
자동 기계학습(AutoML)
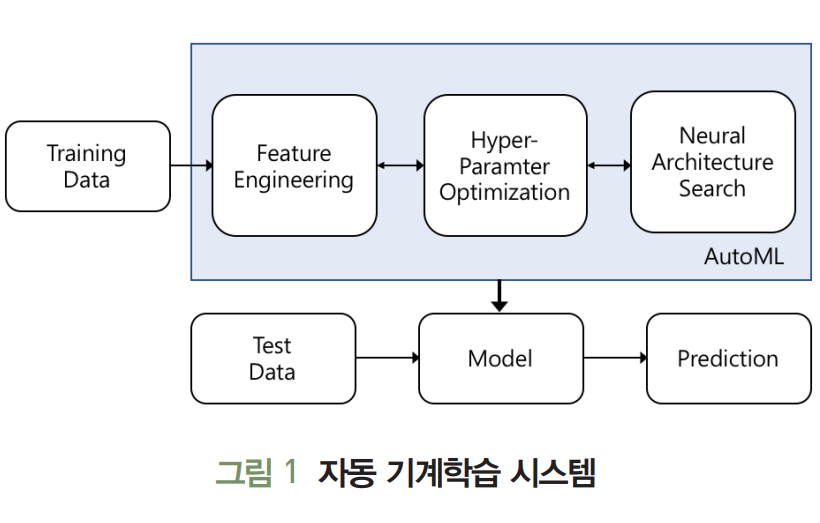
- 목표 데이터별로 모델 선정, 훈련 및 최적화 단계에서 많은 시간과 컴퓨팅 자원이 요구된다.
- 목표 데이터 또는 태스크가 다를 경우 이와 같은 작업이 반복 수행돼야 하는 문제점이 있다.
- 이러한 문제점을 극복하기 위해 자동 기계학습(AutoML: Automated Machine Learning) 기술에 주목한다.
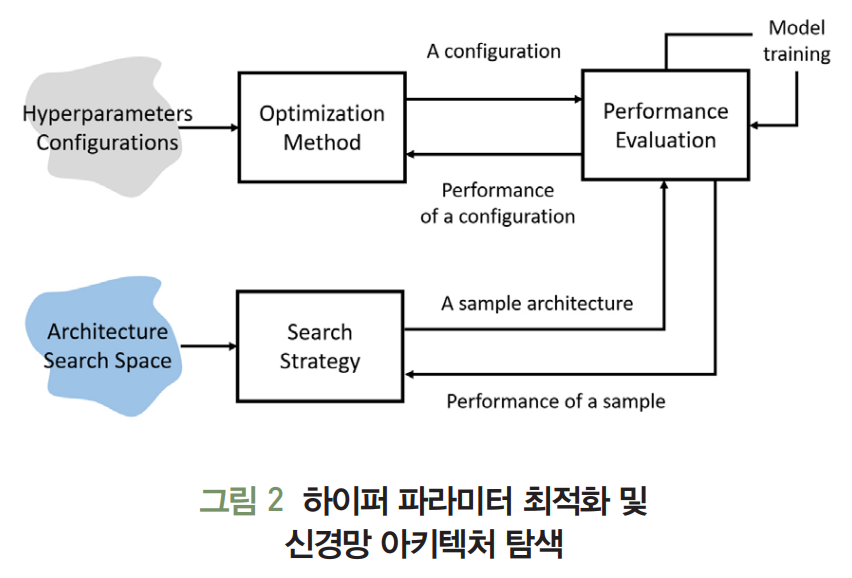
- 해당 기술은 하이퍼 파라미터 최적화(HPO: Hyper Parameter Optimization) 및 신경망 아키텍처 탐색(NAS: Neural Architecture Search)과 같은 주요 프로세스를 자동화하는 데 이용된다.
-
하이퍼 파라미터 최적화
- 머신러닝 및 딥러닝 모델의 입력값으로 해당 모델이 목표 데이터 특성으로부터 일반화된 추론 성능을 훈련할 수 있도록 제어하는 기능
- 학습률
- 학습률 스케줄링 방법
- 손실 함수
- 훈련 반복횟수
- 가중치 초기화 방법
- 정규화 방법
- 적층할 계층의 수
- 개별 변수 조율 방식에 따라 다양한 하니퍼 파라미터 설정이 도출될 수 있다.
