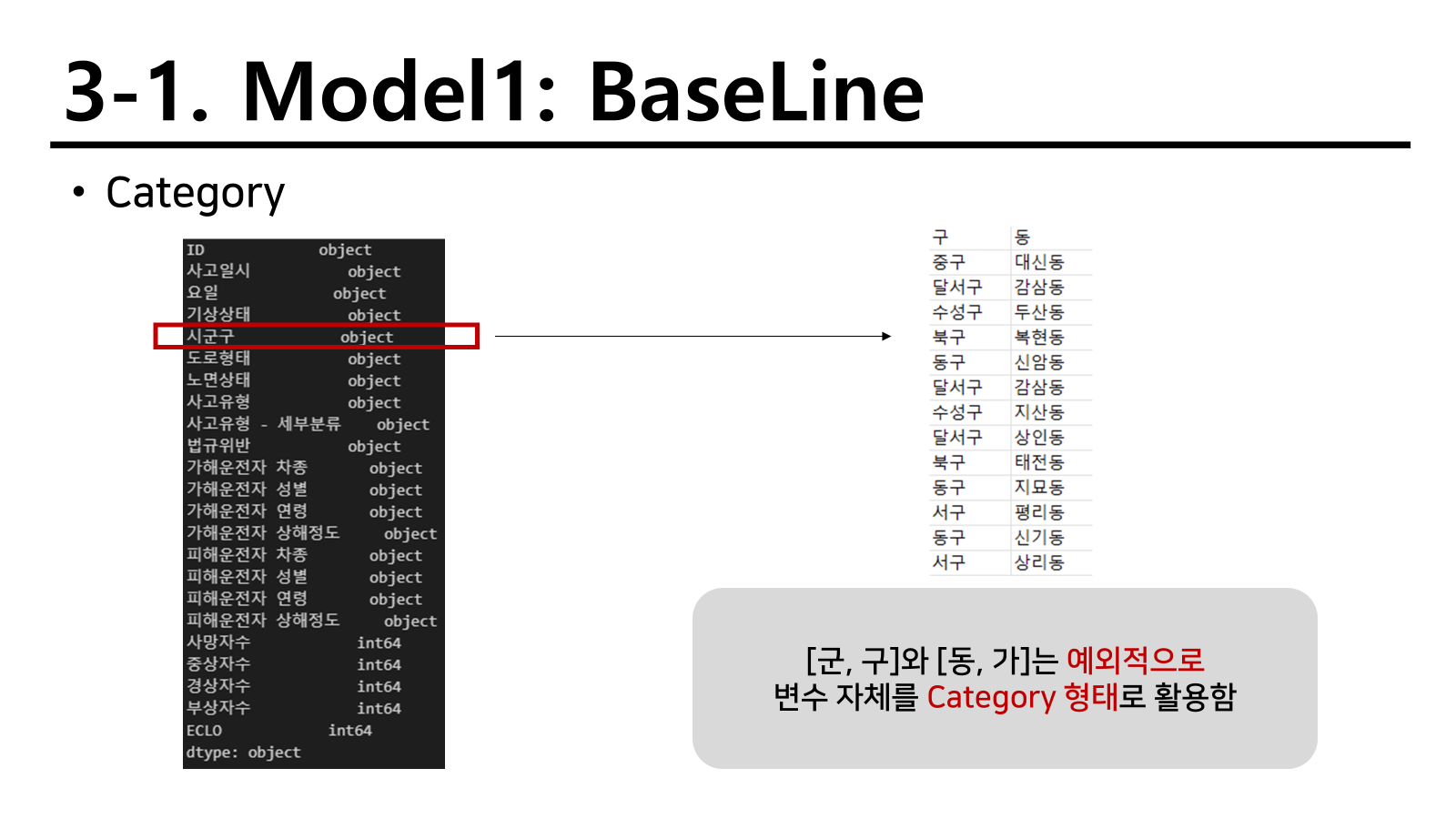
그러나 onehotencoder을 label이 많은데 사용하게 되면 너무 많은 columns가 생성되기 때문에 차원의 저주에 걸릴 수 있다. 따라서 이를 피하고자 변수 자체를 category로 활용하여 적합하기로 하였다.

기본 전략은 부스팅 방법인 XGB, LGBM, CB를 활용하기로 하였다. 이중 가장 성능이 좋은 모델의 결과를 가져오는 방식으로 진행하였고 기본적인 RMSLE값인 0.4679를 우리의 기본으로 진행하게 되었다.
분할 예측 방법
ECLO를 계산할 때 사망자수, 중상자수, 경상자수, 부상자수를 통하여 계산하기 때문에 다음과 같이 네 개의 영역을 따로 예측하고 직접 계산하는 방식을 적용했다. 총 4개의 모델을 통해 예측을 진행한다음 ECLO는 직접 계산한 방식이다. 결과는 다음과 같이 확인할 수 있다.
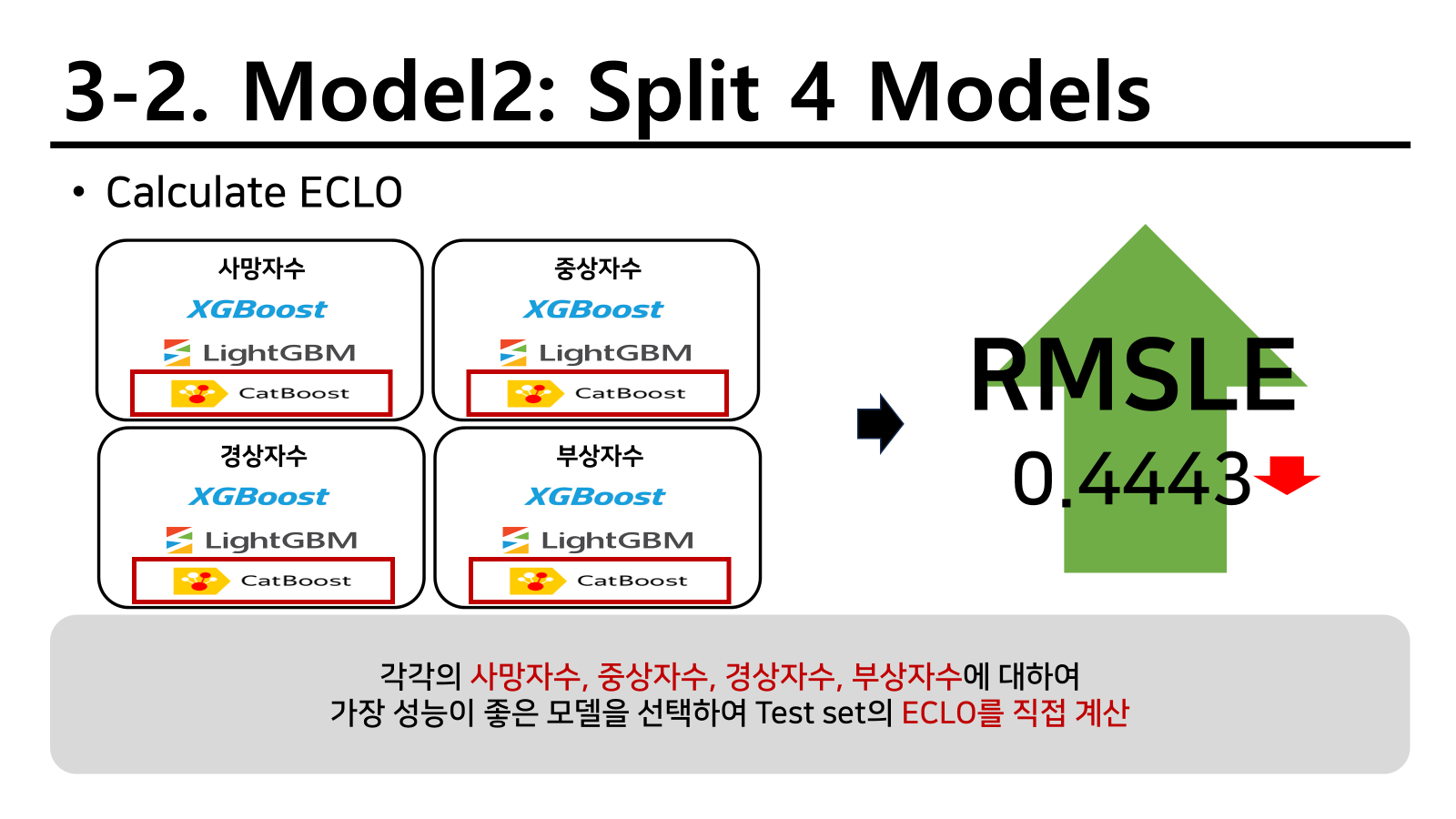
다행이도 성능은 올랐지만 비교하였을 때 큰 차이는 없었기 때문에 다른 방법을 찾도록 진행하였다.
