
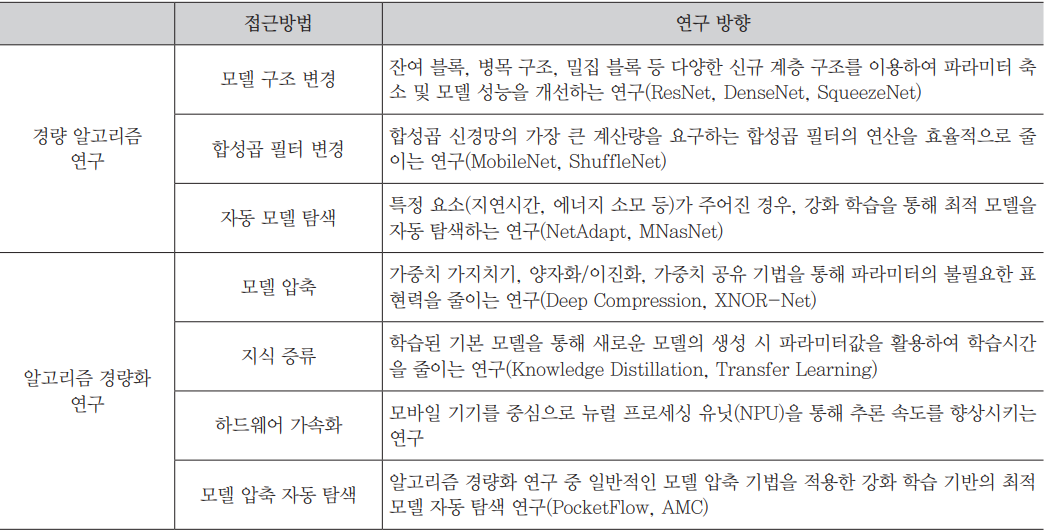
서론
경량 딥러닝 기술
- 알고리즘 자체를 적은 연산과 효율적인 구조로 설계하여, 기존 모델 대비 효율을 극대화하기 위한 경량 딥러닝 알고리즘 연구
- 만들어진 모델의 파라미터들을 줄이는 모델 압축(Model Compression)
경량 딥러닝 알고리즘
- CNN(Convolutional Neural Network) 계열 모델에서 학습 시 가장 큰 연산량을 요구하는 합성곱 연산을 줄이기 위한 효율적인 합성곱 필터 기술
- 연산량과 파라미터 수를 줄이기 위한 잔여 블록(Residual Block) 또는 병목 블록(Bottleneck Block)과 같은 형태를 반복적으로 쌍아 신경망을 구성
- 인간에게 의존적으로 수행하지 않고 모델 구조를 자동으로 탐색함으로 모델을 자동화하거나 연산량 대비 모델 압축 비율을 조정하는 등 자동 탐색 기술
모델 압축
- 모델이 가지는 가중치의 실제값이 아주 작을 경우 값을 모두 0으로 설정하여 가중치 가지치기(Weight Prunning)
- 일반적인 모델의 가중치는 부동 소수점을 가지지만, 특정 비트 수로 줄이는 양자화(quantization)
- 0과 1로 표현하여 표현력을 줄이지만, 정확도의 손실은 어느 정도 유지하면서 모델 저장 크기를 확연히 줄이는 이진화(Binarization)
경량 딥러닝 알고리즘
1. 신경망 구성
- 합성곱 신경망은 알렉스넷(AlexNet) ZF-Net VGGNet을 거치면서 점차 필터의 크기가 줄어들어 1X1 필터를 주로 이용
- 단일 필터를 사용하는 구조에서 벗어나 다른 필터를 병렬로 연결하는 인셉션(Inception) 모듈을 통해 발전했다.
- 인셉션이 2개의 연속적인 합성곱 층에 단위행렬을 추가하는 지름길(shortcut)을 더해 줌으로 가중치들이 잔여 블록 병 목 구조 밀집 블록으로 발전되는 중이다.
A. ResNet
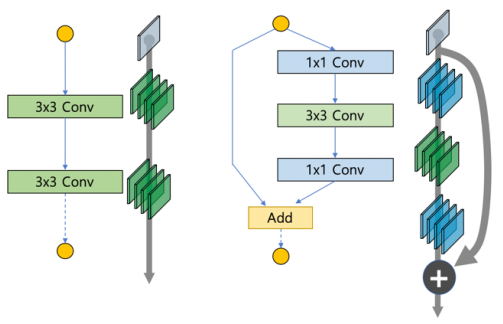
- 네트워크의 깊이를 늘리다 보니 성능이 떨어지는 Degradation Problem 발생 사람들은 Optimization 문제라고 추측
- 기존의 PlainNet의 수식 를 로 바꿔서 이라는 목표를 가지기 때문에 학습이 더 쉬워진 다.
- 에서 를 사용하기 위해서 Skip Connection을 사용한다.
- Residual Block을 사용하면 Gradient Vanishing 문제를 해결할 수 있다.