- 하이퍼 파라미터 최적화 기술로 베이지안 최적화(Bayesian Optimization)가 연구 됐지만, 탐색 복잡성을 줄이기 위해 대안 기술이 제안된다.
- 머신러닝 및 딥러닝 모델의 입력값으로 해당 모델이 목표 데이터 특성으로부터 일반화된 추론 성능을 훈련할 수 있도록 제어하는 기능
-
신경망 아키텍처 탐색 기술
- 데이터와 태스크를 대상으로 효과적으로 신경망을 자동 생성하기 위해 뉴런 연결구조와 가중치를 탐색 대상으로 삼는다.
- 신경망 탐색 과정
- 탐색 영역 설계
- 탐색 최적화 기법 고안
- 성능 평가 전략 정의 및 기본 연산(Primitive Operaitons) 설정
- 신경망을 구성하는 단위 구조를 어떻게 설계하는가에 따라 신경망의 조합수(탐색 영역)가 결정된다.
- 탐색 영역 설계가 신경망 자동 탐색 복잡도를 결정한다.
하이퍼 파라미터 최적화(HPO)
1. 그리드 탐색과 랜덤 탐색
-
그리드 탐색
- 하이퍼 파라미터 구간에서 일정 간격으로 하이퍼 파라미터 값을 선택해 성능을 측정한다.
- 가장 높은 성능을 보장하는 하이퍼 파라미터 값을 최적해로 도출한다.
- 구간 전역을 탐색하기 때문에 하이퍼 파라미터의 종류가 많아질수록 탐색 시간이 증가한다.
- 균일한 간격으로 탐색하기 때문에 최적 하이퍼 파라미터 값을 찾지 못할 수 있다.
-
랜덤 탐색
- 하이퍼 파라미터 구간 내에서 임의로 값을 선택한다.
- 불필요한 반복 탐색을 줄여 빠르게 최적 하이퍼 파라미터 발견 가능성을 높인다.
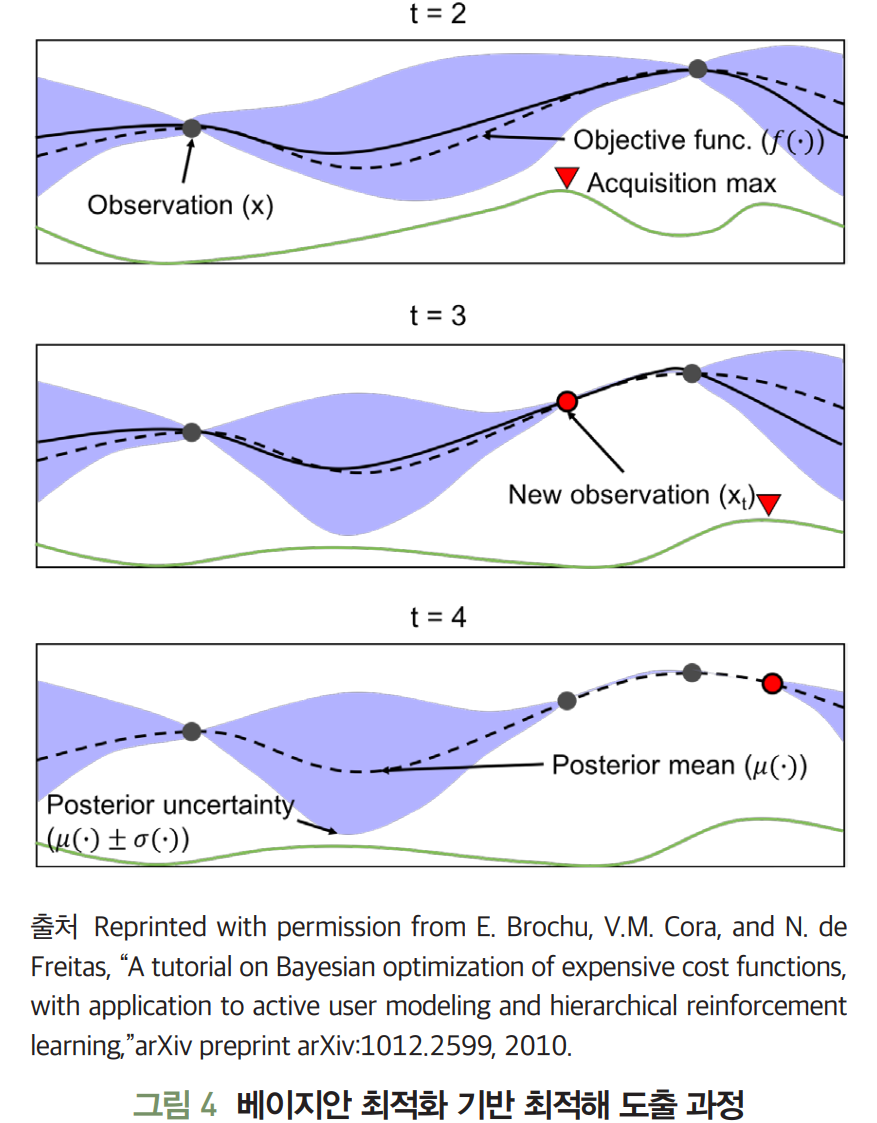
2. 베이지안 최적화
-
목적 함수를 최대로 하는 최적해를 찾는 기법이다.