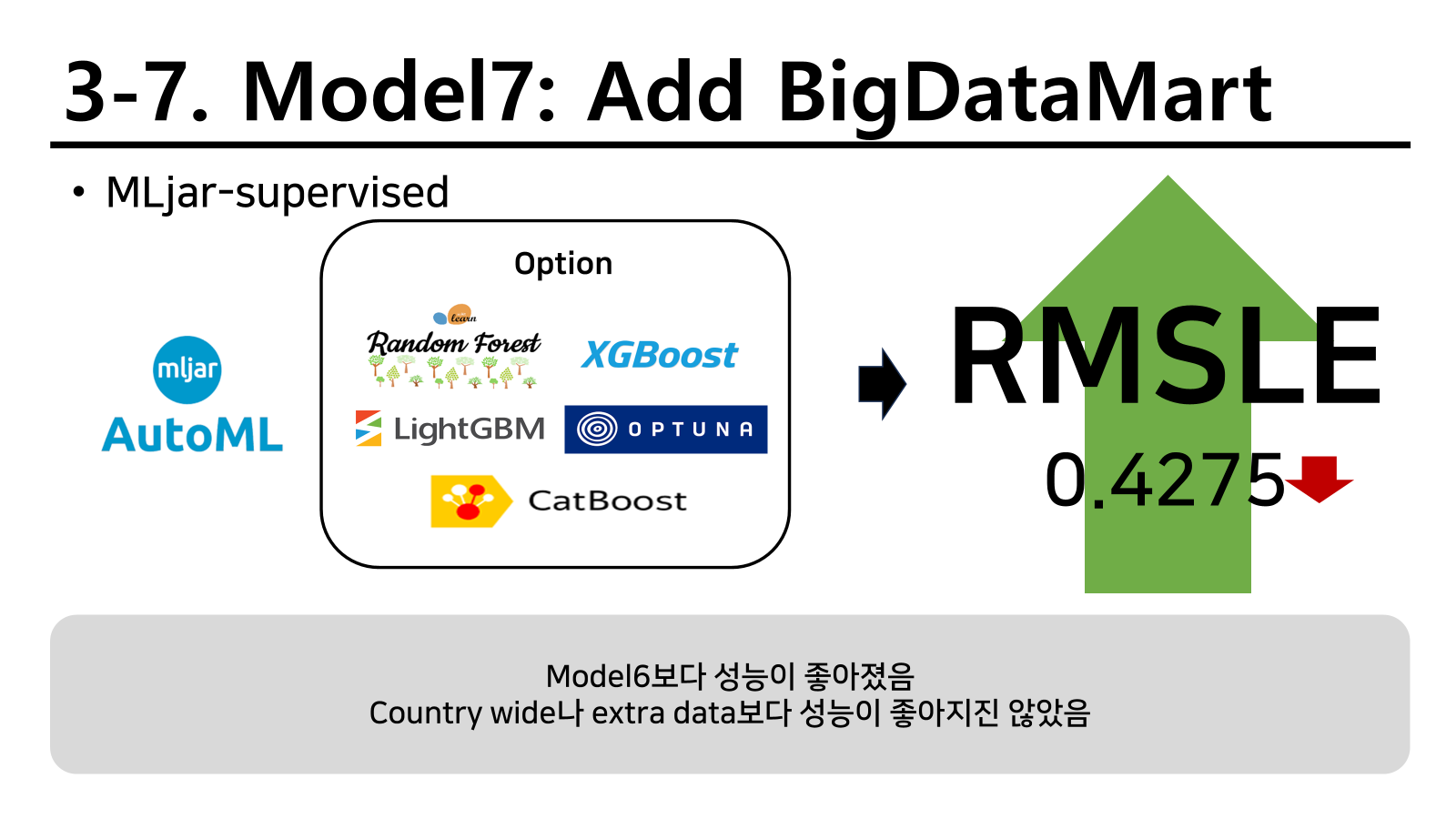
MLjar-supervised의 AutoML
다음 전략으로 파라미터 튜닝부터 새로운 피처까지 자동으로 합쳐주는 AutoMl을 활용하게 되었다. 다만 이것을 처음부터 활용하게 되면 머신러닝을 배우는 의미가 없어질 뿐 더러 나중에 따로 모델을 활용하게 되었을 때 아무것도 하지 못한다고 경고하고 진행하였다. 실제로 모든것을 자동으로 다 해주니 손수 해보는 기회를 잃는것이기 때문이다.
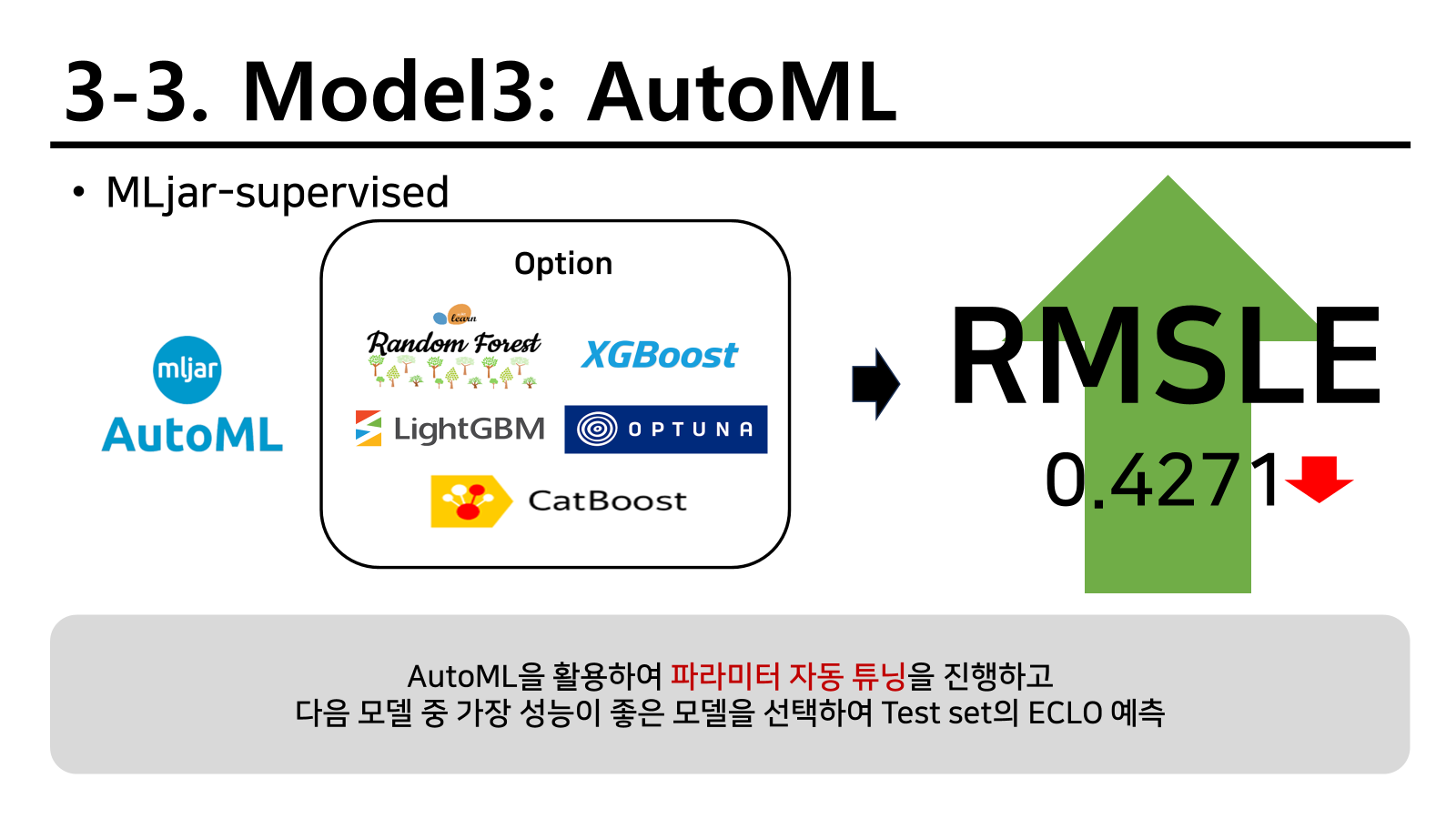
결과는 기존의 두 방법보다 성능이 훨씬 좋아졌다.
