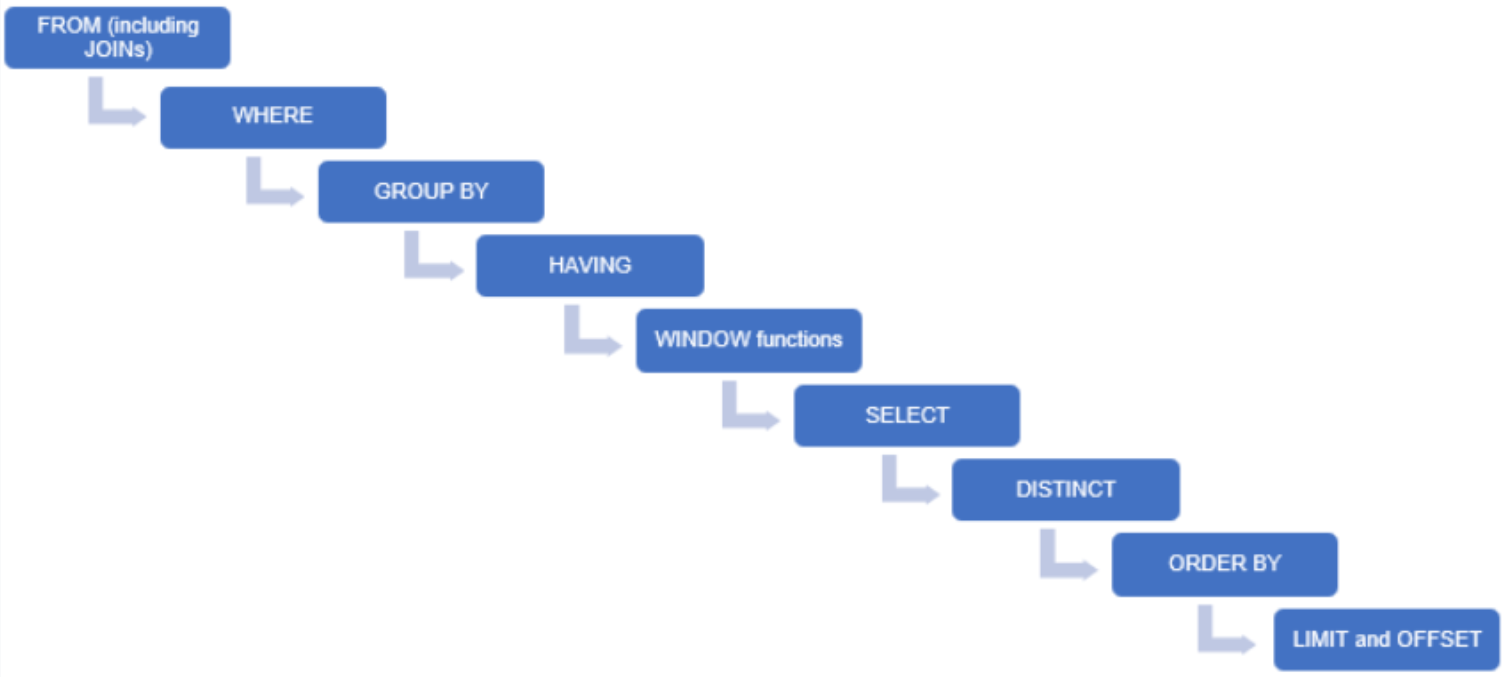
SQL 튜닝에서 절대적인 원칙은 없다. 실행 시간과 실행 계획을 실제로 분석하여 Index를 적합하게 적용하자.
(DBMS마다도 결과가 조금씩 다를 수 있다)
[WHERE vs ORDER BY]

튜닝을 해볼 Query는 위와 같다.
Index 적용이 가능해보이는 컬럼은 created_at, department, salary 세가지가 있다.
이중 중복도가 높은 department(WHERE)는 제외하고(Index 사용의 효용이 떨어짐)
created_at(WHERE)과 salary(ORDER BY) 중 비교 해보고자 한다.