-
Jasper Sneok: 베이지안 최적화를 하이퍼 파라미터 탐색에 적용함
- Surrogate 모델과 Acquisition 함수로 구성된다.
- Surrogate 모델: 현재가지 조사된 입력값과 함수값을 바탕으로 목적 함수의 형태에 대한 확률적 추정을 수행한다.
- Acquisition 함수: Surrogate 모델의 결과를 이용해 최적해를 찾는 데 유용한 후보를 추천한다.
- 그림의 t=2에서
- Surrogate 모델은 현재까지 조사된(입력값 - 함숫값)을 사용해 입력 x에 따른 표춘 편차(파란 음영)와 평균을 추정한다.
- Acquisition(초록 실선) 함수는 Surrogate 모델의 추정 결과에서 표준 편차가 큰 영역 또는 현재까지 조사된 값들 중 함수값 이 큰 x의 근방을 탐색해 목적 함숫값을 최대로 만드는 를 예측한다.
- 그림의 t=3에서
- 를 Surrogate 모델의 새로운 입력으로 반영하여 t=2에서의 과정을 반복한다.
- 반복할수록 Surrogate 모델에서 입력 x에 따른 표준 편차가 작아지고, 추정된 목적 함수(검정 실선)가 실제 목적 함수(검정 점선)에 가까워진다.
- 블랙박스인 목적 함수를 추정하는 최적 입력해의 탐색이 가능하다.
- Surrogate 모델과 Acquisition 함수로 구성된다.
-
최근에는 베이지안 최적화와 Hyperband 기법을 조합한 하이퍼 파라미터 최적화 기술이 등장하고 있다.
-
FABOLAS
- 무작위로 선별된 하이퍼 파라미터 집학과 집합의 크기를 이용해 최적해를 탐색한다.
- 멀티 태스크 베이지안 최적화와 엔트로피 탐색을 활용해 하이퍼 파라미터를 부분 집합으로 나눠 베이지안 최적화를 적용한다.
- 하이퍼 파라미터 부분 집학과 전체 집합의 상관관계에 기반해 최적해를 추정한다.
- 기존 멀티 태스크 베이지안 최적화보다 10배, 엔트로피 탐색보다 100배 빠른 탐색 성능을 보장한다.
-
Hadrien Bertrand: 베이지안 최적화와 Hyperband를 조합한 탐색 기법 제안
- 하이퍼 파라미터 집합에서 하나의 부분 집합을 선택해 Hyperband로 평가하고 Surrogate 모델로 학습한다.
- 탐색되지 않은 부분 집합들에 대해 성능 향상 기댓값을 계산해 정규화를 통해 확률 분포를 구성한다.
- 확률 분포를 이용해 다음으로 탐색할 부분 집합을 정한다.
- 해당 과정은 최적해를 탐색할 때까지 반복된다.
- 베이지안 최적화보다 손실값이 적고, 약 2배 정도 빠르게 최적해를 탐색한다.
