
Pytorch란
- numpy + Autograd
- PyTorch Tensor
-
다차원 Arrays를 표현하는 PyTorch 클래스
-
numpy-like operations: numpy의 ndarray와 사실상 동일 (== Tensorflow의 Tensor).
- numpy의 ndarray를 다루는 방법이 대부분 그대로 적용됨
-
PyTorch의 tensor는 GPU에 올려서 사용이 가능함
x_data.device >>> device(type = 'cpu') if torch.cuda.is_availabel(): x_data_cuda = x_data.to('cuda') # GPU로 올리기 x_data_cuda.device >>> device(type = 'cuda', index = 0) -
torch.tensorvstorch.Tensortorch.Tensor
- 클래스 (Class)
- int 입력시 float로 변환
- torch 데이터 입력시 입력 받은 데이터의 메모리 공간을 사용
- list, numpy 데이터 입력 시 입력 받은 데이터를 복사하여 새롭게 torch.Tensor를 만든 후 사용
torch.tensor
- 함수 (Function)
- int 입력시 int 그대로 입력
- 입력 받은 데이터를 새로운 메모리 공간으로 복사 후 사용
-
- Documentation main - PyTorch 공식 문서
딥러닝 파이토치 주요과정
.png)
PyTorch
-
torch: 텐서를 생성하는 라이브러리 -
torch.autograd: 자동미분 기능을 제공하는 라이브러리 -
torch.nn: 신경망을 생성하는 라이브러리 -
torch.multiprocessing: 병럴처리 기능을 제공하는 라이브러리 -
torch.utils: 데이터 조작 등 유틸리티 기능 제공 -
torch.legacy(./nn/.optim): Torch로부터 포팅해온 코드 -
torch.onnx: ONNX(Open Neural Network Exchange)- 서로 다른 프레임워크 간의 모델을 공유할 때 사용
(참고: 이수안컴퓨터연구소 - 파이토치)
텐서 조작(manipulations)
인덱싱(Indexing) 공식 문서
Numpy-like Indexing
import torch
a = torch.Tensor([[1, 2],
[3, 4]])
print(a[1, 1])
>>> tensor(4.)torch.gather - PyTorch 공식 문서
-
공식문서
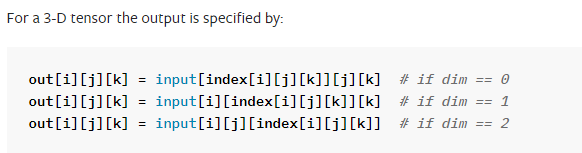
-
(3-D tensor) if dim == 2
- input[i][j]가 돌아가는 상황에서 [k]를 인덱싱하는 것.
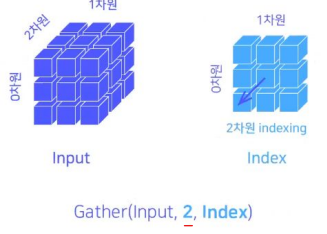
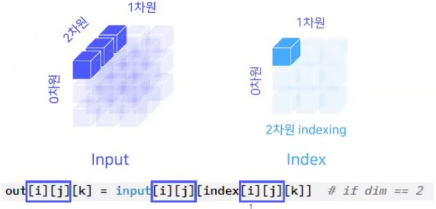
- (첫 번째 인덱싱)input[i][j]가 돌아가는 상황에서 [k] == 0이라면, 다음과 같이 인덱싱 됨.
- (두 번째 인덱싱)input[i][j]가 돌아가는 상황에서 [k] == 0이라면, 다음과 같이 인덱싱 됨.
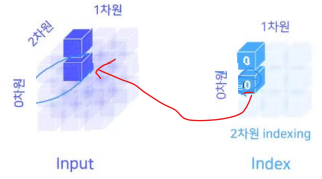
- 이를 반복
- input[i][j]가 돌아가는 상황에서 [k]를 인덱싱하는 것.
-
파이썬 코드(2-D tensor)
import torch A = torch.Tensor([[1, 2], [3, 4]]) output = torch.gather(A, 1, torch.tensor([[0], [1]])) print(output) >>> tensor([[1.], >>> [4.]])
torch.view
reshape()과 동일하게 텐서의 크기(size)나 모양(shape)을 변경
import torch
A = torch.Tensor([[1, 2],
[3, 4]])
output = torch.gather(A, 1, torch.tensor([[0],
[1]]))
print(output.view(2, 1))
print(output.view(1, 2))
print(output.view(-1, 2)) # -1: ,2에 맞춰 자동으로 조정
>>> tensor([[1.],
>>> [4.]])