- Bottleneck 구조에서는 layer가 하나 더 생겼지만 1X1 Convolution layer 2개를 사용하기 때문에 파라미터 수가 감소해 연산량 이 줄어든다.
- 결론적으로 ResNet은 Skip Connection을 이용한 Shortcut과 Bottleneck 구조를 이용해 더 깊게 층을 쌓을 수 있다.
B. DenseNet
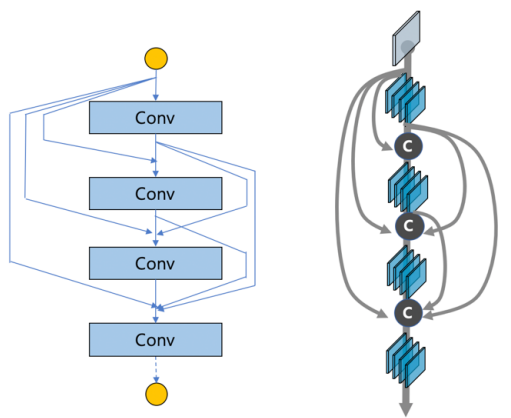
- ResNet의 Convolution layer가 너무 많이 쌓이면 layer 간 의미있는 논리를 전개하지 못하는 단점을 보완하기 위해 나온 모델
- 모든 layer의 피처맵(Feature Map)을 연결한다.
- 덧셈이 아닌 연결(Concatenate)를 사용 피쳐맵 크기 동일해야 한다.
- 연결 덩어리를 Dense Block으로 만든다.
- Vanishing Gradient 개선
- Feature Propagation 강화
- Feature Reuse
- Parameter 수 절약
C. SqueezeNet
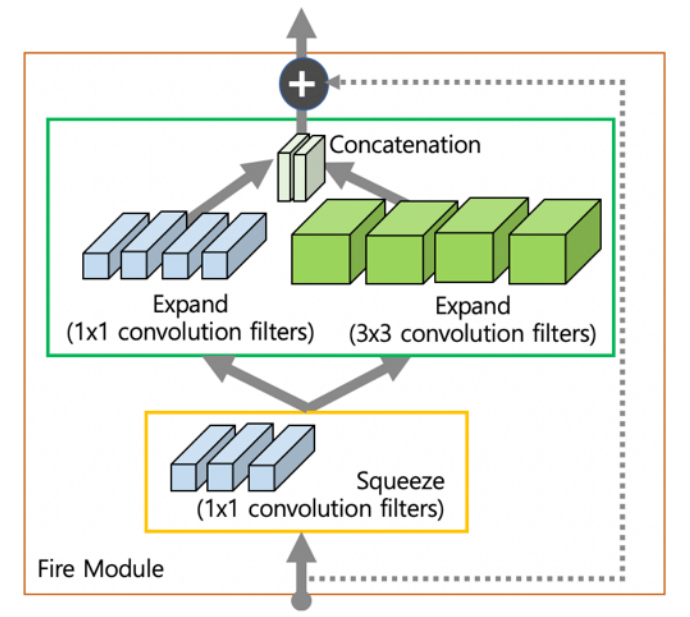
- 3x3 Filter를 1x1 Filter로 대체하여 파라미터수 9배 절약
- Convolution layer가 큰 넓이의 feature map 갖게 하기위해 Downsampling을 늦게 실행
- 이미지의 정보를 압축시키는 효과
- Fire module(파이어 모듈)은 squeeze layer(1x1 convolution layer)와 expand layer(1x1와 3x3 convolution layer)로 구성되어있다.
- fire module은 각 convolution filter의 개수를 조절 squeeze의 필터 수가 expand보다 크지 않도록 제한
2. 효율적인 합성곱 필터 기술
- 채널별(Depthwise)로 합성곱을 수행하고 점별(Pointwise)로 연산을 나누어 전체 파라미터를 줄인다.
- 점별 그룹 형태로 섞는 셔플 방법 연구 중이다.
A. MobileNet
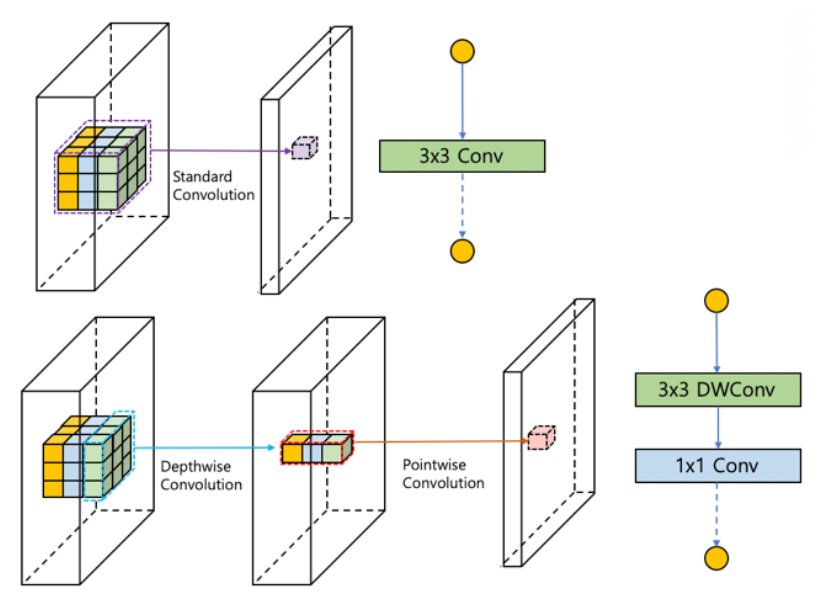
- 채널별 합성곱(Depthwise Convolution)은 각 입력 채널에 대해 3x3 filter가 연산을 수행해 하나의 피쳐맵을 생성한다.
