
torch.nn.Module
- 딥러닝을 구성하는 Layer의 base class
- Input, Output, Forward, Backward(Auto-Grad) 정의
- 학습의 대상이 되는 parameter 정의
torch.Parameter
- nn.Module 안에 미리 만들어진 tensor들을 보관
- nn.Parameter 클래스는 torch.Tensor 클래스를 상속받아 만들어졌음
- torch.nn.Module 클래스의 attribute로 할당되면, 자동으로 파라메터 목록(parameters())에 추가됨(torch.Tensor 클래스와의 차이점)
- Parameter로 지정된 tensor의 경우, 역전파시 gradient 값을 계산하여 값을 업데이트 해주고, 모델을 저장할 때 값을 저장해줌.
- tensor로 저장된 값은 업데이트 되지 않고 모델을 저장할 때도 무시됨
- 대부분 layer에는 weights 값들이 지정되어 있음
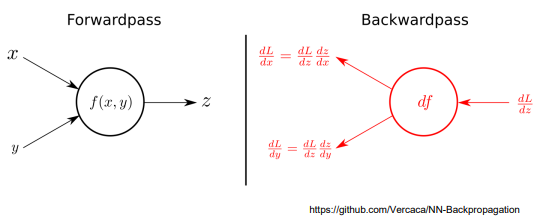
Backward
- Layer에 있는 Parameter들의 미분을 수행
- Forwad의 결과값(예측치)과 실제값 간의 차이(Loss)에 대해 미분을 수행함
- 해당 값으로 Parameter를 업데이트
- ex - AutoGrad
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
Q = 3*a**3 - b**2
external_grad = torch.tensor([1., 1.]) #
Q.backward(gradient=external_grad)
print(a.grad) # a에 대한 편미분값
print(b.grad) # b에 대한 편미분값
>>> tensor([36., 81.])
>>> tensor([-12., -8.])- 선형회귀에서의 AutoGrad
import torch
x_train = torch.tensor([i for i in range(11)], requires_grad = True, dtype = torch.float32).view(-1, 1)
y_train = torch.tensor([i * 2 for i in range(11)], requires_grad = True, dtype = torch.float32).view(-1, 1)
inputDim = 1
outputDim = 1
learningRate = 0.01
epochs = 10
model = nn.Linear(inputDim, outputDim)
##### For GPU #####
if torch.cuda.is_available():
model.cuda()
## Loss, optimizer
criterion = torch.nn.MSELoss() # MSE
optimizer = torch.optim.SGD(model.parameters(), lr=learningRate) # torch.optim.SGD(대상이 되는 파라미터, lr)
## Parameter 업데이트 과정
for epoch in range(epochs):
if torch.cuda.is_available():
inputs = x_train.cuda()
labels = y_train.cuda()
else:
inputs = x_train
labels = y_train
# 이전 그레디언트 값이 지금의 학습에 영향을 주지 않게 하기 위해 초기화를 시켜줌
optimizer.zero_grad()
# 예측값
outputs = model(inputs)
# 예측값/실제값의 Loss
loss = criterion(outputs, labels)
print(loss)
# 그레디언트 구하기(미분)
loss.backward()
# 파라미터 업데이트
optimizer.step()
print('epoch {}, loss {}'.format(epoch, loss.item()))
>>>
nn.Module 뜯어보기


AI Engineer : Lv 0