- Hyperband와 손실값은 유사하지만 약 10배 정도 빠른 탐색 성능을 보여준다.
-
BOHB
- 앞서 언급한 연구들과 달리 베이지안 최적화에 Tree Parzen Estimate를 사용해 간결성과 계산 효율을 증가시켰다.
- 베이지안 최적화의 하이퍼 파라미터 집합 선택 방식을 사용한다.
- 속도 향상을 위해 병렬 처리를 지원하며, 32개의 병렬 워커를 사용할 경우 15배의 속도 향상이 보장된다.
- Toy Function, SVM, Feed-forward 신경망, 베이지안 신경망, 심화 강화 학습 에이전트, 합성곱 신경망을 대상으로 가장 우수한 성능을 보인다.
3. 그 외 최적화 기법
- Hyperband
- 하이퍼 파라미터 선택 문제를 최적화가 가능한 Infinite-Armed Bandit 문제로 설정한다.
- 하이퍼 파라미터 설정(Configuration) 중 더 우수한 조합에 상대적으로 많은 자원(훈련 횟수, 데이터 표본 등)을 할당한다.
- 균일한 자원할당 전략으로 인해 효율적 탐색이 어려웠던 SuccessiveHarving 알고리즘의 문제점을 개선했다.
- 최적화 속도를 베이지안 최적화 기법보다 5배에서 30배까지 향상시켰지만, 하이퍼 파라미터의 차원이 증가할 경우 확장성에 문제가 있다.
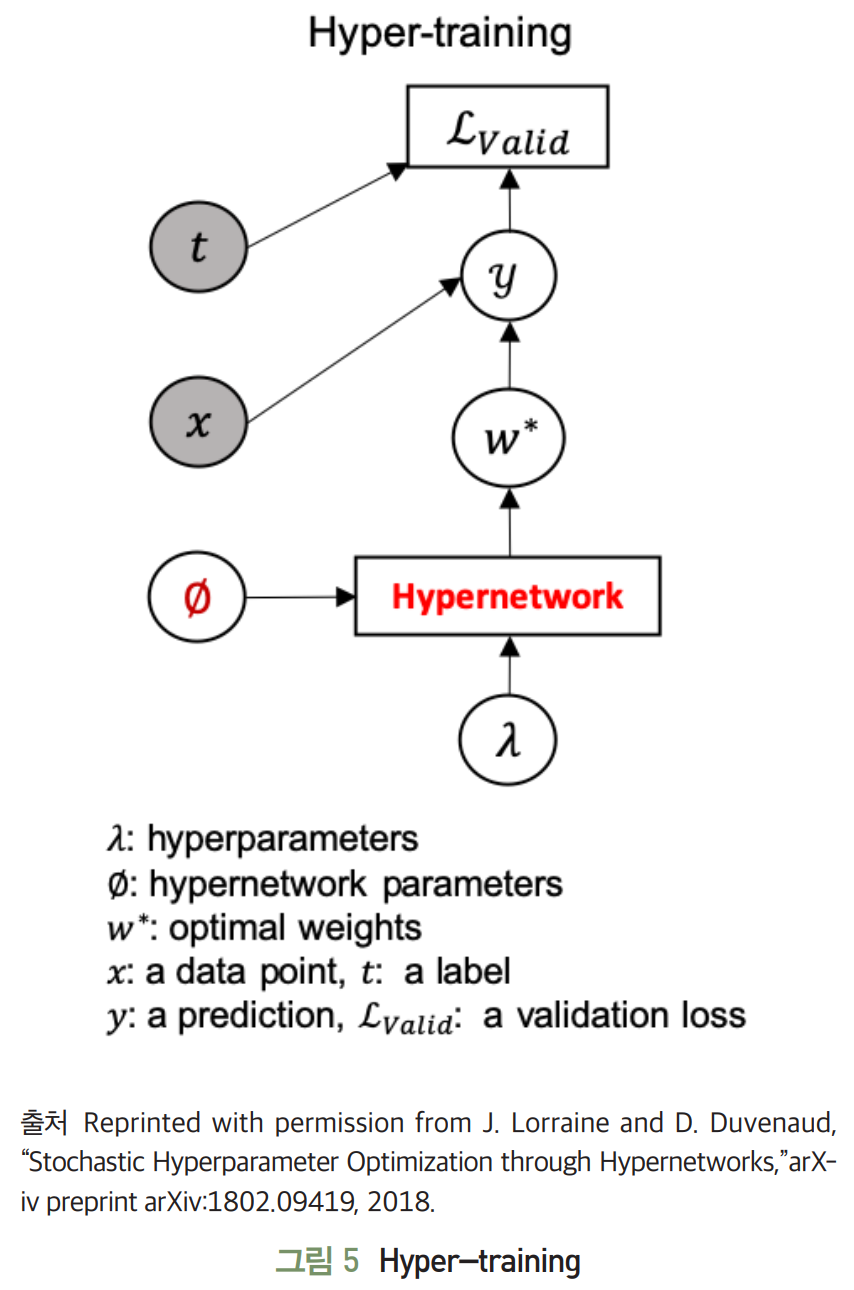
- Hyper-training
- 하이퍼 파라미터 탐색 영역상에서 이웃한 설저에 적합하게 근사 최적화된 가중치를 훈련할 수 있을 정도의 하이퍼 네트워크만 사용해도 충분한 탐색을 보장한다.