- 입력 채널 수가 M개이면 M개의 피쳐맵을 생성한다.
- 각 채널마다 독립적으로 연산을 수행하여 spatial correlation을 계산한다.
- 채널별 합성곱의 연산량은 다음과 같다.는 입력값 크기 은 입력의 채널 수 는 피쳐맵 크기이다.
- 점별 합성곱(Pointwise Convolution)은 채널별 합성곱이 생성한 피쳐맵들을 1x1 Convolution으로 채널 수를 조정한다.
- cross-channel correlation을 계산한다.
- 점별 합성곱의 연산량은 다음과 같다.은 입력 채널 수 은 출력 채널 수 는 피쳐맵 크기이다.
- Depthwise seperable convolution은 채널별 합성곱에 점별 합성곱을 적용하는 것이다.
- 전체 연산량은 이다.
- 기존 Convolution의 연산량은 이다.
- 두 식을 비교했을 때, Depthwise seperable convolution의 연산량이 기존 Convolution의 연산량보다 8~9배 적다.
B. ShuffleNet
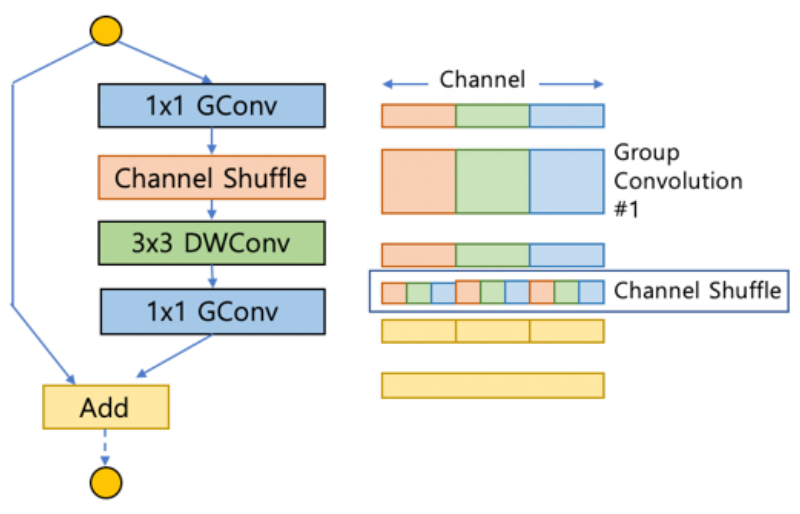
- MobileNet에서 1x1 Convolution을 활용했지만 모델의 전체 연산량에서 많은 비율을 차지한다는 단점이 존재한다.
- Group Convolution의 대표적인 예는 AlexNet이다.
- GPU 성능이 좋지 않아서 channel을 나누어 학습
- 연산량도 줄고 성능이 좋게 나옴
- 1x1 Convolution 연산량 줄임 channel 수 늘림 더 많은 정보를 네트워크가 갖는다.
- Group Convolution은 입력이 들어온 channel의 수만큼 group이 나눠진다.
- group이 나눠진 상태로 진행하면 group 사이의 교류(Cross Talk)가 없어 독립적인 네트워크를 학습시키는 것 처럼 된다.
- 이것을 해결하기 위해 Channel Shuffle이 나왔다.
- Channel Shuffle을 하면 안했을 때 보다 성능이 좋아진다.
3. 경량 모델 자동 탐색
- 기존의 신경망 최적화는 MACs(Multiplier-Accumulators) 또는 FLOPs(Floating Operations Per Seconds)에 의존했다.
- Latency 또는 Energy Consumption 문제로 기준이 바뀌고 있다.
- 추론에 최적화된 신경망을 자동 생성하거나 연산량 대비 모델의 압축비를 조정하는 방향으로 발전 중이다.
A. NetAdapt
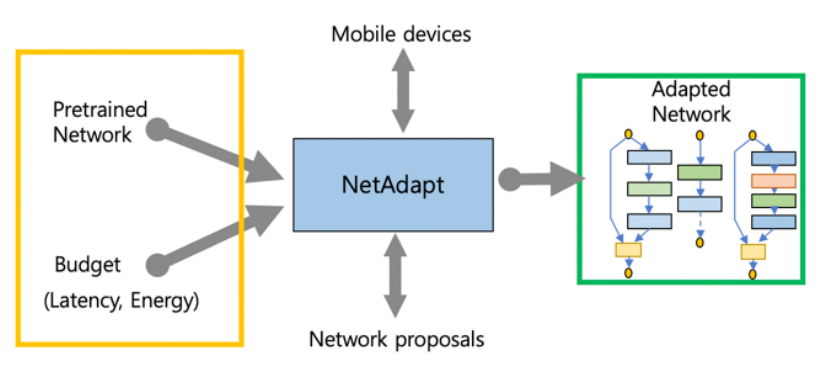
- NetAdapt는 다음 식을 푸는 데 초점이 맞춰져 있다.