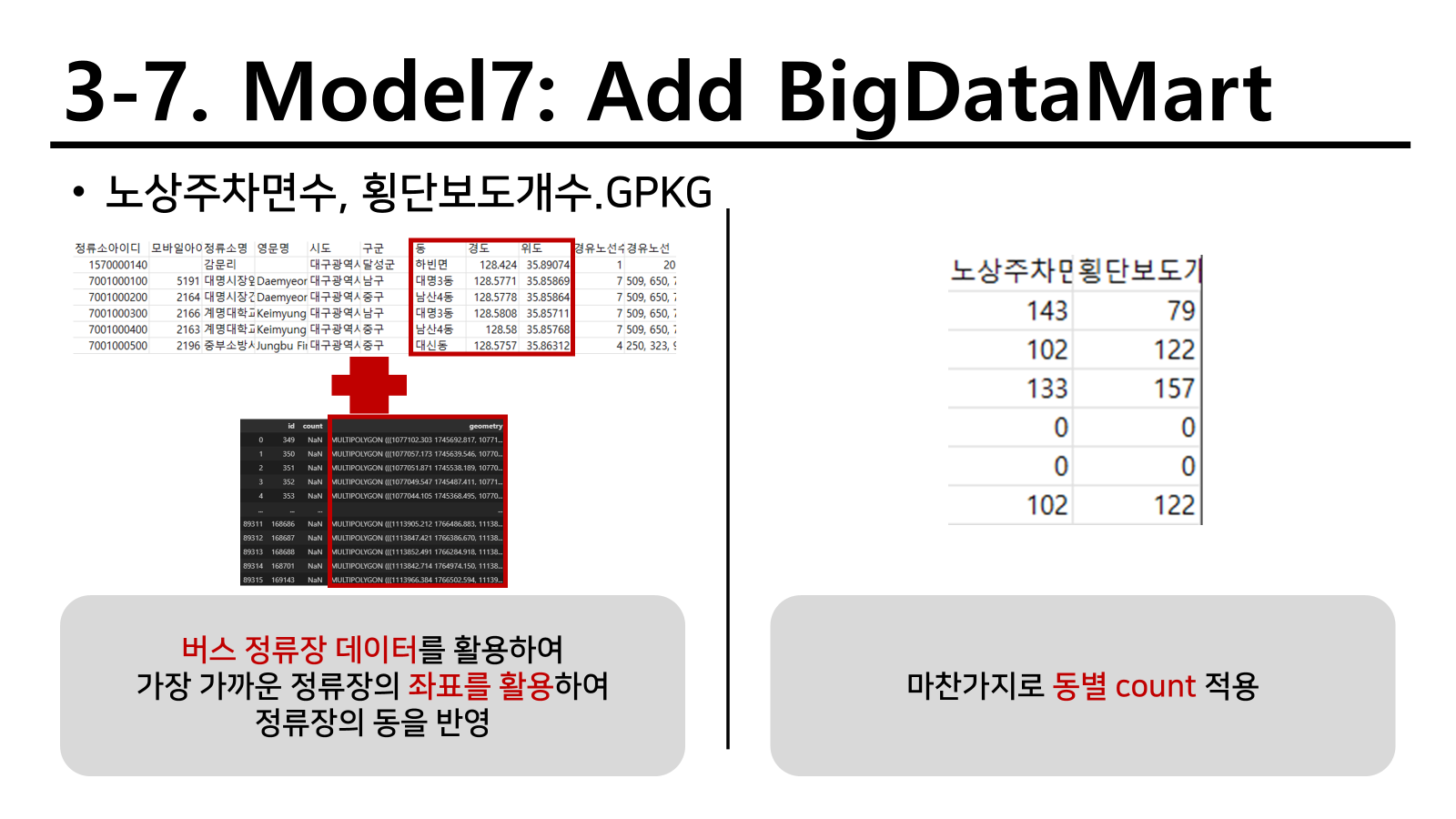
빅데이터마트 외부 데이터 적용
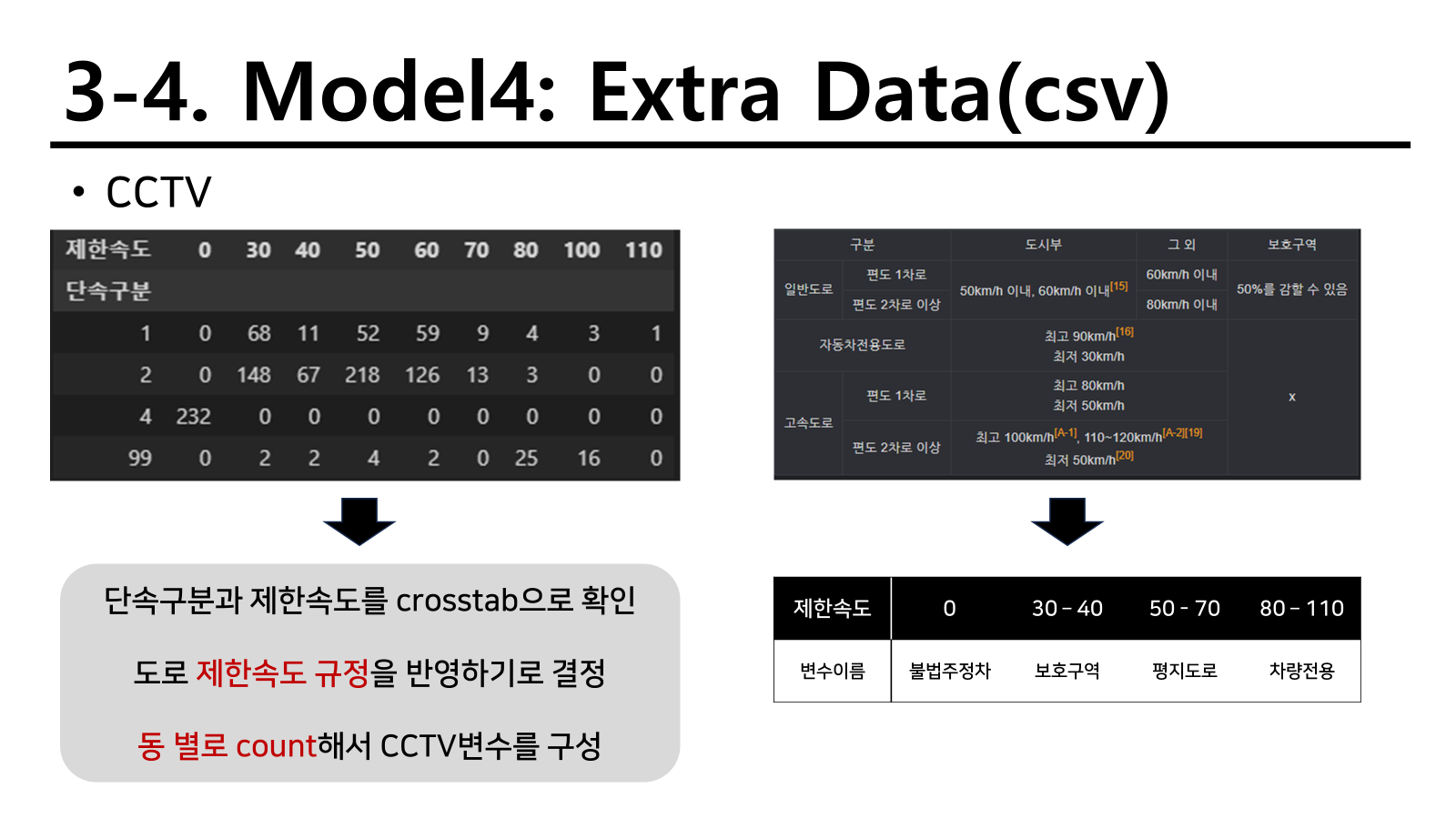
CCTV 제한속도와 유형은 차량의 통행 속도를 제한시키는 효과가 있을 것이기 때문에 도로에서 주행하는 차들의 속도와 연관이 있을 것이라는 아이디어를 통해 다음과 같이 변수를 생성하였다. 실제로 차의 추돌 사고와 같은 경우 일반 도로에서 60km/h로 추돌하는 것 보다 110km/h로 고속도로에서 추돌하는 것이 더 큰 사고를 야기할 수 있고 연쇄 추돌사고로 어마어마한 피해를 생성할 수 있기 때문이다.
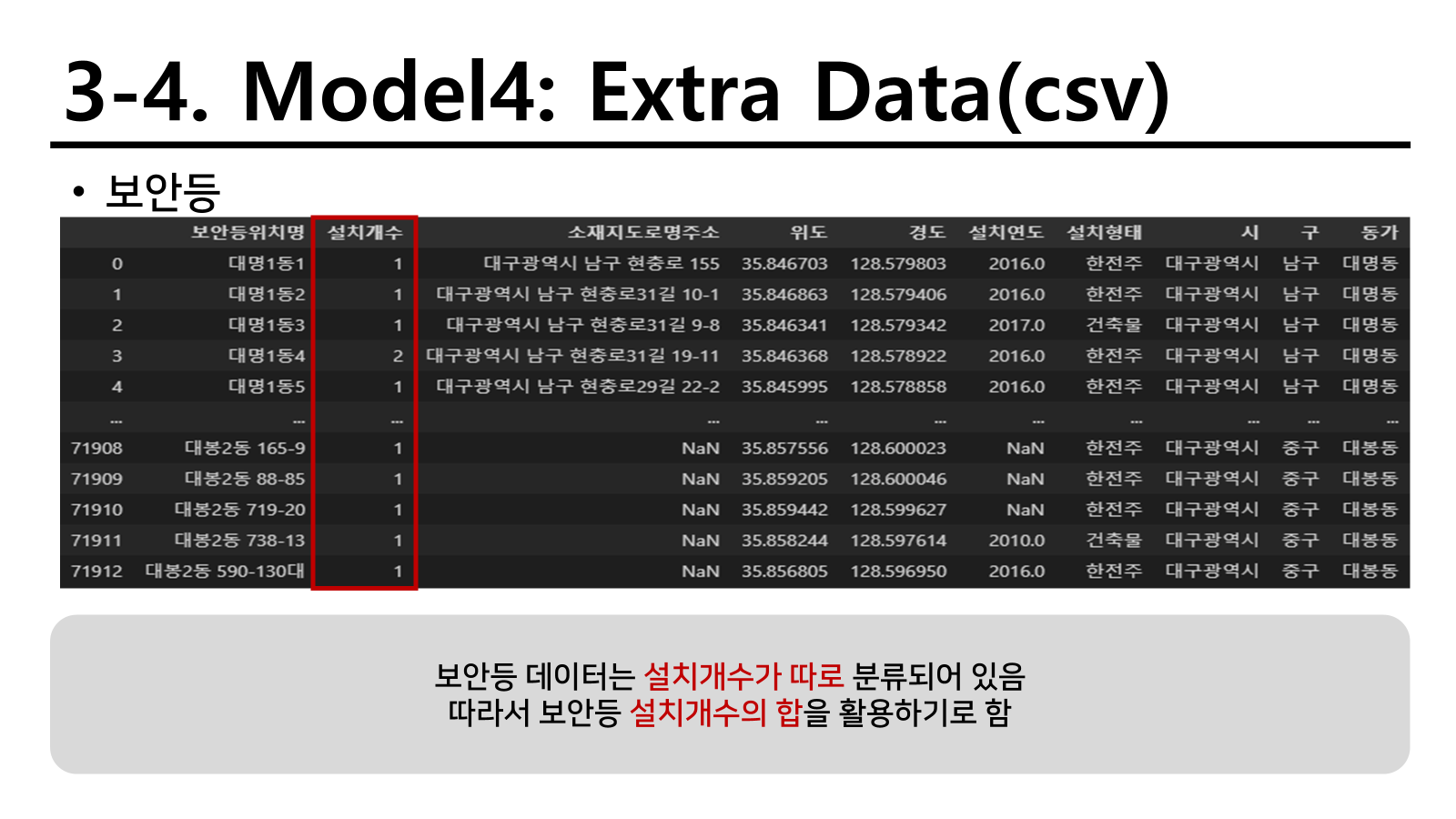
보안등은 자체 설치 개수가 있어서 단순 count보다는 설치개수를 동별로 sum하는 것이 더 바람직하다 판단하였다.