- SMASH가 최적 가중치를 근사화하기 위해 규모가 큰 하이퍼 네트워크를 요구하는 문제점 개선했다.
신경망 아키텍처 탐색
1. 진화 알고리즘 기반 탐색
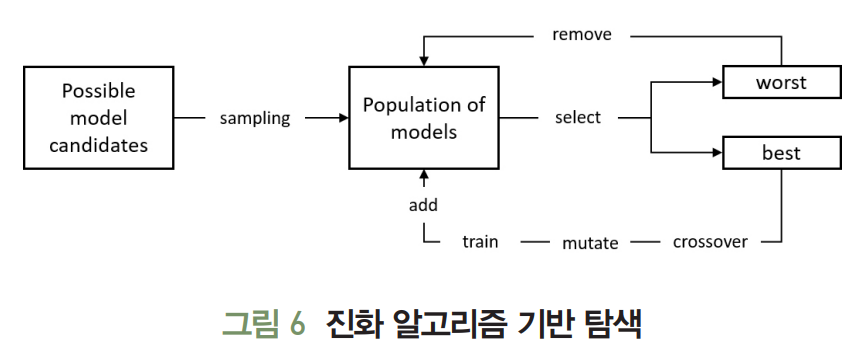
-
진화 알고리즘(Evolution Algorithm)은 후보해 집합(Population)을 생성한다.
-
선택-크로스오버-뮤테이션-평가의 과정을 반복해 해당 집합을 업데이트 하여 적합성 지표(Fitness)를 만족시키는 해를 탐색한다.
-
이후 진화 알고리즘 기반으로 합성곱 신경망을 자동 탐색하는 제안들이 등장하고 있다.
-
AmoebaNet
- NASNet이 제안한 탐색 영역을 활용해 후보해 집합을 구성한다.
- 탐색의 효율을 높이기 위해 특정 세대 이상 후보해 집합에 머물러 있으면 노후(Aging)의 관점에서 제거해 후보해 간의 경쟁 확률을 줄인다.
- 뮤테이션을 이용해 부모해를 자식해로 변환해 크로스오버로 인한 최적해 수렴 저해 요소를 제거한다.
- ImageNet을 대상으로 ResNet 계열의 이미지 분류 모델과 대등한 성능을 달성했다.
- 큰 연산 자원이 요구되는 문제점이 있다.
-
Hierarchical NAS
- 노드와 엣지로 구성된 계산 그래프를 계층화해 반복적인 Motifs로 구성된 CNN의 탐색 영역을 생성한다.
- 임의 후보해는 계산 그래프 형태로 표현되며, 노드는 특징 맵을, 노드 간의 엣지는 연산으로 기능한다.
- 단순화된 뮤테이션을 통해 노드 간 엣지에 부여될 연산을 확률적으로 변경해 신경망을 만든다.
- Hierarchical NAS가 AmeobaNet에 비해 짧은 탐색 시간을 보장한다.
- 탐색 복잡도를 결정하는 요소 기술이 탐색 영역 설계라는 것이다.