- 는 정확도를 계산하고, 는 j번째의 자원 소비에대한 항목을 평가하고, 는 j번째 자원의 예산이다.
- 자원은 latency, energy, memory가 될 수있다.
- NetAdapt는 latency에 주목한다.
- NetAdapt는 다음과 같은 식으로 문제를 나눠서 쉽게 만들어 풀어낸다.
- 는 i번째 반복으로 생성된 네트워크이고, 은 시작하는 Pretrained Network이다.
- 제약 조건으로는 반복이 될 수록 예산이 줄어든다.
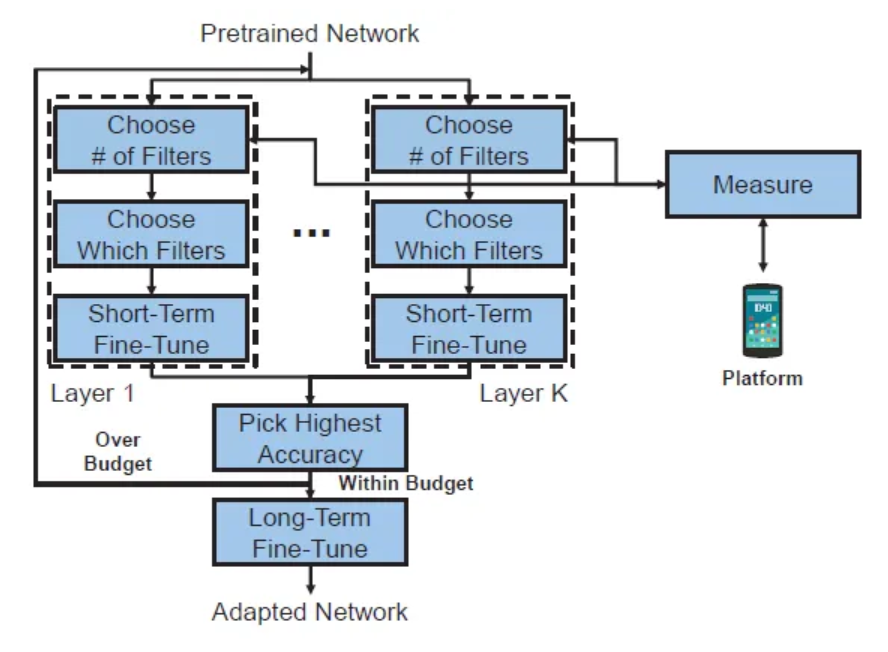
- 각 반복은 위의 2번째 식을 해결하기 위해 Convolution 또는 FC layer의 필터의 수를 줄인다.
- 간단해진 네트워크는 정확도를 복원 시키기 위해서 짧은 시간동안 fine-tuned 된다.
- NetAdapt는 1개의 반복에서 K개의 네트워크 제안을 생성한다.
- 제안된 네트워크 중 가장 높은 정확도를 가진 네트워크가 다음 반복으로 진행된다.
- Target Budget을 만나면 선택된 네트워크는 fine-tuned 된다.
B. MNasNet
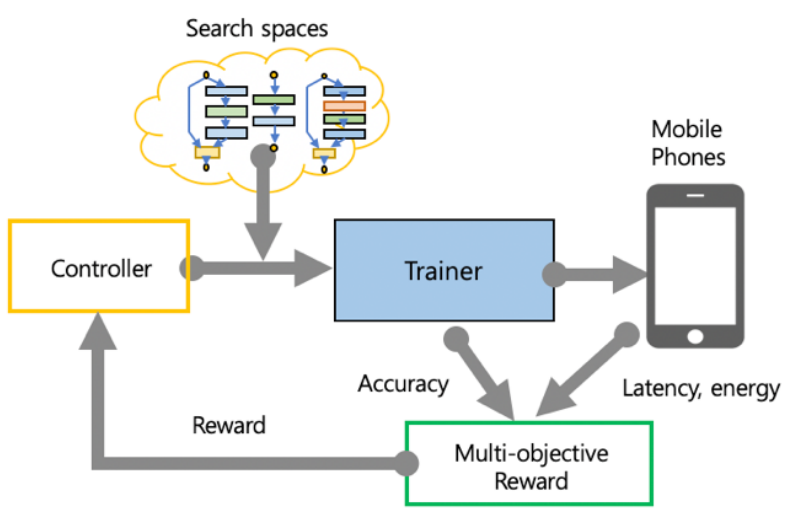
- 모바일 기기에 맞게 CNN을 설계하는 것은 어렵다.