>>> tensor([[1., 4.]])
>>> tensor([[1., 4.]])
torch.viewvstorch.reshape
reshape():reshape은 가능하면 input의view를 반환하고, 안되면contiguous한 tensor로 copy하고 view를 반환한다.view():view는 기존의 데이터와 같은 메모리 공간을 공유하며 stride 크기만 변경하여 보여주기만 다르게 한다. 그래서contigious해야만 동작하며, 아닌 경우 에러가 발생함.
contiguous란
- arrow(), view(), expand(), transpose() 등의 함수는 새로운 Tensor를 생성하는 게 아니라 기존의 Tensor에서 메타데이터만 수정하여 우리에게 정보를 제공함. 즉 메모리상에서는 같은 공간을 공유함.
- 하지만 연산 과정에서 Tensor가 메모리에 올려진 순서(메모리 상의 연속성)가 중요하다면 원하는 결과가 나오지 않을 수 있고 에러가 발생함. 그렇기에 어떤 함수 결과가 실제로 메모리에도 우리가 기대하는 순서로 유지하려면 .contiguous()를 사용하여 에러가 발생하는 것을 방지할 수 있다.
(참고: Hello Subinium!)
squeeze() & unsqueeze()
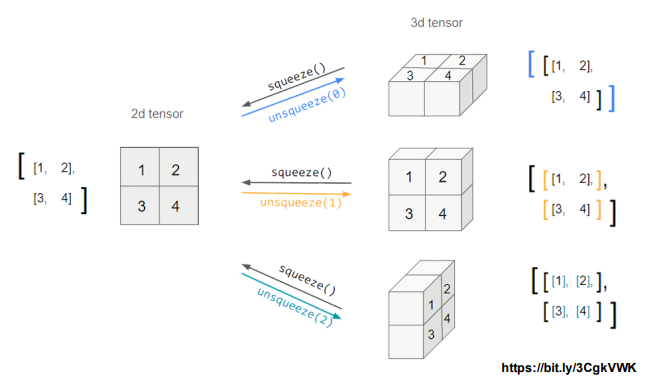
- squeeze(): 차원의 개수가 1인 차원을 삭제(압축)
import torch
A = torch.Tensor([[[1, 2],
[3, 4]]])
print(A.size())
A = A.squeeze()
print(A.size())
>>> torch.Size([1, 2, 2])
>>> torch.Size([2, 2])- unsqueeze(): 차원을 증가시킴
import torch
A = torch.Tensor([[[1, 2],
[3, 4]]])
print(A.size())
A = A.unsqueeze(dim = 3) # dim = 3 -> A.size([1, 2, 2, <여기에 추가>]) (dim = -1 한것과 같음)
print(A)
print(A.size())
>>> torch.Size([1, 2, 2])
>>> tensor([[[[1.],
>>> [2.]],
>>>
>>> [[3.],
>>> [4.]]]])
>>> torch.Size([1, 2, 2, 1])stack() & cat()
stack(): 새로운 차원으로 주어진 텐서들을 붙이는 것cat(): 주어진 차원을 기준으로 주어진 텐서들을 붙이는 것(concatenate)
import torch
a = torch.tensor([1, 2])
b = torch.tensor([3, 4])
ab_stack = torch.stack([a, b])
ab_cat = torch.cat([a, b])
print(ab_stack)
print(ab_cat)
>>> tensor([[1, 2],
>>> [3, 4]])
>>> tensor([1, 2, 3, 4])(참고: 파이토치KR 커뮤니티)
split() & chunk()
split(): n개씩 나눠지게 하는 것chunk(): n개로 나누는 것
import torch
a = torch.tensor([1, 2, 3, 4, 5, 6])
a_split = torch.split(a, 3)
a_chunk = torch.chunk(a, 3)
print(a_split)
print(a_chunk)
>>> (tensor([1, 2, 3]), tensor([4, 5, 6]))
>>> (tensor([1, 2]), tensor([3, 4]), tensor([5, 6]))transpose() & permute()
transpose(): 두 개의 차원을 transpose 시킬 수 있다.permute(): 모든 차원에 대해 transpose 시킬 수 있다.
a = torch.tensor([i for i in range(24)]).view(2, 3, -1)
b = a.transpose(0, 1) # 0번째와 1번째 transpose (최대 두 차원만 변경 가능)
c = a.permute(2, 1, 0) # 모든 차원에 대한 transpose (모든 차원 변경 가능)
print(a.size())
print(b.size())
print(c.size())
>>> torch.Size([2, 3, 4])
>>> torch.Size([3, 2, 4])
>>> torch.Size([4, 3, 2])텐서 연산(Math operations) 공식 문서
Math Ops - Pointwise Ops 공식 문서
- 각 점에 대해 별도로 연산을 적용하는 것.
log1p,rad2deg,clamp,sin,log,floor,exp, .....