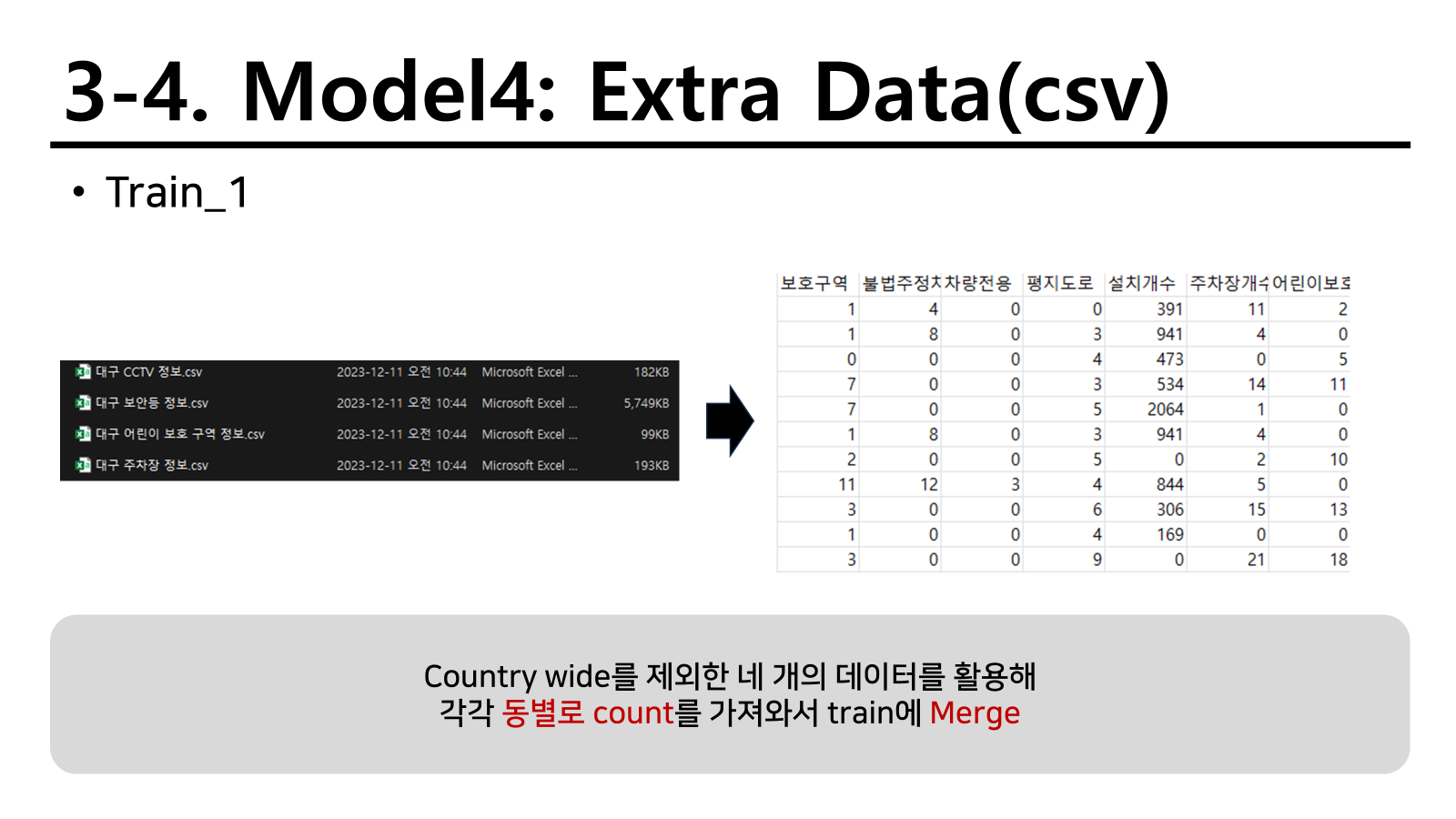
나머지 데이터 파일은 단순하게 count를 세서 전체적으로 동별 count를 붙여넣었다. 주요 전략으로 이를 활용하였고 다음과 같이 간단하게 변수를 변형하였다.
- [구, 군]을 묶어서 onehotencoding
- 월을 계절로 묶어서 변경
- 요일 안에 공휴일을 활용하여 주말 칼럼에 포함시킴
- 시간 변수를 푸리에 변환을 통해 cos_time변수로 활용
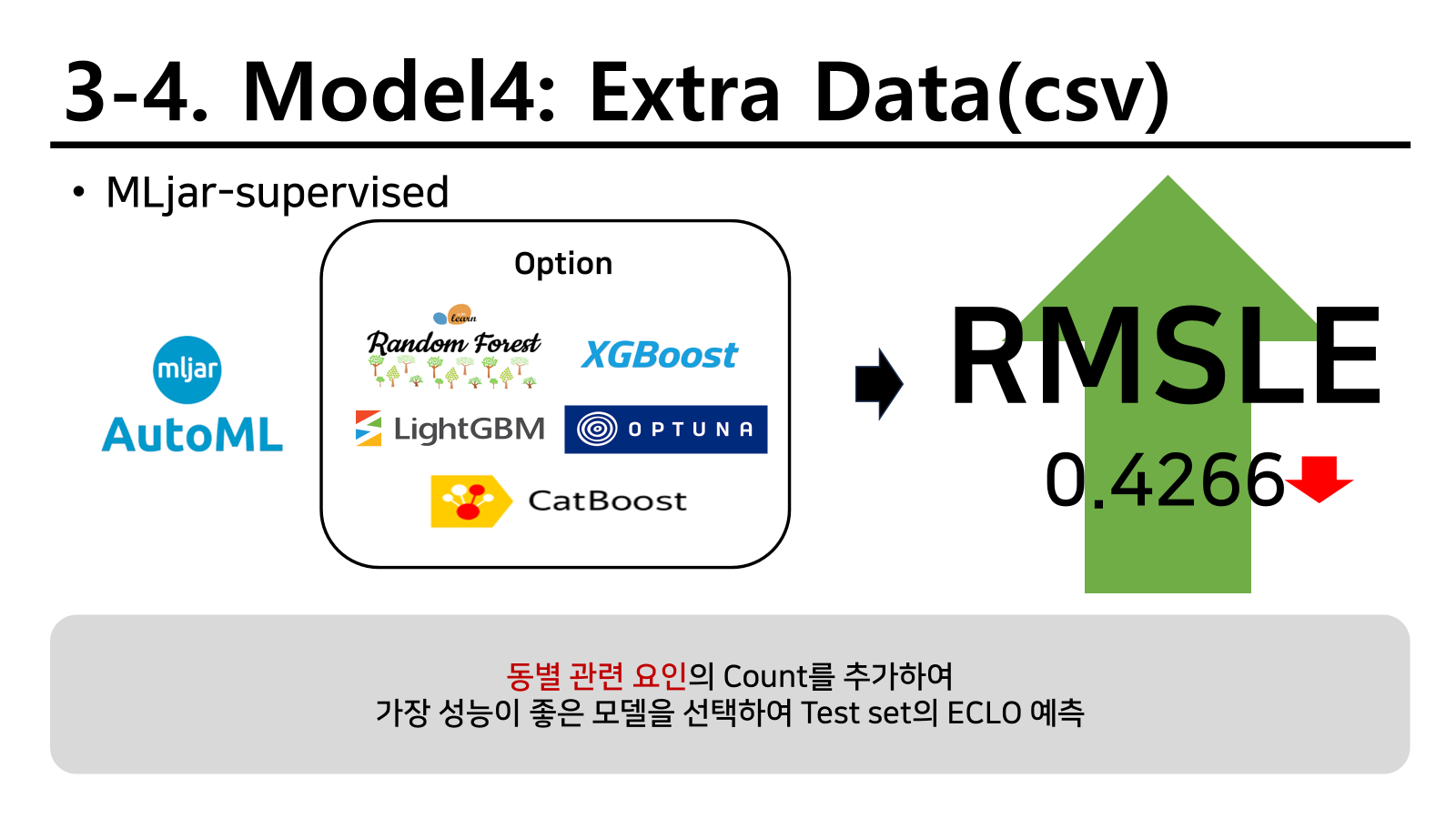
따라서 성능을 확인한 결과 0.4266으로 한층 더 상승 시킬 수 있었다.
country-wide
변수 중요도를 확인했을 때 사고 유형이 가장 크게 나타났다.