- 모바일의 속도 제약을 해결하기 위해 탐색 알고리즘의 메인 보상 함수에 속도를 포함한다.
- MNasNet은 아래의 3가지와 같이 구성되어 있다.
- 모델 아키텍처 학습과 샘플링을 위한 RNN 기반 컨트롤러
- 모델을 빌드하고 훈련시켜 정확도를 달성하는 트레이너
- TensorFlowLite를 사용하여 휴대폰에서 모델 속도를 측정하는 추론 엔진
- 높은 정확도와 속도를 달성하는 것을 목표로 하는 다목표 최적화 문제를 만들고 맞춤 보상 함수가 포함된 강화 학습 알고리즘을 통해 파레토(Pareto) 최적 솔루션을 찾는 방식이다.where is the weight factor defined as:
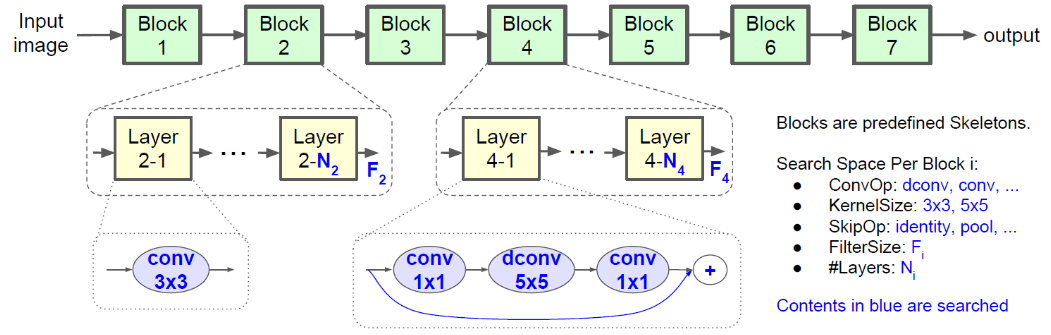
- 탐색 유연성과 탐색 공간의 크기가 균형을 이루기 위해 Novel factorized hierarcical search space를 제안한다.
- 이 방법은 신경망을 연속적인 블록으로 분해 후, 계층적 탐색 공간을 사용해 각 블록의 계층 아키텍처 결정한다.
- 각 계층이 서로 다른 연산과 연결을 사용할 수 있고, 동시에 각 블록의 모든 계층이 동일한 구조를 공유해 탐색 공간 규모를 줄일 수 있다.
알고리즘 경량화
1. 모델 압축 기술
A. 가중치 가지치기
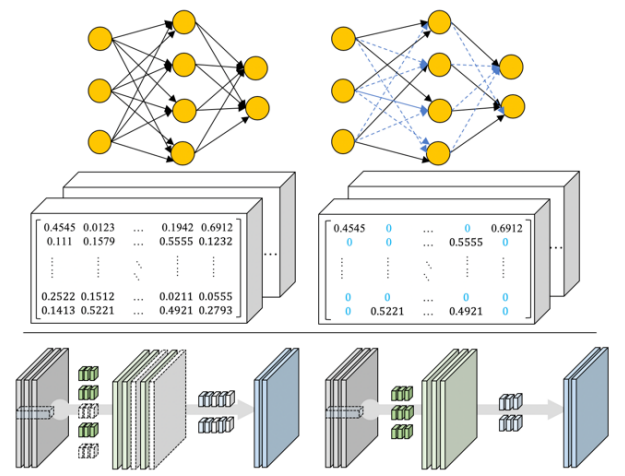
- 가중치(Weights) 중 실제 추론을 위해 필요한 값은 비교적 작은 값들에 대한 내성을 가지므로, 작은 가중치값을 못두 0으로 하여 네트워크의 모델 크기를 줄이는 기술이다.
- 가중치 가지치기(Weight Pruning) 이후 재훈련 과정을 통해 정확도를 높일 수 있는 방식으로 신경망을 조율한다.
- 채널을 선별하여 중복(불필요한) 채널에 대한 가지치기를 통해 모델을 압축하는 연구도 진행 중이다.
- Prunning에서 설정할 내용
- Pruning granularity
- Pruning할 때 각 요소를 pruning하는 것을 element-wise pruning이라고 한다.
- 요소들을 그룹으로 묶고 그룹 전체에 대해 pruning 하는 것을 group pruning이라고 한다.
- Pruning criteria
- Pruning은 가중치들 중 어떤 요소를 어떻게 prune할 지 정하기 위한 기준이 필요하다.
- Pruning schedule
- 학습 후 prunning 하는 것이며 이를 one-shot pruning이라고 한다.
- 학습과 pruning 과정을 거친 후 희귀(sparse)한 네트워크를 다시 학습하는 것을 iterative pruning이라고 한다.
- Pruning granularity
- Sensitivity analysis
- 각 가중치가 결과에 주는 sensitivity를 이해하기 위해 각각의 가중치를 prune한 뒤 평가하고, 정확도가 어떻게 변하는 지 살펴 보면서 가중치가 어느 정도 중요하지 알 수 있다.
