
딥러닝 파이토치 주요과정
.png)
데이터 -> 모델
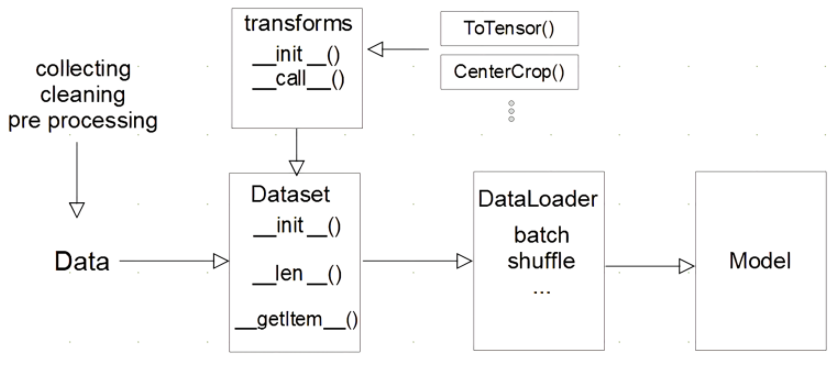
Dataset 클래스
- 데이터 입력 형태를 정의하는 클래스
- 다양한 데이터 형식(Image, Text, ...)을 입력하는 방식을 표준화
- 다음과 같이 3가지 메서드로 구성됨
__init__- 데이터의 위치나 파일명과 같은 초기화 작업을 위해 동작함(데이터 불러오기 및 초기화)
- 처리할 transforms를 Compose해서 정의함
__len__- Dataset의 최대 요소 수를 반환
__getitem__- 데이터셋의 idx번쨰 데이터를 반환
- 원본 데이터를 가져와서 전처리하고 데이터 증강하는 부분도 여기에서 진행됨.
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, text, labels): # 데이터 생성 방법 지정
self.labels = labels
self.data = text
def __len__(self):
return len(self.labels) # 데이터 길이 반환
def __getitem__(self, idx): # 요청된 idx값에 있는 데이터를 반환
label = self.labels[idx]
text = self.data[idx]
sample = {"Text": text, "Class": label}
return sample- 데이터 형태에 따라 각 함수를 다르게 정의함
- EX) NLP와 정형데이터는 처리 방법이 다름
- 최근에는 HuggingFace 등 표준화된 라이브러리를 사용함
DataLoader 클래스
- Data의 Batch 등을 생성(제공)해주는 클래스
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)- dataset: Dataset 인스턴스를 넣어줌
- batch_size: 배치 사이즈 지정
- shuffle: 데이터를 섞을것인지 지정
- SequentialSampler : 항상 같은 순서
- RandomSampler : 랜덤, replacemetn 여부 선택 가능, 개수 선택 가능
- SubsetRandomSampler : 랜덤 리스트, 위와 두 조건 불가능
- WeigthRandomSampler : 가중치에 따른 확률
- BatchSampler : batch단위로 sampling 가능
- DistributedSampler : 분산처리 (torch.nn.parallel.DistributedDataParallel과 함께 사용)
- sampler: 데이터의 index를 원하는 방식대로 조정함(shuffle = False여야 함)
- collate_fn: ((피처1, 라벨1) (피처2, 라벨2))와 같은 배치 단위 데이터가 ((피처1, 피처2), (라벨1, 라벨2))와 같이 바뀜. 또한 데이터 사이즈를 맞추기 위해 사용됨.
(참고: 안수빈님 블로그)
Titanic 데이터 불러오기
import pandas as pd
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
class Titanic(Dataset):
def __init__(self, path, drop_features, train=True):
self.data = pd.read_csv(path).drop(drop_features, axis = 1)
self.data['Sex'] = np.where(self.data['Sex'] == 'male', 0, 1)
self.data['Embarked'] = self.data['Embarked'].map({'S':0, 'C':1, 'Q':2})
self.features = [col for col in self.data.columns[1:]]
self.classes = ['Dead', 'Survived'] # [0, 1]
self.X = self.data.iloc[:, 1:].to_numpy()
self.y = self.data.iloc[:, 0].to_numpy()
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
if self.train:
X, y = self.X[idx], self.y[idx]
return torch.tensor(X), torch.tensor(y)
else:
X = self.X[idx]
return torch.tensor(X)
dataset_titanic = Titanic('./train.csv',
drop_features=['PassengerId', 'Name', 'Ticket', 'Cabin'],
train=True)
dataloader_titanic = DataLoader(dataset=dataset_titanic,
batch_size=4)
print(next(iter(dataloader_titanic)))
## batch_size_4
>>> [tensor([[ 3.0000, 0.0000, 22.0000, 1.0000, 0.0000, 7.2500, 0.0000],
>>> [ 1.0000, 1.0000, 38.0000, 1.0000, 0.0000, 71.2833, 1.0000],
>>> [ 3.0000, 1.0000, 26.0000, 0.0000, 0.0000, 7.9250, 0.0000],
>>> [ 1.0000, 1.0000, 35.0000, 1.0000, 0.0000, 53.1000, 0.0000]],
>>> dtype=torch.float64),
>>> tensor([0, 1, 1, 1])]
AI Engineer : Lv 0