Math Ops - Reduction Ops 공식 문서
- 함수 조건에 따라 tensor의 특정 값만을 가져오거나 연산을 통해서 크기를 줄이는 것(요약, 통계치 등)
argmax,all,mean,median,norm,sum
Math Ops - Comparison Ops 공식 문서
- 비교와 관련된 함수
equal,isclose,isinf,isnan,sort,argsort:작은 수부터 차례로 index 반환, .....
Math Ops - Other Ops 공식 문서
- 기타 연산함수
cov,cumsum,diff, ....
torch.einsum: 다양한 연산 함수에 대해 통일된 표기법으로 연산시켜주는 함수
-
einsum형태:
Result = einsum("dimension notation of A, dimension notation of B,...->Result Dimension", A, B, ...) -
ex) transpose
import torch A = torch.tensor([[1,2], [4,5]]) R = torch.einsum("ij->ji", A) print(A) print(R) >>> tensor([[1, 2], >>> [4, 5]]) >>> tensor([[1, 4], >>> [2, 5]])
Math operations - BLAS and LAPACK Ops 공식 문서
- "BLAS": Basic Linear Algebra Subprograms
- "LAPACK": Linear Algebra PACKage
mm,mataul,dot,bmm,qr,matrix_rank, ...torch.mmvstorch.matmulvstorch.bmmvstorch.mul- mm은 matrix multiplication으로, [n, m] x [m,p] = [n,p] 를 구현한다.
- bmm은 batch matrix multiplication으로, 두 operand가 모두 batch일 때 사용한다.
[B, n, m] x [B, m, p] = [B, n, p] torch.matmul(@)은torch.mm과는 달리 broadcast를 지원한다.torch.matmul은 1차원일 때 내적을 수행한다.
torch.mul은 성분곱 연산이다.- 참고: Sunghee's research blog
torch.nn vs torch.nn.functional
- 그래프를 만들기 위한 모듈(딥러닝 모델 !!)
- 두 패키지가 같은 기능이지만 방식이 조금 다름
- 위의
autograd관련 작업들을 두 패키지를 통해 진행할 수 있음 - 텐서를 직접 다룰 때
requires_grad와 같은 방식으로 진행할 수 있음 - 결론적으로,
torch.nn은 attribute를 활용해 state를 저장하고 활용하고,
torch.nn.functional로 구현한 함수의 경우에는 인스턴스화 시킬 필요 없이 사용이 가능- torch.nn
- 주로 가중치(weights), 편향(bias)값들이 내부에서 자동으로 생성되는 레이어들을 사용할 때
- 따라서,
weight값들을 직접 선언 안함 - (뒤에서 중요한 것 설명)
- torch.nn.functional
- 가중치를 직접 선언하여 인자로 넣어줘야함
- 다양한 수식 변화를 지원
-softmax,one_hot

(참고: 이수안컴퓨터연구소)
- torch.nn
torch.nn
nn.Linear
- 텐서를 선형변환시키는 함수
import torch
from torch import nn
linear = nn.Linear(10, 20) # 10 -> 20
a = torch.randn((3, 10))
output = linear(a)
print(a.size())
print(output.size())
>> torch.Size([3, 10])
>> torch.Size([3, 20])- nn.Linear vs nn.LazyLinear
- nn.Linear
- 입력, 출력값을 지정해야 함
- torch.nn.parameter 사용
- 레이어 생성 시 parameter(W, b)를 초기화
- nn.LazyLinear
- 출력값의 크기만 지정(입력값은 첫 forward를 진행할 때 자동으로 할당됨)
- torch.nn.UninitializedParameter 사용
- 레이어 생성 후 첫 forward 진행 중에 parameter(W, b)를 초기화
- nn.Linear
torch.nn - nn.Module 공식 문서
nn.Module클래스는 nn 모듈의 Base 클래스임.Module은 다른Module를 여러 개 포함할 수 있다(더욱 큰 딥러닝 모델이 됨)- 기본적으로