- Pruning 방법
- Magnitude Pruner
- 가장 기본적인 방법으로, 어떤 값을 기준으로 가중치를 thresholding하는 방법이다.
- 가중치 값이 기준 값 이하라면 0으로 만들고, 기준 값보다 크면 그대로 둔다.
- Sensitivity Pruner
- Convolution layer 그리고 Fully connected layer가 가우시안 분포를 가지고 있는 것을 활용한다.where is std of layer as measured on the dense model
- 논문에서는 iterative pruning을 사용했고, 매 pruning마다 sensitvity parameter인 s 값을 수정했다.
- Sensitivity pruner의 동작 방법
- 모델에 대해 sensitivity 분석을 수행한다.
- 분석을 통해 나온 s에 가중치들 분포의 표준편차를 곱해 threshold로 사용한다.
- Convolution layer 그리고 Fully connected layer가 가우시안 분포를 가지고 있는 것을 활용한다.
- Level Pruner
- 특정 layer의 sparsity level로 pruning한다. 가중치의 값을 보고 판단하는 것이 아닌 layer의 sparsity가 특정 값이 되 게끔 pruning한다.
- Magnitude Pruner
B. 양자화 및 이진화
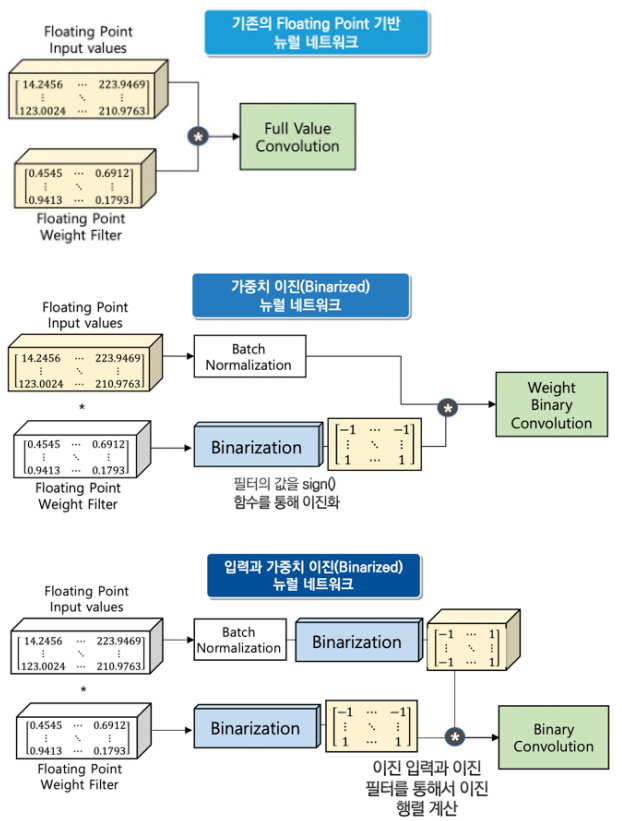
- 기존의 신경망의 부동 소수점 수를 줄이는 데 목적이 있다.
- 양자화(Quantization)의 경우 특정 비트 수만큼으로 줄여서 계산하는 방식이다.
- 예를 들어 32비트 소수점을 8비트로 줄여서 연산을 수행한다.
- 이진화(Binarization)는 가중치(Weight)와 층(layer) 사이의 입력을 부호에 따라서 -1 혹은 +1의 이진(Binary) 형태의 값으로 변환하여 용량과 연산량을 압축시키는 기술이다.
-
양자화
- Dynamic Quantization
- 가장 간단한 양자화 기법
- 모델의 가중치에 대해서만 양자화 진행
- 모델을 메모리에 로딩하는 속도 개선
- 연산 속도 향상 효과 미비 (infernce kernel 연산이 필요하기 때문이다.)
- 양자화 과정
- activations는 메모리에 부동 소수점 형태로 read, write 된다.
- inference시에만 floating-point kernel을 이용해 가중치를 int8에서 float32로 변환한다.
- activations는 항상 부동 소수점 형태로 저장되어 있다.
- 가중치들은 training 후에 양자화
- activations들은 inference time에 dynamic하게 양자화
- Static Quantization
- 모델의 가중치와 활성화 모두 양자화를 사전에 진행
- 연산 속도 향상
- 양자화 과정
- 가중치와 activations fusion(각각의 기능을 수행하는 layer를 하나로 합침)
- calibration(눈금 매김, fine tuning 같은 것으로 이해)하는 동안 활성화가 설정
- 정확도 손실을 최소화하기 위해 calibration으로 미세 조정
- Quantization aware training
- 모델의 가중치와 활성화를 학습하면서 양자화
- Dyanmic, Static Quantization 보다 높은 정확도 확보
- 양자화 과정
- fake-quantization nodes를 양자화가 되는 부분에 위치시킨다.
- Fake-quantization은 clamping(데이터 범위)과 rounding을 수행한다.
- 활성화 함수의 출렴 범위 확인을 진행한다.
- quantization aware training이 끝나면, fake-quantization nodes에 저장된 정보를 이용해, floating point 모델 을 integer 모델로 변경할 수 있다.