-
JASQNet
- 신경망 아키텍처와 양자화 비트 수를 동시에 탐색해 최적의 조합을 결정하는 방법을 제안한다.
- 추론 정확도와 모델 경량화의 두 가지 성능을 조율해 파레토 최적화(Pareto Optimality) 달성이 가능하도록 아키텍처 탐색한다.
- 양자화의 경우 신경망의 계층별로 상이한 비트 수를 설정해 혼합 정밀도(Mixed-Precision) 연산을 지원한다.
- NASNet의 셀(Cell) 구조를 이용하고 있다.
- 양자화 비트 수 추가 탐색으로 인한 복잡도 증가를 고려해야 한다.
- JASQNet 기법은 학습시간을 1~3 GPU Days 이내로 축소했다.
2. 강화 학습 기반 탐색
-
강화 학습(Reinforcement Learning) 기법의
- 액션 탐색
- 액션 공간 탐색 영역
- 보상 신경망의 성능
각각 연결될 수 있다.
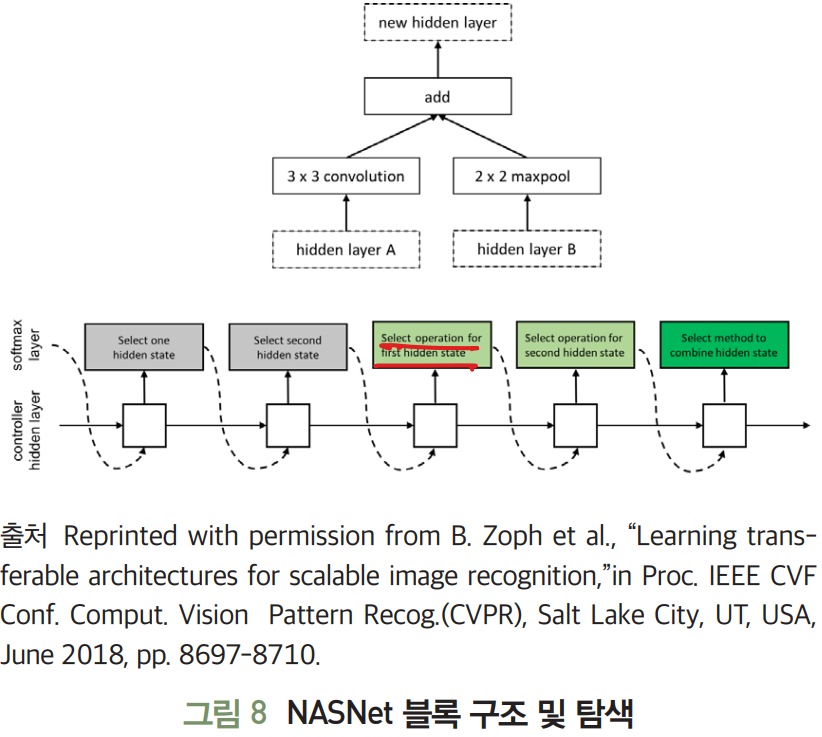
-
NASNet
-
NAS 기술의 신경망을 구성하는 단위 구조인 블록을 제시하고, 제약 조건을 두어 탐색 영역을 한정한다.
-
블록은
- 두 개의 입력을 받아 연산 처리하는 각각의 노드
- 두 노드의 처리 결과를 병합하여 결과값을 산출하는 노드
로 구성된다.
-
순환 신경망(RNN: Recurrent Neural Network) 제어기는 두 입력값, 두 연산자, 병합 연산자라는 파라미터들을 결정하도록 PPO(Proximal Policy Optimization) 이용해 훈련된다.
-
NasNet은 훈련을 5회 반복해 하나의 합성곱 셀을 탐색하는 데, 각 셀은 합성곱 신경망의 한 계층으로 기능한다.
-
NAS 기법과 비교했을 때 단위 구조에 제약을 두어 탐색 영역을 한정하는 거의 성능적 중요성을 입증한다.
-
-
MnasNet
-
RNN 제어기를 훈련시켜 NAS와 동일한 구성 요소들을 도출한다.
-
탐색 성능을 향상할 목적으로 합성곱 신경망을 여러 블록의 순차적 적층으로 구조화 한다.