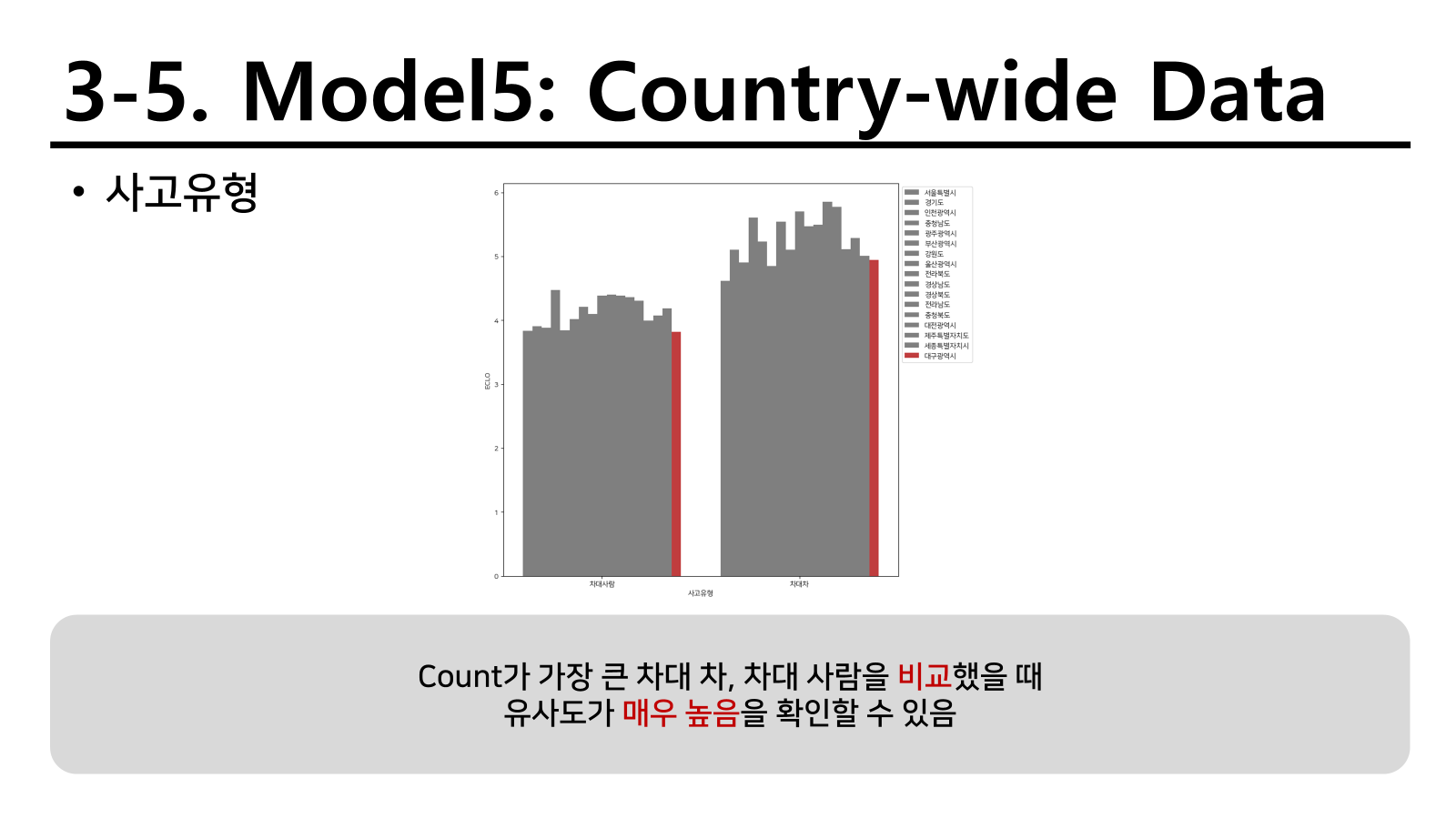
또한 이 그래프를 확인했을 때 사고유형의 유사성이 매우 높았기 때문에 대구 광역시 뿐만 아니라 대한민국에서 다양한 지역의 사고에 대한 내용을 별도 모델로 학습해 보기로 하였다.
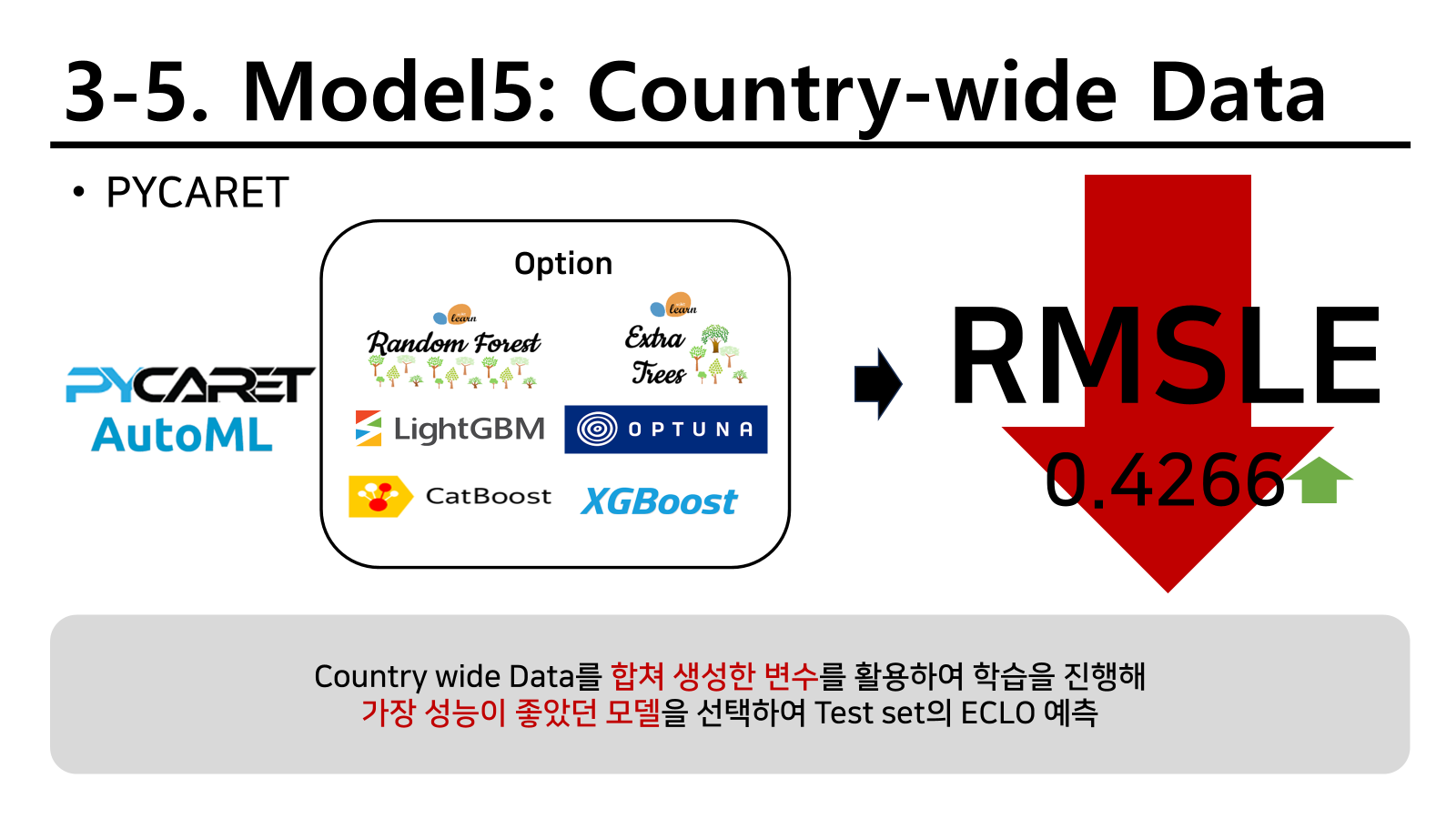
결과는 비슷한 결과를 가져왔지만 아래 소수점에서 기존에 빅데이터 마트에서 제공해준 데이터가 오히려 성능이 좋은 것을 확인할 수 있었다.
여기서 두 가지 데이터를 모두 붙일 수 있지 않냐고 생각할 수 있다. 하지만 기존에 가지고 있던 데이터는 모두 대구 광역시를 기준으로 존재하였고 country wide는 전국구로 존재하기 때문에 대구 정보만을 가지고 붙이는 것은 큰 오류를 범할 수 있기 때문에 이렇게 진행하지 않기로 하고 진행하였다.