- Dynamic Quantization
-
이진화
- 구현할 때 1 비트만으로 표현하는 데 비트 값 0을 -1로 해석하는 방식으로 구동한다.
- float32 모델 대비 32배의 경량화가 가능하다.
- 순전파(forward propagation) 시 가중치 값이 0 이상이면 +1로, 그 미만이면 -1로 이진화를 수행한다.
- 순전파 시 sign 함수를 이용해 구현하지만, 역전파(backward propagation)시 signum 하수의 도함수(derivative)가 미분 가능하지 않다.
- 역전파시 hyperbolic tangent 함수의 도함수를 이용한다.
- 가중치와 활성화를 모두 이진화한다.
- 모델 크기의 축소
- 모델 학습추론 과정에서 필수적인 행렬 곱셈 연산을 비트열 연산으로 대체한다.
- 구현할 때 1 비트만으로 표현하는 데 비트 값 0을 -1로 해석하는 방식으로 구동한다.
C. 가중치 공유
- 낮은 정밀도에 대한 높은 내성을 가진 신경망의 특징을 활용해 가중치를 근사하는 방법이다.
- 기존 가중치 값들은 근사한 값(코드북)을 통해 가중치를 공유한다.
- 코드북과 그 값에 대한 인덱스만 저장하는 구조로, 저장 공간을 절약한다.
- 근사화 방식은 가중치들의 유사도에 기반하는데, K-Means 또는 Gaussian Mixture Model을 활용한다.
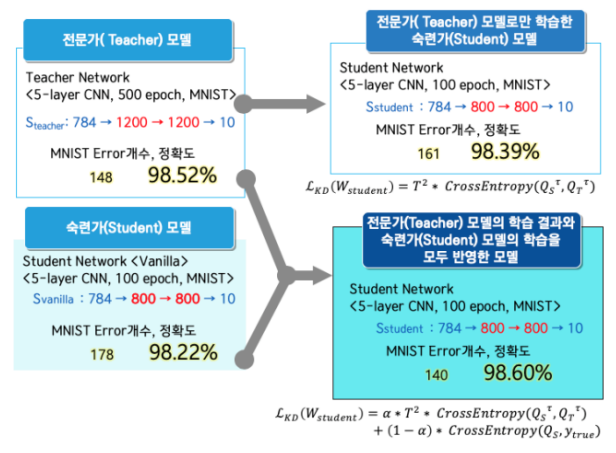
2. 지식 증류 기술
-
앙상블(Ensemble) 기법을 통해 학습된 다수의 큰 네트워크들로부터 작은 하나의 네트워크에 지식을 전달할 수 있는 방법론 중 하나다.
-
큰 네트워크들인 전문가(Teacher) 모델에서 출력은 하나의 확률값만 나타내지만, 이를 분포 형태로 변형해 숙련가(Student) 모 델의 학습 시 모델의 Loss와 전문가 모델의 Loss를 동시에 반영하는 형태로 학습된다.
-
모델 압축 기술과 같이 신경망을 간소화하는 방식으로 이루어지고 있지만, 훈련된 네트워크보다 더 큰 네트워크로의 지식 전의 (Knowledge Transfer) 연구도 진행 중이다.
-
지식 전이 기법 중에서 더 넓은 네트워크를 만들 때 정보를 동일하게 전달하는 연산(Operation) 방법도 가능하다.
-
Knowledge Distillation은 왜 등장했을까?
- 연구 및 개발을 통해 만들어진 딥러닝 모델은 다량의 데이터와 복잡한 모델을 구성하여 좋은 정확도를 내도록 설계된다.
- 모델을 배포한다고 생각했을 때, 모바일 장치는 강력한 하드웨어가 아니기 때문에 복잡한 모델이 적합하지 않을 수도 있다.
- 복잡한 모델 T : 예측 정확도 99% + 예측 소요 시간 3시간
- 단순한 모델 S : 예측 정확도 90% + 예측 소요 시간 3분
- 배포 관점에서는 모델 S가 더 적합하다.
- 모델 T와 모델 S를 활용하는 방법이 지식 증류이다.
-
Knowledge Distillation은 어떻게 하는 걸까?
-
Soft Label
- 이미지 클래스 분류와 같은 task는 신경망의 마지막 softmax 레이어를 통해 각 클래스의 확률값을 출력한다.
- 다음과 같은 수식을 통해 i번째 클래스에 대한 확률값()
-
cow dog cat car 0 1 0 0 -
기존의 개 사진의 레이블을 Original(Hard) Target이라고 생각한다.
-
cow dog cat car .9 .1 -
학습한 딥러닝 모델에 사진을 넣는다면 클래스마다 확률값(q)를 출력한다.
-
그에 따라 가장 높은 출력값인 0.9의 클래스 개를 예측한다.
-
이러한 출력값들이 모델의 지식이 될 수 있다고 본다.
-
softmax에 의해 작아 모델에 반영하기 쉽지 않다.