-
개별 블록을 구성하는
- 복수 계층들의 연산자 종류
- 커널 크기
- 필터 개수
- 계층 개수
세부적인 사항들을 RNN을 통해 산출하도록 탐색 영역을 계층적으로 설계하여, 탐색 영역의 크기를 축소했다.
-
모바일 기기에서 추론 시간을 측정하여 탐색의 정확도를 개선했다.
-
파라미터 개수와 곱셈 누산의 획수가 증가한다는 단점이 있다.
-
-
ENAS
- 장단기 기억(LSTM: Long Short Term Memory) 신경망 제어기로부터 샘플링 된 차일드 모델들(Child Models) 간의 가중치 공유를 통해 신규 탐색된 모델이 재학습되 않도록 만드는 것이다.
- 탐색할 수 있는 모든 모델을 하나의 DAG(Directed Acyclic Graph)로 표현하고, DAG의 서브 그래프를 샘플링된 차일드 모델로 정의한다.
- DAG는 모든 모델의 중첩이므로, 이전 모델의 훈련된 가중치 중 일부는 새롭게 샘플링된 모델에 재활용될 수 있다.
- NAS, NasNet, Hierarchical NAS 대비 각각 50,000배, 4,000배, 666배의 탐색 속도 개선을 이뤘다.
3. 경사 하강법 기반 탐색
- 진화 알고리즘 및 강화 학습 기반의 탐색 기법의 대안 연구이다.
- 이산적이고 미분할 수 없는 탐색 영역을, 연속적이고 미분이 가능한 도메인으로 완화(Relaxation)한 기술들이 제안되고 있다.
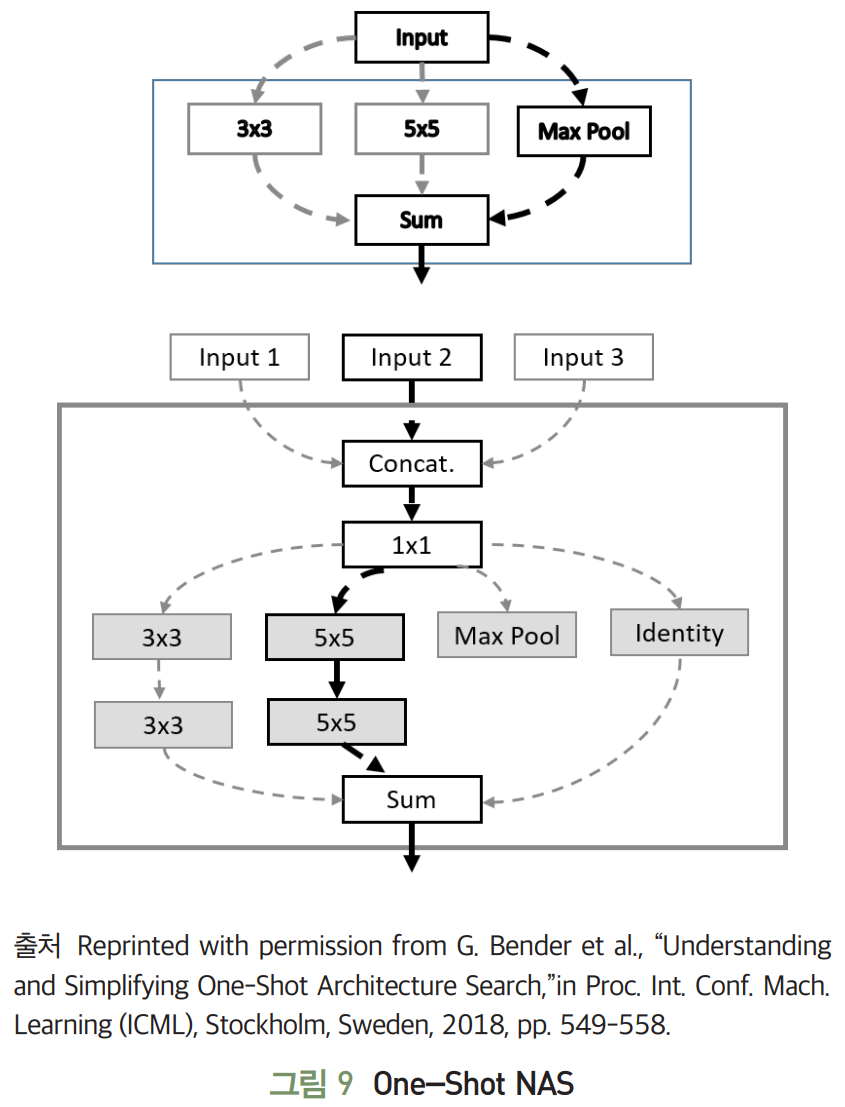
-
One-shot NAS
- 가중치 공유 효과를 통해 탐색 복잡도를 낮추고자 단일한 모델에서 적용 가능한 연산들을 모두 고려하여 훈련하는 원-샷 모델을 제안한다.