__init__와forward로 구성됨. - 내재된 다양한 method들이 있음(공식 문서 참고)
# nn.Module 기본 구성
import torch
from torch import nn
class Add(nn.Module): # nn.Module 상속받음
def __init__(self):
super().__init__()
def forward(self, a, b):
output = torch.add(a, b)
return output
add = Add()
a, b = torch.tensor([10]), torch.tensor([15])
print(add(a, b))
>>> tensor([25])nn.Module - Container 공식문서
- 모듈(Module)들을 묶기 위한 함수들
nn.Sequential
- 모듈들을 하나로 묶어 순차적으로 실행
# nn.Sequential
import torch
from torch import nn
class Add(nn.Module):
def __init__(self, num):
super().__init__()
self.num = num
def forward(self, x):
output = torch.add(x, self.num)
return output
cal = nn.Sequential(Add(1), Add(2), Add(4)) # (1 + 1) (2 + 2) (4 + 4)
x = torch.tensor([1])
print(cal(x))
>>> tensor([8])nn.ModuleList
- Module을 list형태로 모아둠
- 인덱싱을 통해 가져올 수 있음
# nn.Sequential
import torch
from torch import nn
class Add(nn.Module):
def __init__(self, num):
super().__init__()
self.num = num
def forward(self, x):
output = torch.add(x, self.num)
return output
cal = nn.ModuleList([Add(1), Add(2), Add(4)]) # []
x = torch.tensor([1])
print(cal[1](x))
>>> tensor([3])Python ListvsPytorch ModuleList- nn.ModuleList를 사용하면 내부에 담긴 Module들이 nn.Module의 submodule로 등록이 됨.
- nn.Module 내부에서 새로운 변수를 생성할 땐
__setattr__이라는 특수 메서드가 호출됨. - 이때,
__setattr__메서드는 '값'의 타입을 체크해서 만약 모듈이면 submodule로 등록하고 아니면 무시하고 넘어가게 됨. - 따라서
Python List로 값을 저장하면 list에 포함된 어떠한 module들도 저장이 되지 않음
- nn.Module 내부에서 새로운 변수를 생성할 땐
- nn.ModuleList를 사용하면 내부에 담긴 Module들이 nn.Module의 submodule로 등록이 됨.
nn.ModuleDict
- Module을 dict형태로 모아둠
- 특정 모듈의 key값을 이용해 value를 가져올 수 있음
# nn.Sequential
import torch
from torch import nn
class Add(nn.Module):
def __init__(self, num):
super().__init__()
self.num = num
def forward(self, x):
output = torch.add(x, self.num)
return output
cal = nn.ModuleDict({'one': Add(1), 'two': Add(2), 'three': Add(4)}) # {}
x = torch.tensor([1])
print(cal['three'](x))
>>> tensor([5]nn.Module - Parameter
- nn.Module 안에 미리 만들어진 tensor들을 보관
- .nn.Parameter 클래스는 torch.Tensor 클래스를 상속받아 만들어졌음
- torch.nn.Module 클래스의 attribute로 할당되면, 자동으로 파라메터 목록(
parameters())에 추가됨(torch.Tensor 클래스와의 차이점)- Parameter로 지정된 tensor의 경우, 역전파시 gradient 값을 계산하여 값을 업데이트 해주고, 모델을 저장할 때 값을 저장해줌.