-
cow dog cat car .05 .3 .2 .005 -
출력값의 분포를 좀 더 soft하게 만들면, 이 값들이 모델이 가진 지식이라고 볼 수 있다.
-
이러한 soft output을 dark knowledge라고 표현한다.
- soft하게 만들어 주는 과정을 수식으로 표현하면 위와 같다.
- 기존 softmax와 다른 점은 T라는 값이 분모로 들어간다.
- 온도(temperature)라고 표현하고, 이 값이 높아지면 soft하게 낮아지면 hard하게 만든다.
-
Distillation Loss
- 큰 모델을 학습 시킨 후 작은 모델을 손실 함수를 통해 학습한다.
L은 손실함수, S는 Student model, T는 Teacher model을 의미한다.
(x, y)는 하나의 이미지와 그 레이블, 는 모델의 학습 파라미터, 는 temperature를 의미한다.- 손실함수는 크게 기존 이미지 분류에서 사용하는 Cross Entropy Loss()와 Distillation Loss()로 구성된다.
- 는 학습된 Teacher model의 soft labels와 Student model의 soft predictions를 비교하여 손실하수를 구성한다.
-
3. 하드웨어 가속화 기술
- 벡터 / 행렬 연산을 병렬 처리하기 위한 전용 하드웨어 TPU(Tensor Processing Unit)
- On-Device AI 응용 추론을 위한 전용 VPU(Visual Processing Unit) 프로세스 및 GPU Cluster 기반 가속기 연구 개발 중이다.
- 경량 디바이스에서 사용 가능한 칩셋 / USB 스틱 형태
- 인텔 - 모비디우스를 통한 뉴럴 컴퓨터 스틱
- 엔비디아 - 젝슨 TX2
- 구글 - 엣지 TPU
- 퀄컴 - 스냅드래곤
- 화웨이 - 기린
- 애플 - A12칩
- 삼성 - 액시노스
4. 모델 압축을 적용한 경량 모델 자동 탐색 기술
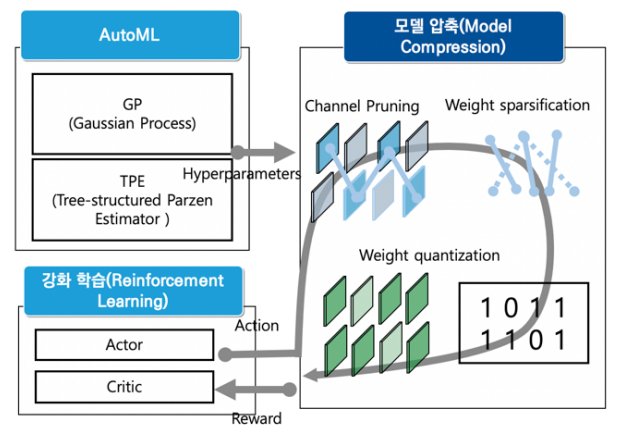
- 알고리즘 경량화도 네트워크 가지치기, 가중치 양자화 등의 탐색 공간을 통한 자동화 연구가 진행 중이다.
- 텐센트(Tencent)의 포켓플로(PocketFlow)는 하이퍼 파라미터의 최적화를 통해 모바일넷(MobileNet)에 모델 압축 기법을 적용한다.
- 정확도와 지연기산을 모두 고려한 강화학습 기잔의 모델 압축 기법을 자동 탐색하는 기법도 있다.
- NAS(Neural Architecture Search) 또는 AutoML(Automated Machine Learning)에 그치지 않고 모델 압축 자동 탐색(AutoMC Automated Model Compression) 형태로 바뀌고 있다.
경량 딥러닝 산업 동향
- 경량 딥러닝을 적용한 산업은 현재 태동 단계에 있다.
- 딥러닝 프레임워크도 경량 알고리즘을 위한 기법을 적용한다.
- 하드웨어 경우 엣지 디바이스 형태로 모바일 기기에서부터 산업 현장의 게이트웨이까지 범위를 넓히고 있다.
- 파이토치(PyTorch)와 텐서플로(Tensorflow)의 경우 양자화를 통한 경량화를 지원한다.
- 파이토치의 경우 모바일넷, 스퀴즈넷, 덴스넷
- 텐서플로우의 경우 모바일넷, 엠나스넷, 스퀴즈넷
- 모바일 기기 위주의 서비스 형태
- 감정 분석
- 문장 번역 서비스
- 이미지 분류
- 음악 태깅
- 키보드 문자열 예측
- 손글씨 분석
- 헬스 케어 분야
- 안과 질환 검증
- 피부암 진단
- 자율주행 자동차 분야
- 눈동자 감김이나 고개 젖힘 감지
- 내장 센서를 통한 운전 패턴 인식
결론
- 산업 현장에 적용하기 위한 간소화 및 경량화 기법들이 제시되고 있다.
- IoT 디바이스, 스마트폰 및 산업용 경량 장치에 탑재 가능한 모델의 형태
- 경량 딥러닝 알고리즘을 통한 적은 파라미터를 가진 효율적인 구조에 대한 연구
- 기존의 알고리즘의 불필요한 표현력을 줄이는 연구