변수 구성 변경
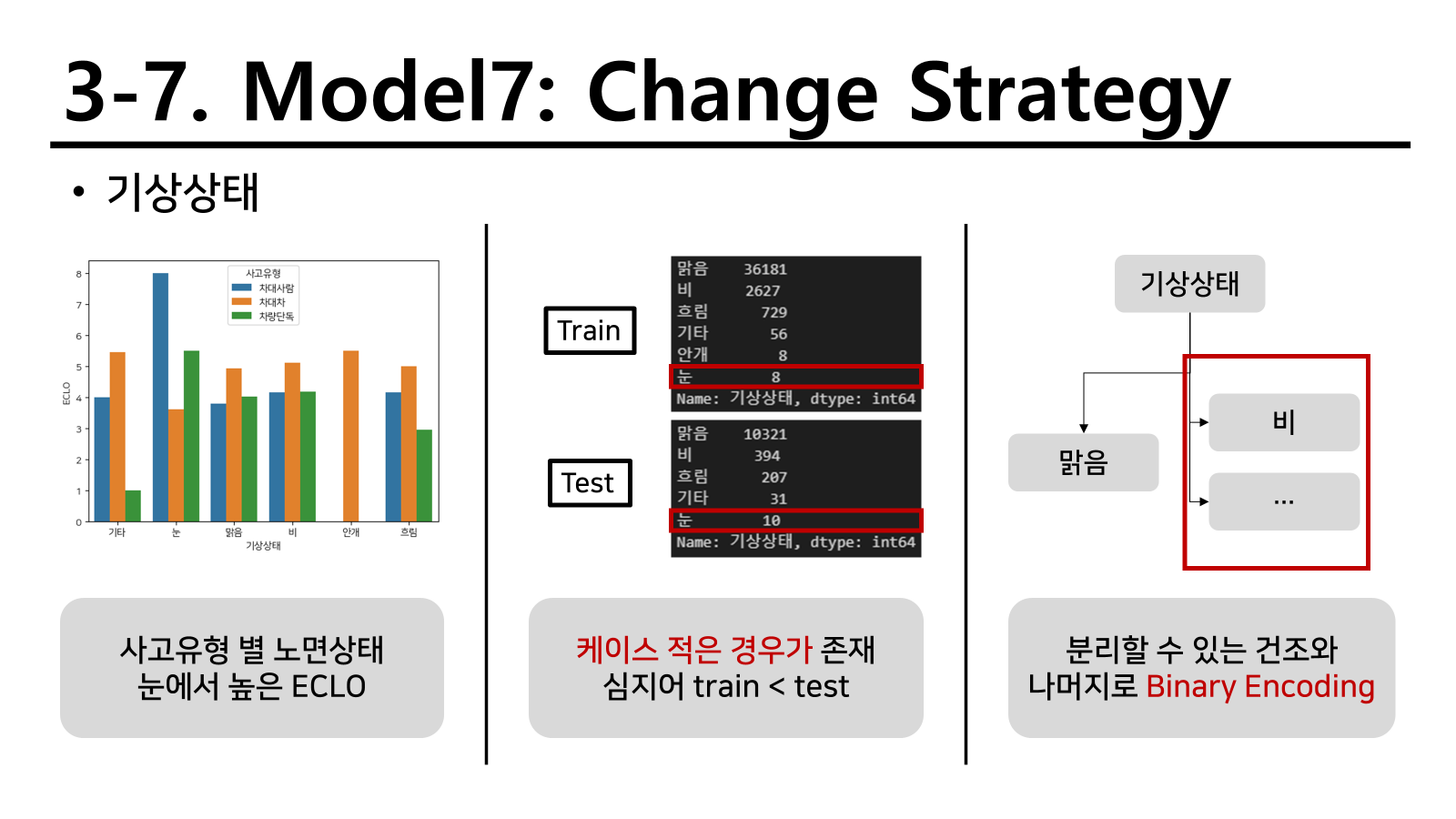
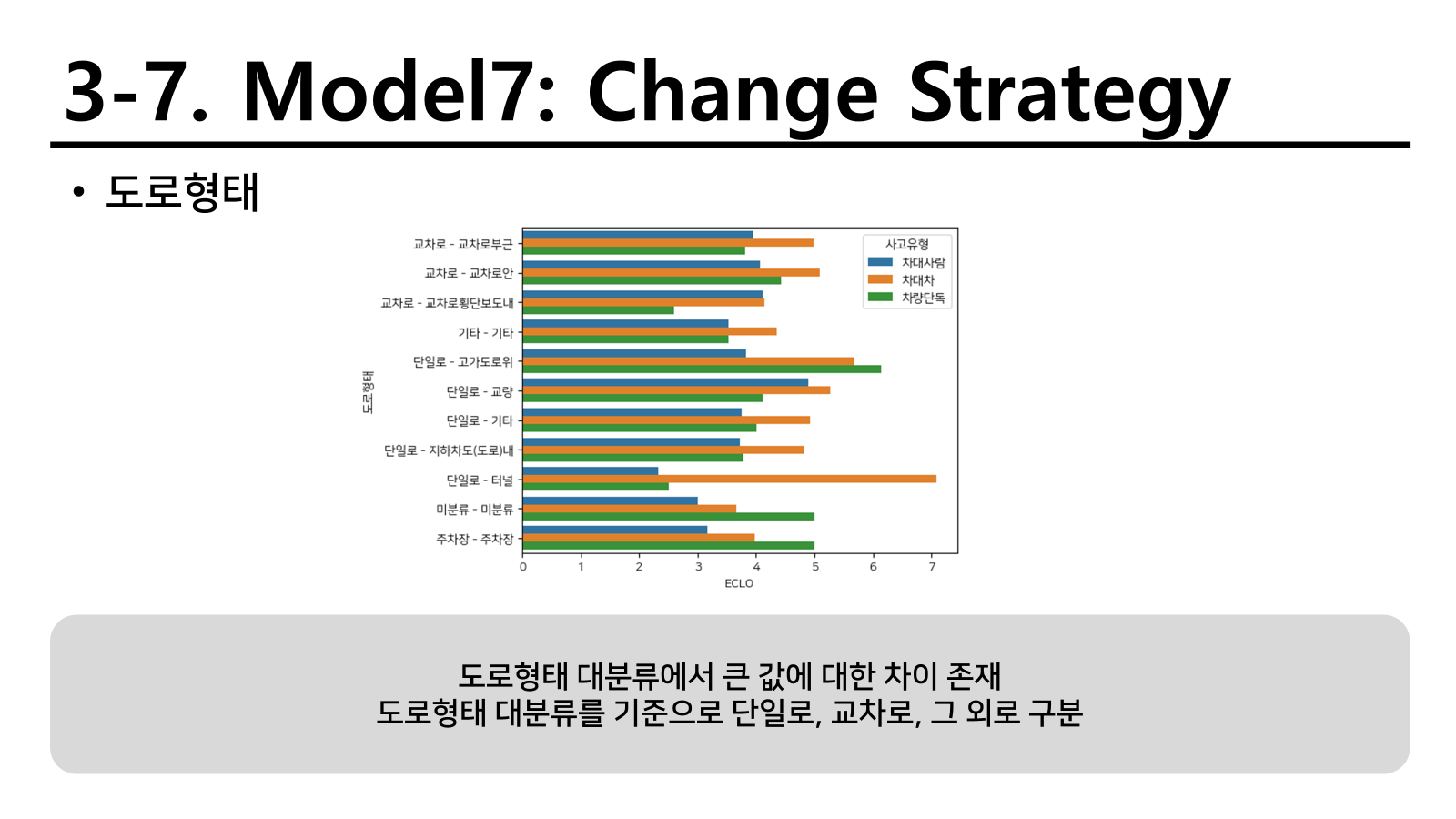
사고유형처럼 변수 형태를 변경하면 성능이 좋아질 수도 있는 모형이 있다 생각하여 일부 변수를 변경하였다.
다음과 같이 두 유형을 변경하거나 추가하였고 이를 통해 적합하면 다음과 같다.