- 여러 신경망 구조들을 모두 학습시키는 효과를 낼 수 있고, 서로 다른 아키텍처들이 같은 가중치 값들을 재활용할 수 있게 된다.
- 메모리 효용성이 떨어지는 문제점을 해결하고자, 블록에서 하나의 연산을 선택하고 나머지 가능한 연산들을 제거(Zeroing Out)하는 방식으로 탐색을 진행한다.
- 탐색 완료 후, 성능이 가장 우수한 아키텍처 모델을 선별하고 해당 모델을 처음부터 다시 훈련해 목표 데이터에 대해 최적 성능을 제공할 수 있는 신경망을 생성한다.
- 신경망은 동일 구조의 셀로 적층되어 있고, 셀은 하나 이상의 블록으로 구성된다.
- 파라미터 축소 측면에서 우월한 결과를 도출했다.
-
DARTS
- ENAS의 순환 셀 설계를 차용해 셀을 정의한다.
- 셀 내부 노드 간에 적용될 수 있는 모든 연산자들을 혼한 연산자(Mixed Operations)의 형태로 고려한다.
- 탐색 영역을 연속적 영역으로 완화해 미분할 수 있도록 만든다.
- 셀을 구성하는 노드 수를 미리 결정할 경우, 노드 간에 적용될 수 있는 연산자 중 확률적으로 가장 좋은 성능을 보장하는 연산자를 선정하는 방식으로 신경망 아키텍처 탐색을 수행한다.
- 아키텍처를 고정한 상태에서 가중치 역시 경사 하강법을 통해 갱신할 수 있다.
- 양단식 최적화(Bilevel Optimization)을 반복해 신경망 구조 가중치를 탐색한다.
-
ProxylessNAS
- 경사 하강법 기반의 NAS 기법들이 GPU 메모리 사용량이 급속도로 증가한다는 문제점에 주목한다.
- 탐색된 신경망을 전이학습(Transfer Learning)을 통해 ImageNet과 같은 큰 데이터 셋에 맞게 재학습한 후 탐색 능력의 우수성을 입증하는 문제점도 지적한다.
- ProxylessNAS는 셀 내부 노드 간의 혼합 연산자를 설정하고, 복수의 중복된 연결이 노드 간에 형성될 수 있는 것을로 가정한다.
- 가지치기(Pruning)와 유사한 개념을 도입해 개별 연결의 유지 또는 제거를 나타내는 이진 파라미터를 연결마다 연산자와 함께 훈련의 대상으로 포함한다.
- 노드 간 복수 연결 중 연결이 유지되는 연산자들에 대해서만 업데이트를 수행하므로 메모리 효율성을 크게 개선할 수 있다.
- 전이학습 없이 큰 규모의 데이터 셋을 직접 훈련하여 최적화된 신경망을 탐색한다.
결론
- 최근에는 하이퍼 파라미터 최적화와 신경망 아키텍처 탐색을 하나의 문제로 풀고자 하는 연구들도 출현하고 있다.
- 최근 탐색 영역을 재설계하거나 한정하여 GPU Days를 개선한 연구 사례가 도출되고 있다.
- 이를 기반으로 기본 연산자 축소, 양자화 도입, 큰 데이터를 대상으로 직접 탐색 등을 시도하는 논문들이 나타날 것으로 예상된다.
- NetScore 관점에서 정확도 대비 파라미터 개수 또는 연산 횟수를 줄이기 위한 기술적 진전이 요구된다.