- tensor로 저장된 값은 업데이트 되지 않고 모델을 저장할 때도 무시됨
import torch
from torch import nn
from torch.nn.parameter import Parameter
class Linear(nn.Module): # 선형변환
def __init__(self, in_features, out_features):
super().__init__()
self.W = Parameter(torch.empty((out_features, in_features)))
self.b = Parameter(torch.empty(out_features))
def forward(self, x):
output = torch.addmm(self.b, x, self.W.T)
return output
x = torch.Tensor([[1, 2],
[3, 4]])
linear = Linear(2, 3)
print(linear(x))
## gradient를 계산하는 함수인 grad_fn가 생성됨
>> tensor([[-1.3925e+31, 2.9512e+04, 9.5367e-06],
>>> [-1.3925e+31, 5.9024e+04, 1.9073e-05]], grad_fn=<AddmmBackward0>)nn.Module - Buffer
- 값이 업데이트 되지는 않지만, 모듈에 값을 저장할 수 있음
| Gradient 계산 | 값 업데이트 | 모델 저장시 값 저장 | |
|---|---|---|---|
| Tensor | ❌ | ❌ | ❌ |
| Parameter | ⭕ | ⭕ | ⭕ |
| Buffer | ❌ | ❌ | ⭕ |
class Model(nn.Module):
def __init__(self):
super().__init__()
self.parameter = Parameter(torch.Tensor([7])) # PARAMETER
self.tensor = torch.Tensor([7]) # TENSOR
self.register_buffer('buffer', torch.Tensor([7]), persistent=True) # BUFFER
m = Model()
print(m.state_dict())
>>> OrderedDict([('parameter', tensor([7.])), ('buffer', tensor([7.]))])nn.Module - 모델 관찰하기
- 간단한 MLP모델 생성
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.layer_A = nn.Linear(2, 5)
self.layer_B = nn.Linear(5, 10)
self.layer_C = nn.Linear(10, 1)
self.relu = nn.ReLU()
def forward(self, x):
output = self.layer1(x)
output = self.relu(output)
output = self.layer2(output)
output = self.relu(output)
output = self.layer3(output)
return output
model = Model()Parameter - state_dict()
- 모듈의 각 계층의 매개변수를 dict형태로 반환
print(model.state_dict())>>>

Parameter - named_parameters()
- 모델 내부에 있는 parameter들을 반환
for name, module in model.named_parameters():
print(name, module)
print("-" * 30)>>>

Parameter - get_parameter()
- 특정 module에 속한 특정 parameter를 반환
print(model.get_parameter('layer_A.weight'))>>>
Module - named_modules()
- 모델 내부의 모든 module들 목록을 return 해줌(generator object)
for name, module in model.named_modules():
print(name, module)
print("-" * 30)>>>

- named_children(): 한단계 아래의 submodule까지만 return 해줌
Module - get_submodule()
- 모델 내부에 있는 특정 module만을 가져옴
print(model.get_submodule('layer_A'))
>>> Linear(in_features=2, out_features=5, bias=True)Buffer - named_buffers()
- 모델 내부에 있는 buffer 전체 목록을 가져옴
model.buffers(): 모델 이름은 생략, buffer만 가져옴model.get_buffer(): 모델의 특정 module에 있는 버퍼를 가져옴
<코드 생략>
** extra_repr
nn.Module - hook
- 패키지화된 코드에서 다른 프로그래머가 custom 코드를 중간에 실행시킬 수 있도록 만들어놓은 인터페이스
- 프로그램의 실행 로직을 분석하거나 프로그램에 기능을 추가하고 싶을 때 사용
- Pytorch에서는 크게 Tensor와 Module에 hook을 적용할 수 있음
- hook 종류별 시점
- pre-hook: 프로그램 실행 전에 걸어놓는 hook
- forward hook
- register_forward_hook
- forward 호출 후, forward ouput 계산 후
hook(module, input, ouput)
- register_forward_pre_hook
- forward 호출 전
hook(module, input)
- register_forward_hook
- backward hook
- register_full_backward_hook
- input에 대한 gradient가 계산될 때마다 호출
hook(module, grad_input, grad_output)
- register_full_backward_hook
- tensor hook
- tensor hook에는 backward hook밖에 없음
- tensor의 gradient가 계산될 때마다 호출
tensor_hook(grad)
import torch
from torch import nn
def pre_hook(module, input):
print('forward 시작!!')