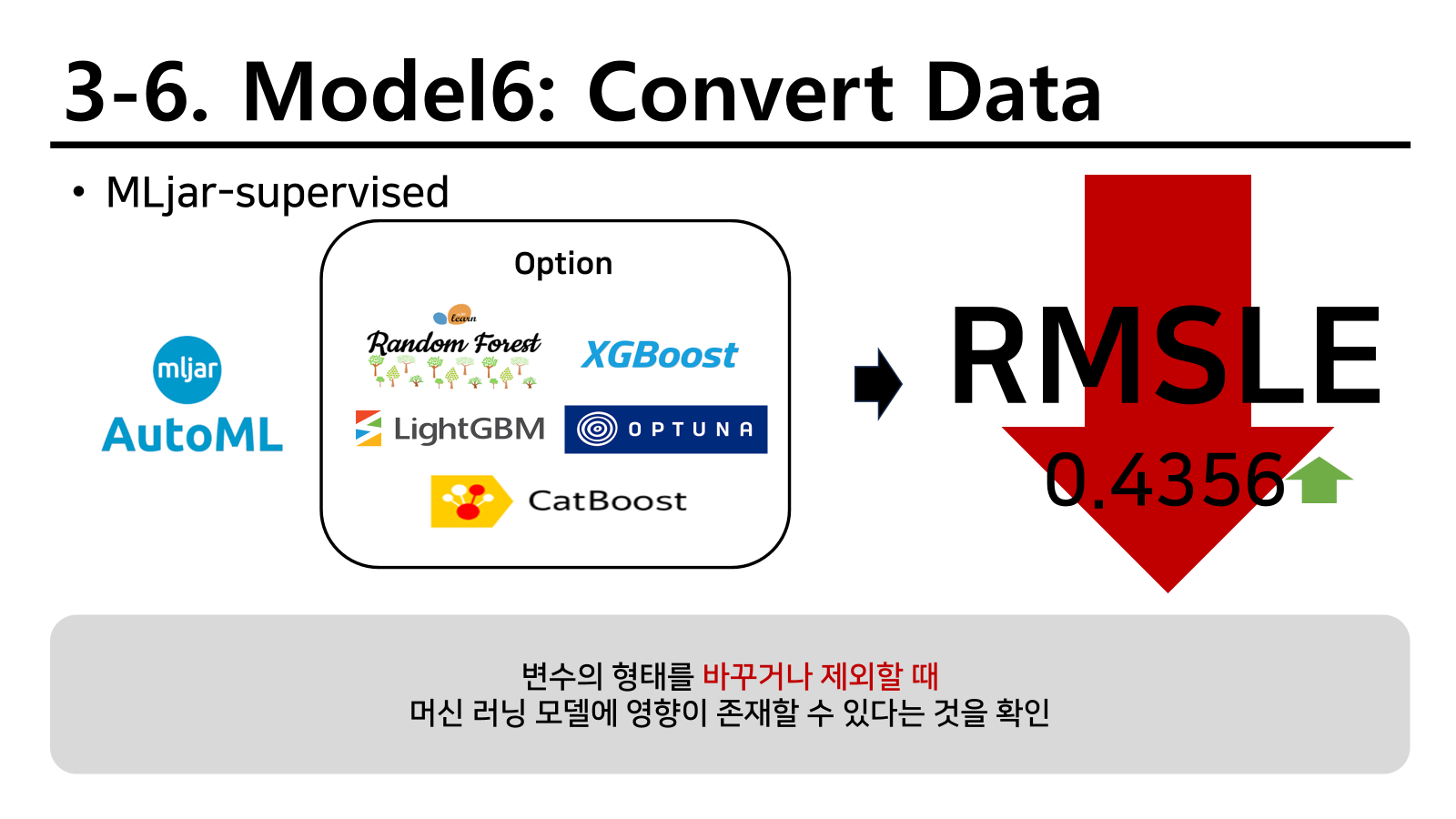
성능이 오히려 많이 저하된 것을 확인할 수 있었다. 이를 통해서 연관있는 변수를 다뤄야 성능이 올라간다는 것을 확인하였고 새로운 EDA를 진행하였다.
기존 변수의 대량 EDA와 GPKG 묶음 데이터
다음 아래와 같이 다양한 변수의 변형을 통해 적합을 진행하였으며 외부 데이터를 직접 불러와 적합에 활용하였다.


성능이 어느정도 개선된 것을 확인할 수 있었지만 최종적으로 가장 좋았던 모델보다 성능이 좋진 않았다.
반응변수의 log화
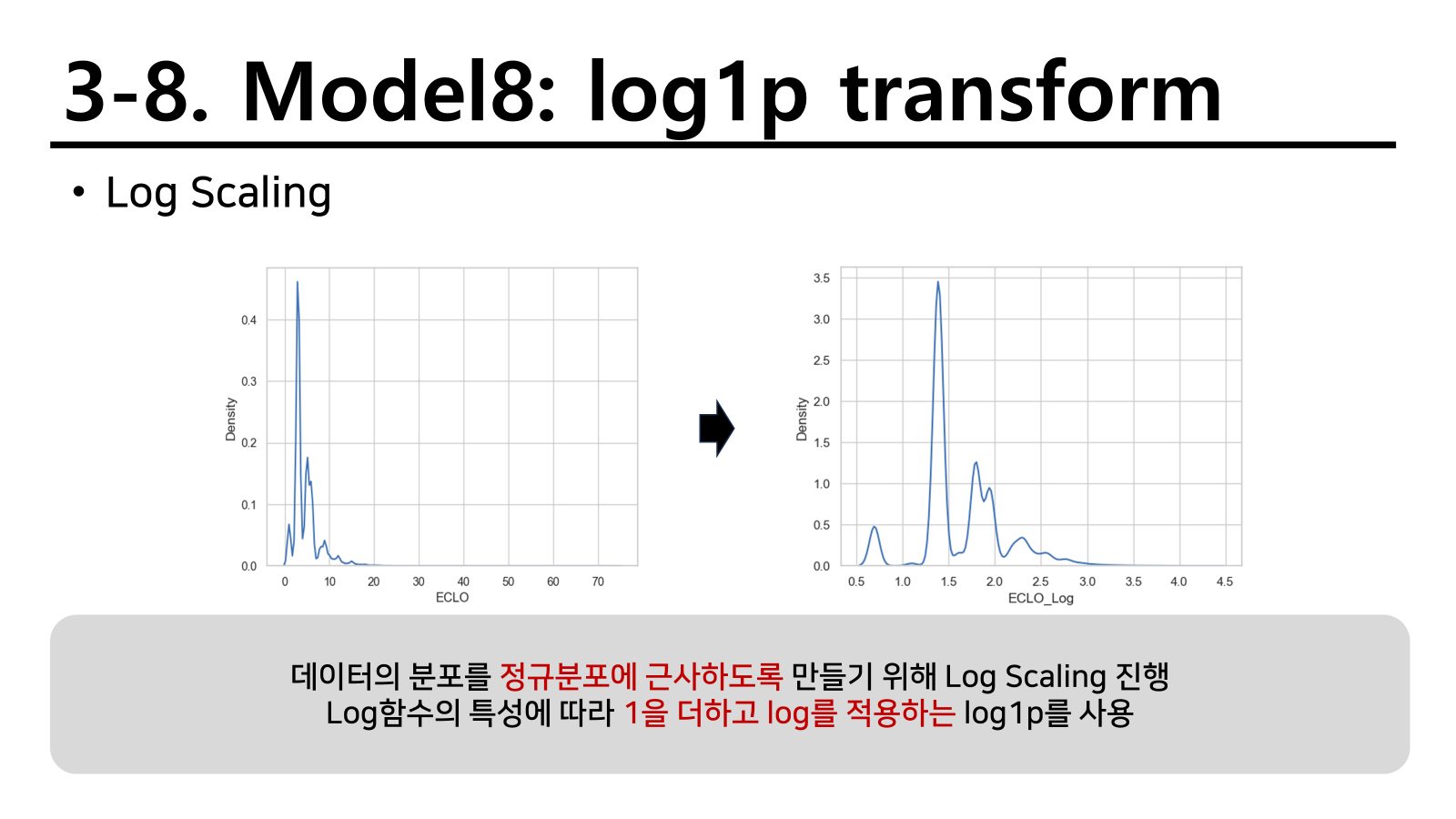
ECLO를 확인해보니 자연스럽게 3~5로 이루어진 케이스가 많았으며 10을 넘는 사고가 흔하지 않았다. 사망자나 중상자수가 크게 있는 사고가 많이 발생하지 않는다는 증거이기도 하다. 따라서 이를 log1p를 통해 3~5사이의 값의 간격을 늘리면서 자연스럽게 나뉠 수 있는 구간도 세분화 하는 방법을 활용하였다. 베스트 모델인 빅데이터마트 외부 데이터 적용모델을 활용하였더니
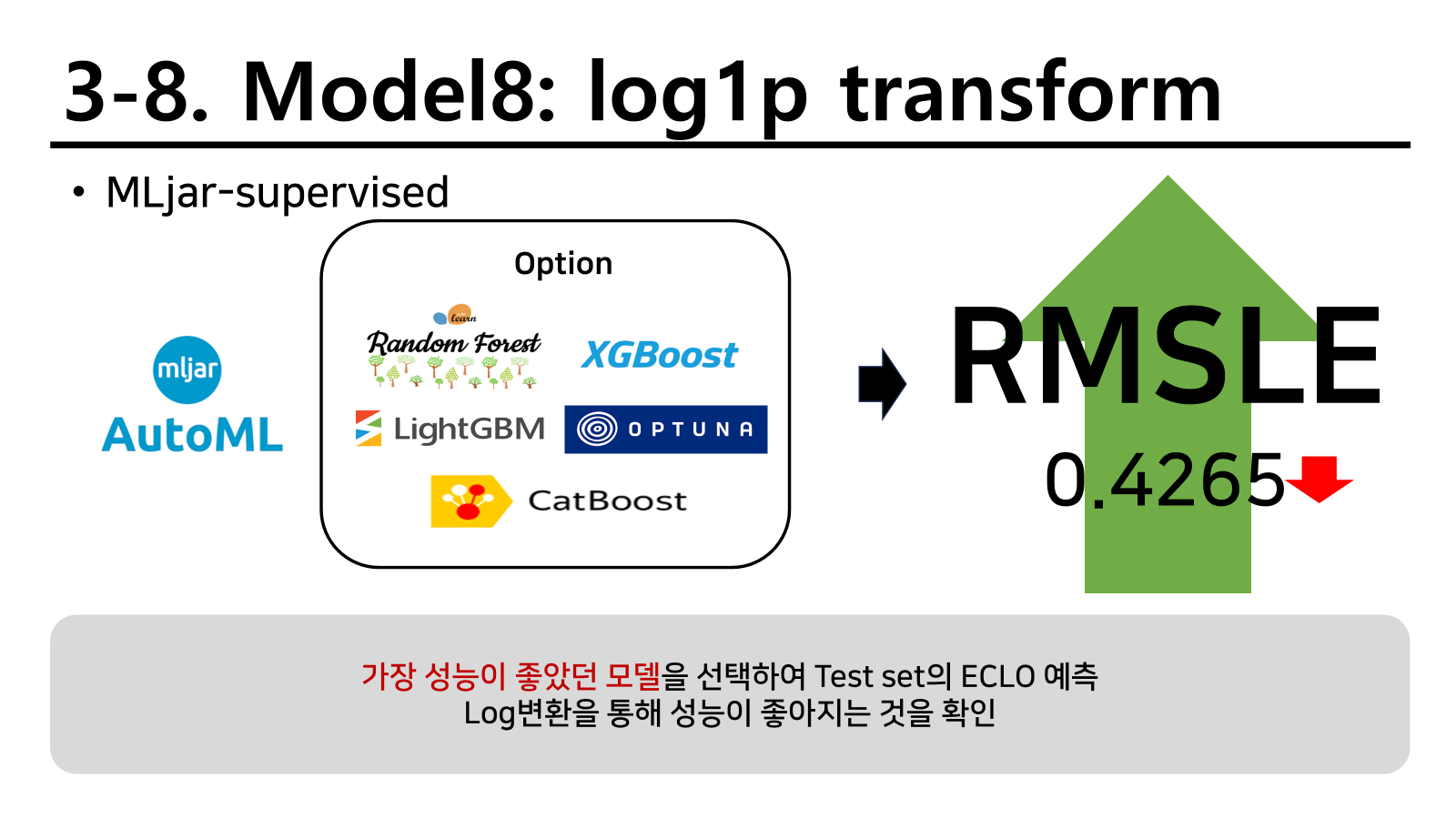
성능이 개선된 것을 확인할 수 있었다. 회귀로 적합해서 그런지 확실히 반응변수가 정규분포에 가까워져야 적합이 잘되는 것도 있는 것 같다.