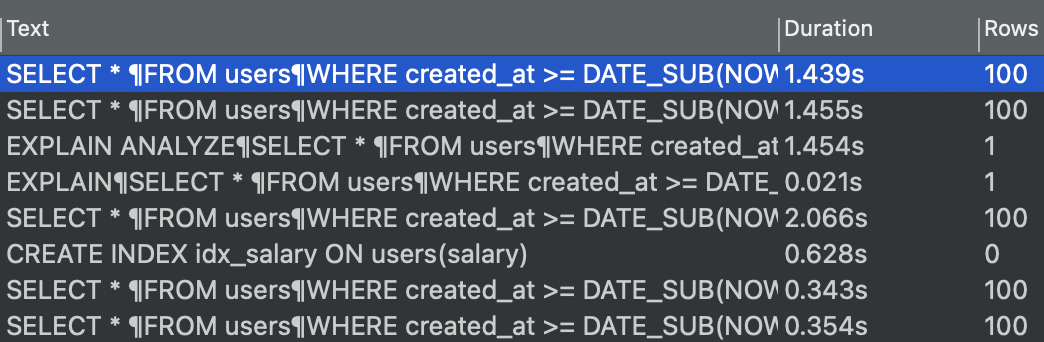
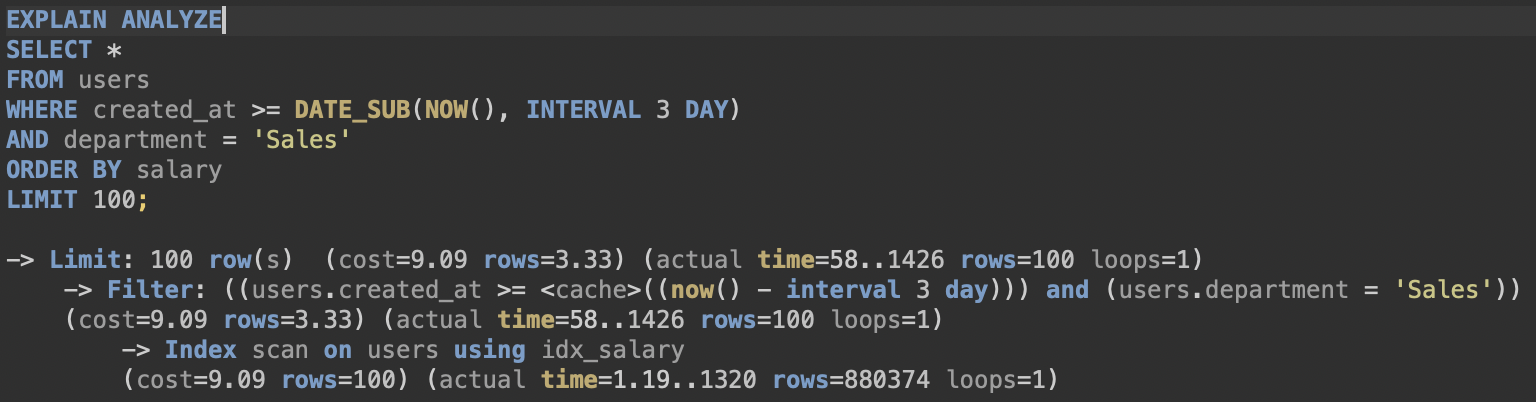
[salary에 Index]
실행 시간 : 343ms -> 1455ms(오히려 느려짐)
실행 계획 : 처음 가져오는 data 수 880374 row(총 data 1000000 row)
Index를 추가하기 전보다 오히려 느려졌다. 분석을 보면 첫 접근이 salary의 Index Table인데
정렬되어 있는 Index Table에서 Filter 조건에 맞는 지를 한번 더 확인해야 하기때문에 오히려 오버헤드 발생하는 것으로 추정된다. 첫 access data 양도 총 data의 88% 정도로 거의 대부분이다.
[created_at에 Index]

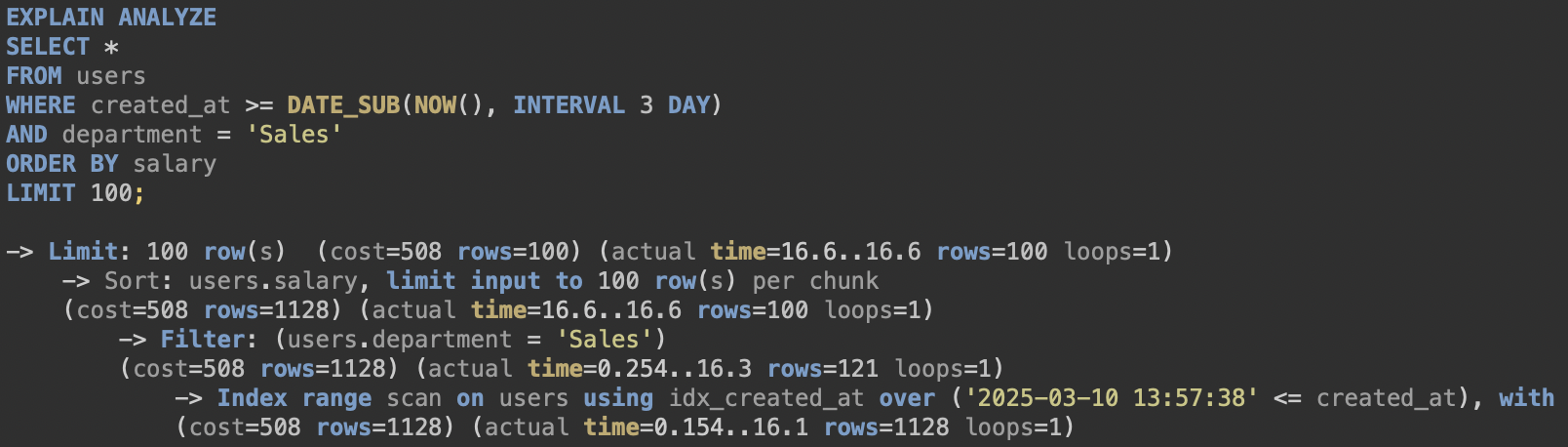
실행 시간 : 343ms -> 37ms
실행 계획 : 처음 가져오는 data 수 1128 row(총 data 1000000 row)
실행 속도가 10배 가량 빨라졌고 첫 access data는 총 data의 0.1% 수준이다.
실행 분석에서는 created_at을 기준으로 Index 범위 탐색 > department로 필터링 > salary로 정렬 하고 있다.
[결론]
SQL 실행문 순서가 중요한 이유는 앞 단계에서의 data를 줄이는 것이
이후 연산에서의 부담을 계속해서 줄여주기 때문이다.
그러한 이유로 위의 CASE에서는 ORDER BY보다 먼저 실행되는 WHERE에 해당하는
created_at에 Index를 설정하는 것이 바람직하다.
- 잘 못된 Index 설정은 오히려 속도를 크게 늦출 수 있다!(+ Index Table 공간 낭비)
- 보편적으로 ORDER BY보다는 WHERE에 Index를 설정하는 것이 효과적이다.
(실제 실행 시간 확인 필요)