def hook(module, input, output):
return output + 10000 #output 값에 10000 더해서 반환
linear = nn.Linear(2, 3)
linear.register_forward_pre_hook(pre_hook)
linear.register_forward_hook(hook)
print(linear(torch.Tensor([[1, 2], [3, 4]])))
>>> tensor([[ 9999.2549, 10000.6816, 9999.8857],
>>> [ 9997.7803, 10000.9023, 9999.5381]], grad_fn=<AddBackward0>)nn.Module - apply
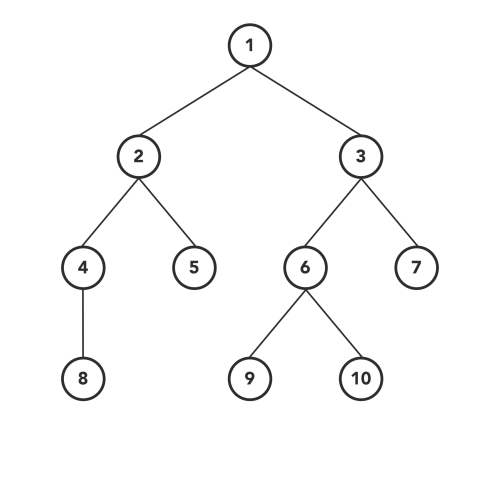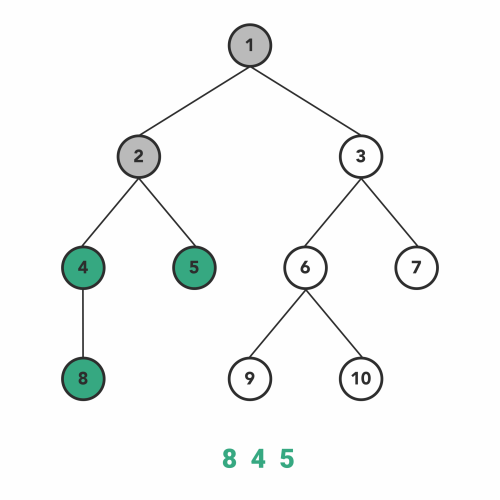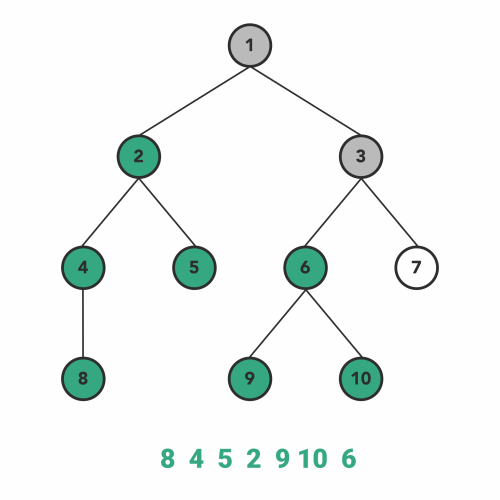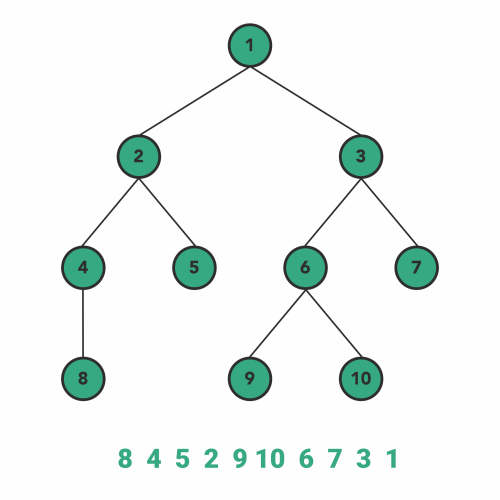
nn.module에서 모델 맨 위 module에 어떤 함수를 적용하면, 그 아래에 존재하는 모든 module에 해당 함수를 적용함(nn.Module에서 내부적으로 이를 지원). 그러나 nn.Module에 이미 구현되어 있는 method가 아닌 custom method를 모델에 적용하고 싶다면, apply함수를 사용해야 함.- apply는 Postorder Traversal 방식으로 module들에 함수를 적용함.
import torch
from torch import nn
@torch.no_grad()
def init_weights(m):
print(m)
if type(m) == nn.Linear:
m.weight.fill_(1.0) # m모듈의 weight(parameter)를 1.0으로 채우는 함수
print(m.weight)
net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
print(net.apply(init_weights)) # apply가 적용된 module을 return해줌>>>
PyTorch 프로젝트 구조
notebook의 한계
- 초기 단계에서는 대화식 개발과정이 유리(학습과정과 디버깅 등 지속적인 확인)
- 배포 및 공유 단계에서는 notebook 공유의 어려움(쉬운 재현의 어려움, 실행순서 꼬임
- DL 코드도 하나의 프로그램: 개발 용이성 확보와 유지보수 향상 필요
Python Project Template
- 다양한 프로젝트 템플릿이 존재
- 실행, 데이터, 모델, 설정, 로깅, 지표, 유틸리티 등 다양한 모듈들을 분리하여 프로젝트 템플릿화
- 모듈 구성(https://github.com/victoresque/pytorch-template)

Pytorch Troubleshooting
- gpu 확인
$ nvidia-smi
GPUtil.showUtilization() - gpu 공간 확보
torch.cuda.empty_cache(): 사용하지 않는 공간을 확보해줌
gc.collect(): 조각모음

AI Engineer : Lv 0