마지막으로 log1p를 활용하지 않은 모델과 활용한 모델 두개를 통해 각 예측값의 평균을 내어 앙상블시켜 마지막 제출로 활용하였다. 결과는 다음과 같이 가장 좋은 성능을 내어 최종적으로 제출할 모델로 선정되었다.
결과
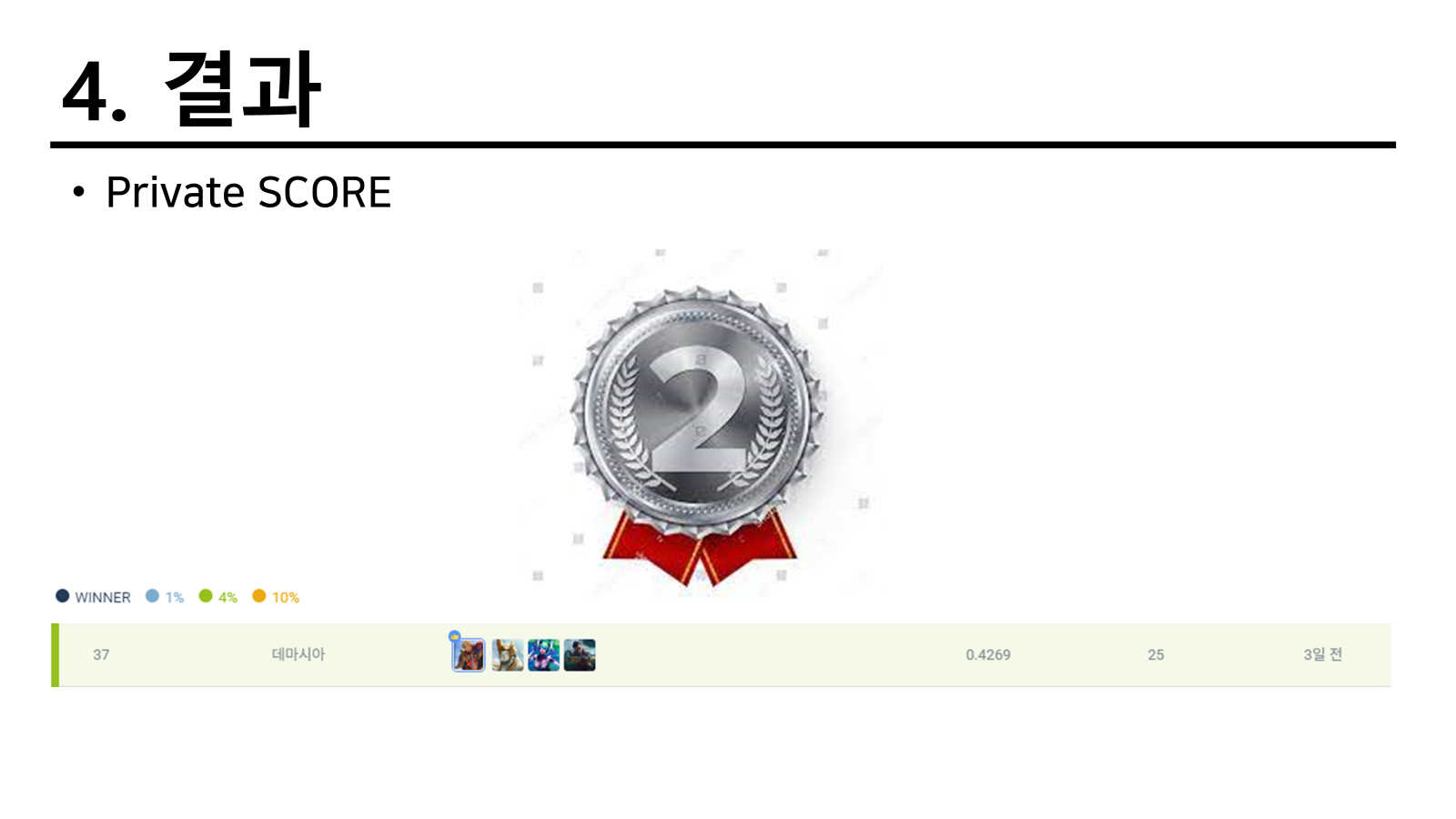
맨처음에는 최종적으로 38등이라 4%조금 넘는 순위를 가졌지만 한 팀이 부정평가를 받으면서 탈락하게 되고 우리 팀이 4%에 속하게 되는 좋은 결과를 가져올 수 있었다.
고찰
최종적으로 4%안에 들 수 있어서 너무 만족스러웠지만 시간이 길었다면 다양한 방법을 더 시도해서 성적을 더 높게 받지 않았을까 하는 아쉬움도 있다. 최종적으로 결론을 가져온 팀의 모델 구현방식이나 변수 생성 방식을 보면 우리의 흐름에서 한 두 스텝 나아간 경우를 확인할 수 있었다. 특히 도로마다 차량의 평균 속도를 생각하여 추가하고 싶었지만 적절한 데이터를 찾지 못했는데 2등 팀에서는 택시를 활용하여 평균 속도를 대입하였다. 정말 아쉬울 따름이었다.
또한 처음으로 우리 팀이 오프라인으로 모였던 날이다.

이렇게 다들 각자의 역할과 프로젝트를 기간상 나눠서 작업해야할 때도 있었고 한 프로젝트 내에서 다양한 상의를 할 필요도 있었기 때문에 다음과 같이 진행하였다. 우리의 팀장님의 머리색이 정말 독특하더라. 그런데 머리색과 다르게 정말 곱고 여린 마음씨를 가지고 있다. 근데 일할때는 어떻게 이렇게 잘 혼내는지 너무 신기하더라. 이건 또 안 비밀인데 동혁은 이번에 하면서 또혼났다. 이번엔 상혁한테 혼났는데 내 학부때랑 비교하면 왜 혼나는지 알것 같기도 하다. 호호호 본인은 괜찮다 하지만 분명 안괜찮을 것이다. 그래도 극복하고 의미있게 가져가면 분명 크게 될 사람이다. 아이디어가 굉장히 많다. 사실 이틀동안 거의 이러고 있었는데 하루는 이 멤버랑 다른 조원이랑 친해져서 보드게임도 하러가고 밥도 같이 먹었다. 첫째날에는 강사님과 함께 점심 식사도 하고 카페도 두번 다녀오면서 많은 이야기를 나눴다. 진짜 너무 의미 있고 원하는 정보를 얻을 수 있어서 오프라인 모임도 종종 가져볼 생각도 가져봐야 하게 된 계기가 되었다.
이렇게 같이 밤도 새면서 대학원이나 학부때 같이 진행했던 프로젝트가 생각났지만 완성하고 나니 어느덧 괜찮은 기반도 잡을 수 있었고 다들 머신러닝에 대해 어떻게 흘러가는지 다시한번 깨닫고 앞으로 계속 진행할 수 있게된 계기를 맞이한것 같았다.
프로젝트 내용: github
